Continuidade dos negócios e recuperação do banco de dados – SQL Server em Linux
Aplica-se: ![]() SQL Server
SQL Server
Este artigo fornece uma visão geral das soluções de continuidade dos negócios para alta disponibilidade e recuperação de desastre do SQL Server, no Windows e no Linux.
Todos que implantam o SQL Server têm uma tarefa comum para levar em consideração, que é certificar-se de que todas as instâncias do SQL Server de missão crítica e os bancos de dados dentro delas estarão disponíveis quando os usuários finais e de negócios precisarem delas, independentemente de ser em horário comercial ou o tempo todo. A meta é manter os negócios em funcionamento com o mínimo ou sem qualquer interrupção. Esse conceito também é conhecido como continuidade dos negócios.
O SQL Server 2017 (14.x) introduziu muitos novos recursos ou aprimoramentos aos existentes, alguns dos quais são de disponibilidade. A maior adição ao SQL Server 2017 (14.x) foi o suporte para as distribuições do SQL Server em Linux. Para ver a lista completa dos novos recursos do SQL Server, confira os seguintes artigos:
- Novidades no SQL Server 2017
- Novidades do SQL Server 2017 em Linux
- Novidades do SQL Server 2019
- Novidades do SQL Server 2019 em Linux
- Novidades do SQL Server 2022
O foco deste artigo é apresentar cenários de disponibilidade do SQL Server 2017 (14.x) e versões posteriores, bem como os novos e aprimorados recursos de disponibilidade. Os cenários incluem os híbridos que poderão estender as implantações do SQL Server no Windows Server e no Linux, bem como aquelas que podem aumentar o número de cópias de leitura de um banco de dados.
Embora este artigo não aborde as opções de disponibilidade externas ao SQL Server, como aquelas fornecidas pela virtualização, tudo discutido aqui se aplica às instalações do SQL Server em uma máquina virtual convidada, seja na nuvem pública ou hospedada em um servidor do hipervisor local.
Cenários do SQL Server com recursos de disponibilidade
Os grupos de disponibilidade Always On, as instâncias de cluster de failover Always On e o envio de logs podem ser usados de várias maneiras e não necessariamente apenas para fins de disponibilidade. Os recursos de disponibilidade podem ser usados de quatro maneiras principais:
- Alta disponibilidade
- Recuperação de desastre
- Migrações e atualizações
- Expandindo cópias legíveis de um ou mais bancos de dados
As próximas seções abordarão os recursos relevantes que podem ser usados nesse cenário específico. O único recurso não abordado é a replicação do SQL Server. Embora não seja indicada de modo oficial como um recurso de disponibilidade no grupo do Always On, a Replicação do SQL Server geralmente é usada para tornar os dados redundantes em determinados cenários. A replicação de mesclagem não é compatível com o SQL Server em Linux. Para obter mais informações, confira a Replicação do SQL Server em Linux.
Importante
Os recursos de disponibilidade do SQL Server não substituem a necessidade de ter uma estratégia de backup e restauração bem testada e robusta, o bloco de construção mais fundamental de qualquer solução de disponibilidade.
Alta disponibilidade
É importante garantir que o banco de dados ou as instâncias do SQL Server estejam disponíveis caso ocorra um problema local em um data center ou em uma região individual da nuvem. Esta seção abordará como os recursos de disponibilidade do SQL Server podem ajudar nessa tarefa. Todos os recursos descritos estão disponíveis no Windows Server e no Linux.
Grupos de disponibilidade
Introduzidos no SQL Server 2012 (11.x), os AGs (grupos de disponibilidade) fornecem proteção de nível de banco de dados enviando cada transação de um banco de dados para outra instância, ou réplica, que contém uma cópia do banco de dados em um estado especial. Um AG pode ser implantado nas edições Standard ou Enterprise. As instâncias que participam de um AG podem ser autônomas ou FCIs (instâncias de cluster de failover, descritas na próxima seção). Como as transações são enviadas para uma réplica conforme elas acontecem, os AGs são recomendados quando há requisitos de objetivos de tempo de recuperação e de ponto de recuperação mais baixos. A movimentação de dados entre as réplicas pode ser síncrona ou assíncrona, com a edição Enterprise, permitindo que até três réplicas (incluindo a primária) sejam síncronas. Um AG tem uma cópia de leitura/gravação completa do banco de dados na réplica primária, enquanto as réplicas secundárias não podem receber transações diretamente dos usuários finais nem de aplicativos.
Observação
Always On é um termo coletivo para os recursos de disponibilidade do SQL Server e abrange AGs e FCIs. Always On não é o nome do recurso do AG.
