Bancos de dados de vetores
Um banco de dados de vetores armazena e gerencia dados na forma de vetores, que são matrizes numéricas de pontos de dados.
O uso de vetores permite consultas e análises complexas, pois os vetores podem ser comparados e analisados usando técnicas avançadas, como pesquisa por similaridade de vetores, quantização e agrupamento. Os bancos de dados tradicionais não são adequados para lidar com dados de alta dimensão, que estão se tornando cada vez mais comuns na análise de dados. No entanto, os bancos de dados de vetores são projetados para lidar com dados de alta dimensão, como texto, imagens e áudio, representando-os como vetores. Os bancos de dados de vetores são úteis para tarefas como aprendizado de máquina, processamento de linguagem natural e reconhecimento de imagens, em que o objetivo é identificar padrões ou semelhanças em grandes conjuntos de dados.
Esse artigo fornece algumas informações básicas sobre bancos de dados de vetores e explica conceitualmente como você pode usar um Eventhouse como um banco de dados de vetores em Inteligência em Tempo Real no Microsoft Fabric. Para obter um exemplo prático, consulte Tutorial: usar uma Eventhouse como banco de dados de vetores.
Conceitos principais
Os seguintes conceitos-chave são usados em bancos de dados de vetores:
Similaridade de vetor
A similaridade de vetores é uma medida de quão diferentes (ou semelhantes) são dois ou mais vetores. A pesquisa por similaridade de vetores é uma técnica usada para encontrar vetores semelhantes em um conjunto de dados. Os vetores são comparados usando uma métrica de distância, como distância euclidiana ou similaridade de cosseno. Quanto mais próximos dois vetores estiverem, mais semelhantes eles serão.
Inserções
Inserções são uma forma comum de representar dados em formato de vetores para uso em bancos de dados de vetores. Uma inserção é uma representação matemática de um dado, como uma palavra, um documento de texto ou uma imagem, projetada para capturar seu significado semântico. As inserções são criadas usando algoritmos que analisam os dados e geram um conjunto de valores numéricos que representam seus principais recursos. Por exemplo, a inserção de uma palavra pode representar seu significado, seu contexto e sua relação com outras palavras. O processo de criação de inserções é simples. Embora possam ser criadas usando pacotes python padrão (por exemplo, spaCy, sent2vec, Gensim), os LLM (Modelos de Linguagem Grandes) geram inserções da mais alta qualidade para pesquisa semântica de texto. Por exemplo, você pode enviar texto para um modelo de inserção no OpenAI do Azure, e ele gera uma representação de vetores que pode ser armazenada para análise. Para obter mais informações, consulte Compreender as inserções no serviço OpenAI do Azure.
Fluxo de trabalho geral

O fluxo de trabalho geral para usar um banco de dados de vetores é o seguinte:
- Inserir dados: converta dados em formato de vetores usando um modelo de inserção. Por exemplo, você pode inserir dados de texto usando um modelo OpenAI.
- Armazenar vetores: armazene os vetores inseridos em um banco de dados de vetores. Você pode enviar os dados inseridos a um Eventhouse para armazenar e gerenciar os vetores.
- Inserir consulta: converta os dados da consulta em formato de vetores usando o mesmo modelo de inserção usado para inserir os dados armazenados.
- Consultar vetores: use a pesquisa por similaridade de vetores para localizar entradas no banco de dados que sejam semelhantes à consulta.
Eventhouse como um banco de dados de vetores
No cerne da pesquisa por similaridade de vetores, está a capacidade de armazenar, indexar e consultar dados de vetores. Os Eventhouses fornecem uma solução para manipulação e análise de grandes volumes de dados, principalmente em cenários que exigem análise e exploração em tempo real, tornando-os uma excelente opção para armazenamento e pesquisa de vetores.
Os seguintes componentes da arquitetura Eventhouse permitem seu uso como banco de dados de vetores:
- O tipo de dados dinâmico, que pode armazenar dados não estruturados, como matrizes e pacotes de propriedades. Portanto, o tipo de dados é recomendado para armazenar valores de vetores. Você pode aumentar ainda mais o valor do vetor armazenando metadados relacionados ao objeto original como colunas separadas em sua tabela.
