Gerenciar bibliotecas de pools do Apache Spark no Azure Synapse Analytics
Depois de identificar os pacotes Scala, Java R (Versão prévia) ou Python que você deseja usar ou atualizar para seu aplicativo Spark, é possível instalá-los ou removê-los de um pool Spark. As bibliotecas de nível de pool estão disponíveis para todos os notebooks e trabalhos em execução no pool.
Há duas maneiras principais de instalar uma biblioteca em um pool do Spark:
- Instalar uma biblioteca de espaço de trabalho que foi carregada como um pacote de espaço de trabalho.
- Para atualizar bibliotecas Python, forneça uma especificação de ambiente requirements.txt ou Conda environment.yml a fim de instalar pacotes de repositórios como PyPI, Conda-Forge e muito mais. Leia a seção sobre a especificação de ambiente para saber mais.
Depois que as alterações forem salvas, um trabalho do Spark executará a instalação e armazenará em cache o ambiente resultante para reutilização posterior. Quando o trabalho for concluído, novos trabalhos do Spark ou sessões de notebook usarão as bibliotecas de pools atualizadas.
Importante
- Se o pacote que você está instalando for grande ou levar muito tempo para ser instalado, o tempo de inicialização da instância do Spark será afetado.
- Não há suporte para a alteração da versão PySpark, Python, Scala/Java, .NET, R ou Spark.
- A instalação de pacotes de repositórios externos, como PyPI, Conda-Forge ou canais Conda padrão, não é compatível com espaços de trabalho habilitados para proteção de exfiltração de dados.
Gerenciar pacotes no Synapse Studio ou no portal do Azure
As bibliotecas do pool do Spark podem ser gerenciadas no Synapse Studio ou no portal do Azure.
Para atualizar ou adicionar bibliotecas a um pool do Spark:
Navegue até o espaço de trabalho do Azure Synapse Analytics no portal do Azure.
Se você estiver atualizando do portal do Azure:
Na seção recursos do Synapse, selecione a guia pools do Apache Spark e selecione um pool do Spark na lista.
Selecione os pacotes na seção Configurações do pool do Spark.

Se você estiver atualizando do Synapse Studio:
Selecione Gerenciar no painel de navegação principal e, em seguida, selecione pools do Apache Spark.
Selecione a seção Pacotes para um pool do Spark específico.

Para bibliotecas de feeds Python, carregue o arquivo de configuração do ambiente usando o seletor de arquivos na seção Pacotes da página.
Também é possível selecionar pacotes de workspace adicionais para incluir arquivos Jar, Wheel ou Tar.gz no pool.
Você também pode remover os pacotes preteridos da seção Pacotes de workspace, pois o pool não anexará mais esses pacotes.
Depois de salvar as alterações, um trabalho do sistema será disparado para instalar e armazenar em cache as bibliotecas especificadas. Esse processo ajuda a reduzir o tempo de inicialização geral da sessão.
Depois que o trabalho for concluído com êxito, todas as novas sessões irão pegar as bibliotecas de pools atualizadas.


Importante
Ao selecionar a opção para forçar novas configurações, você encerrará todas as sessões atuais para o pool do Spark selecionado. Depois que as sessões forem encerradas, você precisará aguardar até que o pool seja reiniciado.
Se essa configuração estiver desmarcada, você precisará aguardar a sessão atual do Spark terminar ou interrompê-la manualmente. Depois que a sessão for encerrada, você precisará deixar o pool reiniciar.
Acompanhar o progresso da instalação
Um trabalho do Spark reservado pelo sistema é iniciado cada vez que um pool é atualizado com um novo conjunto de bibliotecas. Esse trabalho do Spark ajuda a monitorar o status da instalação da biblioteca. Se a instalação falhar devido a conflitos de biblioteca ou outros problemas, o pool do Spark será revertido para seu estado anterior ou padrão.
Além disso, os usuários também podem inspecionar os logs de instalação para identificar conflitos de dependência ou ver quais bibliotecas foram instaladas durante a atualização do pool.