Antes do SQL Server 2022 (16.x), os AGs apenas forneciam proteção de nível do banco de dados e não de nível da instância. Qualquer item não capturado no log de transações nem configurado no banco de dados precisará ser sincronizado manualmente em cada réplica secundária. Alguns exemplos de objetos que devem ser sincronizados manualmente são logons no nível de instância, servidores vinculados e trabalhos do SQL Server Agent.
A partir do SQL Server 2022 (16.x), você pode gerenciar objetos de metadados, incluindo usuários, logons, permissões e trabalhos do SQL Server Agent no nível do AG, além do nível da instância. Para obter mais informações, confira Grupos de disponibilidade independentes.
Um AG também tem outro componente chamado ouvinte, que permite que aplicativos e usuários finais se conectem sem a necessidade de saber qual instância do SQL Server está hospedando a réplica primária. Cada AG deve ter um ouvinte próprio. Enquanto as implementações do ouvinte são um pouco diferentes no Windows Server em comparação com o Linux, a funcionalidade que ele fornece e como ela é usada é a mesma. O diagrama abaixo mostra um AG baseado no Windows Server que usa um WSFC (Cluster de Failover do Windows Server). Um cluster subjacente na camada do sistema operacional é necessário para disponibilidade se estiver no Linux ou no Windows Server. O exemplo mostra uma configuração simples com dois servidores ou nós, com um WSFC como o cluster subjacente.

As edições Standard e Enterprise têm valores máximos diferentes para as réplicas. Um AG na edição Standard, conhecido como um grupo de disponibilidade básico, dá suporte a duas réplicas (uma primária e outra secundária) com apenas um banco de dados individual no AG. A edição Enterprise permite que vários bancos de dados sejam configurados em um só AG e pode ter até nove réplicas no total (uma primária e oito secundárias). A Enterprise Edition também fornece outros benefícios opcionais, como réplicas secundárias legíveis, a capacidade de fazer backups de uma réplica secundária e muito mais.
Observação
O espelhamento de banco de dados, que foi preterido no SQL Server 2012 (11.x), não está disponível na versão Linux do SQL Server nem será adicionado. Os clientes que ainda usam o espelhamento de banco de dados devem planejar a migração para os AGs, que é a substituição do espelhamento de banco de dados.
Quando se trata de disponibilidade, os AGs podem fornecer um failover automático ou manual. O failover automático poderá ocorrer se a movimentação de dados síncronos for configurada e o banco de dados na réplica primária e secundária estiverem em um estado sincronizado. Desde que o ouvinte seja usado e o aplicativo use uma versão posterior do .NET Framework (3.5 com uma atualização ou 4.0 e superior), o failover deverá ser tratado com pouco ou nenhum impacto para os usuários finais se um ouvinte for utilizado. O failover para tornar a nova réplica primária uma réplica secundária pode ser configurado para ser automático ou manual e geralmente é medido em segundos.
A lista abaixo destaca algumas diferenças dos AGs no Windows Server e no Linux:
- Devido às diferenças na maneira que o cluster subjacente funciona no Linux e no Windows Server, todos os failovers (manuais ou automáticos) dos AGs são feitos por meio do cluster no Linux. Nas implantações do AG baseadas no Windows Server, os failovers manuais precisam ser feitos por meio do SQL Server. Os failovers automáticos são tratados pelo cluster subjacente no Windows Server e no Linux.
- Para o SQL Server em Linux, a configuração recomendada para AGs é, no mínimo, de três réplicas. Isso ocorre devido à maneira que o clustering subjacente funciona.
- No Linux, o nome comum usado por cada ouvinte é definido no DNS e não no cluster, como no Windows Server.
Do SQL Server 2017 (14.x) em diante, há novos recursos e aprimoramentos para AGs:
- Tipos de cluster
- REQUIRED_SECONDARIES_TO_COMMIT
- Suporte aprimorado do Coordenador de Transação do Distribuidor (DTC) da Microsoft para configurações com base no Windows Server
- Cenários adicionais de escala horizontal de bancos de dados somente leitura (descritos posteriormente neste artigo)
Tipos de clusters do grupo de disponibilidade
O formulário de disponibilidade interna de clustering no Windows Server é habilitado por meio de um recurso chamado Clustering de Failover. Ele permite que você crie um WSFC para ser usado com um AG ou uma FCI. A integração de AGs e FCIs é fornecida pelas DLLs de recurso com suporte a cluster entregues pelo SQL Server.
O SQL Server em Linux dá suporte a várias tecnologias de clustering. A Microsoft dá suporte aos componentes do SQL Server, enquanto nossos parceiros dão suporte à tecnologia de clustering relevante. Por exemplo, acompanhado do Pacemaker, o SQL Server em Linux dá suporte ao HPE Serviceguard e ao DH2i DxEnterprise como uma solução de cluster.
