Copiar dados do Dataverse no SQL do Azure
Use o Azure Synapse Link para conectar dados do Microsoft Dataverse ao Azure Synapse Analytics para explorá-los e acelerar o tempo para obter insights. Este artigo mostra como executar pipelines do Azure Synapse ou o Azure Data Factory para copiar dados do Azure Data Lake Storage Gen2 para um Banco de Dados SQL do Azure com o recurso de atualizações incrementais habilitado no Azure Synapse Link.
Observação
O Azure Synapse Link for Microsoft Dataverse era conhecido antes como Exportar para o data lake. O serviço foi renomeado em maio de 2021 e continuará a exportar dados para o Azure Data Lake, bem como para o Azure Synapse Analytics. Este modelo é uma amostra de código. Incentivamos você a usar este modelo como orientação para testar a funcionalidade de recuperação de dados de Azure Data Lake Storage Gen2 para Banco de Dados SQL do Azure usando o pipeline fornecido.
Pré-requisitos
- Azure Synapse Link for Dataverse. Este guia pressupõe que você já atendeu aos pré-requisitos para criar um Azure Synapse Link com um Azure Data Lake. Mais informações: Pré-requisitos para um Azure Synapse Link for Dataverse com seu Azure Data Lake
- Crie um Azure Synapse Workspace ou um Azure Data Factory no mesmo locatário do Microsoft Entra como o locatário do Power Apps.
- Crie um Azure Synapse Link for Dataverse com a atualização de pasta incremental habilitada para definir o intervalo de tempo. Mais informações: Consultar e analisar as atualizações incrementais
- O provedor Microsoft.EventGrid precisa ser registrado para disparar. Mais informações: Portal do Azure. Observação: se você estiver usando este recurso no Azure Synapse Analytics, verifique se a sua assinatura também está registrada no provedor de recursos do Data Factory. Caso contrário, você receberá um erro informando que houve falha na criação de uma "Assinatura de Evento".
- Crie um banco de dados SQL do Azure com a propriedade Permitir que serviços e recursos do Azure acessem este servidor habilitada. Mais informações: O que devo saber ao configurar meu Banco de Dados SQL do Azure (PaaS)?
- Crie e configure um Azure Integration Runtime. Mais informações: Criar Azure Integration Runtime – Azure Data Factory e Azure Synapse
Importante
O uso desse modelo pode incorrer em custos adicionais. Esses custos estão relacionados ao uso do Azure Data Factory ou do pipeline do Synapse workspace e são cobrados mensalmente. O custo do uso de pipelines depende principalmente do intervalo de tempo para atualização incremental e dos volumes de dados. Para planejar e gerenciar o custo de uso desse recurso, acesse: Monitorar custos em nível de pipeline com análise de custo
É importante levar em consideração esses custos adicionais ao decidir usar esse modelo, pois eles não são opcionais e devem ser pagos para continuar usando esse recurso.
Usar o modelo de solução
- Vá para o portal do Azure e abra o Azure Synapse workspace.
- Selecione Integrar > Galeria de navegação.
- Selecione Copiar dados do Dataverse no Azure SQL usando o Synapse Link na galeria de integração.
Configurar o modelo de solução
Crie um serviço vinculado para o Azure Data Lake Storage Gen2, que está conectado ao Dataverse usando o tipo de autenticação apropriado. Para fazer isso, selecione Testar a conexão para validar a conectividade e, depois, Criar.
Semelhante às etapas anteriores, crie um serviço vinculado ao Banco de Dados SQL do Azure em que os dados do Dataverse serão sincronizados.
Depois que Entradas estiver configurado, selecione Usar este modelo.
