Tutorial: Criar, avaliar e pontuar um sistema de recomendação
Este tutorial apresenta um exemplo de ponta a ponta de um fluxo de trabalho de Ciência de Dados do Synapse no Microsoft Fabric. O cenário cria um modelo para recomendações de livro online.
Este tutorial aborda estas etapas:
- Carregar os dados em um sistema de armazenamento tipo lakehouse
- Executar análise exploratória nos dados
- Treinar um modelo e registrá-lo com o MLflow
- Carregar o modelo e fazer previsões
Temos muitos tipos de algoritmos de recomendação disponíveis. Este tutorial usa o algoritmo de fatoração de matriz ALS (mínimos quadrados alternantes). O ALS é um algoritmo de filtragem colaborativa baseado em modelo.

ALS tenta estimar a matriz de classificações R como o produto de duas matrizes de menor ordem, U e V. Aqui, R = U * Vt. Normalmente, essas aproximações são chamadas de matrizes de fator.
O algoritmo ALS é iterativo. Cada iteração contém uma das matrizes de fator constante, enquanto resolve a outra usando o método de mínimos quadrados. Em seguida, ele mantém essa constante de matriz de fator recém-resolvida enquanto resolve a outra matriz de fatores.

Pré-requisitos
Obtenha uma assinatura do Microsoft Fabric. Ou cadastre-se para uma avaliação gratuita do Microsoft Fabric.
Entre no Microsoft Fabric.
Use o botão de alternância de experiência no canto inferior esquerdo da página inicial para mudar para o Fabric.
- Se necessário, crie um lakehouse do Microsoft Fabric, conforme descrito em Criar um lakehouse no Microsoft Fabric.
Acompanhar em um notebook
Você pode escolher uma destas opções para acompanhar em um notebook:
- Abra e execute o notebook integrado.
- Carregue seu bloco de anotações no GitHub.
Abrir o bloco de anotações interno
O notebook de exemplo de Recomendação de livros acompanha este tutorial.
Para abrir o bloco de anotações de exemplo para este tutorial, siga as instruções em Preparar seu sistema para tutoriais de ciência de dados.
Certifique-se de anexar um lakehouse ao notebook antes de começar a executar o código.
Importar o notebook do GitHub
O notebook AIsample – Book Recommendation.ipynb acompanha este tutorial.
Para abrir o bloco de anotações que acompanha este tutorial, siga as instruções em Preparar seu sistema para tutoriais de ciência de dados para importar o bloco de anotações para seu espaço de trabalho.
Se você prefere copiar e colar o código desta página, pode criar um notebook.
Certifique-se de anexar um lakehouse ao notebook antes de começar a executar o código.
Etapa 1: Carregar os dados
O conjunto de dados de recomendação de livro neste cenário consiste em três conjuntos de dados separados:
Books.csv: um ISBN (Número de Livro Padrão Internacional) identifica cada livro, com datas inválidas já removidas. O conjunto de dados também inclui o título, o autor e o publicador. Para um livro com vários autores, o arquivo Books.csv lista apenas o primeiro autor. As URLs apontam para os recursos do site da Amazon para as imagens de capa, em três tamanhos.
ISBN Book-Title Autor-do-livro Year-Of-Publication Publisher Image-URL-S Image-URL-M Image-URL-l 0195153448 Mitologia Clássica Mark P. O. Morford 2002 Imprensa da Universidade de Oxford http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: as classificações para cada livro são explícitas (fornecidas pelos usuários, em uma escala de 1 a 10) ou implícitas (observadas sem entrada do usuário e indicadas por 0).
User-ID ISBN Book-Rating 276725 034545104X 0 276726 0155061224 5 Users.csv: as IDs de usuário são anonimizadas e mapeadas para inteiros. Os dados demográficos - por exemplo, local e idade - são fornecidos, se disponíveis. Se esses dados não estiverem disponíveis, esses valores serão
null.User-ID Localização Idade 1 "nyc new york usa" 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Defina estes parâmetros para que você possa executar este notebook com conjuntos de dados diferentes:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Descarregar e armazenar os dados em um lakehouse
Esse código baixa o conjunto de dados e o armazena no lakehouse.
