Referência de sintaxe FAST Query Language (FQL)
Saiba mais sobre como criar consultas de pesquisa complexa da Pesquisa do SharePoint usando FQL (FAST Query Language). Esta referência descreve os elementos de uma consulta FQL e como usar especificações de propriedade, expressões de token e operadores em consultas FQL.
Introdução a subexpressões e expressões de linguagem de consulta e FQL no SharePoint
O FQL (FAST Query Language) é uma linguagem de consulta avançada que permite que os desenvolvedores realizem pesquisas exatas e restrinjam o escopo da pesquisa a valores pertencentes a uma propriedade gerenciada específica ou um índice de texto completo.
Uma expressão de linguagem de consulta pode conter subexpressões aninhadas que incluem termos de consulta, especificações de propriedade e operadores, conforme descrito na Tabela 1.
Tabela 1. Subexpressões em expressões de linguagem de consulta
| Item | Descrição |
|---|---|
| Expressões de token | Um ou mais termos de consulta, frases ou valores numéricos para pesquisar em uma consulta. |
| Especificação de propriedade | Um índice de propriedade ou texto completo para corresponder à expressão afetada. |
| Operadores | As palavras-chave que especificam operações Boolianas (como AND e OR) ou outras restrições para operandos (como FILTER.) |
Exemplo de consulta FQL
O exemplo de consulta FQL a seguir procura os termos "olá" e "mundo" na propriedade gerenciada body de um item indexado:
body:string("hello world", mode="and")
No exemplo:
-
body:limita o escopo da consulta à propriedade gerenciada body no item. -
"hello world"é o operando para o operador STRING que indica os termos para pesquisar. -
mode="and"indica que o operador de consulta lógica AND será aplicado a"hello world".
O comprimento de consultas de FAST Query Language é limitado a 2.048 caracteres.
Especificação de propriedade no FQL
Uma especificação de propriedade limita o escopo da expressão afetada a regiões específicas do conteúdo indexado. Uma região pode ser identificada por um índice de texto inteiro ou uma propriedade gerenciada.
Propriedades gerenciadas de tipo Text e YesNo são avaliadas como texto. Todos os outros tipos de propriedades gerenciadas, incluindo o tipo Datetime, são avaliados como valores numéricos.
Se você não incluir uma especificação de propriedade de uma expressão, o mecanismo de pesquisa tentará fazer a correspondência com o índice de texto completo padrão definido no esquema de índice.
O nome da propriedade sempre deve preceder dois-pontos (operador In), e operadores numéricos sempre devem incluir uma especificação de propriedade.
Uma especificação de propriedade (o operador In) pode ser aplicada às seguintes entidades de consulta:
Um único termo ou frase, da seguinte maneira:
author:shakespeare title:"to be or not to be"Um operador, por exemplo, o operador STRING, da seguinte maneira:
title:string("to be or not to be")Nesse caso, a especificação da propriedade se aplica à expressão completa do operador.
Exemplos
Cada uma das seguintes expressões corresponde a itens que têm "muito" e "nada" na propriedade gerenciada title.
title:and(much, nothing)
and(title:much, title:nothing)
title:string("much nothing", mode="and")
Expressões de token em FQL
As expressões de token são palavras, frases ou valores numéricos correspondentes ao índice.
Uma expressão de token de texto pode ser uma única palavra ou frase entre aspas duplas.
Uma expressão numérica de token pode ser uma expressão de intervalo de valores ou um único valor.
Expressões curinga
Uma expressão curinga indica um único termo ou frase que inclui o caractere de asterisco ("*"). O asterisco sugere uma correspondência de zero ou mais caracteres, exceto espaços em branco. O FQL dá suporte à pesquisa de prefixo para propriedades gerenciadas de texto individuais e índices de texto completo.
Exemplos de expressões curinga
Esta é uma lista de usos válidos de expressões curinga no FQL:
text*string("this examp*")
Expressões de termo numérico
Cada expressão de termo numérico deve incluir uma especificação de propriedade de um tipo de dados de esquema de índice compatível. A Tabela 2 lista os tipos de dados numéricos que podem ser usados no FQL.
Tabela 2. Tipos de dados numéricos que podem ser utilizados no FQL
| Tipo FQL | Tipos de esquema de índice compatíveis | Descrição |
|---|---|---|
| Int | Integer | Inteiro de 64 bits. |
| Float | Double | Ponto flutuante de 64 bits (dupla precisão). |
| Decimal | Decimal | Decimal de 128 bits |
| Datetime | Datetime | Um valor de data e hora. O suporte a data/hora no FQL habilita as mesmas operações numéricas nos valores de data/hora que outros valores numéricos. |
Expressões de consulta de data e hora
O FQL fornece o tipo de dados datetime para data e hora.
Os seguintes formatos de datetime compatíveis com ISO 8601 têm suporte em consultas:
- AAAA-MM-DD
- AAAA-MM-DDThh:mm:ss
- YYYY-MM-DDThh:mm:ssZ
- YYYY-MM-DDThh:mm:ssfrZ
Nestes formatos de datetime:
AAAA especifica um ano de quatro dígitos.
Observação
Há suporte apenas para anos com quatro dígitos.
MM especifica um mês de dois dígitos. Por exemplo, 01 = janeiro.
DD especifica um dia de dois dígitos do mês (01 a 31).
T especifica a letra "T".
hh especifica uma hora de dois dígitos (de 00 a 23); Indicação AM/PM não é permitida..
mm especifica um minuto de dois dígitos (de 00 a 59).
ss especifica um segundo de dois dígitos (de 00 a 59).
fr especifica uma fração opcional de segundos, ss; entre 1 e 7 dígitos que se seguem a . após os segundos. Por exemplo, 2012-09-27T11:57:34.1234567.
