Amostragem de alta densidade em gráficos de dispersão do Power BI
O algoritmo de amostragem do Power BI aprimora a forma como os gráficos de dispersão representam dados de alta densidade.
Por exemplo, você pode criar um gráfico de dispersão com base na atividade de vendas de sua organização, com cada loja tendo dezenas de milhares de pontos de dados a cada ano. Um gráfico de dispersão dessas informações obteriam dados de amostra de uma representação significativa dos dados para ilustrar como as vendas ocorreram com o tempo. Os detalhes da amostragem de dados de alta densidade estão descritos neste artigo.

Observação
O algoritmo de Amostragem de alta densidade descrito neste artigo está disponível no gráfico de dispersão do Power BI Desktop e do serviço do Power BI.
Como funcionam os gráficos de dispersão de alta densidade
Anteriormente, o Power BI selecionava uma coleção de pontos de dados de exemplo em toda a gama de dados subjacentes de uma maneira determinística para criar um gráfico de dispersão. Especificamente, o Power BI selecionava as primeira e última linhas de dados na série de gráficos de dispersão e dividia as linhas restantes igualmente, de modo que o total de 3.500 pontos de dados fossem plotados no gráfico de dispersão. Por exemplo, se a amostra tivesse 35.000 linhas, a primeira e a última linha seriam selecionadas para plotagem e, a cada dez linhas, as linhas também seriam plotadas (35.000/10 = a cada dez linhas = 3.500 pontos de dados). Além disso, antes, os pontos ou valores nulos que não podiam ser plotados, como valores de texto, na série de dados não eram mostrados. Portanto, não eram considerados durante a geração do visual. Com essa amostragem, a densidade percebida do gráfico de dispersão também era baseada nos pontos de dados representativos e, portanto, a densidade implícita do visual era uma particularidade dos pontos amostrados e não da coleção completa dos dados subjacentes.
Ao habilitar a Amostragem de alta densidade, o Power BI implementará um algoritmo que elimina os pontos sobrepostos e garante que os pontos no visual possam ser alcançados durante a interação com o visual. O algoritmo também garante que todos os pontos no conjunto de dados sejam representados no visual, fornecendo contexto para o significado dos pontos selecionados, em vez de apenas plotar uma amostra representativa.
Por definição, os dados de alta densidade são amostrados para criar visualizações que atendam à interatividade. Um número muito grande de pontos de dados em um visual pode atrasá-lo e diminuir a visibilidade das tendências. A maneira em que esses dados são amostrados orienta a criação do algoritmo de amostragem para oferecer a melhor experiência de visualização e garantir que todos os dados sejam representados. No Power BI, o algoritmo foi melhorado para fornecer a melhor combinação de capacidade de resposta, representação e preservação clara de pontos importantes no conjunto de dados geral.
Observação
Os gráficos de dispersão que usam o algoritmo de Amostragem de alta densidade são mais bem plotados em visuais quadrados, assim como ocorre com todos os gráficos de dispersão.
Como funciona o algoritmo de amostragem de gráfico de dispersão
O algoritmo de Amostragem de alta densidade para gráficos de dispersão usa métodos que capturam e representam os dados subjacentes com mais eficiência e elimina os pontos sobrepostos. O algoritmo começa com um pequeno raio em cada ponto de dados, que é o tamanho do círculo visual de determinado ponto na visualização. Depois disso, aumenta o raio de todos os pontos de dados. Quando dois ou mais pontos de dados são sobrepostos, um único círculo do tamanho do raio maior representa os pontos de dados sobrepostos. O algoritmo continua aumentando o raio dos pontos de dados até que o valor do raio resulte em um número razoável de pontos de dados (3.500) exibidos no gráfico de dispersão.
Os métodos deste algoritmo garantem que as exceções sejam representadas no visual resultante. O algoritmo respeita a escala ao determinar a sobreposição também, de modo que as escalas exponenciais sejam visualizadas com fidelidade aos pontos subjacentes visualizados.
O algoritmo também preserva a forma geral do gráfico de dispersão.