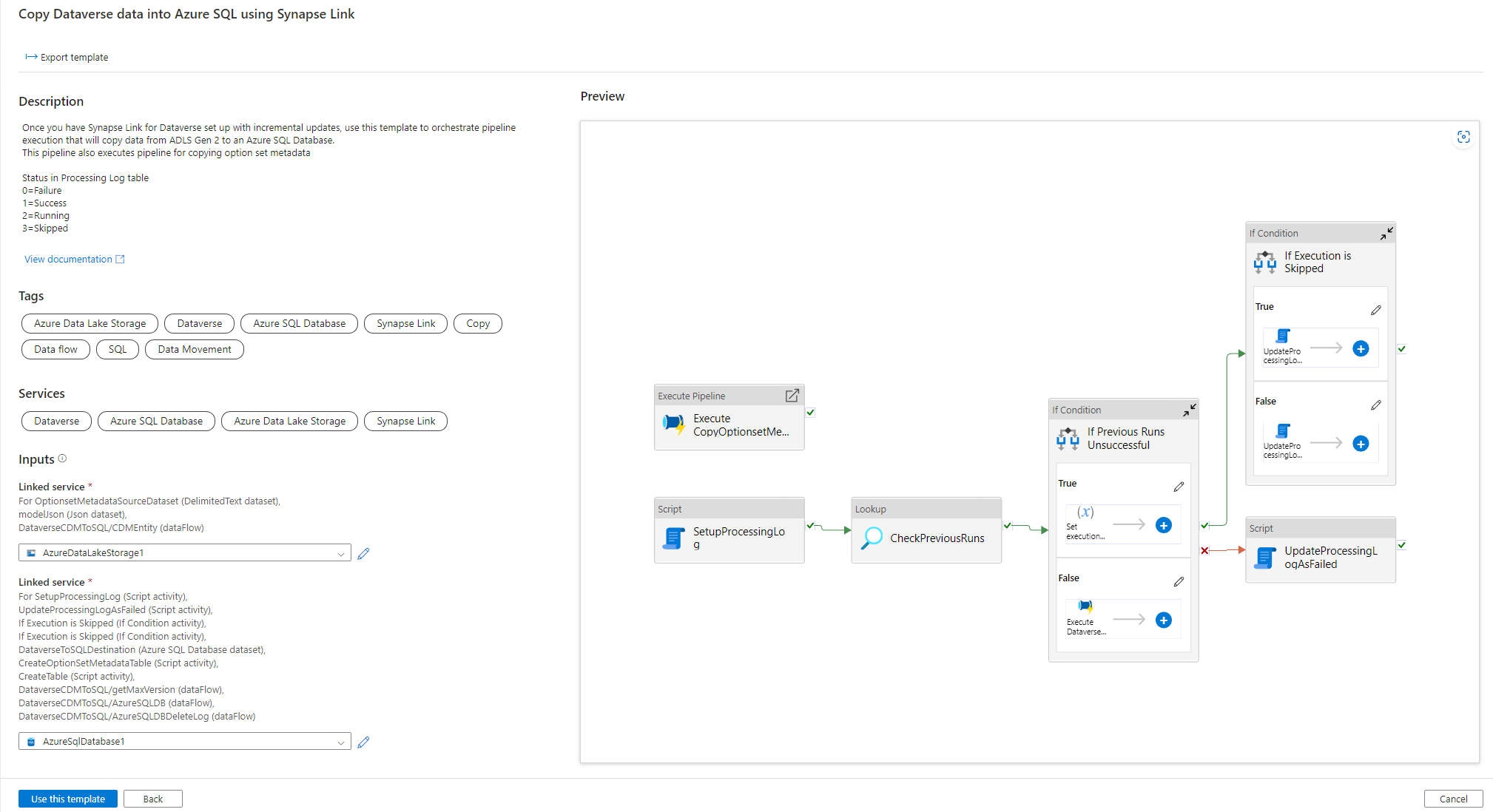
Agora, um gatilho pode ser adicionado para automatizar esse pipeline, para que o pipeline sempre possa processar arquivos quando as atualizações incrementais forem concluídas periodicamente. Vá para Gerenciar > Gatilho e crie um gatilho usando as seguintes propriedades:
- Nome: digite um nome para o gatilho, como triggerModelJson.
- Tipo: Eventos de armazenamento.
- Assinatura do Azure: selecione a assinatura que tem o Azure Data Lake Storage Gen2.
- Nome da conta de armazenamento: selecione o armazenamento que tem os dados do Dataverse.
- Nome do contêiner: selecione o contêiner criado pelo Azure Synapse Link.
- O caminho do blob termina com: /model.json
- Evento: blob criado.
- Ignorar blobs vazios: Sim.
- Iniciar gatilho: habilitar Iniciar gatilho na criação.
