Enviar trabalhos do Spark em clusters de Big Data do SQL Server no Visual Studio Code
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Saiba como usar as Ferramentas do Spark & Hive para Visual Studio Code para criar e enviar scripts de PySpark para o Apache Spark. Primeiro, descreveremos como instalar as ferramentas do Spark & Hive no Visual Studio Code e, em seguida, veremos como enviar trabalhos para o Spark.
As Ferramentas do Spark & Hive podem ser instaladas em plataformas com suporte do Visual Studio Code, que incluem Windows, Linux e macOS. A seguir, você verá os pré-requisitos das diferentes plataformas.
Pré-requisitos
Os itens a seguir são necessários para concluir as etapas neste artigo:
- Um cluster de Big Data do SQL Server. Confira Clusters de Big Data do SQL Server.
- Visual Studio Code.
- Python e a extensão Python no Visual Studio Code.
- Mono. O Mono é necessário apenas para Linux e macOS.
- Configurar o ambiente interativo do PySpark para Visual Studio Code.
- Um diretório local chamado SQLBDCexample. Este artigo usa C:\SQLBDC\SQLBDCexample.
Instalar Ferramentas do Spark & Hive
Após concluir os pré-requisitos, você poderá instalar as Ferramentas do Spark & Hive para Visual Studio Code. Conclua as etapas a seguir para instalar as Ferramentas do Spark & Hive:
Abra o Visual Studio Code.
Na barra de menus, navegue até Exibir>Extensões.
Na caixa de pesquisa, insira Spark & Hive.
Selecione Ferramentas Spark e Hive, publicadas pela Microsoft, nos resultados da pesquisa, e escolha Instalar.
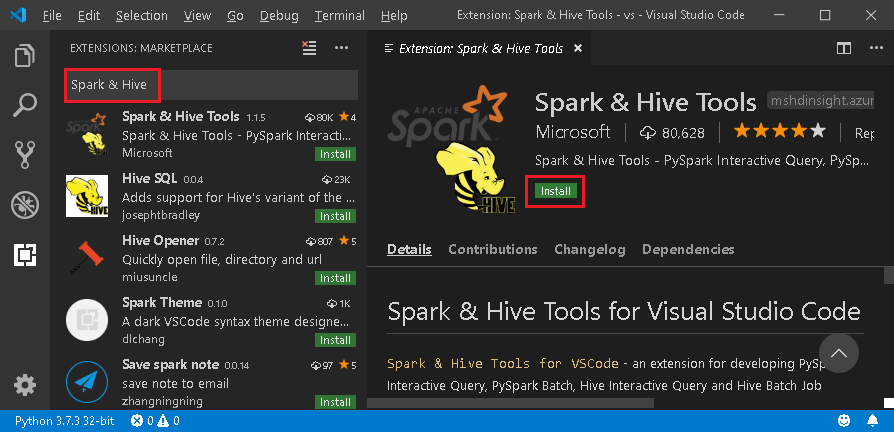
Recarregue quando necessário.
Abrir a pasta de trabalho
Conclua as etapas a seguir para abrir uma pasta de trabalho e criar um arquivo no Visual Studio Code:
Na barra de menus, navegue até Arquivo>Abrir Pasta...>C:\SQLBDC\SQLBDCexamplee, em seguida, selecione o botão Selecionar Pasta. A pasta aparece no modo de exibição do Explorer à esquerda.
No modo de exibição do Explorer, selecione a pasta SQLBDCexample e, em seguida, o ícone Novo Arquivo ao lado da pasta de trabalho.
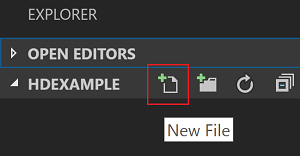
Nomeie o novo arquivo com a extensão de arquivo
.py(script de Spark). Este exemplo usa HelloWorld.py.Copie e cole o seguinte código no arquivo de script:
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
Vincular um cluster de Big Data do SQL Server
Antes de enviar scripts para a seus clusters do Visual Studio Code, você precisa vincular um cluster de Big Data do SQL Server.
Na barra de menus, navegue até Exibir>Paleta de Comandos... e insira Spark / Hive: Vincular um Cluster.

Selecione o tipo de cluster vinculado Big Data do SQL Server.
Insira o ponto de extremidade de Big Data do SQL Server.
Insira o nome de usuário do cluster de big data do SQL Server.
Insira a senha do administrador do usuário.
Defina o nome para exibição do cluster de big data (opcional).
Liste os clusters e examine a exibição SAÍDA para verificação.
Listar clusters
Na barra de menus, navegue até Exibir>Paleta de Comandos... e insira Spark / Hive: Vincular um Cluster.
