Entender e otimizar a atualização de fluxos de dados
Os fluxos de dados do Power BI permitem que você se conecte, transforme, combine e distribua para análise de downstream. Um elemento importante nos fluxos de dados é o processo de atualização, que aplica as etapas de transformação criadas nos fluxos de dados e atualiza os dados nos itens.
Para entender os tempos de execução, o desempenho e se você está obtendo o máximo de seu fluxo de dados, você poderá baixar o histórico de atualização após a atualização de um fluxo de dados.
Entender as atualizações
Há dois tipos de atualizações aplicáveis a fluxos de dados:
Completa, que realiza uma liberação e recarga completas de seus dados.
Incremental (somente Premium) , que processa um subconjunto de seus dados com base em regras baseadas em tempo, expressas como um filtro, que você configura. O filtro na coluna de data particiona dinamicamente os dados em intervalos no serviço do Power BI. Depois de configurar a atualização incremental, o fluxo de dados altera automaticamente sua consulta para incluir a filtragem por data. É possível editar a consulta gerada automaticamente usando o Editor Avançado do Power Query para ajustar ou personalizar sua atualização. Se você trouxer seu próprio Azure Data Lake Storage, poderá ver as frações de tempo dos dados com base na política de atualização que definiu.
Observação
Para saber mais sobre atualização incremental e como ela funciona, confira Como usar atualização incremental com fluxos de dados.
A atualização incremental permite fluxos de dados grandes no Power BI com os seguintes benefícios:
As atualizações são mais rápidas após a primeira atualização pelos seguintes motivos:
- O Power BI atualiza as últimas N partições especificadas pelo usuário (onde a partição é dia/semana/mês e assim por diante) ou
- O Power BI atualiza apenas os dados que precisam ser atualizados. Por exemplo, atualizar somente os últimos cinco dias de um modelo semântico de dez anos.
- O Power BI atualiza apenas os dados que foram alterados, desde que você especifique a coluna cujas alterações deseja verificar.
As atualizações são mais confiáveis – não é mais necessário manter conexões longas com sistemas de origem voláteis.
O consumo de recursos é reduzido – um número menor de dados para atualização reduz o consumo geral da memória e de outros recursos.
Sempre que possível, o Power BI emprega processamento paralelo em partições, o que pode levar a atualizações mais rápidas.
Em qualquer um desses cenários de atualização, se uma atualização falhar, os dados não serão atualizados. Seus dados podem ficar obsoletos até que a atualização mais recente seja concluída ou você pode atualizá-los manualmente e eles podem ser concluídos sem erros. A atualização ocorre em uma partição ou entidade, portanto, se uma atualização incremental falhar ou uma entidade tiver um erro, toda a transação de atualização não ocorrerá. Dito de outra forma, se uma partição (política de atualização incremental) ou entidade falhar para um fluxo de dados, toda a operação de atualização falhará e nenhum dado será atualizado.
Entenda e otimize as atualizações
Para entender melhor o desempenho de uma operação de atualização de fluxo de dados, revise o Histórico de atualização do fluxo de dados navegando até um de seus fluxos de dados. Selecione Mais opções (...) para o fluxo de dados. Em seguida, escolha Configurações > Histórico de atualização. Você também pode selecionar o fluxo de dados no Workspace. Em seguida, escolha Mais opções (...) > Histórico de atualização.