Observação
Ao usar o algoritmo de Amostragem de alta densidade para gráficos de dispersão, a distribuição precisa dos dados será a meta e não a densidade visual implícita. Por exemplo, você pode ver um gráfico de dispersão com vários círculos sobrepostos (densidade) em uma determinada área e imaginar vários pontos de dados que devem ser agrupados aqui. Como o algoritmo de Amostragem de alta densidade pode usar um círculo para representar muitos pontos de dados, essa densidade visual implícita ou "clustering" não aparecerá. Para obter mais detalhes de determinada área, use as segmentações para ampliar.
Além disso, os pontos de dados que não podem ser plotados, como valores nulos ou valores de texto, são ignorados, para que outro valor que pode ser plotado seja selecionado. Isso garante ainda que a forma verdadeira do gráfico de dispersão seja mantida.
Quando o algoritmo padrão para gráficos de dispersão é usado
Há circunstâncias em que a Amostragem de alta densidade não pode ser aplicada a um gráfico de dispersão e o algoritmo original é usado. Essas circunstâncias são:
Se você clicar com o botão direito do mouse em um valor em Valores e defini-lo como Mostrar itens sem dados no menu, o gráfico de dispersão será revertido para o algoritmo original.
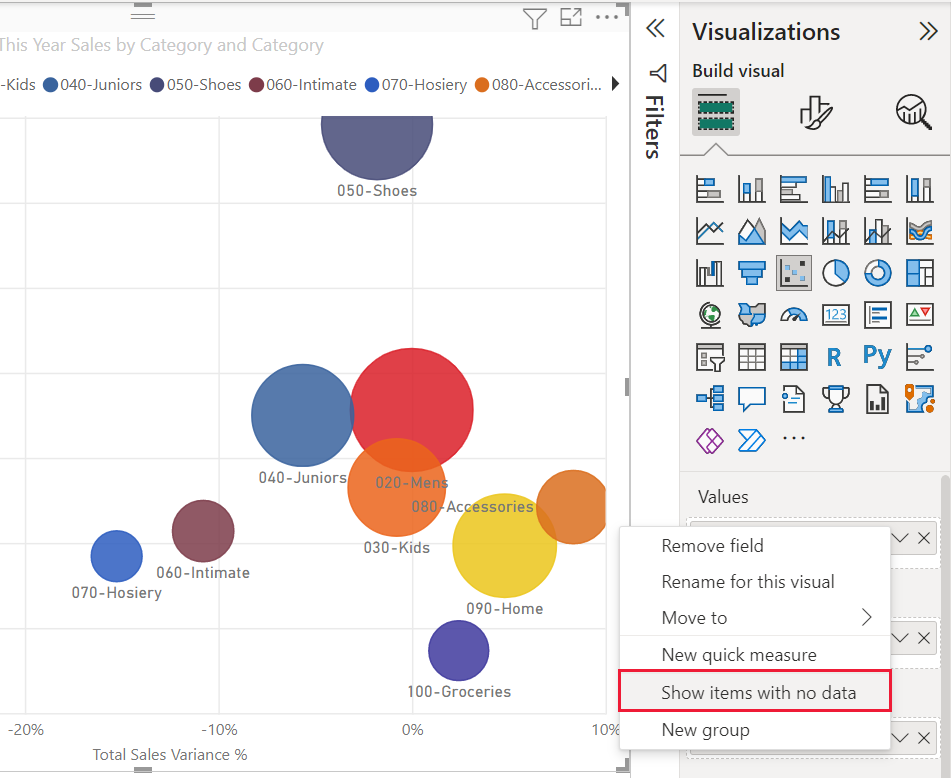
Os valores do eixo Reproduzir resultarão na reversão do gráfico de dispersão para o algoritmo original.
Se os eixos X e Y estiverem ausentes em um gráfico de dispersão, o gráfico será revertido para o algoritmo original.
