Criar um lakehouse para Direct Lake
Este artigo descreve como criar uma *lakehouse*, criar uma tabela Delta na *lakehouse* e, em seguida, criar um modelo semântico básico para a *lakehouse* em um workspace do Microsoft Fabric.
Antes de começar a criar um lakehouse para Direct Lake, leia Visão Geral do Direct Lake.
Criar uma casa no lago
No workspace do Microsoft Fabric, selecione Novo>Mais opções e, em Engenharia de Dados, selecione o bloco Lakehouse.
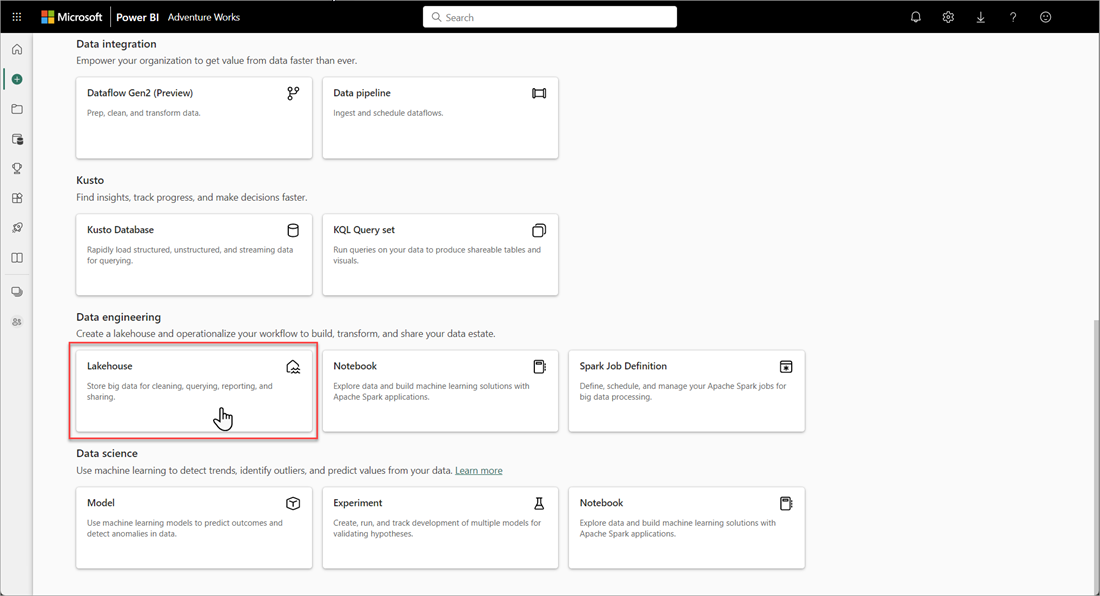
Na caixa de diálogo Novo lakehouse, insira um nome e selecione Criar. O nome só pode conter caracteres alfanuméricos e sublinhados.
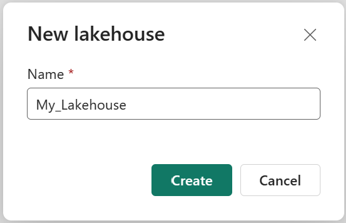
Verifique se o novo lakehouse foi criado e aberto com êxito.
Criar uma tabela Delta no lakehouse
Depois de criar um novo lakehouse, você deve criar pelo menos uma tabela Delta para que o Direct Lake possa acessar alguns dados. O Direct Lake pode ler arquivos no formato parquet, mas, para obter o melhor desempenho, recomenda-se compactar os dados usando o método de compactação VORDER. O VORDER compacta os dados usando o algoritmo de compactação nativa do mecanismo do Power BI. Dessa forma, o mecanismo pode carregar os dados na memória o mais rápido possível.