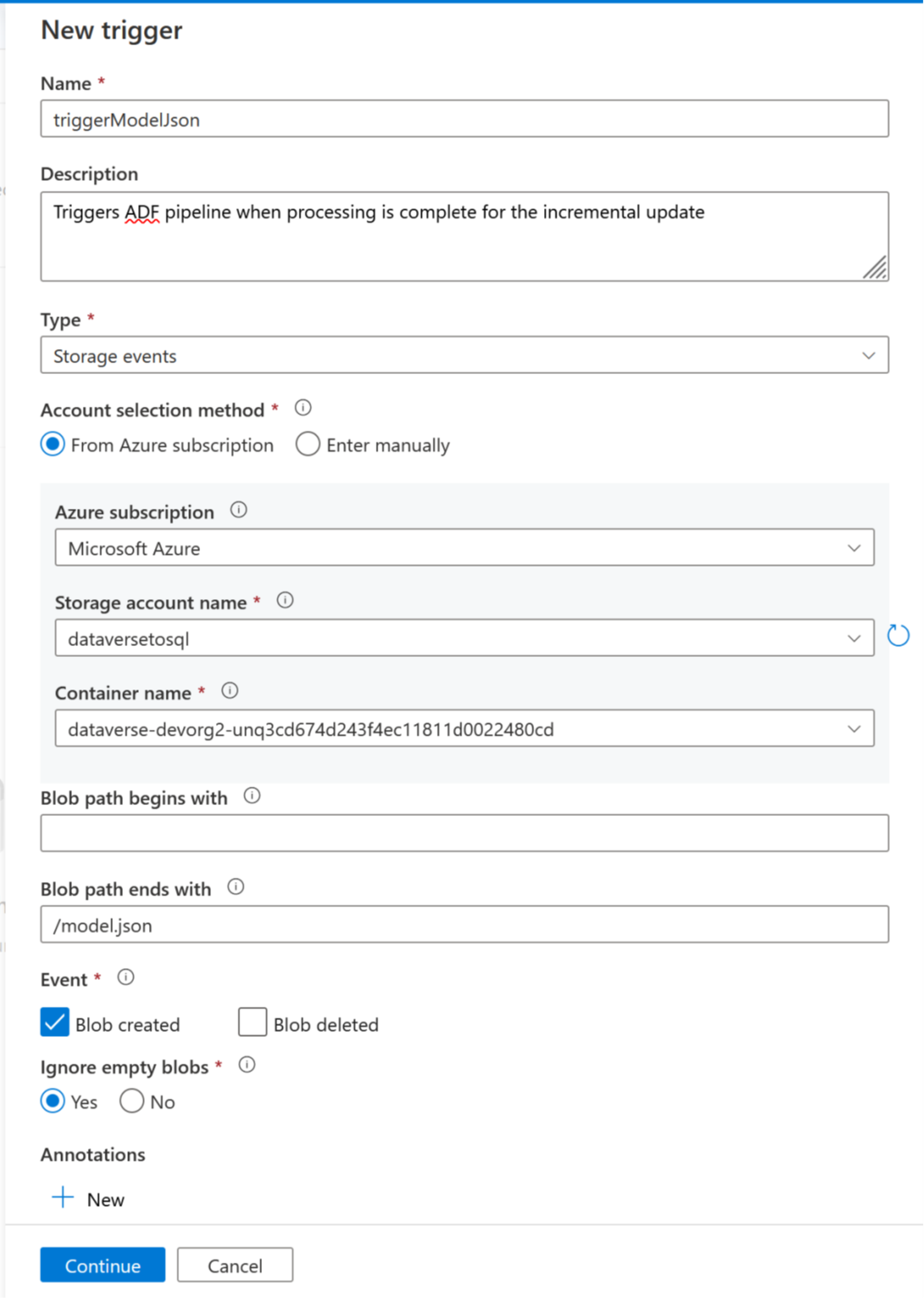
Selecione Continuar para prosseguir para a próxima tela.
Na tela seguinte, o gatilho valida os arquivos correspondentes. Selecione OK para criar o gatilho.
Associe o gatilho a um pipeline. Vá para o pipeline importado anteriormente e selecione Adicionar gatilho > Novo/Editar.