Todos os valores de data/hora devem ser especificados de acordo com o UTC (Tempo Universal Coordenado), também conhecido como fuso de horário GMT (Hora de Greenwich). O identificador de zona de tempo do UTC (um caractere "Z" à direita) é opcional.
Palavras reservadas, caracteres especiais e escape
As palavras a seguir são reservadas no FQL.
and, or, any, andnot, count, decimal, rank, near, onear, int, in32, int64, float, double, datetime, max, min, range, phrase, scope, filter, not, string, starts-with, ends-with, equals, words, xrank.
Se você quiser expressar qualquer uma dessas palavras como termos em expressões de consulta, coloque-as entre aspas duplas, conforme mostrado nos seguintes exemplos:
or("any", "and", "xrank")string("any and xrank", mode="OR")phrase(this, is, a, "phrase")
Dica
Palavras e caracteres reservados não diferenciam maiúsculas de minúsculas, mas o uso de caracteres minúsculos é recomendado para compatibilidade futura.
O FQL nem sempre exige que uma cadeia de caracteres seja colocada entre aspas duplas. Por exemplo, and(cat, dog) é FQL válido, embora cat e dog não estejam entre aspas duplas. No entanto, recomendamos usar aspas duplas para evitar conflitos com palavras reservadas.
Os termos de consulta são indexados de acordo com a configuração de localidade. O processo de geração de tokens remove caracteres especiais. Como os caracteres especiais são removidos, as expressões FQL a seguir são equivalentes.
and("[king]", "<queen>")
and("king", "queen")
Quando uma consulta inclui termos de entrada do usuário ou outro aplicativo, use o operador string("<query terms>", mode="AND|OR|PHRASE") para evitar conflito com palavras reservadas na linguagem de consulta. Você também deve remover possíveis aspas duplas da consulta fornecida pelo usuário.
Operadores FQL
Os operadores FQL (FAST Query Language) são palavras-chave que especificam operações Boolianas outras restrições para operandos. A sintaxe do operador FQL é a seguinte:
[property-spec:]operator(operand [,operand]* [, parameter="value"]*)
Na sintaxe:
- property-spec é uma especificação de propriedade opcional seguida do operador "in".
- operator é uma palavra-chave que especifica a execução de uma operação.
- operand é uma expressão de termo ou outro operador.
- parameter é o nome de um valor que altera o comportamento do operador.
- valor é o valor a ser usado para o nome do parâmetro.
Os nomes de operadores, os nomes de parâmetros e os valores de texto de parâmetro diferenciam maiúsculas de minúsculas. Os espaços em branco são permitidos no corpo do operador, mas são ignorados, a menos que estejam entre aspas duplas. O comprimento de consultas de FAST Query Language é limitado a 2.048 caracteres.
A Tabela 3 lista os tipos de operadores com suporte no FQL.
Tabela 3. Tipos de operador suportados por FQL
| Tipo | Descrição | Operadores |
|---|---|---|
| String | Permite que você especifique operações de consulta em uma cadeia de caracteres de termos. Esse é o operador mais comum para usar em termos de texto. | STRING |
| Boolean | Permite combinar termos e subexpressões em uma consulta. | AND, OR, ANY, ANDNOT, NOT, COUNT, COUNT |
| Proximidade | Permite especificar a proximidade dos termos de consulta em uma sequência de texto correspondente. | NEAR, ONEAR, PHRASE, STARTS-WITH, ENDS-WITH, EQUALS |
| Numeric | Permite especificar condições numéricas na consulta. | RANGE , INT, FLOAT, DATETIME, DECIMAL |
| Relevância | Permite afetar a avaliação de relevância de uma consulta. | XRANK e FILTRO |
A Tabela 4 fornece uma lista de operadores com suporte.
Tabela 4. Operadores suportados pelo FQL
| Operator | Descrição | Tipo |
|---|---|---|
| AND | Retorna somente os itens que correspondem a todos os operandos AND. | Boolean |
| ANDNOT | Retorna somente os itens que correspondem ao primeiro operando e que não correspondem aos operandos subsequentes. | Boolean |
| ANY | Semelhante ao operador OR, exceto que a classificação dinâmica (a pontuação de relevância em result set.md) não é afetada pelo número de operandos correspondentes nem pela distância entre os termos no item. | Boolean |
| COUNT | Permite especificar o número de ocorrências de termos de consulta que um item deve incluir para ser retornado como um resultado. O operando pode ser um termo de consulta simples, uma frase ou termos de consulta curinga. | Boolean |
| DATETIME | Fornece tipos explícitos de valores numéricos. A conversão de tipo explícito é opcional e geralmente não é necessária. O tipo de termo de consulta é detectado de acordo com o tipo de propriedade gerenciada numérica de destino. | Numeric |
| DECIMAL | Fornece tipos explícitos de valores numéricos. A conversão de tipo explícito é opcional e geralmente não é necessária. O tipo de termo de consulta é detectado de acordo com o tipo de propriedade gerenciada numérica de destino. | Numeric |
| ENDS-WITH | Especifica que uma palavra ou frase deve aparecer no final de uma propriedade gerenciada. | Proximidade |
| EQUALS | Especifica que uma palavra, um termo de frase ou uma frase deve fornecer uma correspondência de token exata com a propriedade gerenciada. | Proximidade |
| FILTER | Usado para consultar os metadados ou outros dados estruturados. | Relevância |
| FLOAT | Fornece tipos explícitos de valores numéricos. A conversão de tipo explícito é opcional e geralmente não é necessária. O tipo de termo de consulta é detectado de acordo com o tipo de propriedade gerenciada numérica de destino. | Numeric |
| INT | Fornece tipos explícitos de valores numéricos. A conversão de tipo explícito é opcional e geralmente não é necessária. O tipo de termo de consulta é detectado de acordo com o tipo de propriedade gerenciada numérica de destino. | Numeric |