Há várias opções para carregar dados em um lakehouse, incluindo pipelines de dados e scripts. As etapas a seguir usam o PySpark para adicionar uma tabela Delta a uma lakehouse com base em um Azure Open Dataset:
No lakehouse recém-criado, selecione Abrir notebook e selecione Novo notebook.
Copie e cole o snippet de código a seguir na primeira célula de código para permitir que o SPARK acesse o modelo aberto e pressione Shift + Enter para executar o código.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Verifique se o código produz com sucesso um caminho de blob remoto.
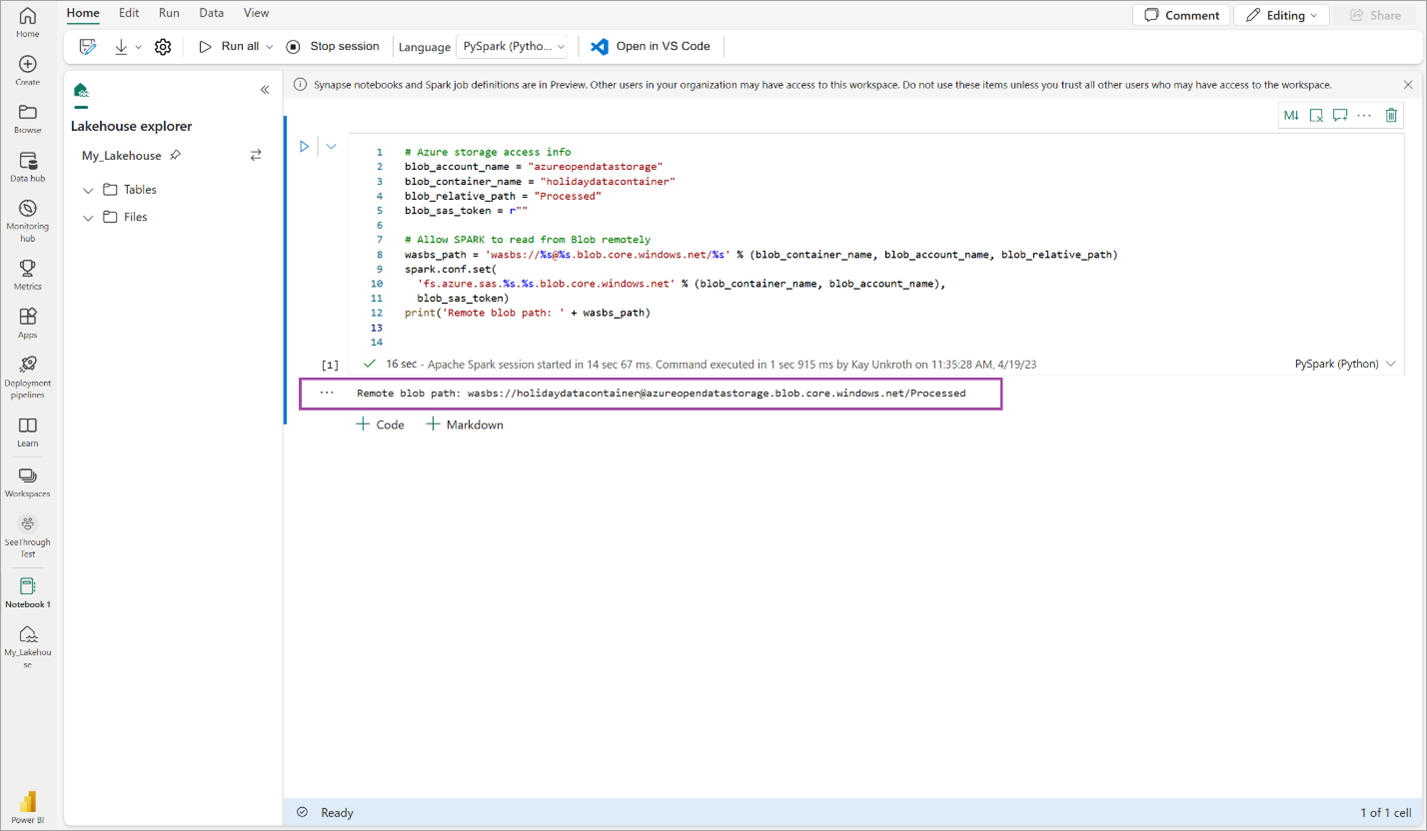
Copie e cole o seguinte código na próxima célula e pressione Shift + Enter.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Verifique se o código gera com êxito o esquema DataFrame.
