Como a Microsoft opera sistemas confiáveis com o DevOps
A Microsoft tem operado plataformas online complexas desde os primórdios da internet comercial. Ao longo do caminho, evoluímos um conjunto substancial de práticas para manter os sistemas disponíveis, íntegros e seguros. Essas práticas fazem parte de uma iniciativa maior para manter e melhorar uma cultura de site ativo.
Cultura de site ativo
A cultura de site ativo é o foco de uma organização para priorizar a experiência e a confiabilidade do site ativo sobre os demais aspectos. Afinal, os clientes podem se mover entre provedores de serviços com facilidade hoje com os serviços baseados em nuvem e na internet, ampliando a importância da confiança do cliente. O site ativo deve estar sempre disponível e funcionar conforme prometido aos clientes.
Existem vários fatores que contribuem para uma cultura de site ativo bem-sucedida.
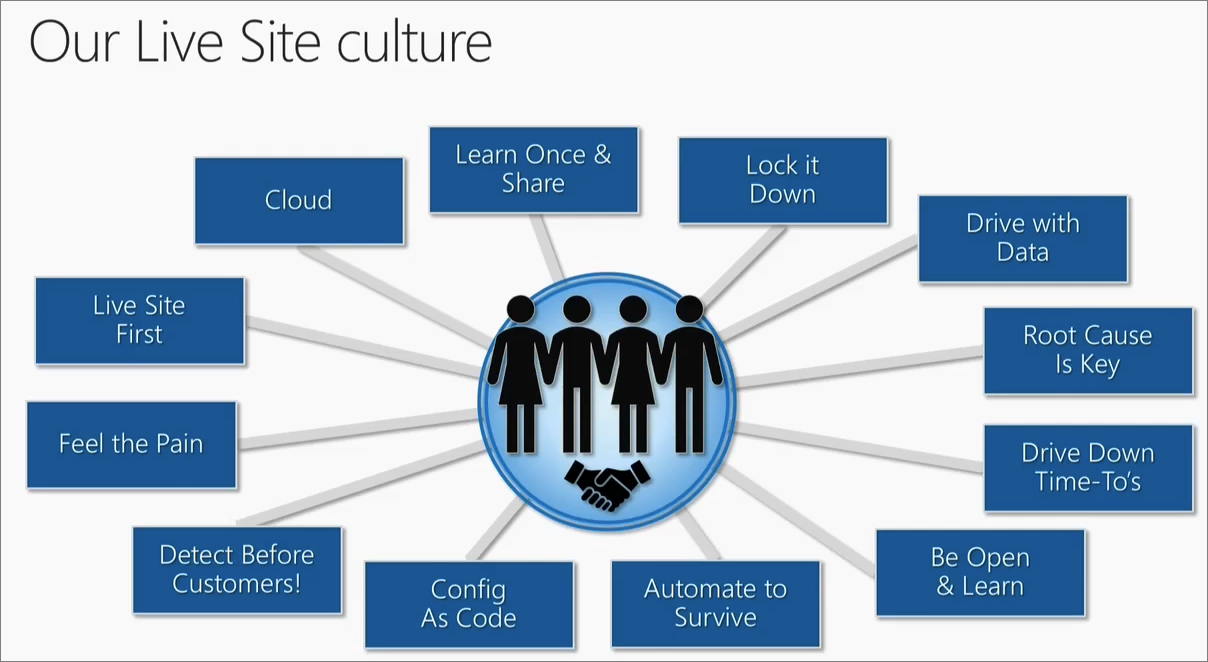
Site ativo em primeiro lugar
Priorizar a experiência do site ativo é essencial para o sucesso de uma plataforma. As equipes não podem concentrar o foco em recursos novos e atraentes e desconsiderar o caminho em que esses recursos são apresentados aos usuários. Contamos com práticas de implantação seguras que ajudam a garantir que nossos clientes tenham acesso ininterrupto à plataforma. Isso pode ser complicado quando é preciso liberar atualizações de serviço com controle de versão sem tempo de inatividade.
Controle da exposição por meio de sinalizadores de recursos
À medida que passamos da fase embrionária da implantação, controlando a exposição com sinalizadores de recursos, ocasionalmente descobrimos um problema na produção. Apesar de toda a nossa automação e revisões, às vezes ainda temos problemas. Como dizem, não existe lugar melhor do que a produção!
Em geral, o monitoramento de integridade e a telemetria nos alertam quando algo não está certo. Um desenvolvedor pode criar uma ramificação main, fazer uma correção e fazer uma solicitação de pull main. Manter o mesmo fluxo de trabalho geral significa que os desenvolvedores não precisam alternar o contexto ou aprender um processo distinto para uma alteração de código distinta.