| NEAR | Restringe o conjunto de resultados a itens que têm N termos a uma certa distância entre si. |
Proximidade |
| NOT | Retorna somente os itens que excluem o operando. | Boolean |
| ONEAR | A variante ordenada de NEAR e requer uma correspondência ordenada dos termos. O operador ONEAR pode ser usado para restringir o conjunto de resultados a itens que têm N termos a uma certa distância. Retorna somente os itens que não correspondem ao operando. O operando pode ser qualquer expressão FQL válida.uma ou outra. |
Proximidade |
| OU | Retorna somente os itens que correspondem a pelo menos um dos operandos OR. Itens correspondentes terão uma classificação dinâmica maior (pontuação de relevância em result set.md) se mais operandos OR forem correspondentes. | Boolean |
| PHRASE | Retorna somente os itens que correspondem a uma cadeia de caracteres de tokens exata. | Proximidade |
| RANGE | Habilita expressões correspondentes ao intervalo. O operador RANGE é usado para propriedades gerenciadas numéricas e de data/hora. | Numeric |
| STARTS-WITH | Especifica que uma palavra ou frase deve aparecer no início de uma propriedade gerenciada. | Proximidade |
| STRING | Definir uma condição de correspondência Booliana para uma cadeia de caracteres de texto. | String |
| XRANK | Permite aumentar a classificação dinâmica de itens com base em determinadas ocorrências de termos sem alterar os itens que correspondem à consulta. Uma expressão XRANK tem um componente que deve ser correspondente e um ou mais componentes que contribuem apenas para a classificação dinâmica. | Relevância |
Observação
No SharePoint, o operador RANK foi preterido e não terá mais efeito. Use XRANK em vez disso.
E
Retorna somente os itens que correspondem a todos os operandos AND. Os operandos podem ser um termo único ou qualquer subexpressão FQL válida.
Sintaxe
and(operand, operand [, operand]*)
Parâmetros
Não aplicável.
Exemplos
A expressão a seguir corresponde a itens para os quais o índice de texto completo padrão contém "gato", "cachorro" e "raposa".
and(cat, dog, fox)
ANDNOT
Retorna somente os itens que correspondem ao primeiro operando e que não correspondem aos operandos subsequentes. Os operandos podem ser um termo único ou qualquer subexpressão FQL válida.
Sintaxe
andnot(operand, operand [,operand]*)
Parâmetros
Não aplicável.
Exemplos
Exemplo 1. A expressão a seguir corresponde a itens para os quais o índice de texto completo padrão contém "gato", mas não "cachorro".
andnot(cat, dog)
Exemplo 2. A expressão a seguir corresponde a itens para os quais o índice de texto completo padrão contém "cachorro", mas não contém "beagle" nem "chihuahua".
andnot(dog, beagle, chihuahua)
ANY
Observação
No SharePoint, o operador ANY foi preterido. Use o operador OR em vez disso.
Semelhante ao operador OR, exceto que a classificação dinâmica (a classificação de relevância no conjunto de resultados) não é afetada pelo número de operandos correspondentes nem pela distância entre os termos no item. Os operandos podem ser um termo único ou qualquer subexpressão FQL válida.
O componente de classificação dinâmica para essa parte da consulta se baseia no termo com melhor correspondência na expressão ANY.
Observação
A diferença em relação a OR está relacionada apenas à classificação no conjunto de resultados. O mesmo conjunto de total de itens corresponderá à consulta.
Sintaxe
any(operand, operand [,operand]*)
Parâmetros
Não aplicável.
Exemplos
A expressão a seguir corresponde a itens para os quais o índice de texto completo padrão contém "gato" ou "cachorro".
Se o índice contiver "gato" e "cachorro", mas "gato" for considerado uma correspondência melhor, a classificação dinâmico do item se baseará em "gato"m sem considerar "cachorro".
any(cat, dog)
COUNT
Especifica o número de ocorrências de termos de consulta que um item deve incluir para ser retornado como um resultado. O operando pode ser um termo de consulta simples, uma frase ou um termo de consulta curinga.
Sintaxe
property-spec:count(operand [,from=<numeric value>, to=<numeric value>])
Parâmetros
| Parâmetro | Valor | Descrição |
|---|---|---|
| De | <valor_numérico> | O valor do parâmetro de deve ser um número inteiro positivo que especifica o número mínimo de vezes que o operando especificado deve ser correspondido. Se o parâmetro de não for especificado, nenhum limite inferior existirá. |
| to | <valor_numérico> | O valor do parâmetro para deve ser um número inteiro positivo que especifica o número máximo não inclusivo de vezes que o operando especificado deve ser correspondido. Por exemplo, um valor de a de 11 especifica 10 vezes ou menos. Se o parâmetro para não for especificado, não existirá nenhum limite superior. |
Exemplos
Exemplo 1. A expressão a seguir corresponde a pelo menos cinco ocorrências da palavra "gato".
count(cat, from=5)
Exemplo 2. A expressão a seguir corresponde a pelo menos cinco, mas não 10 ou mais ocorrências da palavra "gato".
count(cat, from=5, to=10)
Exemplo 3. Cada uma das expressões a seguir corresponde a pelo menos três ocorrências de determinada palavra, e essa palavra pode ser "gato" ou "cachorro".
count(or(cat, dog), from=3)count(string("cat dog", mode="or"), from=3)
A tabela a seguir contém exemplos de valores de cadeia de caracteres de propriedade gerenciada e informa se correspondem às duas expressões do Exemplo 3.
| Correspondeu? | Texto |
|---|---|
| Sim | Meu gato gosta de meu cachorro, mas meu cachorro detesta meu gato. |
| Não | Meu pássaro gosta da minha salamandra, mas meu cachorro detesta meu gato. |
DATETIME
Fornece digitação explícita de valores numéricos de data/hora. O operando é uma cadeia de caracteres de data/hora formatada de acordo com a sintaxe especificada em Expressões de token em FQL.