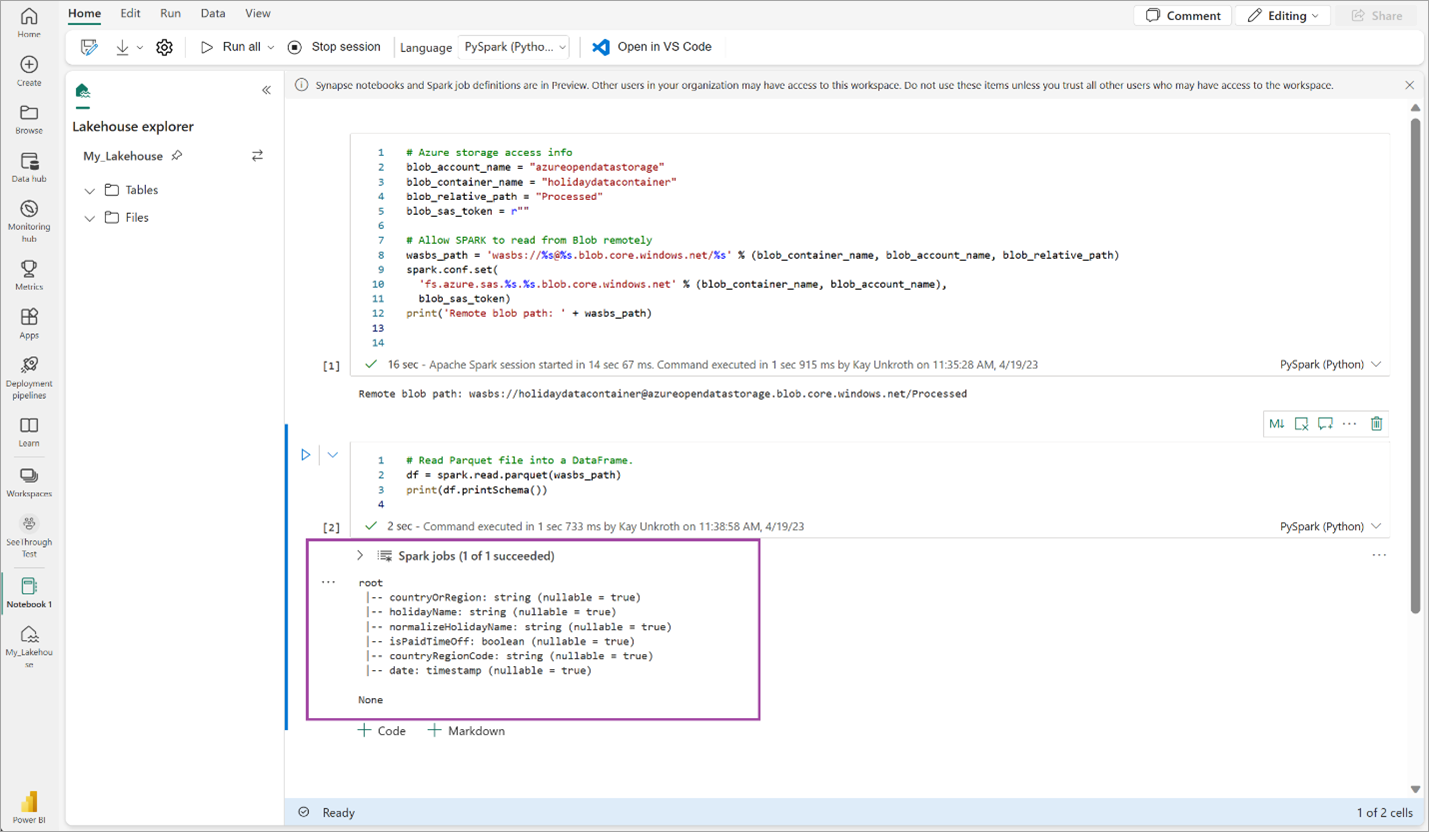
Copie e cole as seguintes linhas na próxima célula e pressione Shift + Enter. A primeira instrução habilita o método de compactação VORDER, e a próxima instrução salva o DataFrame como uma tabela Delta no lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Verifique se todos os trabalhos do SPARK foram concluídos com êxito. Expanda a lista de trabalhos do SPARK para exibir mais detalhes.