Examine a exibição SAÍDA. A exibição mostrará seus clusters vinculados.

Definir cluster padrão
Abra novamente a pasta SQLBDCexample criada anteriormente se estiver fechada.
Selecione o arquivo HelloWorld.py criado anteriormente e ele será aberto no editor de scripts.
Vincule um cluster se ainda não tiver feito isso.
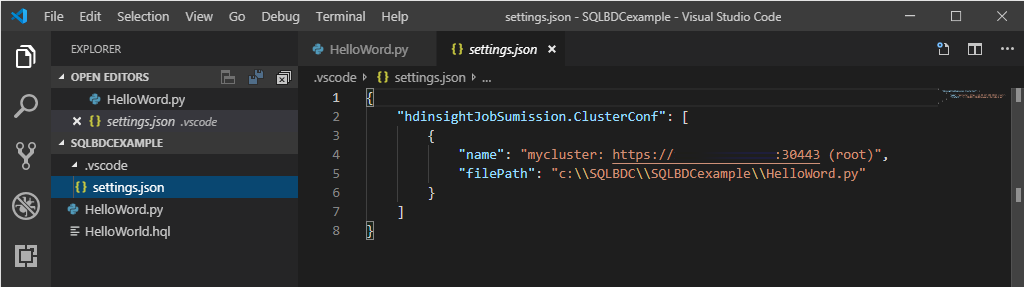
Clique com o botão direito do mouse no editor de scripts e selecione Spark / Hive: Definir Cluster Padrão.
Selecione um cluster como o cluster padrão para o arquivo de script atual. As ferramentas atualizam automaticamente o arquivo de configuração .VSCode\settings.json.
Enviar consultas interativas de PySpark
Você pode enviar consultas de PySpark interativas seguindo as etapas abaixo:
Abra novamente a pasta SQLBDCexample criada anteriormente se estiver fechada.
Selecione o arquivo HelloWorld.py criado anteriormente e ele será aberto no editor de scripts.
Vincule um cluster se ainda não tiver feito isso.
Escolha todo o código e clique com o botão direito do mouse no editor de scripts, selecione Spark: PySpark Interativo para enviar a consulta ou use o atalho Ctrl+Alt+I.
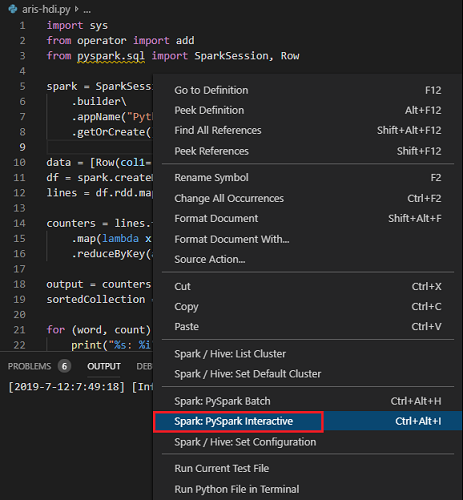
Selecione o cluster se não tiver especificado um cluster padrão. Após alguns instantes, os resultados do Python Interativo aparecem em uma nova guia. As ferramentas também permitem que você envie um bloco de código em vez de todo o arquivo de script usando o menu de contexto.