A conversão de tipo explícito é opcional e geralmente não é necessária. O tipo de termo de consulta é detectado de acordo com o tipo de propriedade gerenciada numérica de destino.
Sintaxe
datetime(<date/time string>)
Parâmetros
Não aplicável.
DECIMAL
Fornece digitação explícita de valores decimais. O operando é um valor decimal de acordo com a sintaxe especificada em Expressões de token em FQL.
A conversão de tipo explícito é opcional e geralmente não é necessária. O tipo de termo de consulta é detectado de acordo com o tipo de propriedade gerenciada numérica de destino.
Sintaxe
decimal(<decimal point value>)
Parâmetros
Não aplicável.
ENDS-WITH
Especifica que uma palavra ou frase deve aparecer no final de uma propriedade gerenciada (correspondência de limite).
Não há suporte para correspondência de limite em propriedades gerenciadas numéricas. Propriedades gerenciadas numéricas são sempre sujeitas à correspondência exata ou de intervalo de valores.
Alguns aplicativos podem exigir que você possa executar uma correspondência exata de uma propriedade gerenciada. Por exemplo, isso pode ser uma propriedade gerenciada product name em que o nome completo de um produto é uma subcadeia de caracteres de outro nome de produto.
Sintaxe
ends-with(<term or phrase>)
Parâmetros
Não aplicável.
Exemplos
A expressão a seguir corresponde a itens com os valores "Sr. Diogo Martins" e "Diogo Martins" na propriedade gerenciada "autor". Não fará a correspondência com itens com o valor "Diogo Martins sr".
author:ends-with("adam jones")
Comentários
A correspondência de limite pode ser aplicada ao texto da propriedade gerenciada ou a cadeias de caracteres individuais em uma propriedade gerenciada que contenha uma lista de valores de cadeia de caracteres; por exemplo, uma lista de nomes. Nesse caso, convém fazer a correspondência com o conteúdo exato de cada cadeia de caracteres e evitar a correspondência de consulta entre limites de cadeia de caracteres.
Para aplicar consultas de correspondência de limite, você deve configurar a propriedade gerenciada relevante no esquema de índice.
Habilitando o recurso de Correspondência de Limite para a propriedade gerenciada, você pode fazer o seguinte:
- Usar consultas de correspondência limite explícitas.
- Impedir a correspondência de frases entre os limites de cadeia de caracteres. Para propriedades gerenciadas que contêm várias cadeias de caracteres, esse recurso garante que uma cadeia de caracteres não corresponda a palavras antes ou depois de uma indicação de limite.
EQUALS
Especifica que uma palavra ou frase deve fornecer uma correspondência de token exata com a propriedade gerenciada.
Sintaxe
equals(<term or phrase>)
Parâmetros
Não aplicável.
Exemplos
O exemplo a seguir corresponderá a itens com os valores "Diogo Martins" na propriedade gerenciada "autor". Não fará a correspondência com itens com o valor "Diogo Martins sr" ou "Sr. Diogo Martins".
author:equals("adam jones")
Comentários
Confira também ENDS-WITH.
FILTER
Usado para consultar os metadados ou outros dados estruturados.
O uso do operador FILTER sugere automaticamente o seguinte para a consulta especificada:
A linguística será definida como linguistics="OFF".
A classificação será desabilitada.
Nenhum realce de consulta será usado no resumo realçado de ocorrências para a ocorrência de resultado da consulta.
Dica: se você usar o operador STRING em uma expressão FILTER, por padrão, a linguística será desabilitada. Você pode habilitar o processamento linguístico em cada expressão STRING dentro de FILTER usando o operando
linguistics="ON".
Sintaxe
filter(<any valid FQL operator expression>)
Parâmetros
Não aplicável.
Exemplos
A expressão a seguir corresponde a itens que têm uma propriedade gerenciada Title que contém "sonata" e uma propriedade gerenciada Doctype que contém apenas o "áudio" de token. Nenhuma correspondência linguística será executada em relação a "áudio". Como o token FILTER será usado para fazer a correspondência com "áudio", esse texto não será realçado no resumo realçado de ocorrências.
and(title:sonata, filter(doctype:equals("audio")))
Comentários
Se você deve restringir sua consulta para corresponder a menos um grande conjunto de valores inteiros em uma propriedade numérica, pode expressar isso de duas maneiras funcionalmente equivalentes:
and(string("hello world"), filter(property-spec:or(1, 20, 453, ... , 3473)))and(string("hello world"), filter(property-spec:int("1 20 453 ... 3473", mode="or")))
O segundo exemplo usa o operador INT usando uma cadeia de caracteres com o conjunto de valores numéricos entre aspas duplas. Isso oferece um desempenho de consulta significativamente melhor durante a filtragem com um grande conjunto de valores numéricos.
Se você deve filtrar um grande conjunto de valores, considere o uso de valores numéricos em vez de valores de cadeia de caracteres e expresse as consultas usando a sintaxe otimizada.
FLOAT
Fornece digitação explícita de valores numéricos de ponto flutuante. O operando é um valor de ponto flutuante de acordo com a sintaxe especificada em Expressões de token em FQL.
A conversão de tipo explícito é opcional e geralmente não é necessária. O tipo de termo de consulta é detectado de acordo com o tipo de propriedade gerenciada numérica de destino.