Para resolver uma implantação de hotfix, é necessária mais uma etapa: escolher a alteração na ramificação de versão. Executamos uma implantação de hotfix fora da ramificação da versão atual todos os dias úteis pela manhã, mas também podemos fazer isso sob demanda para correções urgentes. A correção, na verdade, atinge primeiro a produção fora da ramificação de lançamento. Mas como desenvolvemos primeiro main, sabemos que ele não regredirá no próximo sprint quando uma nova ramificação de lançamento for criada a partir de main.
Os lançamentos de produtos locais são basicamente os mesmos, embora sem a fase embrionária de implantação. Além disso, como fazemos mais testes manuais em configurações e formas de dados variadas, há um intervalo maior entre a ramificação de lançamento e o momento em que o produto chega às mãos dos clientes.
Deve-se cuidar pessoalmente da segurança
O foco é tornar as vulnerabilidades reais e pessoais. Essa é uma garantia de que as pessoas realmente se importem. Também fazemos amplo uso de jogos de guerra para encontrar e abordar riscos de segurança em todo o sistema, em código ou não. Quando a equipe de socorro pode mostrar que obteve o código ao revirar uma caixa de diálogo, isso realmente motiva o proprietário do código a resolver o problema e garantir que ele não ocorra novamente em nenhum outro lugar. Esse tipo de competição é muito mais real e pessoal do que uma análise estática, alertando sobre um risco potencial de XSS. Criamos esse tipo de cultura e dinâmica por meio de jogos de guerra e outros exercícios de segurança. As pessoas se orgulham de invadir o código umas das outras ou de conseguir bloquear as tentativas. Isso inspira uma cultura de código seguro.
Não podemos prever todos os vetores de ataque, mas podemos supor que haverá uma violação e planejar uma reação rápida a essa violação. Grande parte do trabalho de segurança gira em torno disso para nossas equipes.
Finalmente, os seres humanos cometem erros. Às vezes, por preguiça, fazem coisas como armazenar senhas em compartilhamentos de arquivos. Podemos aconselhar que não façam isso, enviá-los para treinamentos em segurança e adotar medidas. A maioria das pessoas aprende, mas basta a ação de uma pessoa para desestabilizar o sistema. Você pode ter diferentes tipos de listas de melhores práticas, mas a menos que esteja tornando isso real, precisa supor que as pessoas cometerão erros. Isso requer um certo nível de supervisão para garantir que processos críticos sejam seguidos.
A engenharia é mais do que um parceiro de operações
Aprendemos desde cedo a tornar o local ativo uma parte importante das responsabilidades da equipe de engenharia. Essa foi uma noção importante para nós porque, antes, uma pessoa podia implantar algo, folgar no fim de semana e, ao voltar na segunda-feira, deparar-se com 900 problemas de clientes que foram tratados durante o fim de semana inteiro pelo atendimento ao cliente e por equipes de operações. É importante que a engenharia pague o preço por problemas no local ativo. Caso contrário, não há incentivo para criar sistemas que evitem esses problemas. Quando for chamado às 2h da manhã para consertar algo que quebrou, você se lembrará disso.
À medida que desenvolvemos essa responsabilidade, o site ativo é nosso item mais importante e se torna o mantra da equipe inteira. Trata-se da experiência do cliente que eles têm agora e não um mero imposto. Na verdade, as pessoas contam conosco para oferecê-lo e nos orgulhamos disso. Esse precisa ser um diferencial do nosso produto.
A telemetria de produção é a pulsação do seu serviço
Para sobreviver no mundo acelerado, onde praticamente tudo pode dar errado, precisamos de ótimos sistemas de alerta. Alertas não acionáveis, alertas redundantes ou volumes de alertas excessivos levam você a ignorar todos os alertas. É fácil criar muitos alertas; então, o processo realmente se resume a uma pergunta simples: esse alerta é acionável? Isso garante que estamos nos envolvendo com os problemas dos clientes certos e tratando-os o mais rápido possível.
À medida que a equipe de engenharia se concentrava em alertas acionáveis, eles notaram que muitos problemas que surgem, especialmente no meio da noite, tendem a ter correções semelhantes, pelo menos temporariamente. Isso resultou no foco em sistemas que se destacavam em failover e autorrecuperação. Agora os problemas surgem, geram alertas e se corrigem o suficiente para que a equipe de engenharia aguarde até de manhã para correção. Isso não teria acontecido se a equipe de engenharia apenas adiasse partes que mantinham outras pessoas acordadas à noite. Agora, eles trabalham para equilibrar essas melhorias como parte não apenas do ritmo acelerado do recurso, mas também da velocidade de melhoria da engenharia.
Resumo
A adoção de uma cultura de site ativo afetou a maneira como a Microsoft cria e fornece software. Ao tornar as equipes de engenharia uma parte fundamental da segurança e das operações, a qualidade do nosso código e a experiência do usuário final melhoraram significativamente. Ser um participante pleno nas operações tornou a engenharia um stakeholder fundamental, resultando em sistemas que são projetados para operações melhores.