Tutorial: Criar um aplicativo Apache Spark com o IntelliJ usando um workspace do Azure Synapse
Este tutorial mostra como usar o plug-in do Azure Toolkit for IntelliJ para desenvolver aplicativos Apache Spark escritos em Scala e depois enviá-los diretamente do IDE (ambiente de desenvolvimento integrado) IntelliJ para um Pool do Apache Spark sem servidor. Você pode usar o plug-in destas maneiras:
- Desenvolver e enviar um aplicativo Scala Spark em um Pool do Spark.
- Acessar seus recursos de pools do Spark.
- Desenvolver e executar um aplicativo Scala Spark localmente.
Neste tutorial, você aprenderá como:
- Usar o plug-in Azure Toolkit for IntelliJ
- Desenvolver aplicativos do Apache Spark
- Enviar aplicativo para pools do Spark
Pré-requisitos
Plug-in do Azure Toolkit 3.27.0-2019.2 – Instalar do repositório de plug-ins do IntelliJ
Plugin Scala – Instalar do repositório de plug-ins do IntelliJ.
O seguinte pré-requisito se aplica apenas a usuários do Windows:
Durante a execução do aplicativo Scala Spark local em um computador Windows, você pode receber uma exceção, conforme explicado em SPARK-2356. A exceção ocorre porque WinUtils.exe está ausente no Windows. Para resolver esse erro, baixe o executável WinUtils, salvando-o em uma localização como C:\WinUtils\bin. Em seguida, adicione uma variável de ambiente HADOOP_HOME e defina o valor da variável para C\WinUtils.
Criar um aplicativo Scala Spark para um Pool do Spark
Inicie o IntelliJ IDEA e selecione Criar novo projeto para abrir a janela Novo projeto.
Selecione Apache Spark/HDInsight no painel esquerdo.
Selecione Projeto Spark com Exemplos (Scala) na janela principal.
Na lista suspensa Ferramenta de build, selecione um dos seguintes tipos:
- Maven para obter suporte ao assistente de criação de projetos Scala.
- SBT para gerenciar as dependências e para criar no projeto Scala.
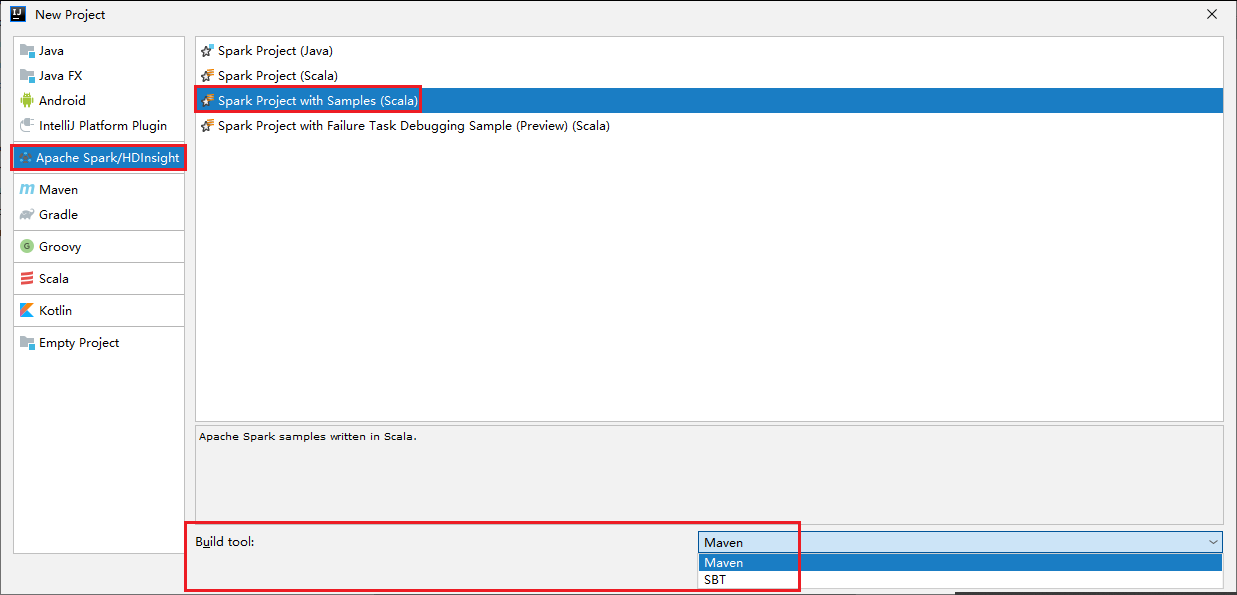
Selecione Avançar.