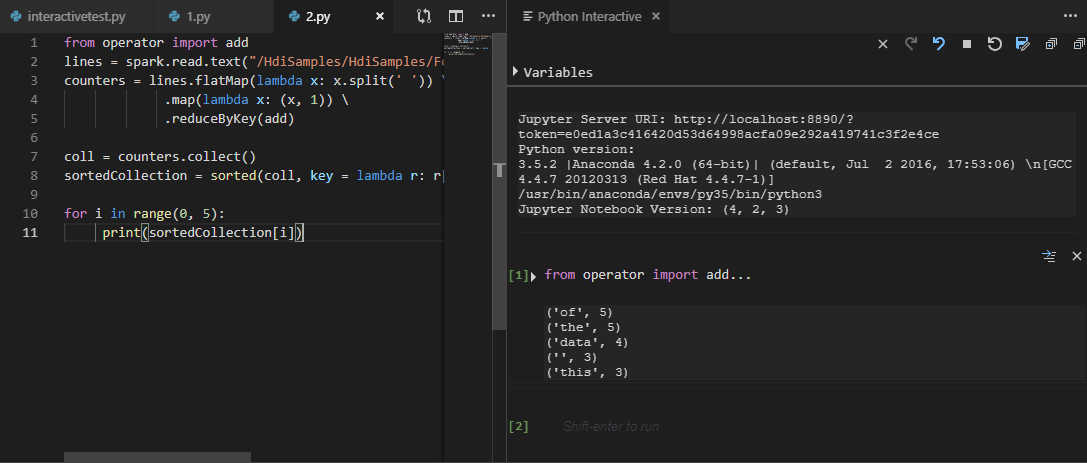
Insira "%%info" e, em seguida, pressione Shift + Enter para exibir informações do trabalho. (Opcional)
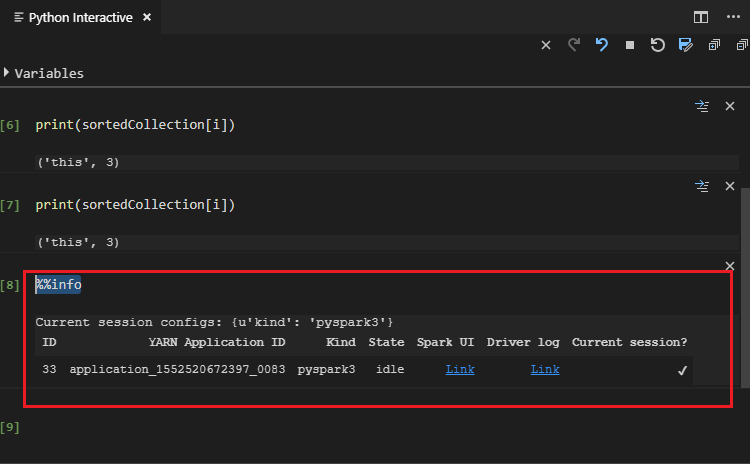
Observação
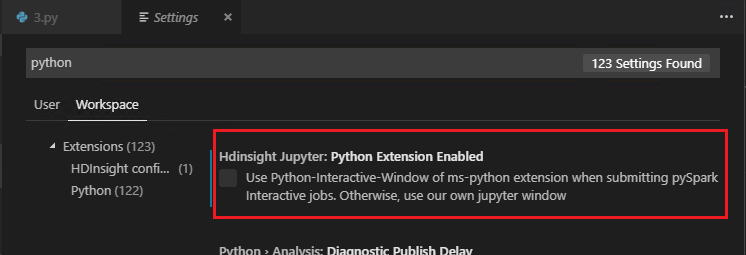
Quando Extensão do Python Habilitada é desmarcado nas configurações (a configuração padrão é estar marcado), os resultados da interação de pyspark enviados usarão a janela antiga.
Enviar trabalho em lotes PySpark
Abra novamente a pasta SQLBDCexample criada anteriormente se estiver fechada.
Selecione o arquivo HelloWorld.py criado anteriormente e ele será aberto no editor de scripts.
Vincule um cluster se ainda não tiver feito isso.
Clique com o botão direito do mouse no editor de scripts e selecione Spark: Lote do PySpark ou use o atalho Ctrl+Alt+H.
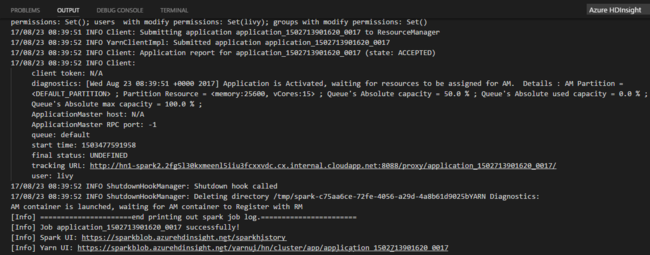
Selecione o cluster se não tiver especificado um cluster padrão. Após você enviar um trabalho do Python, os logs de envio aparecem na janela de SAÍDA no Visual Studio Code. A URL da interface do usuário do Spark e a URL da interface do usuário do YARN também são mostradas. Você pode abrir a URL em um navegador da Web para acompanhar o status do trabalho.
Configuração do Apache Livy
A configuração do Apache Livy tem suporte, ela pode ser definida no .VSCode\settings.json na pasta de espaço de trabalho. Atualmente, a configuração do Livy dá suporte apenas ao script de Python. Para obter mais detalhes, confira o LEIAME do Livy.
Como disparar a configuração do Livy
Método 1
- Na barra de menus, navegue até Arquivo>Preferências>Configurações.
- Na caixa de texto Configurações de pesquisa, insira Envio de Trabalho do HDInsight: Livy Conf.
- Selecione Editar em settings.json para o resultado da pesquisa relevante.
Método 2
Envie um arquivo, observe que a pasta .vscode é adicionada automaticamente à pasta de trabalho. Você pode encontrar a configuração do Livy selecionando settings.json em .vscode.