Importante
Certifique-se de adicionar um lakehouse ao notebook antes de executá-lo. Caso contrário, você receberá um erro.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Configurar o acompanhamento de experimentos do MLflow
Use esse código para configurar o acompanhamento de experimentos do MLflow. Este exemplo desabilita o registro automático. Para obter mais informações, confira o artigo Log automático no Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Ler os dados do lakehouse
Depois que os dados corretos forem colocados no lakehouse, leia os três conjuntos de dados em DataFrames do Spark separados no notebook. Os caminhos de arquivo neste código usam os parâmetros definidos anteriormente.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Etapa 2: executar análise de dados exploratória
Exibir dados brutos
Explore os DataFrames com o comando display. Com esse comando, você pode exibir estatísticas de DataFrame de alto nível e entender como diferentes colunas de conjunto de dados se relacionam entre si. Antes de explorar os conjuntos de dados, use este código para importar as bibliotecas necessárias:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Use este código para examinar o DataFrame que contém os dados do livro:
display(df_items, summary=True)
Adicione uma coluna _item_id para uso posterior. O valor _item_id deve ser um inteiro para modelos de recomendação. Esse código usa StringIndexer para transformar ITEM_ID_COL em índices:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Exiba o DataFrame e verifique se o valor _item_id aumenta monotonicamente e sucessivamente, conforme o esperado:
display(df_items.sort(F.col("_item_id").desc()))
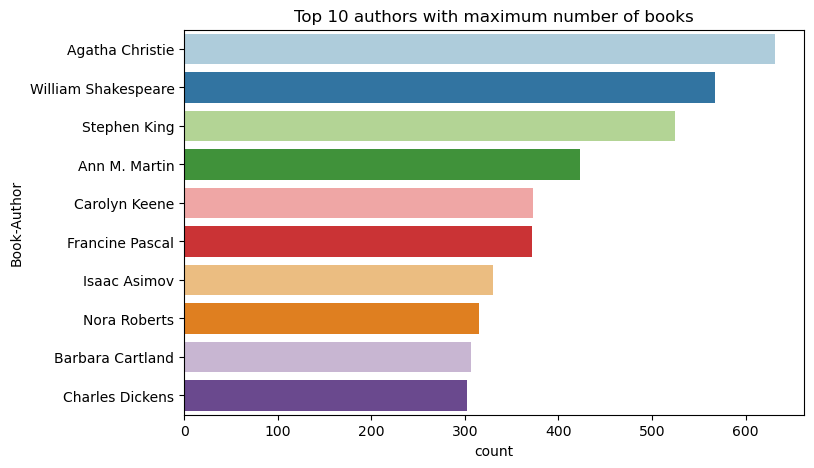
Use este código para plotar os 10 principais autores, por número de livros escritos, em ordem decrescente. Agatha Christie é a principal autora com mais de 600 livros, seguida por William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Em seguida, exiba o DataFrame que contém os dados do usuário:
display(df_users, summary=True)
Se uma linha tiver um valor de User-ID ausente, remova essa linha. Valores ausentes em um conjunto de dados personalizado não causam problemas.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Adicione uma coluna _user_id para uso posterior. Para modelos de recomendação, o valor _user_id deve ser um inteiro. O exemplo de código a seguir usa StringIndexer para transformar USER_ID_COL em índices.
O conjunto de dados do livro já tem uma coluna User-ID de inteiros. No entanto, adicionar uma coluna _user_id para compatibilidade com conjuntos de dados diferentes torna este exemplo mais robusto. Use este código para adicionar a coluna _user_id:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Use este código para exibir os dados de classificação:
display(df_ratings, summary=True)
Obtenha as classificações distintas e salve-as para uso posterior em uma lista chamada ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
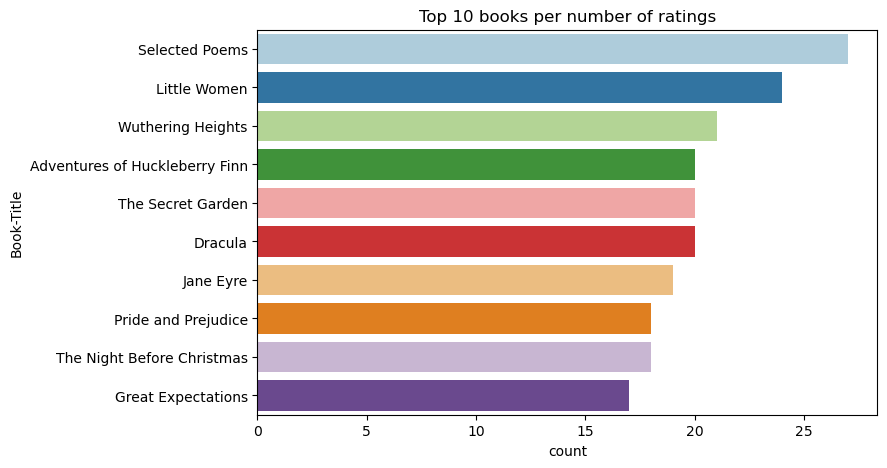
Use este código para mostrar os 10 melhores livros com as classificações mais altas:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
De acordo com a audiência, Selected Poems é o livro mais popular. Adventures of Huckleberry Finn, The Secret Gardene Drácula têm a mesma classificação.