Para exibir esses logs:
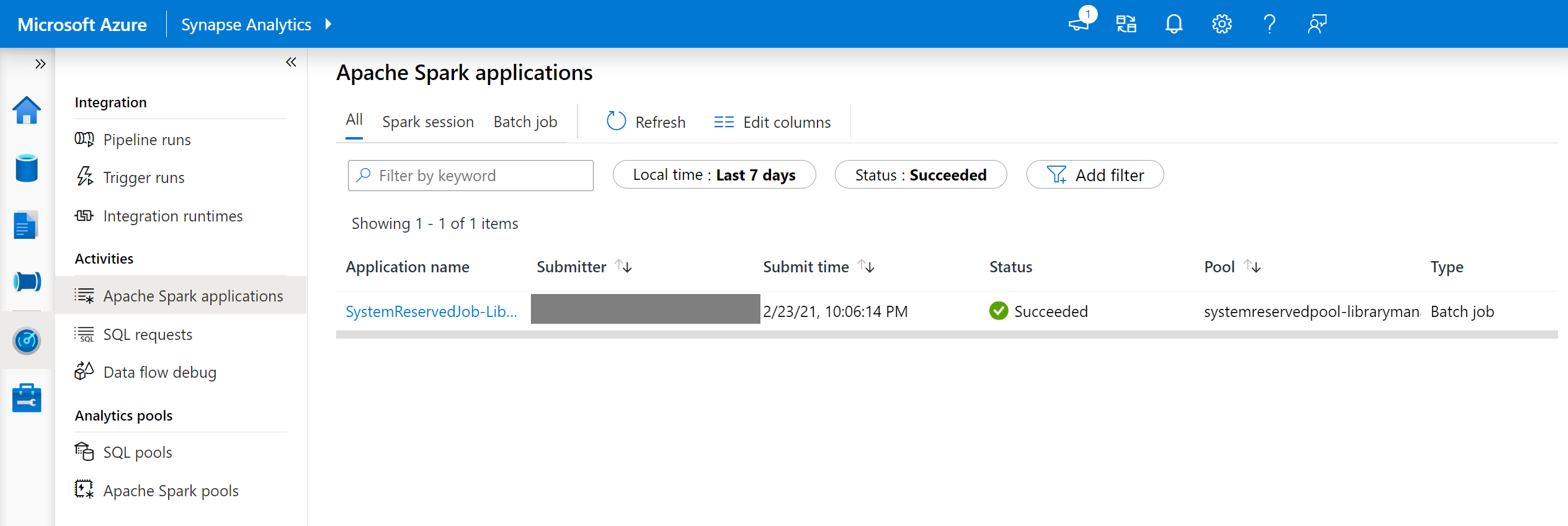
- Navegue até a lista de aplicativos Spark na guia Monitorar.
- Selecione o trabalho do aplicativo Spark do sistema que corresponde à sua atualização de pool. Esses trabalhos do sistema são executados sob o título SystemReservedJob-LibraryManagement.
