Conector do Pool de SQL Dedicado do Azure Synapse para Apache Spark
Introdução
O conector do pool de SQL dedicado do Azure Synapse para Apache Spark no Azure Synapse Analytics permite a transferência eficiente de grandes conjuntos de dados entre o runtime do Apache Spark e o Pool de SQL dedicado. O conector é enviado como uma biblioteca padrão com o Workspace do Azure Synapse. O conector é implementado usando a linguagem Scala. O conector é compatível com Scala e Python. Para usar o Conector com outras opções de idioma do notebook, use o comando magic do Spark %%spark.
Em geral, o conector fornece as seguintes funcionalidades:
- Ler no Pool de SQL Dedicado do Azure Synapse:
- Leia grandes conjuntos de dados de Tabelas do Pool de SQL Dedicado do Synapse (internas e externas) e exibições.
- Suporte abrangente ao empilhamento de predicado, em que os filtros no DataFrame são mapeados para o empilhamento de predicado do SQL correspondente.
- Suporte para remoção de coluna.
- Suporte para push de consulta.
- Gravar no Pool de SQL Dedicado do Azure Synapse:
- Ingerir dados com grande volume para tipos de tabela interno e externo.
- Dá suporte às seguintes preferências de modo de salvamento do DataFrame:
AppendErrorIfExistsIgnoreOverwrite
- O tipo de gravação na tabela externa dá suporte ao formato de arquivo Parquet ou de texto delimitado (exemplo – CSV).
- Para gravar dados em tabelas internas, o conector agora usa instrução COPY em vez da abordagem CETAS/CTAS.
- Aprimoramentos para otimizar o desempenho da taxa de transferência de gravação de ponta a ponta.
- Introduz um identificador de retorno de chamada opcional (um argumento da função do Scala) que os clientes podem usar para receber métricas pós-gravação.
- Alguns exemplos incluem o número de registros, a duração para concluir uma determinada ação e o motivo da falha.
Abordagem de orquestração
Ler
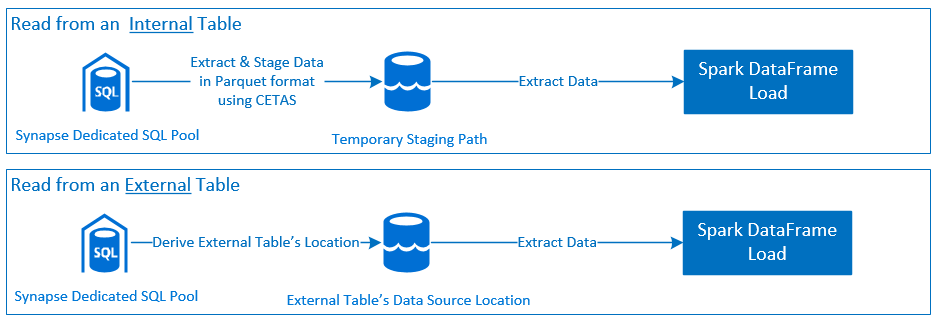
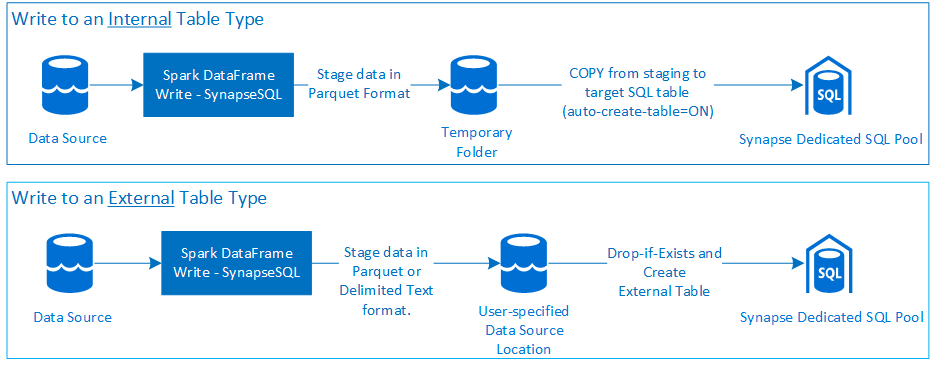
Gravar
Pré-requisitos
Os pré-requisitos, como a configuração dos recursos necessários do Azure e as etapas para configurá-los, são discutidos nesta seção.