Mesclar dados
Mesclar os três DataFrames em um DataFrame para uma análise mais abrangente:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Use este código para exibir uma contagem de usuários, livros e interações distintos:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Computar e plotar os itens mais populares
Use este código para calcular e exibir os 10 livros mais populares:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Dica
Use o valor <topn> para seções de recomendação Populares ou Mais comprados.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Preparar conjuntos de dados de treinamento e teste
A matriz de ALS requer alguma preparação de dados antes do treinamento. Use este exemplo de código para preparar os dados. O código executa estas ações:
- Converter a coluna de classificação para o tipo correto
- Amostre os dados de treinamento com classificações de usuário
- Dividir os dados em conjuntos de dados de treinamento e teste
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Esparsidade refere-se a dados de comentários esparsos, que não podem identificar semelhanças entre os interesses dos usuários. Para obter uma melhor compreensão dos dados e do problema atual, use este código para calcular a esparsidade do conjunto de dados.
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Etapa 3: Desenvolver e treinar o modelo
Treine um modelo de ALS para fornecer aos usuários recomendações personalizadas.
Definir o modelo
O Spark ML fornece uma API conveniente para a criação do modelo de ALS. No entanto, o modelo não lida de forma confiável com problemas como a escassez de dados e o problema de início a partir do zero (fazendo recomendações quando os usuários ou itens são novos). Para melhorar o desempenho do modelo, combine a validação cruzada e o ajuste automático do hiperparâmetro.
Use este código para importar as bibliotecas necessárias para treinamento e avaliação de modelo:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Ajustar hiperparâmetros de modelo
O próximo exemplo de código constrói uma grade de parâmetros para ajudar a pesquisar sobre os hiperparâmetros. O código também cria um avaliador de regressão que usa o RMSE (erro raiz-médio-quadrado) como a métrica de avaliação:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
O próximo exemplo de código inicia diferentes métodos de ajuste de modelo com base nos parâmetros pré-configurados. Para obter mais informações sobre o ajuste do modelo, consulte Ajuste de ML: seleção de modelo e ajuste de hiperparâmetro no site do Apache Spark.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Avaliar o modelo
Você deve avaliar os módulos em relação aos dados de teste. Um modelo bem treinado deve ter métricas altas no conjunto de dados.
Um modelo sobreajustado pode precisar de um aumento no tamanho dos dados de treinamento ou uma redução de alguns dos recursos redundantes. A arquitetura de modelo pode precisar ser alterada ou seus parâmetros podem precisar de ajustes finos.
Nota
Um valor de métrica R quadrado negativo indica que o modelo treinado tem um desempenho pior do que uma linha reta horizontal. Essa descoberta sugere que o modelo treinado não explica os dados.
Para definir uma função de avaliação, use este código:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Acompanhar o experimento usando o MLflow
Use o MLflow para acompanhar todos os experimentos e registrar parâmetros, métricas e modelos. Para iniciar o treinamento e a avaliação do modelo, use este código:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Selecione o experimento chamado aisample-recommendation em seu workspace para exibir as informações registradas em log para a execução de treinamento. Se você alterou o nome do experimento, selecione o experimento que tem o novo nome. As informações registradas se assemelham a esta imagem:

Etapa 4: carregar o modelo final para pontuação e fazer previsões
Depois de concluir o treinamento de modelo e selecionar o melhor modelo, carregue o modelo para pontuação (às vezes chamado de inferência). Esse código carrega o modelo e usa previsões para recomendar os 10 principais livros para cada usuário:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
A saída se assemelha a esta tabela:
| _item_id | _user_id | rating | Book-Title |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Vidas de... |
| 786 | 7 | 6.2255826 | The Piano Man's D... |
| 45330 | 7 | 4.980466 | Estado da Mente |
| 38960 | 7 | 4.980466 | Tudo o que ele sempre quis |
| 125415 | 7 | 4.505084 | Harry Potter e... |
| 44939 | 7 | 4.3579073 | Taltos: Vidas de... |
| 175247 | 7 | 4.3579073 | The Bonesetter's ... |
| 170183 | 7 | 4.228735 | Living the Simple... |
| 88503 | 7 | 4.221206 | Ilha do Blu... |
| 32894 | 7 | 3.9031885 | Solstício de inverno |
Salvar as previsões no lakehouse
Use este código para gravar as recomendações de volta no lakehouse:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)