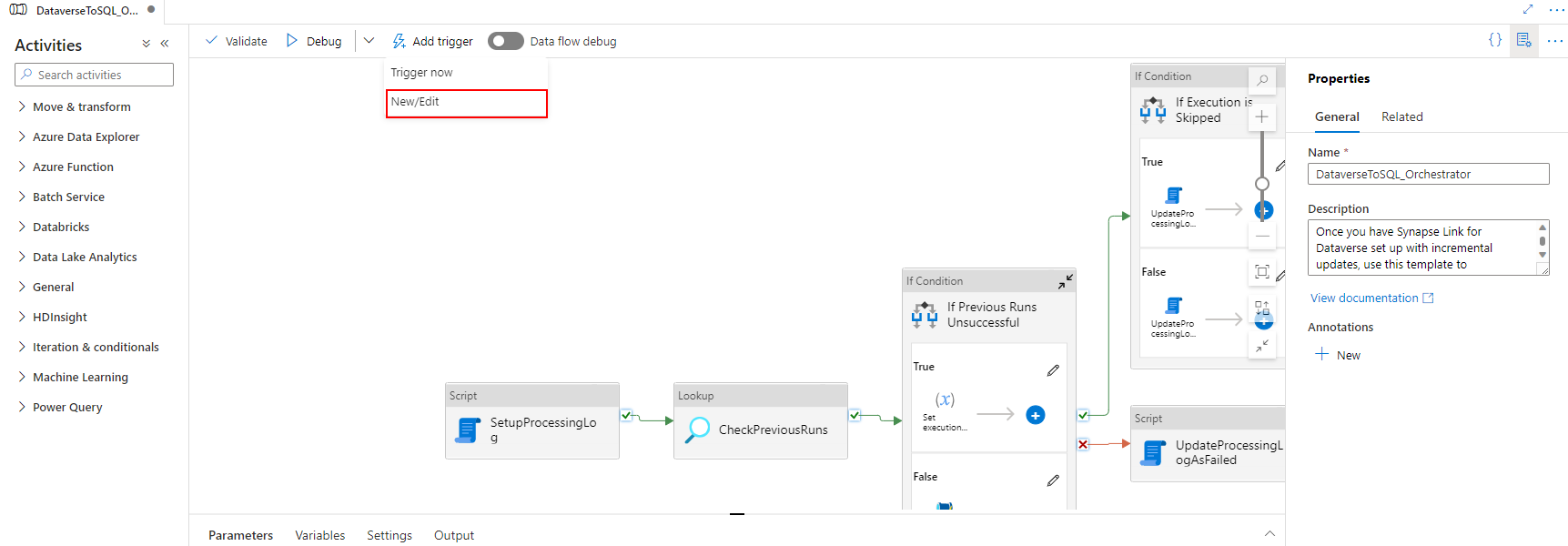
Selecione o gatilho na etapa anterior e, em seguida, selecione Continuar para prosseguir para a próxima tela em que o gatilho valida os arquivos correspondentes.
Selecione Continuar para prosseguir para a próxima tela.
Na seção Parâmetro de Execução de Gatilho, insira os parâmetros abaixo e selecione OK.
- Contêiner:
@split(triggerBody().folderPath,'/')[0] - Pasta:
@split(triggerBody().folderPath,'/')[1]
- Contêiner:
Depois de associar o gatilho ao pipeline, selecione Validar todos.
Quando a validação for bem-sucedida, selecione Publicar Tudo.
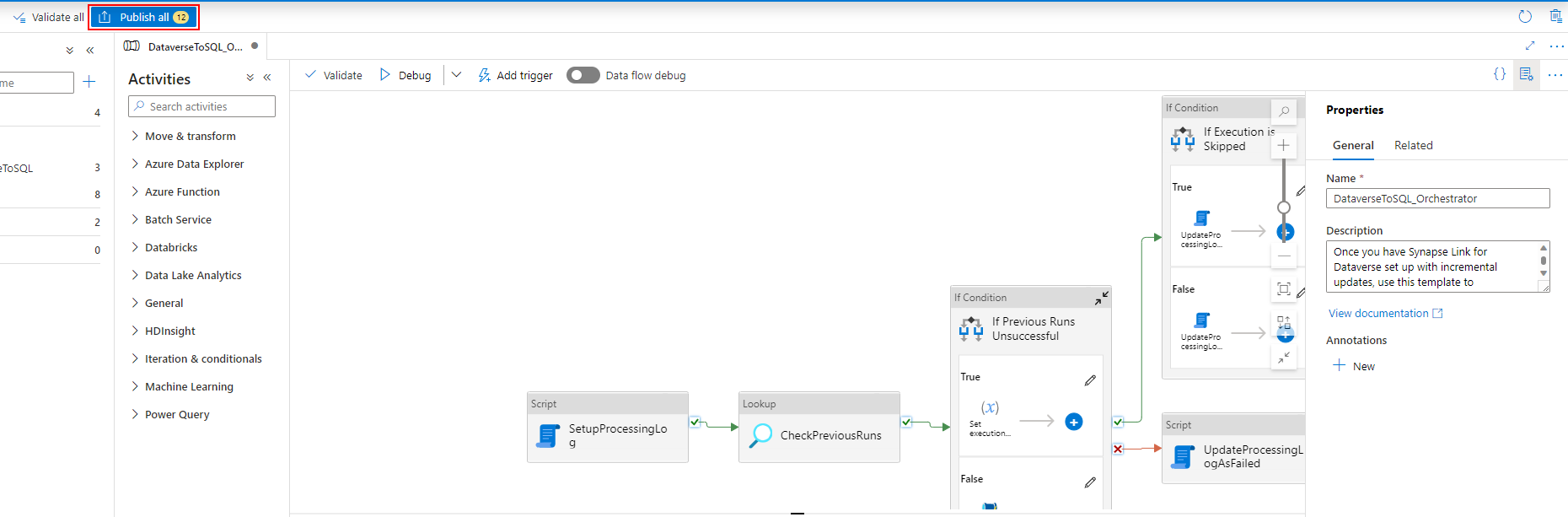
Selecione Publicar para publicar todas as alterações.