Recursos do Azure
Examine e configure os seguintes Recursos do Azure dependentes:
- Azure Data Lake Storage – usado como a conta de armazenamento primária para o workspace do Azure Synapse.
- Workspace do Azure Synapse – crie notebooks, e crie e implante fluxos de trabalho de entrada e saída baseados em DataFrame.
- Pool de SQL Dedicado (anteriormente SQL DW) – fornece recursos corporativos de Data Warehousing.
- Pool do Spark sem Servidor do Azure Synapse – runtime do Spark em que os trabalhos são executados como aplicativos Spark.
Preparar o banco de dados
Conecte o banco de dados do Pool de SQL Dedicado do Azure Synapse e execute as seguintes instruções de configuração:
Crie um usuário de banco de dados mapeado para a Identidade do usuário do Microsoft Entra usada para entrar no Workspace do Azure Synapse.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Crie o esquema no qual as tabelas serão definidas, de modo que o Conector possa gravar e ler com êxito as respectivas tabelas.
CREATE SCHEMA [<schema_name>];
Autenticação
Autenticação baseada na ID do Microsoft Entra
A autenticação baseada na ID do Microsoft Entra é uma abordagem de autenticação integrada. O usuário precisa fazer se conectar no workspace do Azure Synapse Analytics.
Autenticação Básica
A abordagem de autenticação básica exige que o usuário configure as opções username e password. Confira a seção Opções de configuração para saber mais sobre os parâmetros de configuração relevantes para leitura e gravação em tabelas no Pool de SQL Dedicado do Azure Synapse.
Autorização
Azure Data Lake Storage Gen2
Há duas maneiras de conceder permissões de acesso ao Azure Data Lake Storage Gen2 – Conta de armazenamento:
- Função de controle de acesso baseado em função – Função de colaborador de dados do blob de armazenamento
- Atribuir
Storage Blob Data Contributor Roleconcede às permissões de usuário de leitura, gravação e exclusão dos contêineres do Azure Storage Blob. - O RBAC oferece uma abordagem de controle de alta granularidade no nível do contêiner.
- Atribuir
- ACL (Listas de Controle de Acesso)
- A abordagem de ACL permite controles com baixa granularidade sobre caminhos e/ou arquivos específicos em uma determinada pasta.
- As verificações de ACL não são impostas se o usuário já tiver concedido permissões usando a abordagem RBAC.
- Há dois tipos abrangentes de permissões de ACL:
- Permissões de acesso (aplicadas em um nível ou objeto específico).
- Permissões padrão (aplicadas automaticamente a todos os objetos filho no momento da criação).
- Os tipos de permissões incluem:
Executehabilita a capacidade de percorrer ou navegar pelas hierarquias de pasta.Readhabilita a capacidade de leitura.Writehabilita a capacidade de gravação.
- É importante configurar as ACLs para que o conector possa gravar e ler com êxito nos locais de armazenamento.
Observação
Se você quiser executar notebooks usando pipelines do Workspace do Synapse, também precisará conceder as permissões de acesso listadas acima para a identidade gerenciada padrão do Workspace do Synapse. O nome da identidade gerenciada padrão do workspace é o mesmo do workspace.
Para usar o workspace do Synapse com contas de armazenamento protegidas, um ponto de extremidade privado gerenciado precisará ser configurado no notebook. O ponto de extremidade privado gerenciado precisa ser aprovado na seção
Private endpoint connectionsda conta de armazenamento do ADLS Gen2 no painelNetworking.