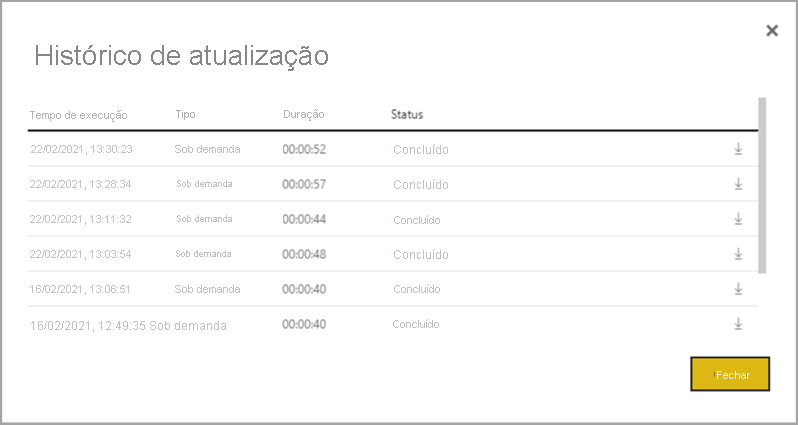
O Histórico de Atualização fornece uma visão geral das atualizações, incluindo o tipo – sob demanda ou agendado, a duração e o status da execução. Para ver detalhes na forma de um arquivo CSV, selecione o ícone de download na extrema direita da linha da descrição de atualização. O CSV baixado inclui os atributos descritos na tabela a seguir. As atualizações Premium fornecem mais informações com base nos recursos extras de computação e fluxo de dados, em comparação aos fluxos de dados baseados no Pro que residem na capacidade compartilhada. Dessa forma, algumas das métricas a seguir estão disponíveis apenas no Premium.
| Item | Descrição | Pro | Premium |
|---|---|---|---|
| Solicitado em | A atualização de tempo foi agendada ou a opção de atualizar agora foi clicada, na hora local. | ✔ | ✔ |
| Nome do fluxo de dados | Nome do seu fluxo de dados. | ✔ | ✔ |
| Status de atualização de fluxo de dados | Concluído, Com falha ou Ignorado (para uma entidade) são status possíveis. Casos de uso como Entidades Vinculadas são motivos pelos quais alguém pode ver Ignorado. | ✔ | ✔ |
| Nome da entidade | Nome da tabela. | ✔ | ✔ |
| Nome da partição | Este item depende se o fluxo de dados é premium ou não e se o Pro é exibido como NA porque não oferece suporte a atualizações incrementais. Premium mostra FullRefreshPolicyPartition ou IncrementalRefreshPolicyPartition-[DateRange]. | ✔ | |
| Atualizar status | Atualize o status da entidade ou da partição individual, que fornece o status dessa fração de tempo dos dados que estão sendo atualizados. | ✔ | ✔ |
| Hora de início | No Premium, esse item corresponde à hora em que o fluxo de dados foi colocado na fila para processamento da entidade ou partição. Essa hora pode se diferenciar dependendo de os fluxos de dados terem dependências e precisarem aguardar o conjunto de resultados de um fluxo de dados upstream para iniciar o processamento. | ✔ | ✔ |
| Hora de término | A hora de término corresponde ao momento em que a entidade ou partição de fluxo de dados foi concluída, se aplicável. | ✔ | ✔ |
| Duration | Tempo total decorrido para a atualização de fluxo de dados expressa em HH:MM:SS. | ✔ | ✔ |
| Linhas processadas | Para uma determinada entidade ou partição, o número de linhas verificadas ou gravadas pelo mecanismo de fluxos de dados. Este item pode não conter dados com base na operação que você executou. Os dados podem ser omitidos quando o mecanismo de computação não é usado ou quando você usa um gateway quando os dados são processados lá. | ✔ | |
| Bytes processados | Para uma determinada entidade ou partição, os dados gravados pelo mecanismo de fluxos de dados, expressos em bytes. Ao usar um gateway nesse fluxo de dados específico, essas informações não serão fornecidas. |
✔ | |
| Confirmação máxima | A Confirmação Máxima é a memória de pico de confirmação, útil para diagnosticar falhas de memória insuficiente quando a consulta M não está otimizada. Quando você usa um gateway nesse fluxo de dados específico, essas informações não são fornecidas. |
✔ | |
| Tempo do Processador | Para uma determinada entidade ou partição, o tempo, expresso em HH:MM:SS, que o mecanismo de fluxo de dados gastou executando transformações. Quando você usa um gateway nesse fluxo de dados específico, essas informações não são fornecidas. |
✔ | |
| Tempo de espera | Para uma determinada entidade ou partição, o tempo que uma entidade gastou no status de espera, com base na carga de trabalho na capacidade Premium. | ✔ | |
| Mecanismo de computação | No caso de uma determinada entidade ou partição, são detalhes sobre como a operação de atualização usa o mecanismo de computação. Os valores são: - ND - Dobrado - Armazenado em cache - Armazenado em cache + Dobrado Esses elementos são descritos em mais detalhes posteriormente neste artigo. |
✔ | |
| Erro | Se aplicável, a mensagem de erro detalhada será descrita por entidade ou partição. | ✔ | ✔ |
Diretrizes de atualização de fluxo de dados
As estatísticas de atualização fornecem informações valiosas que você pode usar para otimizar e acelerar o desempenho de seus fluxos de dados. Nas seções a seguir, descrevemos alguns cenários, o que deve ser observado e como otimizar com base nas informações fornecidas.