Na janela Novo Projeto, forneça as seguintes informações:
Propriedade Descrição Nome do projeto Insira um nome. Este tutorial usa myApp.Localização do projeto Insira a localização desejada para salvar o projeto. SDK do projeto Isso poderá ficar em branco no primeiro uso do IDEA. Selecione Novo... e navegue até o JDK. Versão do Spark O assistente de criação integra a versão apropriada para o SDK do Spark e o SDK do Scala. Aqui você pode escolher a versão do Spark de que precisa. 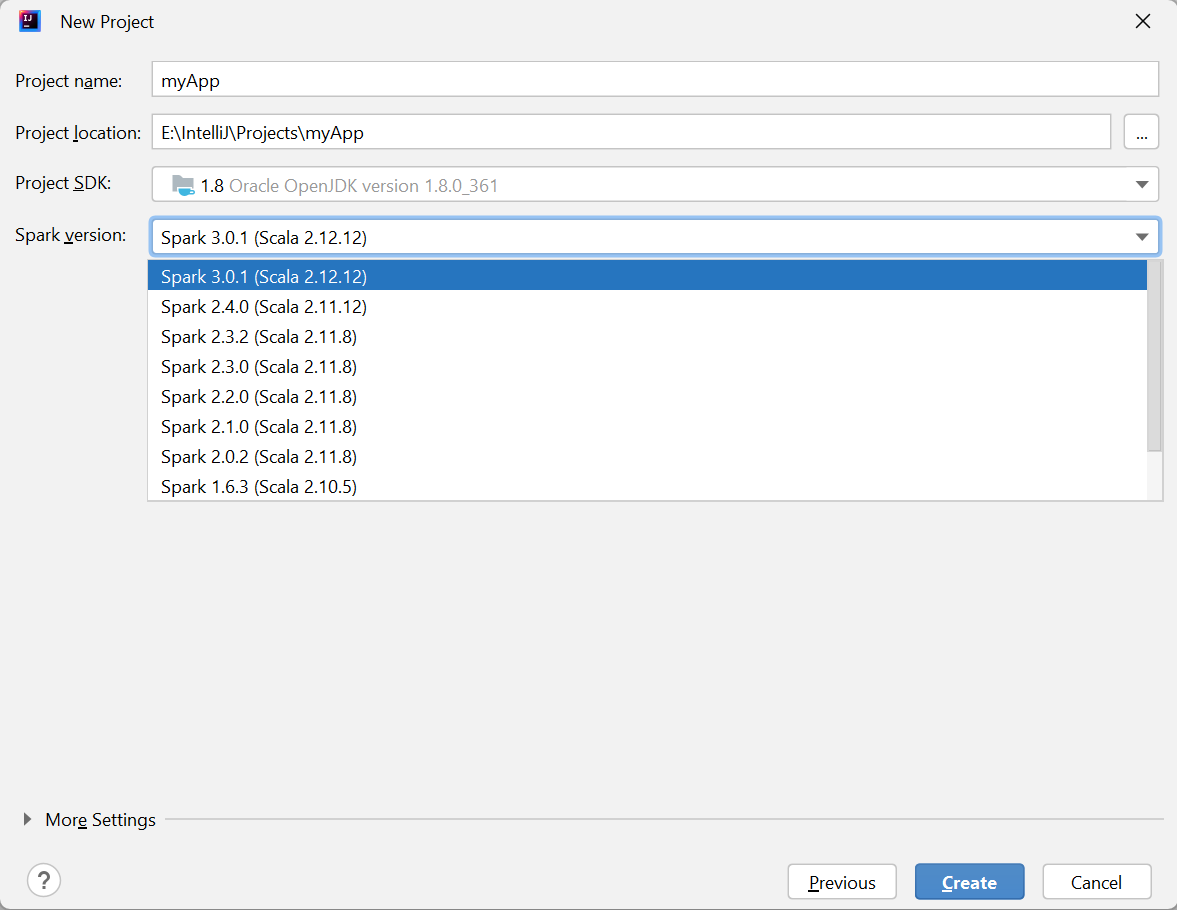
Selecione Concluir. Pode levar alguns minutos antes que o projeto fique disponível.