Pool de SQL Dedicado do Azure Synapse
Para habilitar a interação com êxito com o pool de SQL dedicado do Azure Synapse, a seguinte autorização será necessária, exceto se você for um usuário também configurado como um Active Directory Admin no Ponto de Extremidade do SQL Dedicado:
Cenário de leitura
Conceda ao usuário
db_exporterusando o procedimento armazenado do sistemasp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Cenário de gravação
- O conector usa o comando COPY para gravar dados de preparação na localização gerenciada da tabela interna.
Configure as permissões necessárias descritas aqui.
Veja abaixo um snippet de acesso rápido do mesmo:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- O conector usa o comando COPY para gravar dados de preparação na localização gerenciada da tabela interna.
Documentação da API
Conector do Pool de SQL Dedicado do Azure Synapse para Apache Spark – Documentação da API.
Opções de configuração
Para inicializar e orquestrar com êxito a operação de leitura ou gravação, o Conector espera determinados parâmetros de configuração. A definição de objeto - com.microsoft.spark.sqlanalytics.utils.Constants fornece uma lista de constantes padronizadas para cada chave de parâmetro.
Veja abaixo a lista de opções de configuração com base no cenário de uso:
- Leitura usando a autenticação baseada na ID do Microsoft Entra
- As credenciais são mapeadas automaticamente e o usuário não precisará fornecer as opções de configuração específicas.
- O argumento de nome de tabela de três partes no método
synapsesqlé necessário para ler a tabela respectiva no pool de SQL dedicado do Azure Synapse.
- Ler usando a Autenticação Básica
- Ponto de Extremidade do SQL dedicado do Azure Synapse
Constants.SERVER: ponto de extremidade do Pool do SQL Dedicado do Azure Synapse (FQDN do servidor)Constants.USERSQL_USER_NAME.Constants.PASSWORD: senha de usuário SQL.
- Ponto de Extremidade Azure Data Lake Storage (Gen 2): pastas de preparo
Constants.DATA_SOURCE: o caminho do armazenamento definido no parâmetro de localização da fonte de dados é usado para o preparo de dados.
- Ponto de Extremidade do SQL dedicado do Azure Synapse
- Gravar usando a autenticação baseada na ID do Microsoft Entra
- Ponto de Extremidade do SQL dedicado do Azure Synapse
- Por padrão, o Conector infere o ponto de extremidade SQL dedicado do Synapse usando o conjunto de nomes de banco de dados no parâmetro de nome da tabela de três partes do método
synapsesql. - Como alternativa, os usuários podem usar a opção
Constants.SERVERpara especificar o ponto de extremidade do SQL. Verifique se o ponto de extremidade hospeda o banco de dados correspondente com o respectivo esquema.
- Por padrão, o Conector infere o ponto de extremidade SQL dedicado do Synapse usando o conjunto de nomes de banco de dados no parâmetro de nome da tabela de três partes do método
- Ponto de Extremidade Azure Data Lake Storage (Gen 2): pastas de preparo
- Para o tipo de tabela interna:
- Configure a opção
Constants.TEMP_FOLDERouConstants.DATA_SOURCE. - Se o usuário escolher fornecer a opção
Constants.DATA_SOURCE, a pasta de preparo será derivada com o uso do valorlocationde DataSource. - Se ambas forem fornecidas, o valor da opção
Constants.TEMP_FOLDERserá usado. - Na ausência de uma opção de pasta de preparo, o Conector derivará uma com base na configuração de runtime
spark.sqlanalyticsconnector.stagingdir.prefix.
- Configure a opção
- Para o tipo de tabela externa:
Constants.DATA_SOURCEé uma opção de configuração necessária.- O conector usa o caminho de armazenamento definido no parâmetro de localização da fonte de dados em combinação com o argumento
locationpara o métodosynapsesqle deriva o caminho absoluto para persistir dados de tabela externa. - Se o argumento
locationpara o métodosynapsesqlnão for especificado, o conector derivará o valor da localização como<base_path>/dbName/schemaName/tableName.