Orquestração
O uso de fluxos de trabalho no mesmo workspace que permite a orquestração direta. Por exemplo, você pode ter fluxos de dados A, B e C em um único workspace e encadeamento como A > B > C. Se você atualizar a origem (A), as entidades downstream também serão atualizadas. No entanto, se você atualizar o C, precisará atualizar os outros de forma independente. Além disso, se você adicionar uma nova fonte de dados no fluxo de dados B (que não está incluído em A), esses dados não serão atualizados como parte da orquestração.
Talvez você queira encadear itens que não se ajustam à orquestração gerenciada executada pelo Power BI. Nesses cenários, você pode usar as APIs e/ou usar o Power Automate. Você pode conferir a documentação da API e o script do PowerShell para a atualização programática. Há um conector Power Automate que permite fazer esse procedimento sem escrever nenhum código. Você pode ver exemplos detalhados, com orientações específicas para atualizações sequenciais.
Monitoramento
Usando as estatísticas de atualização aprimoradas descritas anteriormente neste artigo, você pode obter informações detalhadas de atualização por fluxo de dados. Mas, se quiser ver os fluxos de trabalho com visão geral das atualizações de todo o locatário ou de todo o workspace, talvez para criar um painel de monitoramento, você poderá usar as APIs ou modelos do PowerAutomate. Da mesma forma, para casos de uso, como de envio de notificações simples ou complexas, você pode usar o conector PowerAutomate ou criar seu próprio aplicativo personalizado usando as APIs.
Erros do tempo limite
A otimização do tempo necessário para executar os cenários de ELT (extração, transformação e carregamento) é ideal. No Power BI, os seguintes casos se aplicam:
- Alguns conectores têm configurações de tempo limite explícitas que você pode configurar. Para obter mais informações, confira Conectores no Power Query.
- Os fluxos de dados do Power BI, usando o Power BI Pro, também podem experimentar tempos limite para consultas de execução prolongada em uma entidade ou nos próprios fluxos de dados. Essa limitação não existe nos workspaces do Power BI Premium.
Diretrizes de tempo limite
Os limites de tempo limite para fluxos de dados do Power BI Pro são:
- Duas horas no nível da entidade individual.
- Três horas no nível de todo o fluxo de dados.
Por exemplo, se você tiver um fluxo de dados com três tabelas, nenhuma tabela individual poderá levar mais de duas horas e todo o fluxo de dados expirará se a duração exceder três horas.
Se você estiver experimentando tempos limite, considere otimizar suas consultas de fluxo de dados e usar a dobragem de consultas em seus sistemas de origem.
Separadamente, considere fazer a atualização para o Premium por usuário, que não está sujeito a esses tempos limite e oferece maior desempenho devido a vários recursos do Power BI Premium por usuário.
Durações longas
Fluxos de dados complexos ou grandes podem levar mais tempo para serem atualizados, assim como os fluxos de dados mal otimizados. As seções a seguir fornecem orientação sobre como reduzir as durações longas de atualização.