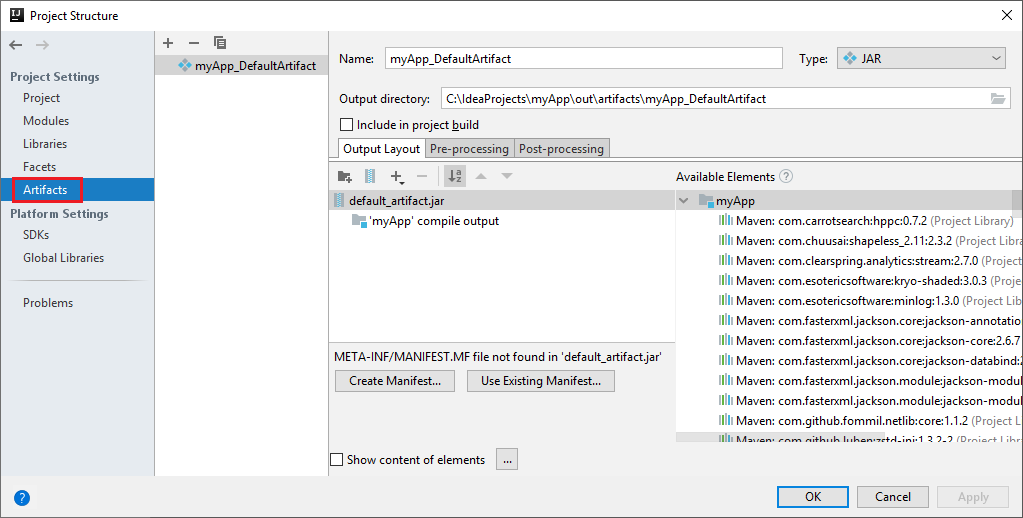
O projeto do Spark cria automaticamente um artefato para você. Para ver o artefato, execute as seguintes operações:
a. Na barra de menus, navegue até Arquivo>Estrutura do projeto... .
b. Na janela Estrutura do Projeto, selecione Artefatos.
c. Selecione Cancelar depois de exibir o artefato.
Localize LogQuery em myApp>src>main>scala>sample>LogQuery. Este tutorial usa LogQuery para executar.
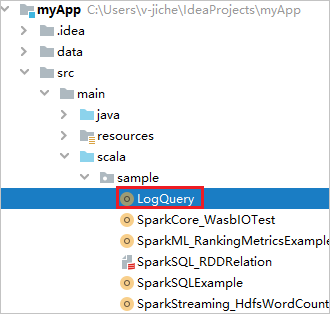
Conectar-se aos seus pools do Spark
Entre na assinatura do Azure para se conectar aos seus pools do Spark.
Entre em sua assinatura do Azure
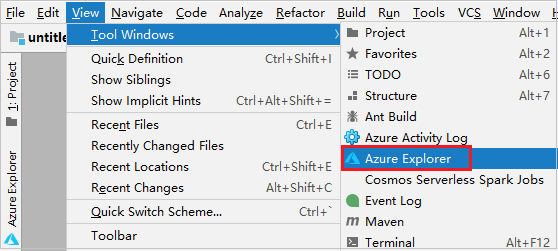
Na barra de menus, navegue até Exibição>Janelas de Ferramentas>Azure Explorer.
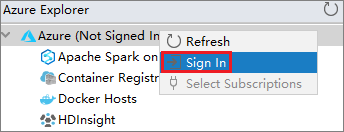
No Azure Explorer, clique com o botão direito do mouse no nó Azure e, em seguida, selecione Entrar.
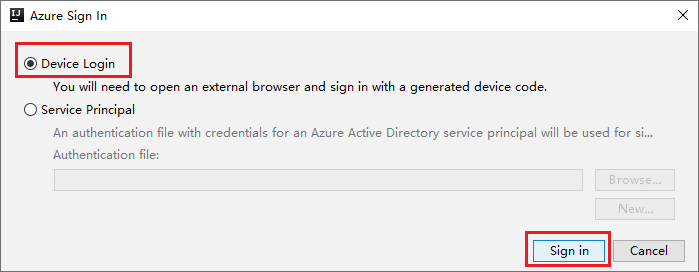
Na caixa de diálogo Entrar no Azure, escolha Logon do Dispositivo e selecione Entrar.
Na caixa de diálogo Logon no Dispositivo do Azure, selecione Copiar e Abrir.
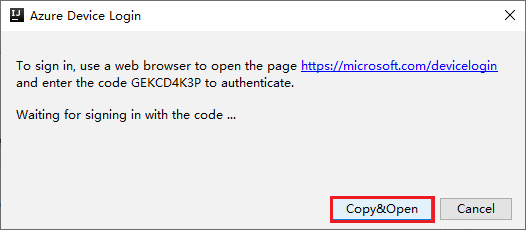
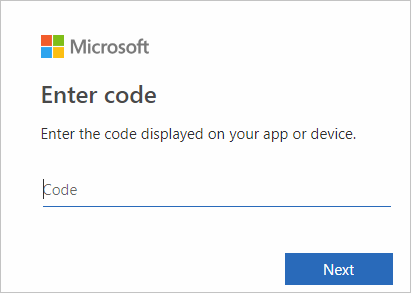
Na interface do navegador, cole o código e selecione Avançar.