- Para o tipo de tabela interna:
- Ponto de Extremidade do SQL dedicado do Azure Synapse
- Gravar usando a Autenticação Básica
- Ponto de Extremidade do SQL dedicado do Azure Synapse
Constants.SERVER: ponto de extremidade do Pool do SQL Dedicado do Azure Synapse (FQDN do servidor).Constants.USERSQL_USER_NAME.Constants.PASSWORD: senha de usuário SQL.Constants.STAGING_STORAGE_ACCOUNT_KEYassociado à Conta de Armazenamento que hospedaConstants.TEMP_FOLDERS(somente tipos de tabela interna) ouConstants.DATA_SOURCE.
- Ponto de Extremidade Azure Data Lake Storage (Gen 2): pastas de preparo
- As credenciais de autenticação básica do SQL não se aplicam a pontos de extremidade de armazenamento de acesso.
- Ou seja, atribua permissões de acesso de armazenamento pertinentes conforme descrito na seção Azure Data Lake Storage Gen2.
- Ponto de Extremidade do SQL dedicado do Azure Synapse
Modelos de código
Esta seção apresenta modelos de código de referência para descrever como usar e invocar o Conector do Pool de SQL Dedicado do Azure Synapse para Apache Spark.
Observação
Como usar o conector no Python
- O conector tem suporte apenas no Python para Spark 3. No Spark 2.4 (sem suporte), podemos usar a API do conector Scala para interagir com o conteúdo de um DataFrame no PySpark usando DataFrame.createOrReplaceTempView ou DataFrame.createOrReplaceGlobalTempView. Veja a seção Usando dados materializados entre células.
- O identificador de chamada de volta não está disponível no Python.
Ler do pool de SQL dedicado do Azure Synapse
Solicitação de gravação: assinatura de leitura synapsesql
Ler de uma tabela usando a autenticação baseada na ID do Microsoft Entra
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Ler de uma consulta usando a autenticação baseada na ID do Microsoft Entra
Observação
Restrições ao ler da consulta:
- O nome da tabela e a consulta não podem ser especificados ao mesmo tempo.
- Somente consultas selecionadas são permitidas. SQLs DDL e DML não são permitidos.
- As opções de seleção e filtro no dataframe não são enviadas por push para o pool dedicado do SQL quando uma consulta é especificada.
- A leitura de uma consulta só está disponível no Spark 3.1 e 3.2.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Ler de uma tabela usando a autenticação básica
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Ler de uma consulta usando a autenticação básica
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Gravar no pool de SQL dedicado do Azure Synapse
Solicitação de gravação: assinatura de método synapsesql
A assinatura do método da versão do Conector criada para Spark 2.4.8 tem um argumento a menos do que o aplicado na versão do Spark 3.1.2. Veja abaixo as duas assinaturas de método:
- Pool do Spark versão 2.4.8
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None):Unit
- Pool do Spark versão 3.1.2
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Gravar usando a autenticação baseada na ID do Microsoft Entra
Abaixo está um modelo de código abrangente descreve como usar o Conector para cenários de gravação:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Gravar usando a Autenticação Básica
O snippet de código a seguir substitui a definição de gravação descrita na seção Gravar usando a autenticação baseada na ID do Microsoft Entra, para enviar a solicitação de gravação usando a abordagem de autenticação básica do SQL:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
Em uma abordagem de autenticação básica, para ler dados de um caminho de armazenamento de origem, outras opções de configuração serão necessárias. O seguinte snippet de código fornece um exemplo para ler de uma fonte de dados do Azure Data Lake Storage Gen2 usando as credenciais da Entidade de Serviço:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Modos de salvamento do DataFrame com suporte
Há suporte aos seguintes modos de salvamento ao gravar dados de origem em uma tabela de destino no pool de SQL dedicado do Azure Synapse:
- ErrorIfExists (modo de salvamento padrão)
- Se a tabela de destino existir, a gravação será anulada com uma exceção retornada ao receptor. Caso contrário, uma tabela será criada com os dados das pastas de preparo.