Diretrizes para durações longas de atualização
A primeira etapa para melhorar durações longas de atualização em fluxos de dados é criar fluxos de acordo com as melhores práticas. Padrões notáveis incluem:
- Use entidades vinculadas para dados que possam ser usadas posteriormente em outras transformações.
- Use entidades computadas para armazenar dados em cache, reduzindo o carregamento de dados e a carga de ingestão de dados em sistemas de origem.
- Divida os dados em fluxos de dados de preparo e fluxos de dados de transformação, separando o ETL em diferentes fluxos de dados.
- Otimizar operações de expansão de tabela.
- Siga as diretrizes para fluxos de dados complexos.
Em seguida, ele poderá ajudar a avaliar se você pode usar a atualização incremental.
Usar a atualização incremental pode melhorar o desempenho. É importante que os filtros de partição sejam enviados por push para o sistema de origem quando as consultas forem enviadas para operações de atualização. Enviar os filtros por push significa que a fonte de dados deverá dar suporte à dobragem de consultas ou você poderá expressar a lógica comercial por meio de uma função ou outros meios que possam ajudar o Power Query a eliminar e filtrar arquivos ou pastas. A maioria das fontes de dados que dá suporte a consultas SQL dá suporte à dobragem de consultas, e alguns feeds OData também podem dar suporte à filtragem.
No entanto, fontes de dados como arquivos simples, blobs e feeds da Web normalmente não são compatíveis com filtragem. Nos casos em que o back-end da fonte de dados não oferece suporte ao filtro, ele não pode ser removido. Nesses casos, o mecanismo de mashup compensa e aplica o filtro localmente, o que pode exigir a recuperação do modelo semântico completo da fonte de dados. Essa operação pode fazer com que a atualização incremental seja lenta e o processo pode ficar sem recursos no serviço do Power BI ou no gateway de dados local, se usado.
Dados os vários níveis de suporte de dobragem de consulta para cada fonte de dados, você deve executar a verificação para garantir que a lógica do filtro seja incluída nas consultas de origem. Para facilitar, o Power BI tenta executar essa verificação para você, com indicadores de dobragem de etapas para o Power Query Online. Muitas dessas otimizações são experiências em tempo de design, porém, depois que uma atualização ocorrer, você terá a oportunidade de analisar e otimizar o desempenho da atualização.
Por fim, considere a otimização de seu ambiente. Você pode otimizar o ambiente do Power BI expandindo sua capacidade, dimensionando os gateways de dados corretamente e reduzindo a latência de rede com as seguintes otimizações:
Ao usar as capacidades disponíveis com o Power BI Premium ou Premium por usuário, você poderá melhorar o desempenho aumentando sua instância Premium ou atribuindo o conteúdo a uma capacidade diferente.
O gateway será necessário sempre que o Power BI precisar acessar dados que não estejam diretamente disponíveis pela Internet. Você pode instalar o gateway de dados local em um servidor local ou em uma máquina virtual.
- Para entender as recomendações de dimensionamento e cargas de trabalho de gateways, confira Dimensionamento de gateway de dados local.
- Avalie também trazer os dados primeiro para um fluxo de dados de preparação e fazer referência a downstream usando entidades vinculadas e computadas.
A latência de rede pode afetar o desempenho da atualização do relatório, aumentando o tempo necessário para que as solicitações acessem o serviço do Power BI e para que as respostas sejam entregues. Locatários no Power BI são atribuídos a uma região específica. Para determinar onde seu locatário está localizado, confira Localizar a região padrão para sua organização. Quando os usuários de um locatário acessam o serviço do Power BI, suas solicitações sempre são roteadas para essa região. Quando as solicitações acessam o serviço do Power BI, o serviço pode enviar solicitações extras, por exemplo, para a fonte de dados subjacente ou o gateway de dados, que também estão sujeitos à latência de rede.