Sintaxe
float(<floating point value>)
Parâmetros
Não aplicável.
INT
Fornece digitação explícita de valores inteiros. O operando é um valor inteiro de acordo com a sintaxe especificada em Expressões de token em FQL.
A conversão de tipo explícito é opcional e geralmente não é necessária. O tipo de termo de consulta é detectado de acordo com o tipo de propriedade gerenciada numérica de destino.
O operador INT também pode ser usado para expressar um conjunto de valores de número inteiro como argumentos para os operadores FQL Boolianos. Isso oferece um método com desempenho eficiente para fornecer um conjunto de valores inteiros em uma consulta, pois os valores que são passados usando o operador INT não são analisados pelo analisador de consulta FQL, mas são passados diretamente para o componente correspondente da consulta.
Sintaxe
int(<integer value>)
int("value, value, ??? , value")
A primeira sintaxe especifica um único inteiro. A segunda sintaxe especifica uma lista de valores inteiros separados por vírgulas entre aspas duplas.
Parâmetros
Não aplicável.
Exemplos
Se você precisa restringir a consulta para corresponder pelo menos a um grande conjunto de valores inteiros em uma propriedade numérica, pode expressar isso usando o operador INT:
and(string("hello world"), filter(id:int("1 20 49 124 453 985 3473", mode="or")))
NEAR
Restringe o conjunto de resultados a itens que têm N termos a uma certa distância entre si.
A ordem dos termos de consulta não é importante para a correspondência, apenas a distância.
Qualquer número de termos pode ser combinado com os operadores NEAR.
Os operandos NEAR podem ser termos simples, frases ou expressões de operador Booliano OR ou ANY. Caracteres curinga são aceitos.
Se várias operandos do operador NEAR corresponderem ao mesmo token indexado, serão considerados próximos uns dos outros.
Sintaxe
near(arg, arg [, arg]* [, N=<numeric value>])
Parâmetros
| Parâmetro | Valor | Descrição |
|---|---|---|
| N | <valor_numérico> | Especifica o número máximo de palavras que pode ser exibidas entre os termos (proximidade explícita). Se NEAR incluir mais de dois operandos, o número máximo de palavras permitidas entre os termos (N) será contada na expressão inteira. Padrão: 4 |
Exemplos
Exemplo 1. A expressão a seguir corresponde a cadeias de caracteres que contêm "gato" e "cachorro" se não mais de quatro tokens indexados (padrão) os separam.
near(cat, dog)
Exemplo 2. A expressão a seguir corresponde a cadeias de caracteres que contêm "gato", "cachorro", "raposa" e "lobo" se não mais de quatro tokens indexados os separam.
near(cat, dog, fox, wolf)
A tabela a seguir contém exemplos de valores de cadeia de caracteres de propriedade gerenciada e informa se eles correspondem à expressão do Exemplo 2.
| Correspondeu? | Texto |
|---|---|
| Sim | A imagem mostra um gato, um cachorro, uma raposa e um lobo. |
| Sim (com lematização) | Cachorros, raposas e lobos são caninos, mas gatos são felinos. |
| Não | A imagem mostra um gato com um cachorro, uma raposa e um lobo. |
A expressão a seguir corresponde a todas as cadeias de caracteres da tabela anterior.
near(cat, dog, fox, wolf, N=5)
Comentários
Considerações sobre a distância entre termos de NEAR/ONEAR
N indica o número máximo de palavras que podem ser exibidas entre os termos de consulta no segmento correspondente do item. Se NEAR ou ONEAR inclui mais de dois operandos, o número máximo de palavras permitidas entre os termos de consulta (N) é contado no segmento do item correspondente a todos os termos NEAR ou ONEAR.
NEAR ou ONEAR funciona em texto indexado. Isto significa que carateres especiais, como vírgula (" , "), ponto (" . "), dois pontos (" : "), ou ponto e vírgula (" ; ") será tratado como espaço em branco. O termo "distância" se relaciona a tokens dentro do texto indexado.
Se você usar ONEAR ou NEAR com operandos iguais, o operador funcionará da seguinte maneira:
near(a, a, n=x)
Essa consulta sempre retornará true se pelo menos uma instância de "a" aparecer no contexto. Isso também significa que NEAR não pode ser usado como um operador COUNT. Para saber mais sobre como contar as ocorrências de termos, confira o operador COUNT.
NEAR aplicado a frases também corresponderá a frases sobrepostas no texto.
Se um token no segmento correspondente corresponder a mais de um operando para a expressão NEAR ou ONEAR, a consulta poderá corresponder mesmo se o número de tokens não correspondentes no segmento correspondente exceder o valor de 'N' na expressão de operador NEAR ou ONEAR. Por exemplo, uma sobreposição pode consistir em frases sobrepostas. Se o número de correspondências de sobreposição de token for 'O', a consulta corresponderá se não mais de 'N+O' tokens não correspondentes aparecerem no segmento correspondente do item.
NEAR ou ONEAR com NOT
O operador NOT não pode ser usado dentro do operador NEAR ou ONEAR. A seguir, um exemplo de sintaxe FQL incorreta:
near(audi,not(bmw),n=2)
NÃO
Retorna somente os itens que não correspondem ao operando. O operando pode ser qualquer expressão FQL válida.
Sintaxe
not(operand)
Parâmetros
Não aplicável.
ONEAR
A variante ordenada de NEAR e requer uma correspondência ordenada dos termos. O operador ONEAR pode ser usado para restringir o conjunto de resultados a itens que têm N a uma certa distância entre si.