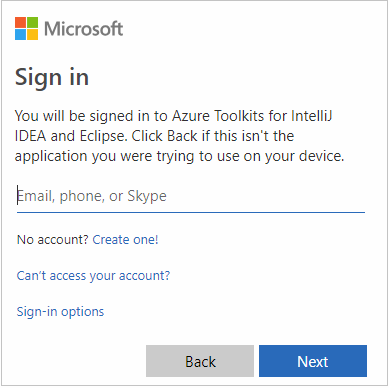
Insira suas credenciais do Azure e feche o navegador.
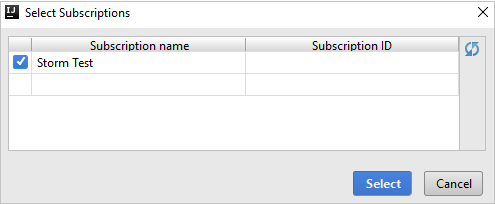
Depois que você estiver conectado, a caixa de diálogo Selecionar Assinaturas listará todas as assinaturas do Azure associadas às credenciais. Selecione sua assinatura e escolha Selecionar.
No Azure Explorer, expanda Apache Spark no Synapse para ver os workspaces que estão em suas assinaturas.
Para ver os pools do Spark, você pode expandir ainda mais um workspace.
Executar remotamente um aplicativo Scala Spark em um Pool do Spark
Depois de criar um aplicativo Scala, você poderá executá-lo remotamente.
Abra a janela Configurações de Execução/Depuração selecionando o ícone.
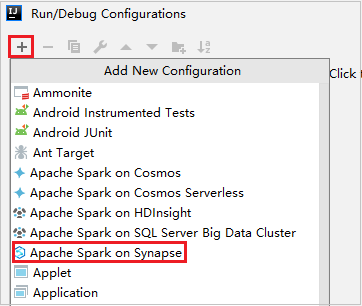
Na janela da caixa de diálogo Configurações de Execução/Depuração, selecione + e escolha Apache Spark no Azure Synapse.
Na janela Configurações de Execução/Depuração, forneça os seguintes valores e, em seguida, selecione OK:
Propriedade Valor Pools do Spark Selecione os pools do Spark nos quais você deseja executar o aplicativo. Selecione um Artefato para enviar Deixe a configuração padrão. Nome da classe principal O valor padrão é a classe principal do arquivo selecionado. Você pode alterar a classe selecionando as reticência ( ... ) e escolhendo outra classe. Configurações de trabalho Você pode alterar os valores e as chaves padrão. Para obter mais informações, confira API REST do Apache Livy. Argumentos de linha de comando Você pode inserir argumentos separados por espaço para a classe principal se necessário. Arquivos Referenciados e Jars Referenciados você pode inserir os