- Ignorar
- Se a tabela de destino existir, a gravação vai ignorar a solicitação de gravação sem retornar um erro. Caso contrário, uma tabela será criada com os dados das pastas de preparo.
- Overwrite
- Se a tabela de destino existir, os dados existentes no destino serão substituídos pelos dados das pastas de preparo. Caso contrário, uma tabela será criada com os dados das pastas de preparo.
- Acrescentar
- Se a tabela de destino existir, os novos dados serão acrescentados a ela. Caso contrário, uma tabela será criada com os dados das pastas de preparo.
Gravar identificador de retorno de chamada de solicitação
As novas alterações da API do caminho de gravação apresentaram um recurso experimental para fornecer ao cliente um mapa de chave/valor das métricas de pós-gravação. As chaves para as métricas são definidas na nova definição de objeto - Constants.FeedbackConstants. As métricas podem ser recuperadas como uma cadeia de caracteres JSON passando o identificador de retorno de chamada (uma Scala Function). Abaixo há uma assinatura de função:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
A seguir estão algumas métricas notáveis (apresentadas em letras concatenadas):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Veja abaixo uma cadeia de caracteres JSON de exemplo com métricas de pós-gravação:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Mais exemplos de código
Usando dados materializados entre células
O createOrReplaceTempView do Spark DataFrame poderá ser usado para acessar dados obtidos em outra célula registrando uma exibição temporária.
- Célula onde os dados efetuam fetch (por exemplo, com preferência de linguagem do Notebook como
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Agora, altere a preferência de linguagem no Notebook para
PySpark (Python)e efetue fetch de dados da exibição registrada<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Tratamento de resposta
A invocação de synapsesql tem dois estados finais possíveis : êxito ou com falha. Esta seção descreve como tratar a resposta da solicitação de cada cenário.
Ler a resposta da solicitação
Após a conclusão, o snippet de resposta de leitura será exibido na saída da célula. A falha na célula atual também cancelará as execuções de células subsequentes. As informações detalhadas de erros estarão disponíveis nos Logs do Aplicativo Spark.
Gravar a resposta da solicitação
Por padrão, uma resposta de gravação é impressa na saída da célula. Em caso de falha, a célula atual será marcada como com falha e as execuções de células subsequentes serão anuladas. A outra abordagem é passar a opção identificador de retorno de chamada para o método synapsesql. O identificador de retorno de chamada fornecerá acesso programático à resposta de gravação.
Outras considerações
- Ao ler as tabelas do Pool de SQL Dedicado do Azure Synapse:
- Considere aplicar os filtros necessários no DataFrame para aproveitar o recurso de remoção de coluna do Conector.
- O cenário de leitura não dá suporte à cláusula
TOP(n-rows)ao enquadrar as instruções de consultaSELECT. A opção para limitar os dados é usar a cláusula limit(.) do DataFrame.- Confira a seção de exemplo Usando dados materializados entre células.
- Ao gravar em tabelas do pool de SQL dedicado do Azure Synapse:
- Para tipos de tabela interna:
- As tabelas são criadas com distribuição de dados ROUND_ROBIN.
- Os tipos de coluna são inferidos do DataFrame que lê os dados da origem. As colunas de cadeia de caracteres são mapeadas para
NVARCHAR(4000).
- Para os tipos de tabelas externas:
- O paralelismo inicial do DataFrame orienta a organização dos dados para a tabela externa.
- Os tipos de coluna são inferidos do DataFrame que lê os dados da origem.
- Uma melhor distribuição de dados entre os executores poderá ser obtida ajustando
spark.sql.files.maxPartitionBytese o parâmetrorepartitiondo DataFrame. - Ao gravar grandes conjuntos de dados, é importante considerar o impacto da configuração do Nível de desempenho de DWU que limita o tamanho da transação.
- Para tipos de tabela interna:
- Monitore as tendências de utilização do Azure Data Lake Storage Gen2 para detectar os comportamentos de limitação que podem afetar o desempenho de leitura e gravação.