Adicionar um filtro de assinatura de evento
Para garantir que o gatilho seja acionado apenas quando a criação do model.json for concluída, os filtros avançados precisam ser atualizados para a assinatura de evento do gatilho. Um evento é registrado na conta de armazenamento na primeira vez que o gatilho é executado.
Quando uma execução de gatilho for concluída, vá para conta de armazenamento > Eventos > Assinaturas de Eventos.
Selecione o evento que foi registrado para o gatilho model.json.
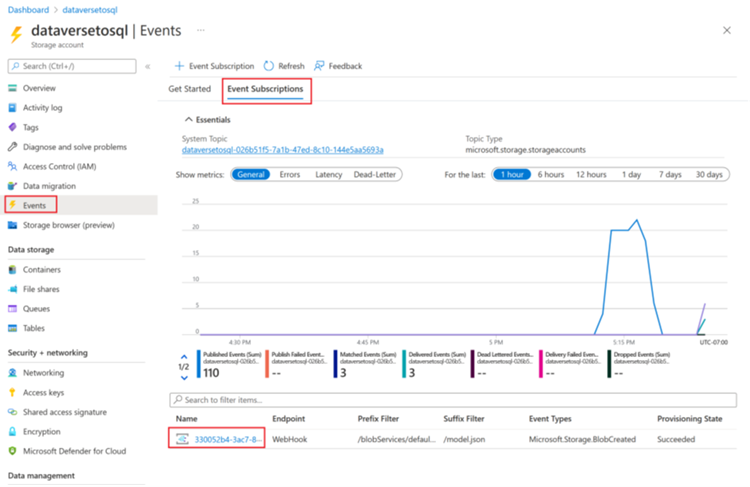
Selecione a guia Filtros e selecione Adicionar Novo Filtro.