caminhos para os Jars e os arquivos referenciados, se houver. Você também pode procurar arquivos no sistema de arquivos virtual do Azure, que atualmente dá suporte apenas ao cluster ADLS Gen2. Para mais informações: Configuração do Apache Spark e Como carregar recursos no cluster. Armazenamento de Upload de Trabalho Expanda para revelar opções adicionais. Tipo de armazenamento Selecione Usar o blob do Azure para carregar ou Usar a conta de armazenamento padrão do cluster para carregar na lista suspensa. Conta de Armazenamento Insira sua conta de armazenamento. Chave de Armazenamento Insira sua chave de armazenamento. Contêiner de armazenamento Selecione seu contêiner de armazenamento na lista suspensa depois que Conta de Armazenamento e Chave de Armazenamento tiverem sido inseridas. 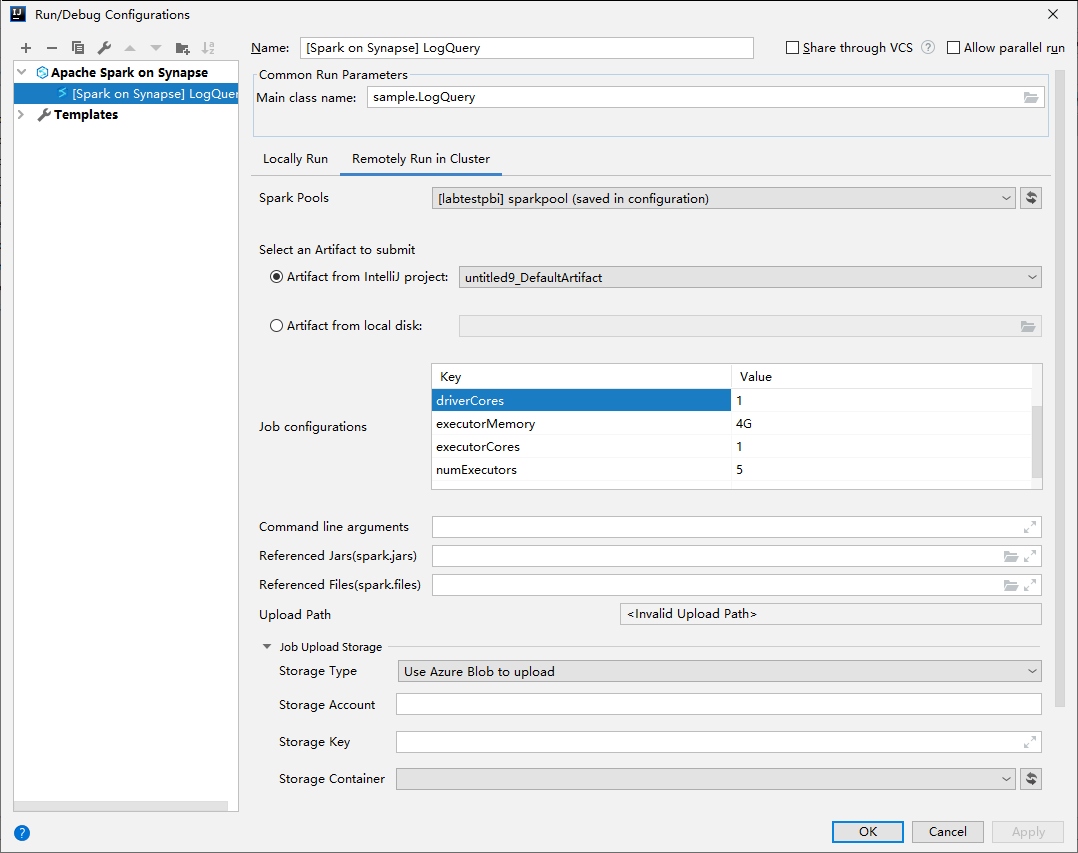
Selecione o ícone SparkJobRun para enviar seu projeto para o Pool do Spark selecionado. A guia Trabalho do Spark Remoto no Cluster exibe o andamento da execução do trabalho na parte inferior. Você pode parar o aplicativo selecionando o botão vermelho.

Depurar/executar localmente aplicativos do Apache Spark
Você pode seguir as instruções abaixo para configurar a execução e a depuração locais para seu trabalho do Apache Spark.
Cenário 1: Fazer execução local
Abra a caixa de diálogo Executar/Depurar Configurações, selecione o sinal de mais (+). Em seguida, selecione a opção Apache Spark no Synapse. Insira as informações em Nome e Nome de classe principal para salvar.
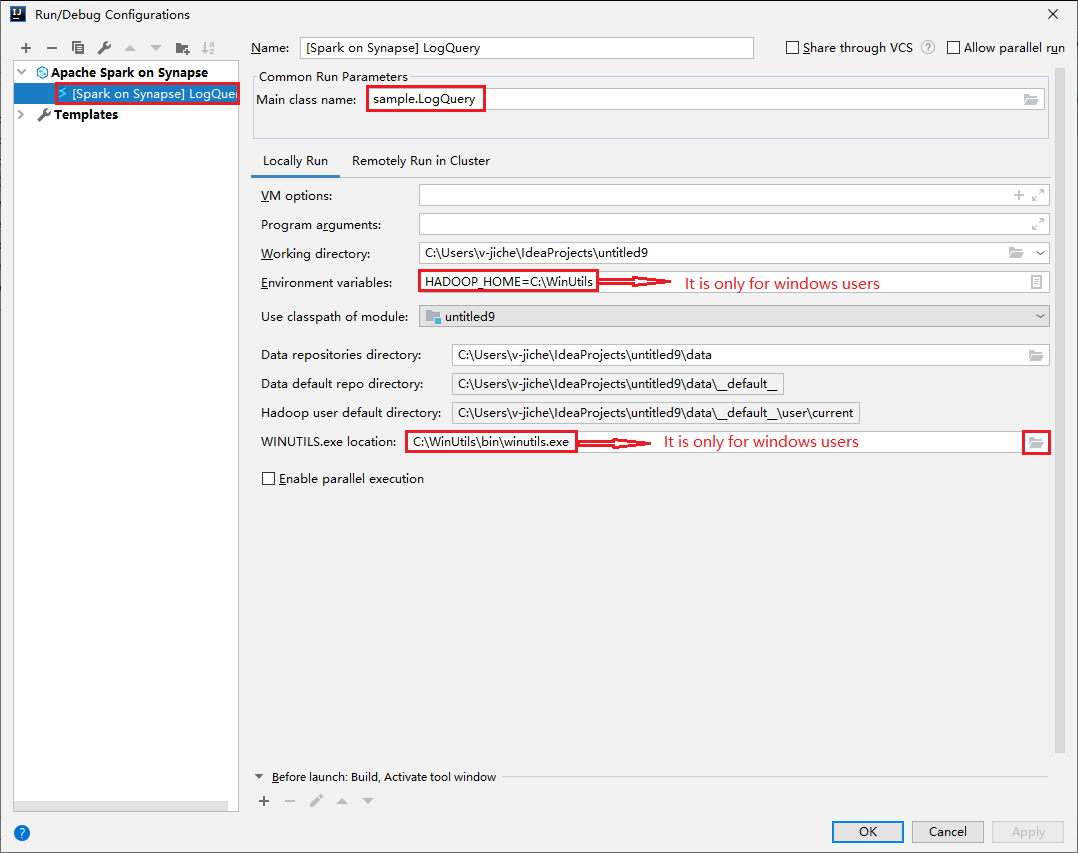
- As variáveis de ambiente e a localização de WinUtils.exe são apenas para usuários do Windows.