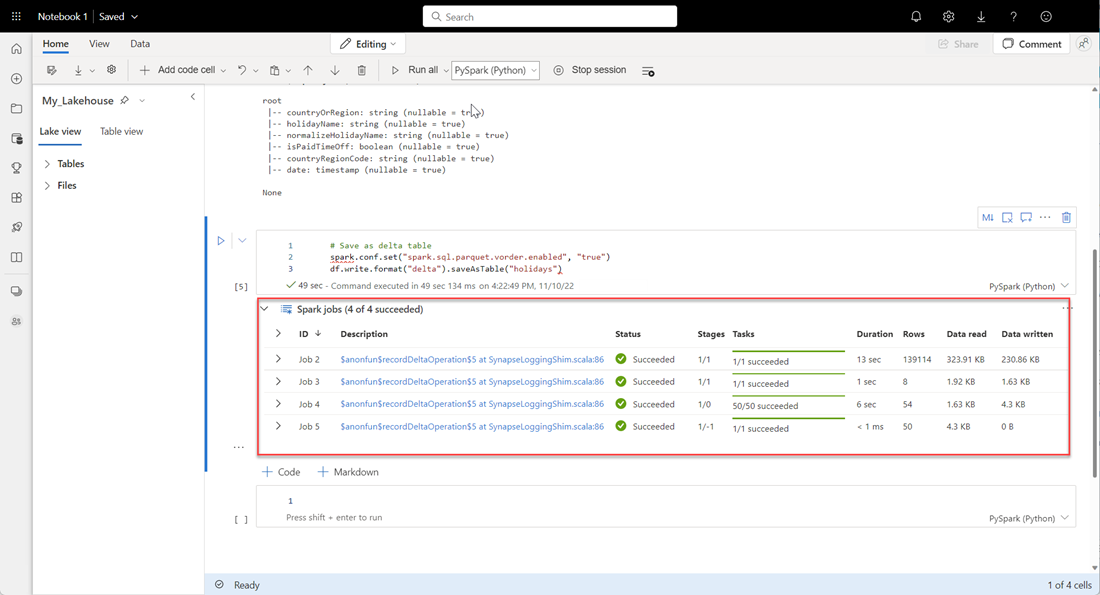
Para verificar se uma tabela foi criada com êxito, na área superior esquerda, ao lado de Tabelas, selecione as reticências (…), selecione Atualizar e, em seguida, expanda o nó Tabelas.