- Ferramentas como o Teste de Velocidade do Azure fornecem uma indicação da latência de rede entre o cliente e a região do Azure. Em geral, para minimizar o impacto da latência de rede, empenhe-se para manter fontes de dados, gateways e o cluster do Power BI o mais próximo possível. É preferível que sejam residentes na mesma região. Se a latência de rede for um problema, tente localizar os gateways e as fontes de dados mais próximos do seu cluster do Power BI, colocando-os em máquinas virtuais hospedadas na nuvem.
Tempo de processador alto
Se você observar um alto tempo de processador, provavelmente terá transformações caras que não estão sendo dobradas. O alto tempo do processador é devido ao número de etapas aplicadas que você possui ou ao tipo de transformações que está fazendo. Cada uma dessas possibilidades pode resultar em tempos de atualização mais altos.
Diretrizes para tempo do processador alto
Há duas opções para otimizar o tempo do processador alto.
Primeiro, use a dobragem de consulta na própria fonte de dados, o que deve reduzir a carga no mecanismo de computação de fluxo de dados diretamente. A dobragem de consulta na fonte de dados permite que o sistema de origem faça a maior parte do trabalho. O fluxo de dados pode então passar por consultas no idioma nativo da fonte, em vez de ter que realizar todos os cálculos na memória após a consulta inicial.
Nem todas as fontes de dados podem executar a dobragem de consultas e, mesmo quando for possível dobrar a consulta, poderá haver fluxos de dados que executem determinadas transformações que não possam dobrar para a origem. Nesses casos, o Mecanismo de Computação aprimorado é um recurso introduzido pelo Power BI para melhorar potencialmente o desempenho em até 25 vezes, para transformações especificamente.
Usar o Mecanismo de Computação para maximizar o desempenho
Embora o Power Query tenha visibilidade de tempo de design na dobragem de consultas, a coluna do Mecanismo de Computação fornece detalhes se o mecanismo interno em si foi usado ou não. O Mecanismo de Computação é útil quando você tem um fluxo de dados complexo e está executando transformações na memória. É nessa situação que as estatísticas de atualização avançadas podem ser úteis, pois a coluna do mecanismo de computação fornece detalhes se o mecanismo em si foi ou não usado.
As seções a seguir fornecem orientações sobre como usar o mecanismo de computação e suas estatísticas.
Aviso
Durante o tempo de design, o indicador de dobra no editor pode mostrar que a consulta não é dobrada ao consumir dados de outro fluxo de dados. Verifique o fluxo de dados de origem se a computação aprimorada estiver habilitada para garantir que a dobra no fluxo de dados de origem esteja habilitada.
Diretrizes sobre status do mecanismo de computação
A ativação do mecanismo de computação aprimorado e a compreensão dos vários status é útil. Internamente, o mecanismo de computação aprimorado usa um banco de dados SQL para ler e armazenar dados. É melhor fazer com que suas transformações sejam executadas no mecanismo de consulta aqui. Os seguintes parágrafos fornecem várias situações e orientações sobre o que fazer para cada uma delas.
NA: esse status significa que o mecanismo de computação também não foi usado porque:
- Você está usando fluxos de dados do Power BI Pro.
- Você desativou explicitamente o mecanismo de computação.
- Você está usando a dobragem de consultas na fonte de dados.
- Você está executando transformações complexas que não podem usar o mecanismo SQL usado para acelerar as consultas.
Se você estiver experimentando longas durações e ainda tiver um status NA, certifique-se de que ele esteja ativado e não tenha sido desativado acidentalmente. Um padrão recomendado é usar fluxos de dados de preparo para colocar inicialmente seus dados no serviço do Power BI e criar fluxos de dados sobre esses dados depois que eles estiverem em um fluxo de dados de preparo. Esse padrão pode reduzir a carga em sistemas de origem e, junto com o Mecanismo de Computação, fornecer um aumento de velocidade para transformações e melhorar o desempenho.
Em cache: se você vir o status em cache, os dados do fluxo de dados foram armazenados no mecanismo de computação e estão disponíveis para serem referenciados como parte de outra consulta. Essa situação é ideal se você estiver usando como uma entidade vinculada, porque o mecanismo de computação armazena esses dados em cache para uso downstream. Os dados armazenados em cache não precisam ser atualizados várias vezes no mesmo fluxo de dados. Essa situação também será potencialmente ideal se você quiser usar os dados no DirectQuery.