- Variáveis de ambiente: A variável de ambiente do sistema poderá ser detectada automaticamente se você a tiver definido antes e não precisar adicioná-la manualmente.
- Local de WinUtils.exe: Você pode especificar a localização de WinUtils selecionando o ícone de pasta à direita.
Depois, selecione o botão de execução local.

Depois que a execução local for concluída, se o script incluir a saída, você poderá verificar o arquivo de saída em data>default.
Cenário 2: fazer depuração local
Abra o script LogQuery e defina pontos de interrupção.
Selecione o ícone Depuração local para fazer esse procedimento.

Acessar e gerenciar o workspace do Synapse
Você pode executar operações diferentes no Azure Explorer no Azure Toolkit for IntelliJ. Na barra de menus, navegue até Exibição>Janelas de Ferramentas>Azure Explorer.
Iniciar o workspace
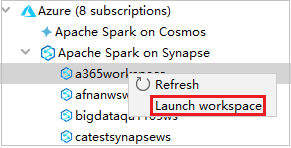
No Azure Explorer, navegue até Apache Spark no Synapse e, em seguida, expanda-o.
Clique com o botão direito do mouse em um workspace e selecione Iniciar workspace. O site será aberto.
Console do Spark
Você pode executar o Console Local do Spark (Scala) ou o Console de Sessão Interativa do Spark Livy (Scala).
Console local do Spark (Scala)
Verifique se você satisfez o pré-requisito do WINUTILS.EXE.
Na barra de menus, navegue até Executar>Editar Configurações... .
Na janela Configurações de Execução/Depuração, no painel esquerdo, navegue até Apache Spark no Synapse>[Spark no Synapse] myApp.
Na janela principal, selecione a guia Executar Localmente.
Forneça os seguintes valores e, em seguida, selecione OK:
Propriedade Valor Variáveis de ambiente Verifique se o valor de HADOOP_HOME está correto. Localização de WINUTILS.exe Verifique se o caminho está correto. 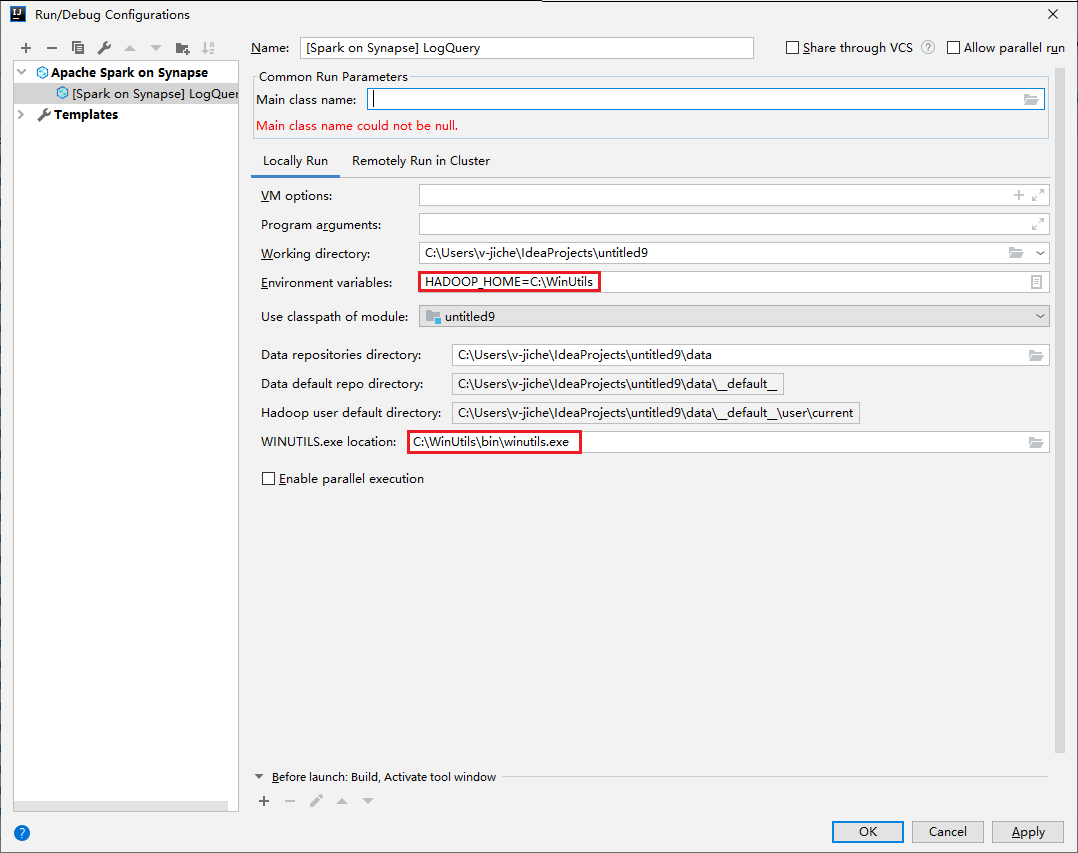
De Projeto, navegue até myApp>src>main>scala>myApp.
