Introdução ao pool de dados no Clusters de Big Data do SQL Server
Aplica-se a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Este artigo descreve a função dos pools de dados do SQL Server em um cluster de Big Data do SQL Server. As seções a seguir descrevem a arquitetura, a funcionalidade e os cenários de uso de um pool de dados.
Este vídeo de 5 minutos apresenta pools de dados e mostra como consultar dados de pools de dados:
Arquitetura do pool de dados
Um pool de dados consiste em uma ou mais instâncias do pool de dados do SQL Server que fornecem armazenamento do SQL Server persistente para o cluster. Ele permite a consulta de desempenho de dados armazenados em cache em fontes de dados externas e o descarregamento de trabalho. Os dados são incluídos no pool de dados usando consultas T-SQL ou de trabalhos do Spark. Para aprimorar o desempenho em grandes conjuntos de dados, os dados ingeridos são distribuídos em fragmentos e armazenados em todas as instâncias do SQL Server no pool. Os métodos de distribuições com suporte são round robin e replicados. Para a otimização de acesso de leitura, um índice columnstore clusterizado é criado em cada tabela em cada instância do pool de dados. Um pool de dados funciona como o data mart de expansão para Clusters de Big Data do SQL Server.
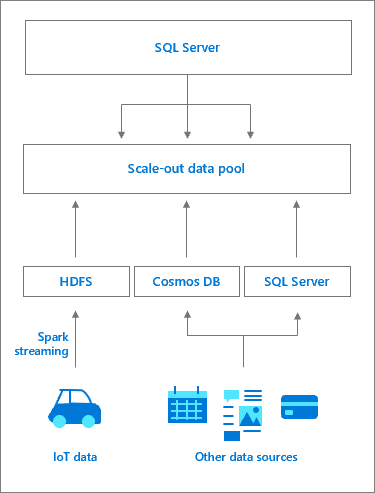
O acesso às instâncias do SQL Server no pool de dados é gerenciado por meio da instância mestra do SQL Server. Uma fonte de dados externa ao pool de dados é criada, juntamente com as tabelas externas do PolyBase para armazenar o cache de dados. Em segundo plano, o controlador cria um banco de dados no pool de data com tabelas que correspondem às tabelas externas. Na instância mestra do SQL Server, o fluxo de trabalho é transparente; o controlador redireciona as solicitações de tabela externa específicas às instâncias do SQL Server no pool de dados, o que pode ocorrer por meio do pool de computação, executa consultas e retorna o conjunto de resultados. Os dados no pool de dados só podem ser ingeridos ou consultados e não podem ser modificados. Portanto, qualquer atualização de dados exigiria uma remoção da tabela, seguida da recriação dela e de um novo preenchimento de dados subsequente.
Cenários de pool de dados
A finalidade dos relatórios é um cenário de pool de dados comum. Por exemplo, uma consulta complexa que une várias fontes de dados do PolyBase, usada para um relatório semanal, pode ser descarregada para o pool de dados. Os dados armazenados em cache fornecem uma computação rápida local e eliminam a necessidade de voltar para os conjuntos de dados originais. Da mesma forma, os dados do painel que exigem atualização periódica podem ser armazenados em cache no pool de dados para relatórios otimizados. A exploração de repetição do Machine Learning também poderia se beneficiar do armazenamento em cache de conjuntos de dados no pool de dados.
Próximas etapas
Para saber mais sobre o Clusters de Big Data do SQL Server, confira os seguintes recursos: