Como criar uma definição de trabalho do Apache Spark no Fabric
Neste tutorial, saiba como criar uma definição de trabalho do Spark no Microsoft Fabric.
Pré-requisitos
Antes de começar, você precisa do:
- Uma conta de locatário do Fabric com uma assinatura ativa. Crie uma conta gratuitamente.
Dica
Para executar o item de definição de trabalho do Spark, você deve ter um arquivo de definição principal e o contexto padrão do lakehouse. Se você não tiver um lakehouse, poderá criar um seguindo as etapas em Criar um lakehouse.
Criar uma definição de trabalho do Spark
O processo de criação de definição de trabalho do Spark é rápido e simples; há várias maneiras de começar.
Opções para criar uma definição de trabalho do Spark
Há algumas maneiras de iniciar o processo de criação:
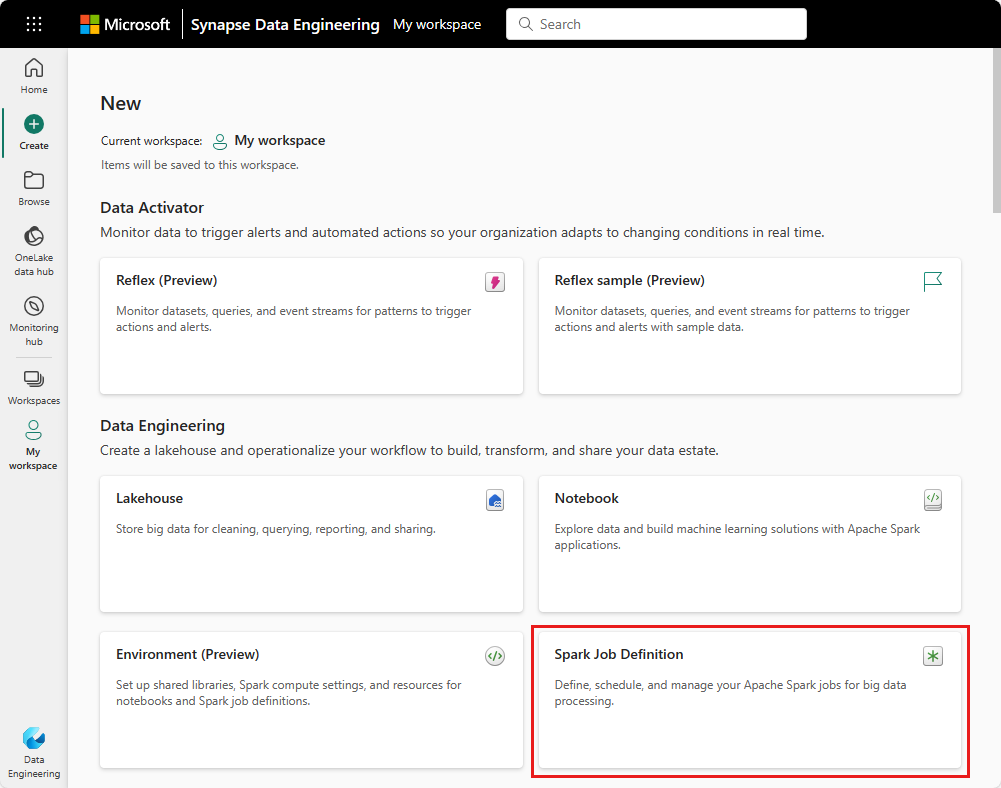
Home page de engenharia de dados: você pode criar facilmente uma definição de trabalho do Spark por meio do cartão Definição de trabalho do Spark na seção Novo na home page.
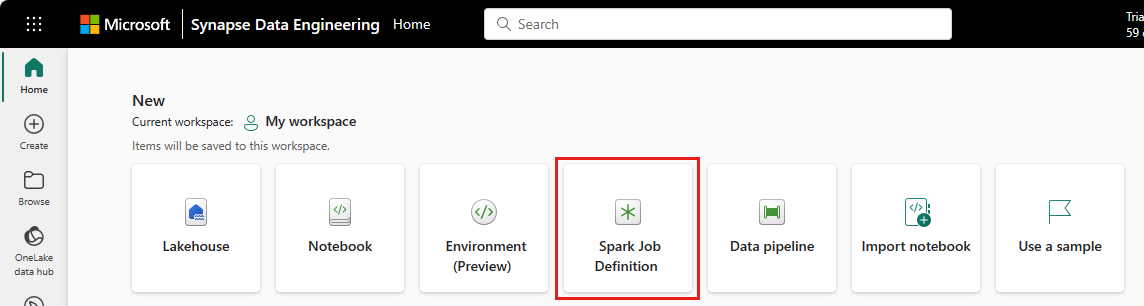
Modo de exibição do workspace: você também pode criar uma definição de trabalho do Spark por meio do modo de exibição Workspace em Engenharia de dados usando o menu suspenso Novo.
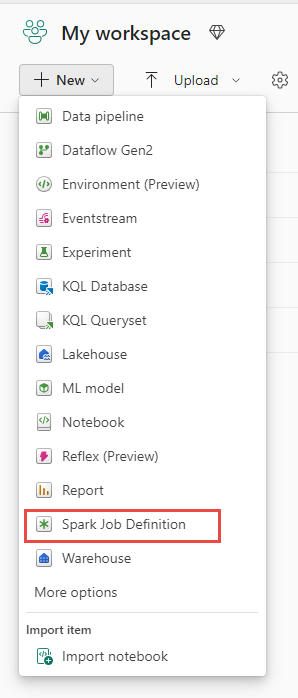
Criar exibição: outro ponto de entrada para criar uma definição de trabalho do Spark é a página Criar em Engenharia de dados.
Você precisa dar um nome à definição de trabalho do Spark ao criá-la. O nome deve ser exclusivo no workspace atual. A nova definição de trabalho do Spark é criada em seu workspace atual.
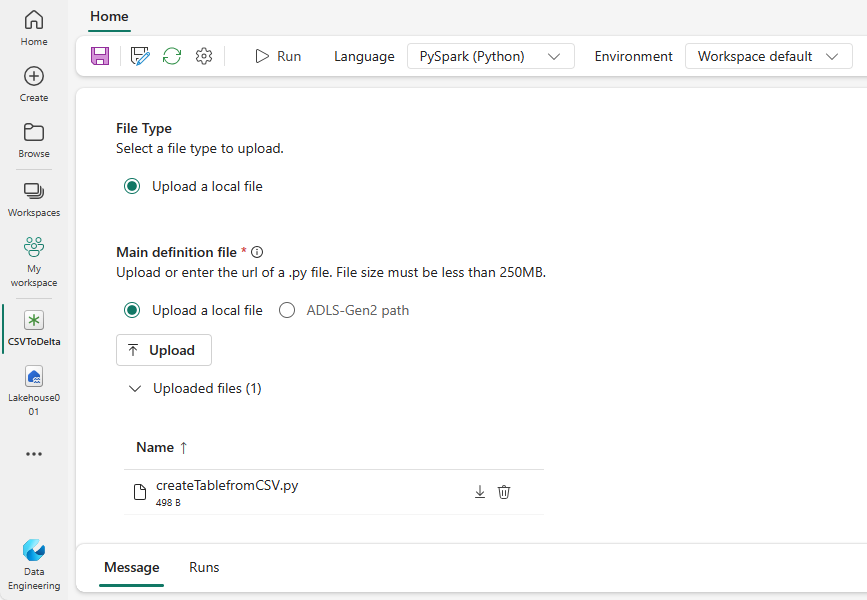
Criar uma definição de trabalho do Spark para PySpark (Python)
Para criar uma definição de trabalho do Spark para o PySpark:
Baixe o arquivo Parquet de exemplo yellow_tripdata_2022-01.parquet e carregue-o na seção de arquivos do lakehouse.
Crie uma nova definição de trabalho do Spark.
Selecione PySpark (Python) na lista suspensa Linguagem.
Baixe a amostra createTablefromParquet.pyy e carregue-o como o arquivo de definição principal. O arquivo de definição principal (job.Main) é o arquivo que contém a lógica do aplicativo e é obrigatório para executar um trabalho do Spark. Para cada definição de trabalho do Spark, você só pode carregar um arquivo de definição principal.
Você pode carregar o arquivo de definição principal diretamente da área de trabalho local ou carregá-lo de um Azure Data Lake Storage (ADLS) Gen2 existente fornecendo o caminho ABFSS completo do arquivo. Por exemplo,
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Carregue arquivos de referência como arquivos .py. Os arquivos de referência são os módulos Python importados pelo arquivo de definição principal. Assim como o arquivo de definição principal, você pode carregar da área de trabalho ou de um ADLS Gen2 existente. Há suporte para vários arquivos de referência.
Dica
Se você usar um caminho do ADLS Gen2, para garantir que o arquivo esteja acessível, forneça à conta de usuário que executa o trabalho a permissão adequada para a conta de armazenamento. Sugerimos duas maneiras diferentes de fazer isso:
- Atribua à conta de usuário uma função de Colaborador para a conta de armazenamento.
- Conceda permissão de leitura e execução à conta de usuário do arquivo por meio da lista de controle de acesso (ACL) do ADLS Gen2.
Para uma execução manual, a conta do usuário de logon atual é usada para executar o trabalho.