Quando armazenado em cache, o impacto no desempenho na ingestão inicial é compensado mais tarde, no mesmo fluxo de dados ou em um fluxo de dados diferente no mesmo workspace.
Se você tiver uma duração grande para a entidade, considere desativar o mecanismo de computação. Para armazenar em cache a entidade, o Power BI a grava no armazenamento e no SQL. Se for uma entidade de uso único, o benefício de desempenho para os usuários pode não valer a desvantagem da ingestão dupla.
Dobrado: significa que o fluxo de dados conseguiu usar a computação SQL para ler dados. A entidade calculada usou a tabela do SQL para ler dados e o SQL usado está relacionado aos constructos de sua consulta.
O status dobrado aparecerá se, quando você estiver usando fontes de dados locais ou na nuvem, primeiro você tiver carregado os dados em um fluxo de dados de preparo e fez referência a ele nesse fluxo de dados. Esse status se aplica somente a entidades que fazem referência a outra entidade. Isso significa que suas consultas foram executadas na parte superior do mecanismo SQL e, portanto, têm o potencial de serem melhoradas com a computação SQL. Para garantir que o mecanismo do SQL processe suas transformações, use as transformações que oferecem suporte à dobragem de SQL, como mesclar (juntar), agrupar por (agregação) e anexar (união) ações no Editor de consultas.
Em cache + Dobrado: quando você vir em cache + dobrado, é provável que a atualização de dados seja otimizada, pois há uma entidade que faz referência a outra entidade e é referenciada por outra entidade upstream. Essa operação também é executada sobre o SQL e, como tal, também tem potencial para melhorias com a computação do SQL. Para ter certeza de que você está obtendo o melhor desempenho possível, use transformações que dão suporte ao dobramento de SQL, como ações de mesclagem (junção), agrupamento por (agregação) e acréscimo (união) no Editor do Power Query.
Diretrizes para otimização de desempenho do mecanismo de computação
As etapas a seguir permitem que cargas de trabalho acionem o mecanismo de computação e, assim, melhorem o desempenho.
Para entidades computadas e vinculadas no mesmo workspace:
Para a ingestão, concentre-se em colocar os dados no armazenamento o mais rápido possível, usando filtros somente se eles reduzirem o tamanho geral do modelo semântico. Mantenha sua lógica de transformação separada desta etapa. Em seguida, separe sua transformação e lógica de negócios em um fluxo de dados separado no mesmo workspace. Use entidades vinculadas ou computadas. Isso permite que o mecanismo ative e acelere seus cálculos. Para uma simples analogia, é como a preparação do alimento na cozinha: a preparação do alimento normalmente é uma etapa separada e distinta da coleta dos ingredientes brutos e um pré-requisito para colocar a comida no forno. Da mesma forma, você precisa preparar sua lógica separadamente antes que ela possa aproveitar o mecanismo de computação.
Lembre-se de executar as operações que são dobradas, como mesclagens, junções, conversão e outras.
Além disso, criar fluxos de dados dentro das diretrizes e das limitações publicadas.
Quando o mecanismo de computação está ativado, mas o desempenho é lento:
Execute as etapas a seguir ao investigar cenários em que o mecanismo de computação está ativado, mas você está vendo um desempenho ruim:
- Limite as entidades computadas e vinculadas que existem no workspace.
- Se a atualização inicial for com o mecanismo de computação ativado, os dados serão gravados no lake e no cache. Essa gravação dupla resulta em atualizações mais lentas.
- Se você tiver uma vinculação de fluxo de dados com vários fluxos de dados, lembre-se de agendar as atualizações dos fluxos de dados de origem para que eles não sejam todos atualizados simultaneamente.
Considerações e limitações
Uma licença do Power BI Pro tem um limite de atualização de fluxos de dados de oito atualizações por dia.