Na barra de menus, navegue até Ferramentas>Console do Spark>Executar Console Local do Spark (Scala) .
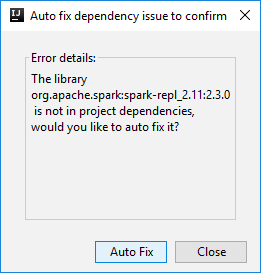
Em seguida, duas caixas de diálogo poderão ser exibidas para perguntar se você deseja corrigir automaticamente as dependências. Em caso afirmativo, selecione Autocorreção.
O console deve ser semelhante à imagem abaixo. Na janela do console, digite
sc.appNamee pressione ENTER. O resultado será exibido. Você pode interromper o console local selecionando o botão vermelho.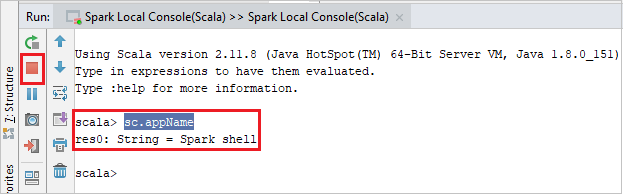
Console de sessão interativa do Spark Livy (Scala)
Ele é compatível apenas com o IntelliJ 2018.2 e 2018.3.
Na barra de menus, navegue até Executar>Editar Configurações... .
Na janela Configurações de Execução/Depuração, no painel esquerdo, navegue até Apache Spark no Synapse>[Spark no Synapse] myApp.
Na janela principal, selecione a guia Executar Remotamente no Cluster.
Forneça os seguintes valores e, em seguida, selecione OK:
Propriedade Valor Nome da classe principal Selecione o nome de classe Main. Pools do Spark Selecione os pools do Spark nos quais você deseja executar o aplicativo. 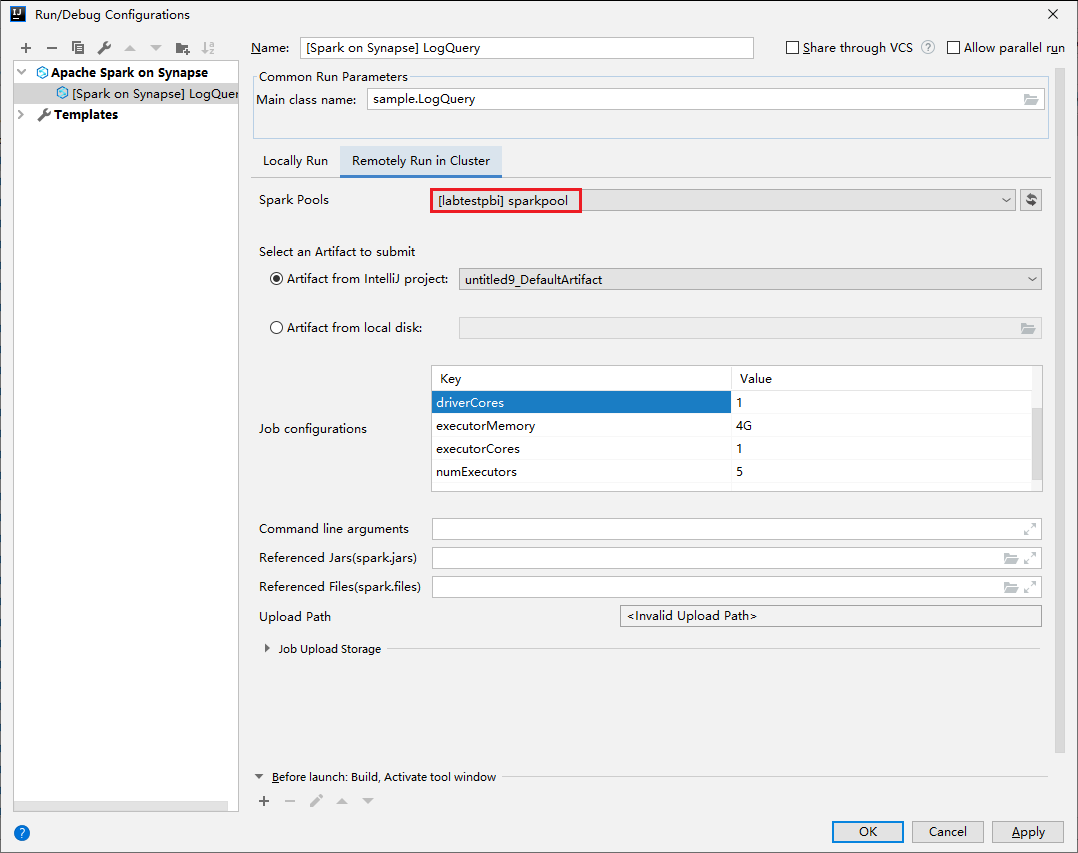
De Projeto, navegue até myApp>src>main>scala>myApp.