- O tipo de codificação
Vector16projetado para armazenar vetores de números de ponto flutuante com precisão de 16 bits, que usaBfloat16em vez dos 64 bits padrão. Essa codificação é recomendada para armazenar inserções de vetores de ML, pois reduz os requisitos de armazenamento em um fator de quatro e acelera funções de processamento de vetores, como series_dot_product() e series_cosine_similarity(), em ordens de magnitude. - A função series_cosine_similarity, que pode realizar pesquisas de similaridade de vetores sobre os vetores armazenados no Eventhouse.
Otimizar para escala
Para otimizar a pesquisa de similaridade de cosseno, é possível dividir a tabela de vetores em muitas extensões que são distribuídas uniformemente entre todos os nós do cluster. Você pode ver os efeitos do particionamento no tempo de consulta no exemplo a seguir. Esse exemplo usa várias tabelas contendo até 1 milhão de vetores de inserção testando o desempenho de similaridade de cosseno em clusters com 1, 2, 4, 8 e 20 nós. O seguinte gráfico compara o desempenho da pesquisa (em segundos) antes e depois do particionamento:
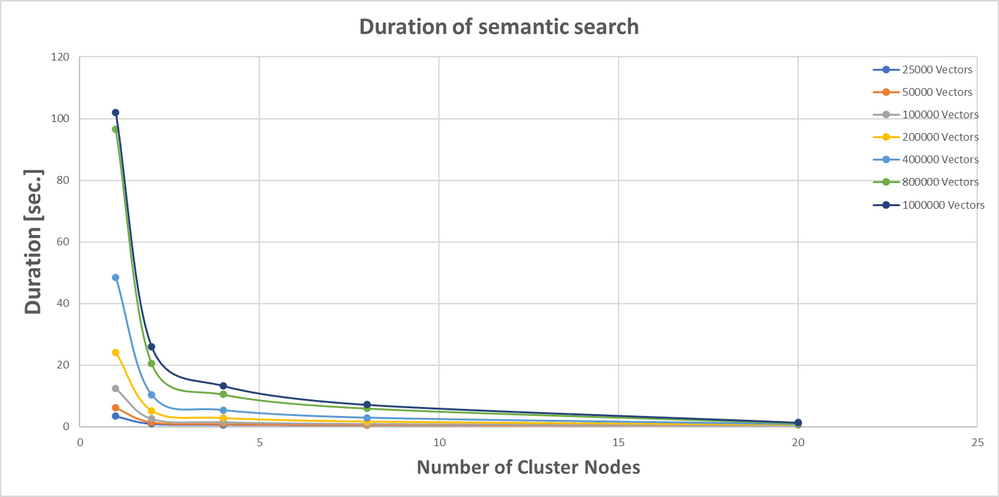
Mesmo no menor cluster, a velocidade de pesquisa melhora em mais de um fator de quatro. Em geral, a velocidade é inversamente proporcional ao número de nós. O número de vetores de inserção necessários para cenários comuns de LLM (Modelo de Linguagem Grande) (por exemplo, Recuperação Aumentada de Geração) raramente excede 100 mil; portanto, com oito nós, a pesquisa pode ser feita em 1 segundo.
Criar uma política de particionamento para otimizar a escala
Para definir a política de particionamento para a tabela de inserção, use o seguinte comando .alter-merge policy partitioning:
.alter-merge table TABLENAME policy partitioning
```
{
"PartitionKeys": [
{
"ColumnName": "vector_id_str",
"Kind": "Hash",
"Properties": {
"Function": "XxHash64",
"MaxPartitionCount": 2048, // set it to max value create smaller partitions thus more balanced spread among all cluster nodes
"Seed": 1,
"PartitionAssignmentMode": "Uniform"
}
}
],
"EffectiveDateTime": "2000-01-01" // set it to old date in order to apply partitioning on existing data
}
```
Observação
Você pode notar que o cluster tem 2 nós, mas as tabelas são armazenadas em um único nó. Essa é a linha de base antes de aplicar a política de particionamento.
O processo de particionamento requer uma chave de cadeia de caracteres com alta cardinalidade; portanto, o vector_id exclusivo foi projetado e convertido em um tipo de dados string. A prática recomendada é criar uma tabela vazia, modificar sua política de partição e ingerir os dados. Nesse caso, não há necessidade de definir o EffectiveDateTime antigo como no comando anterior. Demora algum tempo após a ingestão de dados até que a política seja aplicada.