Solucionar problemas do notebook pyspark
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Este artigo demonstra como solucionar problemas de um notebook pyspark com falha.
Arquitetura de um trabalho do PySpark no Azure Data Studio
O Azure Data Studio se comunica com o ponto de extremidade do livy em Clusters de Big Data do SQL Server.
O ponto de extremidade do livy emite comandos spark-submit no Cluster de Big Data. Cada comando spark-submit tem um parâmetro que especifica o YARN como o Gerenciador de Recursos de Cluster.
Para solucionar problemas de sua sessão do PySpark de maneira eficiente, você coletará e examinará os logs em cada camada: Livy, YARN e Spark.
Essas etapas de solução de problemas exigem que você tenha:
- o CLI de Dados do Azure (
azdata) instalado e configurado corretamente para seu cluster. - Familiaridade com a execução de comandos do Linux e algumas habilidades de solução de problemas de log.
Etapas para solucionar problemas
Examine as mensagens de pilha e de erro no
pyspark.Obtenha a ID do aplicativo da primeira célula no notebook. Use essa ID de aplicativo para investigar os logs do
livy, YARN e Spark.SparkContextusa essa ID de aplicativo do YARN.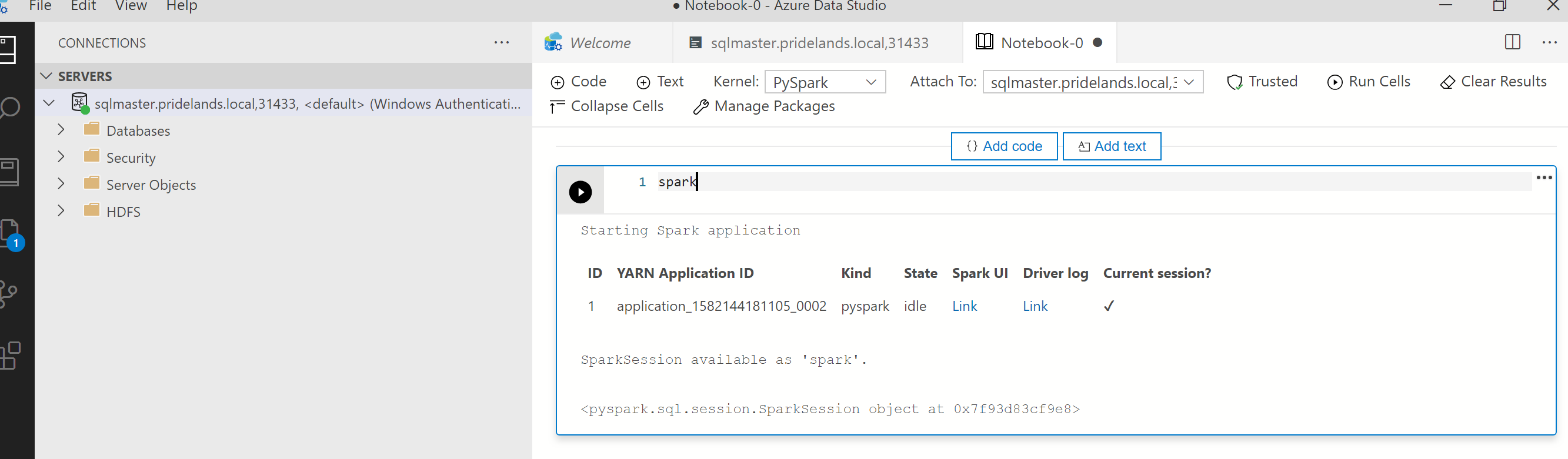
Obtenha os logs.
Use
azdata bdc debug copy-logspara investigarO exemplo a seguir conecta um ponto de extremidade de cluster de Big Data para copiar os logs. Atualize os valores a seguir no exemplo antes de executar.
-
<ip_address>: ponto de extremidade do cluster de Big Data -
<username>: o nome de usuário do cluster de Big Data -
<namespace>: o namespace do Kubernetes para o cluster -
<folder_to_copy_logs>: o caminho da pasta local para o qual você deseja copiar seus logs
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>Saída de exemplo
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.-
Examine os logs do Livy. Os logs do Livy estão em
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\log.- Procure a ID de aplicativo do YARN na primeira célula do notebook pyspark.
- Pesquise o status
ERR.
Exemplo de log do Livy que tem um estado
YARN ACCEPTED. O Livy enviou o aplicativo do YARN.HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>Examinar a interface do usuário do YARN
Obtenha a URL do ponto de extremidade do YARN no painel de gerenciamento do cluster de Big Data do Azure Data Studio ou execute
azdata bdc endpoint list –o table.Por exemplo:
azdata bdc endpoint list -o tableRetornos
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy httpsVerifique a ID do aplicativo e o application_master individual e os logs de contêiner.
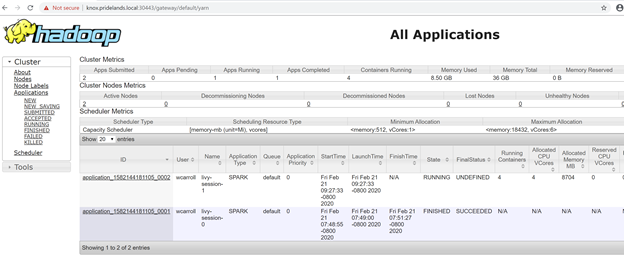
Examine os logs do aplicativo do YARN.
Obtenha o log do aplicativo para o aplicativo. Use
kubectlpara se conectar ao podsparkhead-0, por exemplo:kubectl exec -it sparkhead-0 -- /bin/bashEm seguida, execute este comando dentro desse shell usando o
application_idcorreto:yarn logs -applicationId application_<application_id>Procure erros ou pilhas.
Um exemplo de erro de permissão em relação ao HDFS. Na pilha de Java, procure o
Caused by:YYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-xExamine a interface do usuário do Spark.
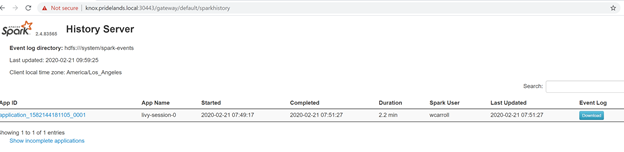
Faça drill down das tarefas de estágios em busca de erros.
Próximas etapas
Solucionar problemas de integração do Active Directory e Clusters de Big Data do SQL Server