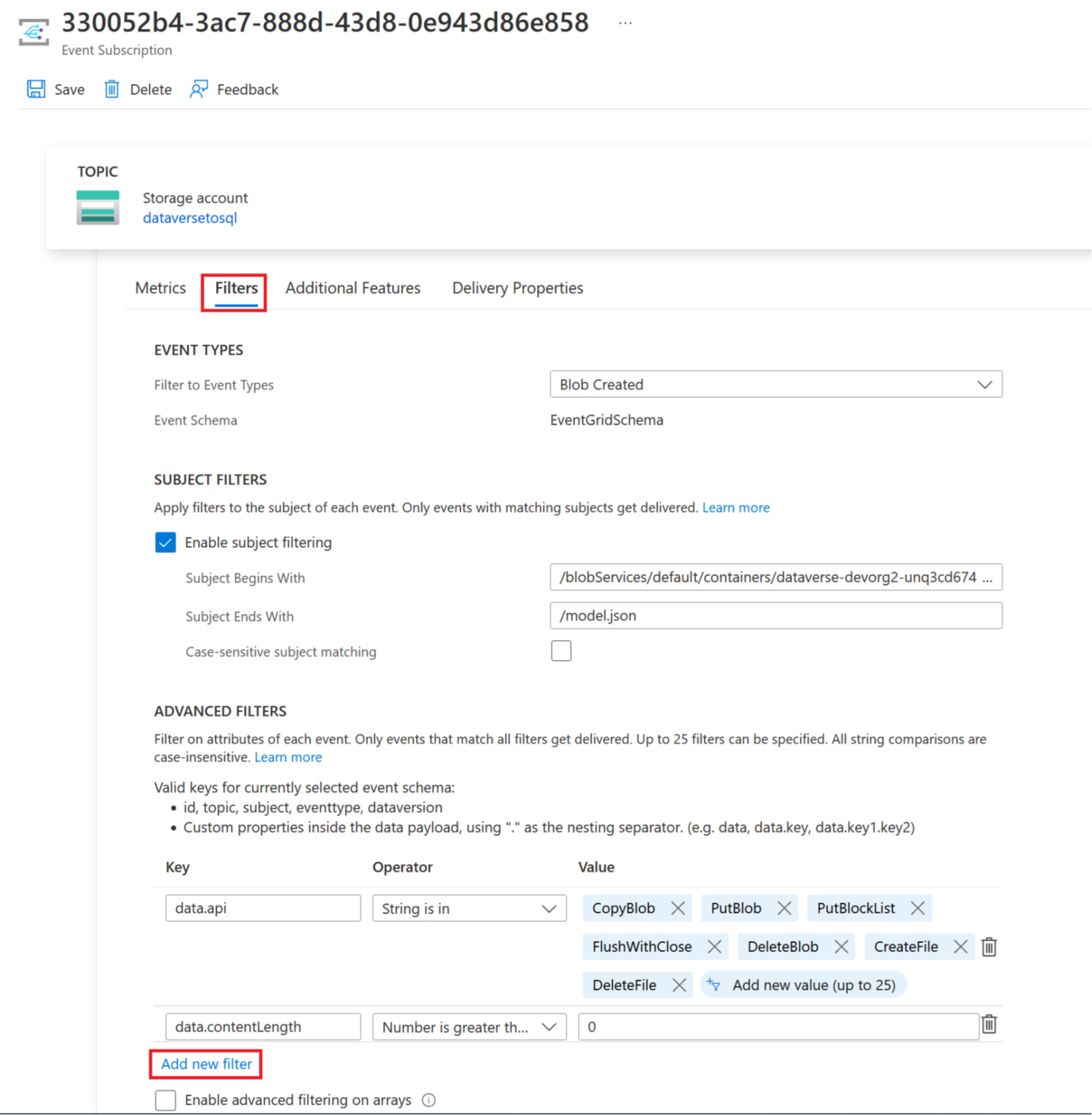
Crie o filtro:
- Chave: assunto
- Operador: A cadeia de caracteres não termina com
- Valor: /blobs/model.json
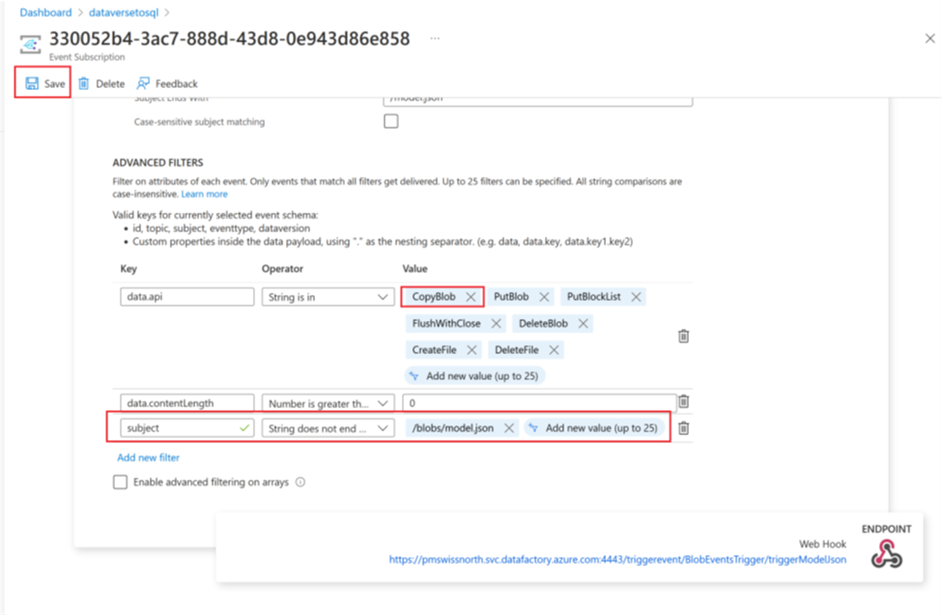
Remova o parâmetro CopyBlob da matriz Valor data.api.
Selecione Salvar para implantar o filtro adicional.
Confira também
Blog: Apresentando o Azure Synapse Link for Dataverse
Observação
Você pode nos falar mais sobre suas preferências de idioma para documentação? Faça uma pesquisa rápida. (Observe que esta pesquisa está em inglês)
A pesquisa levará cerca de sete minutos. Nenhum dado pessoal é coletado (política de privacidade).