Sintaxe
onear(arg, arg [, arg]* [, N=<numeric value>])
Parâmetros
| Parâmetro | Valor | Descrição |
|---|---|---|
| N | <valor_numérico> | Especifica o número máximo de palavras que podem ser exibidas entre os termos (proximidade explícita). Se ONEAR incluir mais de dois operandos, o número máximo de palavras permitidas entre os termos (N) será contada na expressão inteira. Padrão: 4 |
Exemplos
Exemplo 1. A expressão a seguir corresponde a todas as ocorrências das palavras "gato", "cachorro", "raposa" e "lobo" que aparecem em ordem, se não mais de quatro tokens indexados as separam.
onear(cat, dog, fox, wolf)
A tabela a seguir contém exemplos de valores de cadeia de caracteres de propriedade gerenciada e informa se eles correspondem à expressão anterior.
| Correspondeu? | Texto |
|---|---|
| Sim | A imagem mostra um gato, um cachorro, uma raposa e um lobo. |
| Não | Cachorros, raposas e lobos são caninos, mas gatos são felinos. |
| Não | A imagem mostra um gato com um cachorro, uma raposa e um lobo. |
Exemplo 2. A expressão a seguir corresponde (com lematização) ao texto na segunda linha da tabela anterior.
onear(dog, fox, wolf, cat, N=5)
Exemplo 3. A expressão a seguir corresponde ao texto na primeira e na terceira linha da tabela anterior.
onear(cat, dog, fox, wolf, N=5)
Comentários
Confira também NEAR.
OU
Retorna somente os itens que correspondem a pelo menos um dos operandos OR. Itens correspondentes terão uma classificação dinâmica maior (pontuação de relevância no conjunto de resultados) se mais operandos OR forem correspondentes. Os operandos podem ser um termo único ou qualquer subexpressão FQL válida.
Sintaxe
or(operand, operand [,operand]*)
Parâmetros
Não aplicável.
Exemplos
A expressão a seguir corresponde a todos os itens para os quais o índice de texto completo padrão contém "gato" ou "cachorro". Se um índice de texto completo padrão de um item contiver "gato" e "cachorro", ele será correspondente e terá uma classificação dinâmica mais alta do que teria se contivesse apenas um dos tokens.
or(cat, dog)
PHRASE
Pesquisa uma cadeia de tokens exata.
Os operandos PHRASE podem ser termos únicos. Caracteres curinga são aceitos.
Sintaxe
phrase(term [, term]*)
Parâmetros
Não aplicável.
Comentários
Confira também STRING.
RANGE
Use o operador RANGE para propriedades gerenciadas de data/hora e numéricas. O operador habilita expressões correspondentes a intervalos.
Sintaxe
range(start, stop [,from="GE"|"GT"] [,to="LE"|"LT"])
Parâmetros
| Parâmetro | Valor | Valor | Descrição |
|---|---|---|---|
| início | _<numeric_value>\ | <date/time_value>_ | Valor de início do intervalo. Para especificar que o intervalo não tem um limite inferior, use a palavra reservada min. |
| stop | _<numeric_value>\ | <date/time_value>_ | Valor final do intervalo. Para especificar que o intervalo não tem um limite superior, use a palavra reservada max. |
| from | **GE\ | GT** | Parâmetro opcional que indica o intervalo de início de abertura ou fechamento. Valores válidos:
|
| to | **LE\ | LT** | Parâmetro opcional que indica o intervalo de término de abertura ou fechamento. Valores válidos:
|
Exemplos
A expressão a seguir corresponde a uma propriedade description começando com a frase "grandes realizações" que aparece em itens com tamanho de pelo menos 10.000 bytes.
and(size:range(10000, max), description:starts-with("big accomplishments"))
STARTS-WITH
Especifica uma palavra ou frase que deve aparecer no início de uma propriedade gerenciada.
Sintaxe
starts-with(<term or phrase>)
Parâmetros
Não aplicável.
Exemplos
A expressão a seguir corresponde a itens com os valores "Diogo Martins sr" e "Diogo Martins" na propriedade gerenciada autor. Não fará a correspondência com itens com o valor "Sr Diogo Martins".
author:starts-with("adam jones")
Comentários
Para ver comentários adicionais sobre correspondência de limite, confira ENDS WITH.
STRING
Define uma condição de correspondência Booliana para uma cadeia de caracteres de texto.
O operando é uma cadeia de caracteres de texto (um ou mais termos) que devem ser correspondidos. A cadeia de caracteres é seguida de nenhum ou mais parâmetros.
O operador STRING também pode ser usado como uma conversão de tipo. A consulta string("24.5"), por exemplo, tratará o valor numérico "24,5" como uma cadeia de caracteres de texto.
Sintaxe
string("<text string>"
[, mode=<mode>]
[, n=<near>]
[, weight=<n>]
[, linguistics=<on|off>]
[, wildcard=<on|off>])
Parâmetros
| Parâmetro | Valor | Descrição | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| modo | <mode> | O parâmetro mode especifica como avaliar o valor <text string>. A lista a seguir mostra os valores válidos.