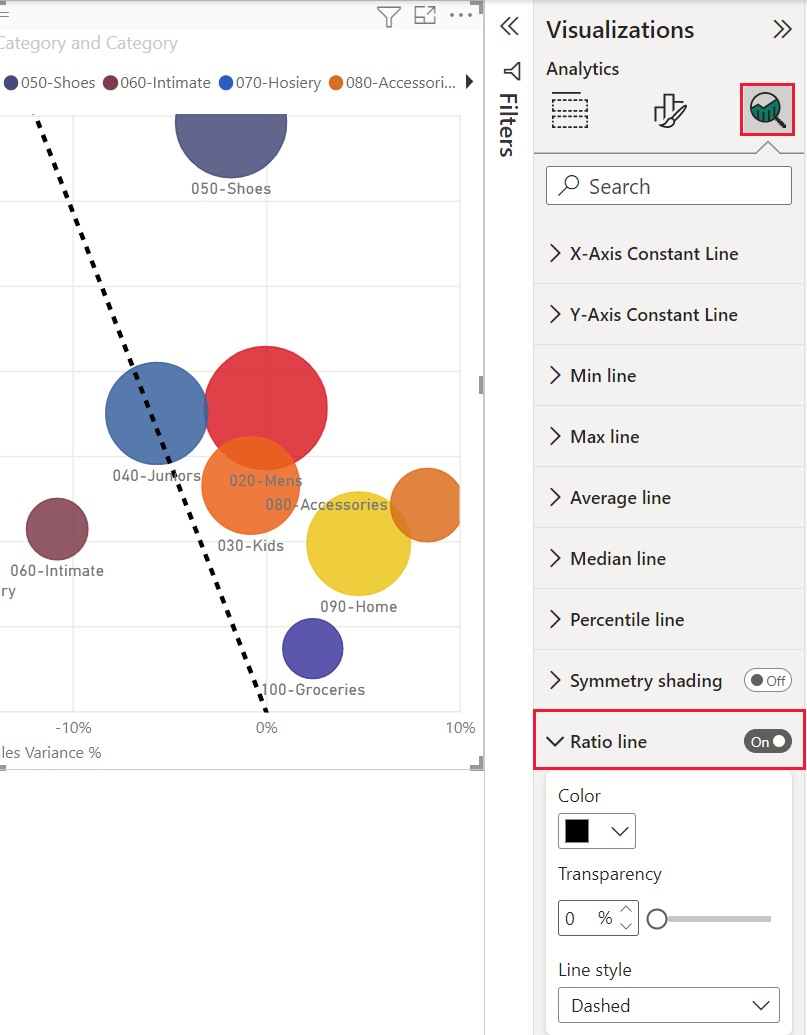
O uso de uma Linha de proporção no painel Análise resulta na reversão do gráfico para o algoritmo original.
Como ativar a amostragem de alta densidade em um gráfico de dispersão
Para colocar a Amostragem de alta densidade em Ativo, selecione um gráfico de dispersão, vá para o painel Visual do formato, expanda o cartão Geral e, próximo ao fim desse cartão, deslize o controle deslizante de alternância Amostragem de alta densidade para Ativar.

Observação
Depois que o controle deslizante for ativado, o Power BI tentará usar o algoritmo de Amostragem de alta densidade sempre que possível. Quando o algoritmo não puder ser usado, por exemplo, você coloca um valor no eixo Reproduzir, o controle permanecerá em Ativado mesmo que o gráfico tenha sido revertido para o algoritmo padrão. Se você remover um valor do eixo Reproduzir ou se mudarem as condições para habilitar o uso do algoritmo de amostragem de alta densidade, o gráfico usará a amostragem de alta densidade automaticamente neste gráfico porque o recurso estará ativo.
Observação
Os pontos de dados são agrupados ou selecionados pelo índice. Ter uma legenda não afeta a amostragem do algoritmo. Isso afeta apenas a ordenação do visual.
Considerações e limitações
O algoritmo de amostragem de alta densidade é uma melhoria importante no Power BI. No entanto, o algoritmo de Amostragem de alta densidade funciona apenas com conexões dinâmicas em modelos baseados no serviço do Power BI, modelos importados ou o DirectQuery.