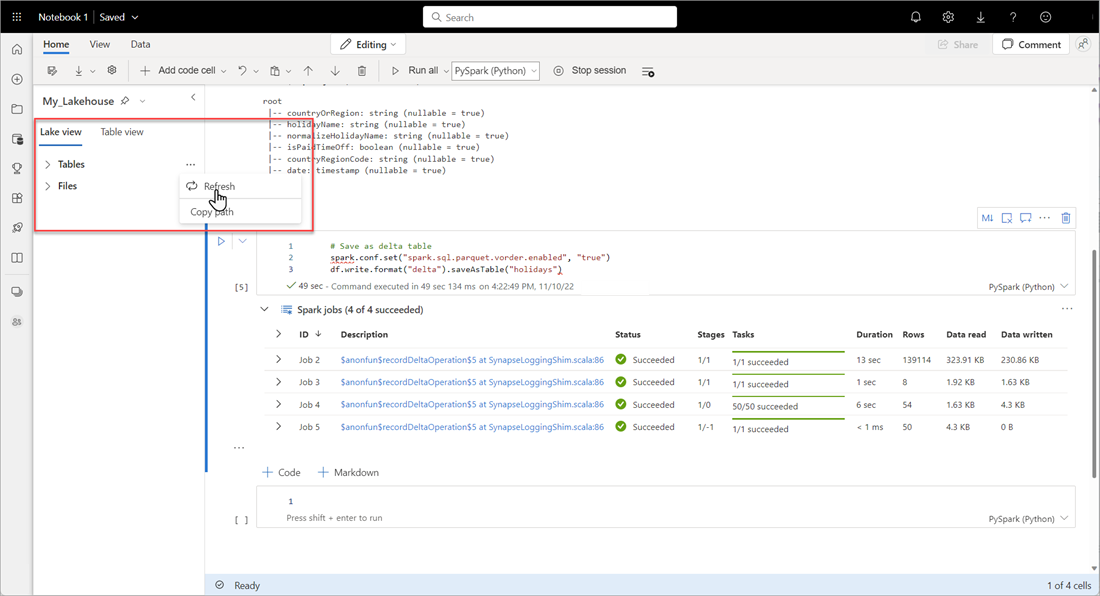
Usando o mesmo método que acima ou outros métodos com suporte, adicione mais tabelas Delta para os dados que você deseja analisar.
Criar um modelo básico do Direct Lake para o seu lakehouse
Em seu lakehouse, selecione Novo modelo semânticoe, na caixa de diálogo, selecione as tabelas a serem incluídas.