As configurações do projeto:
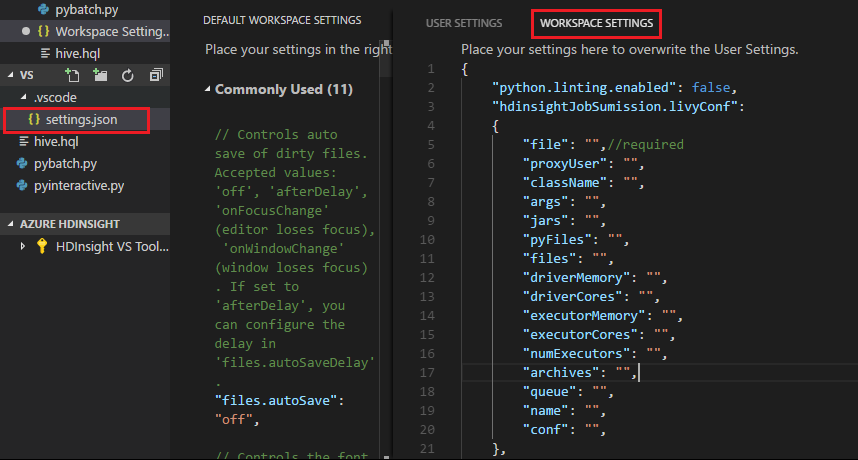
Observação
Para as configurações driverMemory e executorMemory, defina o valor com a unidade, por exemplo, 1 GB ou 1024 MB.
Configurações do Livy com suporte
POST /lotes
Corpo da solicitação
| name | descrição | type |
|---|---|---|
| file | Arquivo que contém o aplicativo a ser executado | caminho (obrigatório) |
| proxyUser | Usuário a representar ao executar o trabalho | string |
| className | Classe principal de Java/Spark do aplicativo | string |
| args | Argumentos de linha de comando para o aplicativo | lista de cadeias de caracteres |
| jars | jars a serem usados nesta sessão | Lista de cadeias de caracteres |
| pyFiles | Arquivos Python a serem usados nesta sessão | Lista de cadeias de caracteres |
| files | arquivos a serem usados nesta sessão | Lista de cadeias de caracteres |
| driverMemory | Quantidade de memória a ser usada para o processo do driver | string |
| driverCores | Número de núcleos a serem usados para o processo do driver | INT |
| executorMemory | Quantidade de memória a ser usada pelo processo de executor | string |
| executorCores | Número de núcleos a serem usados para cada executor | INT |
| numExecutors | Número de executores a serem iniciados para esta sessão | INT |
| archives | Arquivos a serem usados nesta sessão | Lista de cadeias de caracteres |
| fila | O nome da fila YARN para a qual foi enviado | string |
| name | O nome desta sessão | string |
| conf | Propriedades de configuração do Spark | Mapa de chave = valor |
| :- | :- | :- |
Corpo da resposta
O objeto de lote criado.
| name | descrição | type |
|---|---|---|
| id | A ID da sessão | INT |
| appId | A ID do aplicativo desta sessão | String |
| appInfo | As informações detalhadas do aplicativo | Mapa de chave = valor |
| log | As linhas de log | lista de cadeias de caracteres |
| state | O estado do lote | string |
| :- | :- | :- |
Observação
A configuração do Livy atribuída será exibida no painel de saída quando o script for enviado.
Recursos adicionais
O Spark & Hive para Visual Studio Code tem suporte para os seguintes recursos:
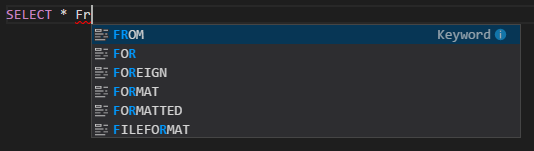
Preenchimento automático do IntelliSense. Aparecerão sugestões de palavras-chave, métodos, variáveis e muito mais. Ícones diferentes representam tipos diferentes de objetos.
Marcador de erro do IntelliSense. O serviço de linguagem sublinha os erros de edição para o script do Hive.
Destaques da sintaxe. O serviço de linguagem usa cores diferentes para distinguir variáveis, palavras-chave, tipo de dados, funções, entre outros.
Desvincular cluster
Na barra de menus, navegue até Exibir>Paleta de Comandos... e insira Spark / Hive: Desvincular um Cluster.
Selecione o cluster a ser desvinculado.
Examine a exibição SAÍDA para verificação.
Próximas etapas
Para obter mais informações sobre os clusters de Big Data do SQL Server e os cenários relacionados, confira Clusters de Big Data do SQL Server.