"PHRASE" - phrase(term [,term]*)
|
||||||||||||||
| n | <valor_numérico> | Este parâmetro indica a distância máxima do termo para modo= "NEAR" ou modo= "ONEAR". As seguintes expressões são equivalentes: string("hello world", mode="NEAR", n=5)near(hello, world, n=5) Predefinição: 4 |
||||||||||||||
| weight | <valor_numérico> | Esse parâmetro é um valor numérico positivo que indica o peso de termos para a classificação dinâmica. Um valor mais baixo indica que um termo deve contribuir menos para a classificação. Um valor maior indica que um termo deve contribuir mais para a classificação. Um valor zero para o parâmetro de peso especifica que um termo não deve afetar a classificação dinâmica. O parâmetro weight se aplica a todos os termos na expressão STRING. Dica: o parâmetro de peso afeta somente as consultas de índice de texto completo. Padrão: 100. | ||||||||||||||
| linguística | ativado|desativado | Desabilita/habilita todos os recursos linguísticos para a cadeia de caracteres (lematização, sinônimos, verificação ortográfica) se essas opções estão habilitadas para a consulta. Você poderá usar esse parâmetro para desativar o processamento linguístico de determinado termo ou cadeia de caracteres, enquanto ainda quiser que o termo ou a cadeia de caracteres contribua para a classificação. Padrão: "ON" | ||||||||||||||
| curinga | ativado|desativado | Esse parâmetro controla a expansão de curinga termos na <cadeia de caracteres de texto>. Essa configuração substitui as configurações de curinga em parâmetros de consulta e permite que caracteres curinga estendidos sejam habilitados ou desabilitados em partes específicas da consulta. A seguir, os valores válidos:
|
Observação
No Microsoft Office SharePoint Online, os parâmetros minexpansion, maxexpansion e annotation_class para o operador STRING são obsoletos.
Exemplos
Exemplo 1. Como o modo de cadeia de caracteres padrão é "PHRASE", cada uma das expressões a seguir retorna os mesmos resultados.
"what light through yonder window breaks"string("what light through yonder window breaks")string("what light through yonder window breaks", mode="phrase")phrase(what, light, through, yonder, window, breaks)
Exemplo 2. A expressão de token de cadeia de caracteres a seguir e a expressão de operador AND retornam os mesmos resultados.
string("cat dog fox", mode="and")and(cat, dog, fox)
Exemplo 3. A expressão de token de cadeia de caracteres a seguir e a expressão de operador OR retornam os mesmos resultados.
string("coyote saguaro", mode="or")or(coyote, saguaro)
Exemplo 4. A expressão de token de cadeia de caracteres a seguir e a expressão de operador ANY retornam os mesmos resultados.
string("coyote saguaro", mode="any")any(coyote, saguaro)
Exemplo 5. A expressão de token de cadeia de caracteres e a expressão de operador NEAR a seguir retornam os mesmos resultados.
string("coyote saguaro", mode="near")near(coyote, saguaro)
Exemplo 6. A expressão de token de cadeia de caracteres e a expressão de operador NEAR a seguir retornam os mesmos resultados.
string("cat dog fox wolf", mode="near", N=4)near(cat, dog, fox, wolf, N=4)
Exemplo 7. A expressão de token de cadeia de caracteres a seguir e a expressão de operador ONEAR retornam os mesmos resultados.
string("cat dog fox wolf", mode="onear")onear(cat, dog, fox, wolf)
Exemplo 8. A expressão de token de cadeia de caracteres a seguir corresponde à palavra "nobre" com os recursos linguísticos desabilitados, para que outras formas da palavra (como "enobrecedor") não sejam correspondentes usando a lematização.
string("nobler", linguistics="off")
Exemplo 9. A expressão a seguir corresponde a itens que contêm "gato" ou "cachorro", mas a expressão aumenta a ordem dos itens que contêm "cachorrinho" mais de itens que contêm "gato" dinâmica.
or(string("cat", weight="200"), string("dog", weight="500"))
Comentários
Peso de relevância para classificação dinâmica
O efeito principal do parâmetro weight é para consultas OR. Também pode ter alguns efeito sobre consultas AND. O algoritmo de classificação dinâmica pode sugerir que termos diferentes dão uma contribuição de classificação diferente, dependendo de onde no item o termo correspondente ocorre.
A diferença na contribuição de classificação também pode ser baseada na frequência do termo e na frequência inversa do item. Este é um exemplo:
- Consulta:
and(string("a"), string("b", weight=200)) - Esquema de índice: a propriedade gerenciada title tem mais peso do que a propriedade gerenciada body.
- O item de índice 1 inclui o termo 'a' no título e o termo 'b' no corpo.
- O item de índice 2 inclui o termo 'a' no corpo e o termo 'b' no título.
Nesse exemplo, o item 2 obterá a maior classificação total, pois os itens com contribuição de classificação dinâmica mais elevada receberão um aumento ainda mais.
Dica: o aumento de termo relativo (positivo ou negativo) é aplicado ao componente de classificação dinâmica da classificação total. No entanto, os cálculos de classificação de aumento de proximidade (a distância entre as palavras) não serão afetados pelo peso do termo. O peso relativo nem sempre implica que a classificação total para o item é modificada acordo com a porcentagem fornecida. > A consulta seguinte irá procurar os termos "pedro", "paulo" ou "maria", em que "pedro" terá o dobro da contribuição de classificação que os outros dois termos. >
or(peter, string("paul mary", mode="OR", weight=50))
Lidar com cadeias de caracteres especiais
Os caracteres especiais, como vírgulas (","), ponto e vírgula (";"), dois-pontos (":"), ponto ("."), sinal de subtração ("-"), sublinhado ("_") ou barra ("/"), são tratados como espaços em branco dentro de uma expressão de cadeia de caracteres entre aspas duplas. Isso está relacionado ao processo de geração de tokens. Esses caracteres também sugerem uma frase implícita dos tokens separados por esses caracteres.
As expressões de consulta a seguir são equivalentes.
title:string("animals birds", mode="phrase")title:"animals/birds"title:string("animals/birds", mode="and")title:string("animals/birds", mode="or")
As expressões de consulta a seguir são equivalentes.
title:or(string("animals birds", mode="phrase"), string("animals insects", mode="phrase"))title:string("animals/birds animals/insects", mode="or")
As expressões de consulta a seguir são equivalentes.
body:string("help contoso com", mode="phrase")body:string("help@contoso.com")
Correspondência de frase indexada
Você pode pesquisar uma cadeia de caracteres exata de tokens usando o operador STRING com mode="phrase" ou o operador PHRASE.
Todas as operações com frase sugerem uma correspondência de frase com token. Isto significa que carateres especiais, como vírgula (" , "), ponto e vírgula (" ; "), dois pontos (" : "), caráter de sublinhado (" _ "), menos (" - "), ou barra (" / ") são tratados como espaço em branco. Isso está relacionado ao processo de geração de tokens.
XRANK
Aumenta a classificação dinâmica de itens com base em certas ocorrências de termo na expressão de correspondência, sem alterar quais itens correspondem à consulta. Uma expressão XRANK consiste em um componente que deve ser correspondido, a expressão de correspondência, e um ou mais componentes que contribuem apenas para a classificação dinâmica, a expressão de classificação. Pelo menos um dos parâmetros, excluindo n, deve ser especificado para que uma expressão XRANK seja válida.
Expressões de correspondência podem ser qualquer expressão FQL válida, incluindo expressões aninhadas XRANK. Expressões de classificação podem ser qualquer expressão FQL válida sem expressões XRANK. Se as consultas FQL têm vários operadores XRANK, o valor de classificação dinâmico final é calculado como uma soma de aumentos em todos os operadores XRANK.
Observação
No Microsoft Office SharePoint Online Server 2010, o operador XRANK tinha dois parâmetros: boost e boostall, bem como a seguinte sintaxe: xrank(operand, rank-operand [, rank-operand]* [,boost=n] [,boostall=yes]). Essa seguinte sintaxe, juntamente com seus parâmetros, foi preterida no SharePoint. Recomendamos o uso da nova sintaxe e dos novos parâmetros em vez disso.
Sintaxe
xrank(<match expression> [, <rank-expression>]*, rank-parameter[, rank-parameter]*)
Fórmula
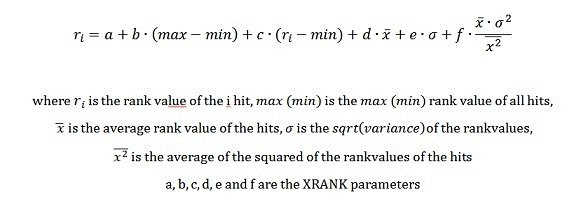
Parâmetros
| Parâmetro | Valor | Descrição |
|---|---|---|
| N | <valor_inteiro> | Especifica o número de resultados para calcular as estatísticas. Este parâmetro não afeta o número de resultados para os que a classificação dinâmica contribui; é apenas um meio para excluir os itens sem importância dos cálculos das estatísticas. Padrão: 0. Um valor zero carrega a semântica de todos os documentos. |
| Nb | <valor_float> | O parâmetro nb refere-se ao aumento normalizado. Este parâmetro especifica o fator que será multiplicado com o produto de pontuação média e de variação dos valores de classificação do conjunto de resultados. f na fórmula XRANK. |
O aumento tipicamente normalizado, nb, é o único parâmetro que é modificado. Esse parâmetro fornece o controle necessário para promover ou rebaixar um item específico, sem levar em consideração o desvio padrão.
Parâmetros avançados
Os parâmetros avançados a seguir também estão disponíveis. No entanto, geralmente não são usados.
| Parâmetro | Valor | Descrição |
|---|---|---|
| cb | <valor_float> | O parâmetro cb se refere ao aumento constante. Padrão: 0. a na fórmula XRANK. |
| stdb | <valor_float> | O parâmetro stdb se refere ao aumento do desvio padrão. Padrão: 0. e na fórmula XRANK. |
| avgb | <valor_float> | O parâmetro avgb se refere ao aumento médio. Esse fator é multiplicado com o valor médio de classificação do conjunto de resultados. Padrão: 0. d na fórmula XRANK. |
| rb | <valor_float> | O rb parâmetro se refere ao aumento do intervalo. Este fator é multiplicado com o intervalo de valores de classificação no conjunto de resultados. Padrão: 0. b na fórmula XRANK. |
| pb | <valor_float> | O parâmetro pb se refere a porcentagem de aumento. Esse fator é multiplicado com a classificação do item comparado com o valor mínimo no corpo. Padrão: 0. c na fórmula XRANK. |
Exemplos
Exemplo 1. A expressão a seguir corresponde a itens para os quais o índice de texto completo padrão contém "gato" ou "cachorro". A expressão aumenta a ordem dinâmica desses itens com um aumento constante de 100 para itens que também contêm "de raça".
xrank(or(cat, dog), thoroughbred, cb=100)
Exemplo 2. A expressão a seguir corresponde a itens para os quais o índice de texto completo padrão contém "gato" ou "cachorro". A expressão aumenta a ordem dinâmica desses itens com um aumento normalizado de 1,5 para itens que também contêm "de raça".
xrank(or(cat, dog), thoroughbred, nb=1.5)
Exemplo 3. A expressão a seguir corresponde a itens para os quais o índice de texto completo padrão contém "gato" ou "cachorro". A expressão aumenta a ordem dinâmica desses itens com um aumento constante de 100 e com um aumento normalizado de ,1,5, para itens que também contêm "de raça".
xrank(or(cat, dog), thoroughbred, cb=100, nb=1.5)
Exemplo 4. A expressão a seguir corresponde a todos os itens que contêm o termo "animais" e aumenta a ordem dinâmica da seguinte maneira:
A classificação dinâmica de itens que contêm o termo "cachorros" é aumentada em 100 pontos.
A classificação dinâmica de itens que contêm o termo "gatos" é aumentada em 200 pontos.
A classificação dinâmica de itens que contenham os termos "cachorros" e "gatos" é aumentada em 300 pontos.
xrank(xrank(animals, dogs, cb=100), cats, cb=200)