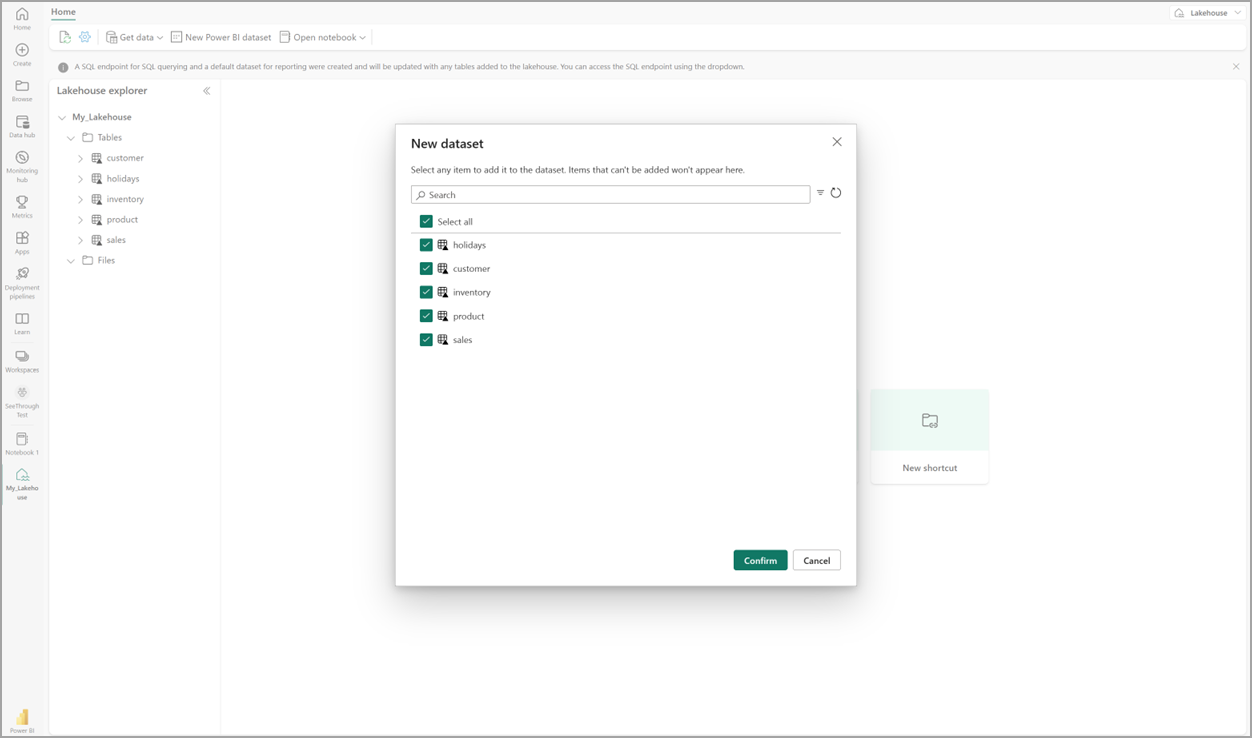
Selecione Confirmar para gerar o modelo do Direct Lake. O modelo é salvo automaticamente no workspace com base no nome do seu lakehouse e é aberto em seguida.
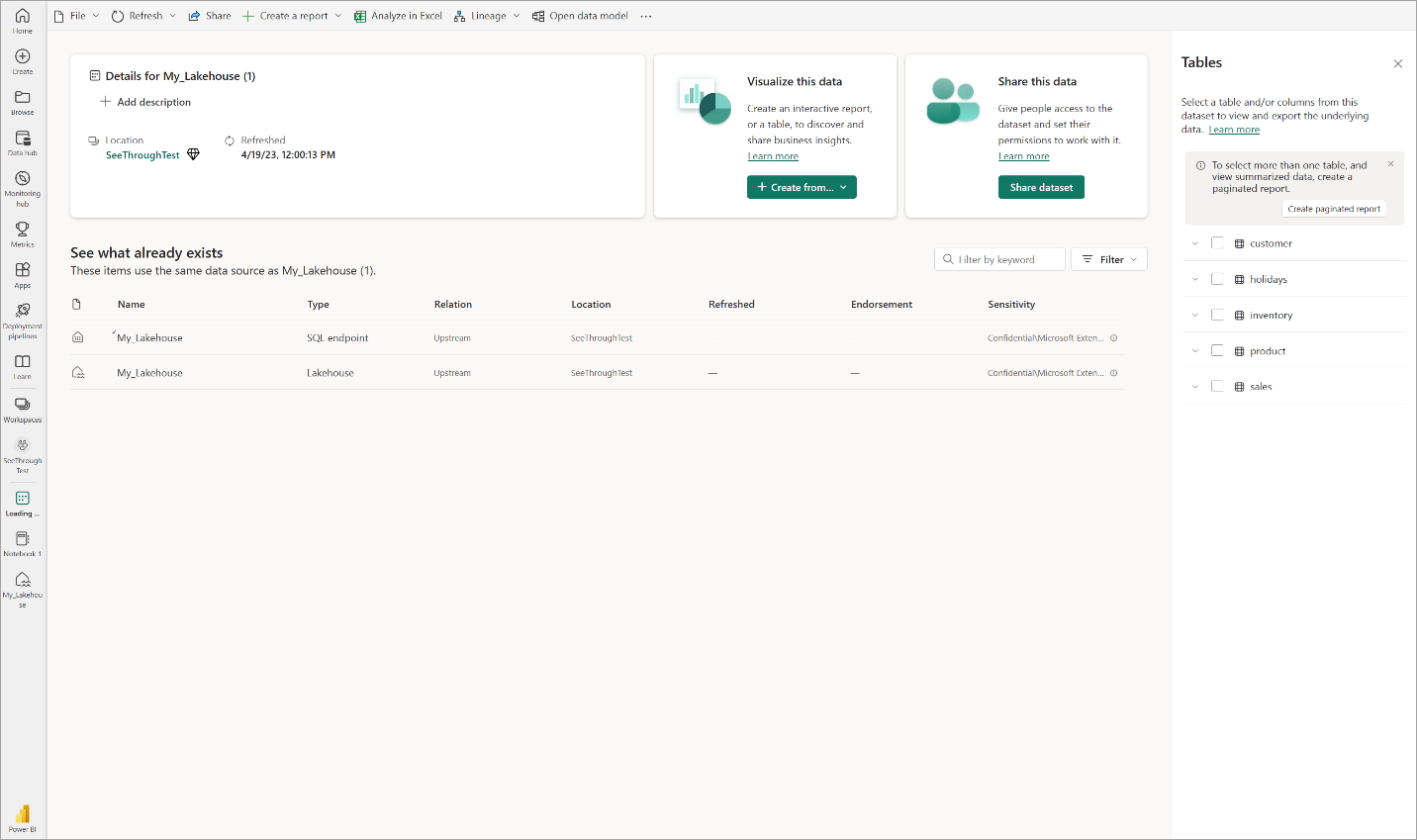
Selecione Modelo de dados abertos para abrir a experiência de