Forneça argumentos de linha de comando para o trabalho, se necessário. Use um espaço como um divisor para separar os argumentos.
Adicione a referência de lakehouse ao trabalho. Você deve ter pelo menos uma referência de lakehouse adicionada ao trabalho. Este lakehouse é o contexto padrão do lakehouse para o trabalho.
Há suporte para várias referências de lakehouse. Localize o nome do lakehouse não padrão e a URL completa do OneLake na página de configurações do Spark.
Criar uma definição de trabalho do Spark para Scala/Java
Para criar uma definição de trabalho do Spark para Scala/Java:
Crie uma nova definição de trabalho do Spark.
Selecione Spark(Scala/Java) na lista suspensa Linguagem.
Carregue o arquivo de definição principal como um arquivo .jar. O arquivo de definição principal é o arquivo que contém a lógica do aplicativo desse trabalho e é obrigatório para executar um trabalho do Spark. Para cada definição de trabalho do Spark, você só pode carregar um arquivo de definição principal. Forneça o nome de classe principal.
Carregue arquivos de referência como arquivos .jar. Os arquivos de referência são os arquivos referenciados/importados pelo arquivo de definição principal.
Forneça argumentos de linha de comando para o trabalho, se necessário.
Adicione a referência de lakehouse ao trabalho. Você deve ter pelo menos uma referência de lakehouse adicionada ao trabalho. Este lakehouse é o contexto padrão do lakehouse para o trabalho.
Criar uma definição de trabalho do Spark para R
Para criar uma definição de trabalho do Spark para SparkR(R):
Crie uma nova definição de trabalho do Spark.
Selecione SparkR(R) na lista suspensa Linguagem.
Carregue o arquivo de definição principal como um arquivo .R. O arquivo de definição principal é o arquivo que contém a lógica do aplicativo desse trabalho e é obrigatório para executar um trabalho do Spark. Para cada definição de trabalho do Spark, você só pode carregar um arquivo de definição principal.
Carregue arquivos de referência como arquivos .R. Os arquivos de referência são os arquivos referenciados/importados pelo arquivo de definição principal.
Forneça argumentos de linha de comando para o trabalho, se necessário.
Adicione a referência de lakehouse ao trabalho. Você deve ter pelo menos uma referência de lakehouse adicionada ao trabalho. Este lakehouse é o contexto padrão do lakehouse para o trabalho.
Observação
A definição de trabalho do Spark será criada em seu workspace atual.
Opções para personalizar definições de trabalho do Spark
Há algumas opções para personalizar ainda mais a execução de definições de trabalho do Spark.
- Computação do Spark: na guia Computação do Spark, é possível ver a Versão do Runtime, que é a versão do Spark que será usada para executar o trabalho. Você também pode ver as definições de configurações do Spark que serão usadas para executar o trabalho. Você pode personalizar as definições de configurações do Spark clicando no botão Adicionar.
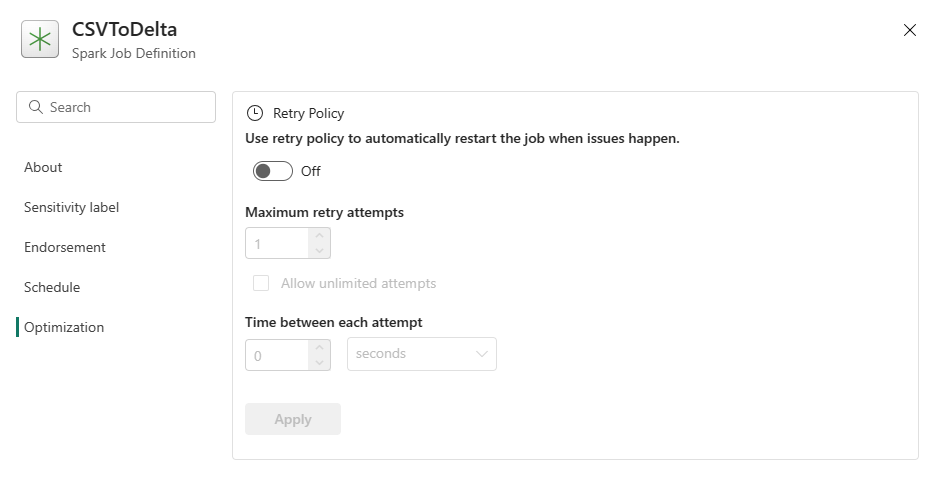
Otimização: na guia Otimização, você pode habilitar e configurar a política de repetição para o trabalho. Quando habilitado, o trabalho será repetido se falhar. Você também pode definir o número máximo de repetições e o intervalo entre elas. Para cada tentativa de repetição, o trabalho é reiniciado. Verifique se o trabalho é idempotente.