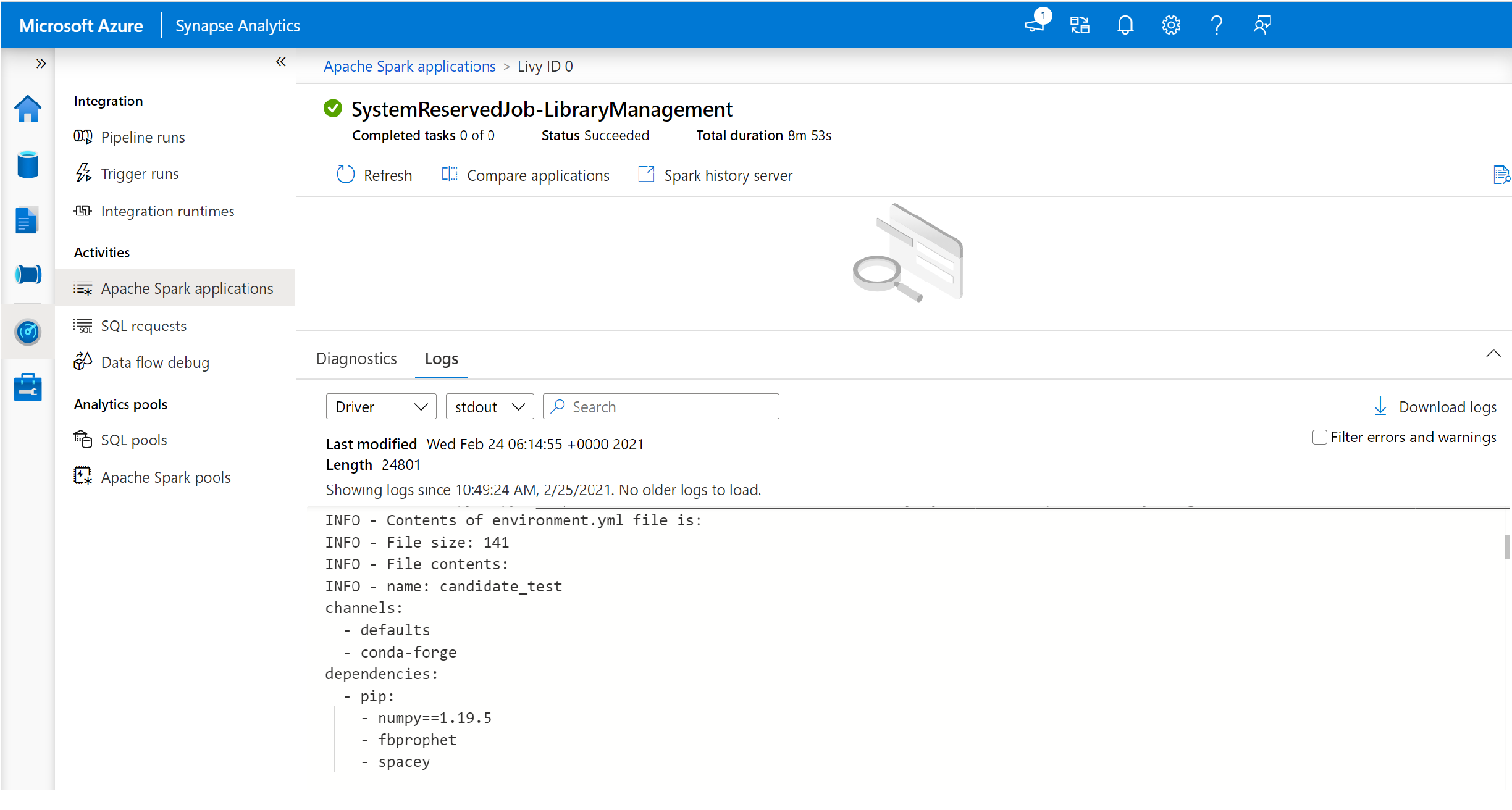
- Alterne para exibir os logs de driver e stdout.
- Nos resultados, você verá os logs relacionados à instalação de suas dependencias.


Formatos de especificação de ambiente
PIP requirements.txt
Um arquivorequirements.txt (saída do pip freeze comando) pode ser usado para atualizar o ambiente. Quando um pool é atualizado, os pacotes listados nesse arquivo são baixados do PyPI. As dependencias completas são então armazenadas em cache e salvas para reutilização posterior do pool.
O trecho a seguir mostra o formato do arquivo de requisitos. O nome do pacote PyPI é listado junto com uma versão exata. Esse arquivo segue o formato descrito na documentação de referência do pip freeze.
Este exemplo fixa uma versão específica.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
Formato YML
Além disso, você também pode fornecer um arquivo environment. yml para atualizar o ambiente do pool. Os pacotes listados neste arquivo são baixados dos canais de Conda padrão, Conda-Forge e PyPI. Você pode especificar outros canais ou remover os canais padrão usando as opções de configuração.
Este exemplo especifica os canais e as dependencias de Conda/PyPI.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
Para detalhes sobre como criar um ambiente desse arquivo environment.yml, consulte Criando um ambiente de um arquivo environment.yml.
Próximas etapas
- Exibir as bibliotecas padrão: suporte à versão Apache Spark
- Solucionar erros de instalação da biblioteca: solucionar erros de biblioteca