modelagem da Web em que você pode adicionar relações de tabela e medidas DAX.
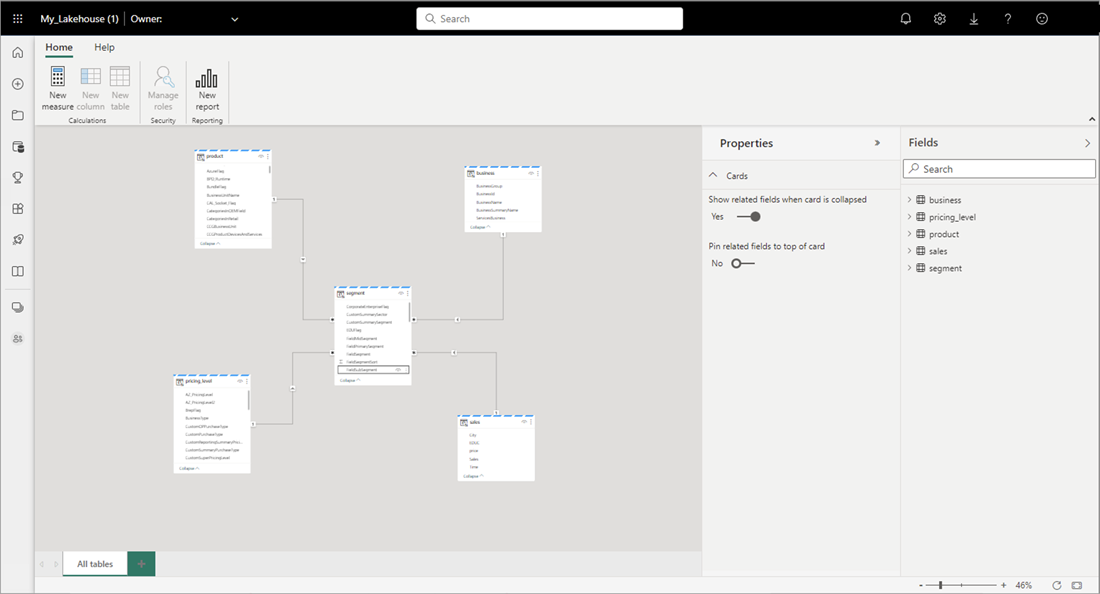
Quando terminar de adicionar relações e medidas DAX, você poderá criar relatórios, criar um modelo composto e consultar o modelo por meio de pontos de extremidade XMLA da mesma maneira que qualquer outro modelo.