Na barra de menus, navegue até Ferramentas>Console do Spark>Executar Console de Sessão Interativa do Spark Livy (Scala) .
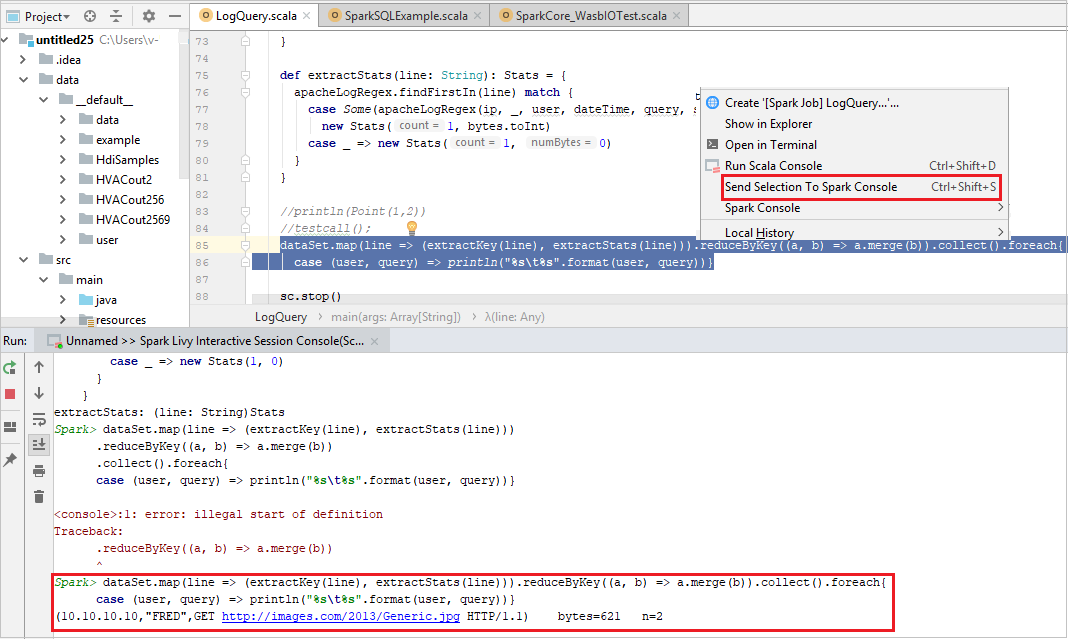
O console deve ser semelhante à imagem abaixo. Na janela do console, digite
sc.appNamee pressione ENTER. O resultado será exibido. Você pode interromper o console local selecionando o botão vermelho.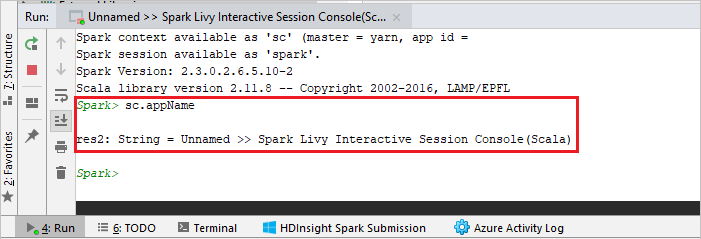
Enviar seleção ao console do Spark
Talvez você queira ver o resultado do script enviando código ao console local ou ao Console de Sessão Interativa do Livy (Scala). Para fazer isso, você pode realçar o código no arquivo do Scala e clicar com o botão direito do mouse em Enviar Seleção ao Console do Spark. O código selecionado será enviado para o console e será executado. O resultado será exibido após o código no console. O console verificará os erros existentes.