Um cluster de failover baseado no Windows e uma solução de cluster do Linux são mais semelhantes do que diferentes. Ambos fornecem uma maneira de obter servidores individuais e combiná-los em uma configuração para fornecer disponibilidade e têm conceitos de coisas como recursos, restrições (mesmo se implementadas de maneira diferente), failover e assim por diante.
Por exemplo, a fim de dar suporte ao Pacemaker nas configurações do AG e da FCI, incluindo recursos como o failover automático, a Microsoft fornece ao Pacemaker o pacote mssql-server-ha, que é semelhante, mas não exatamente igual às DLLs de recurso de um WSFC. Uma das diferenças entre um WSFC e o Pacemaker é que não há recursos de nome de rede no Pacemaker. Ele é o componente que ajuda a resumir o nome do ouvinte (ou o nome da FCI) em um WSFC. O DNS fornece essa resolução de nome no Linux.
Devido à diferença na pilha do cluster, algumas alterações precisam ser feitas nos AGs, porque o SQL Server precisa processar alguns dos metadados que são nativamente tratados por um WSFC. Uma alteração significativa desse tipo é a introdução de um tipo de cluster para um grupo de disponibilidade. Isso é armazenado em sys.availability_groups nas colunas cluster_type e cluster_type_desc. Há três tipos de cluster:
- WSFC
- Externo
- Nenhum
Todos os AGs que exigem alta disponibilidade precisarão usar um cluster subjacente, que, no caso do SQL Server 2017 (14.x) e versões posteriores, significa o WSFC ou um agente de clustering do Linux. Para os AGs baseados no Windows Server que usam um WSFC subjacente, o tipo de cluster padrão é o WSFC e não precisa ser definido. Para os AGs baseados em Linux, quando o AG é criado, o tipo de cluster precisa ser definido como Externo. A integração a uma solução de cluster externo no Linux é configurada depois que o AG é criado, enquanto em um WSFC, isso é feito no momento da criação.
O tipo de cluster Nenhum pode ser usado com AGs do Windows Server e do Linux. A definição do tipo de cluster como Nenhum significa que o AG não exige um cluster subjacente. Isso significa que o SQL Server 2017 (14.x) é a primeira versão do SQL Server a dar suporte aos AGs sem um cluster, mas a desvantagem é que não há suporte para essa configuração como uma solução de alta disponibilidade.
Importante
Do SQL Server 2017 (14.x) em diante, não é possível alterar um tipo de cluster em um AG depois que ele é criado. Isso indica que um AG não pode ser alternado de Nenhum para Externo ou para WSFC ou vice-versa.
Usar um AG com o tipo de cluster Nenhum é a solução perfeita para aqueles que desejam apenas adicionar cópias somente leitura extras de um banco de dados ou gostam do que um AG fornece para executar migrações/atualizações, porém não querem ficar sujeitos à complexidade adicional de um cluster subjacente ou até de uma replicação. Para obter mais informações, consulte as seções Migrações e upgrades e Escala de leitura.
A captura de tela abaixo mostra o suporte para os diferentes tipos de cluster do SSMS (SQL Server Management Studio). Você deve estar executando a versão 17.1 ou posterior. A captura de tela abaixo é da versão 17.2.

REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT
O SQL Server 2016 (13.x) aumentou o suporte para o número de réplicas síncronas de duas para três na edição Enterprise. No entanto, se uma réplica secundária foi sincronizada, mas a outra estava com problema, não havia como controlar o comportamento para informar à primária para aguardar a réplica com comportamento inadequado ou para permitir que ela prossiga. Isso significa que a réplica primária, em algum momento, continuará recebendo o tráfego de gravação, mesmo que a réplica secundária não esteja em um estado sincronizado, o que significa que há perda de dados na réplica secundária.
Do SQL Server 2017 (14.x) em diante, é possível controlar o comportamento do que acontece quando há réplicas síncronas com REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT. Essa opção funciona da seguinte maneira:
- Há três valores possíveis:
0,1e2 - O valor é o número de réplicas secundárias que precisam ser sincronizadas, que tem implicações quanto à perda de dados, à disponibilidade do AG e ao failover
- Para os WSFCs e o tipo de cluster Nenhum, o valor padrão é
0e pode ser definido manualmente como1ou2 - Para o tipo de cluster Externo, por padrão, o mecanismo de cluster definirá esse valor e ele poderá ser substituído manualmente. Para três réplicas síncronas, o valor padrão será
1.
No Linux, o valor de REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT é configurado no recurso de AG no cluster. No Windows, ele é definido por meio do Transact-SQL.
Um valor maior que 0 garante maior proteção de dados, porque se o número necessário de réplicas secundárias não estiver disponível, a primária não estará disponível até que seja resolvida. O REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT também afeta o comportamento de failover, pois o failover automático não poderá ocorrer se o número correto de réplicas secundárias não estiver no estado apropriado. No Linux, um valor igual a 0 não permitirá o failover automático, ou seja, no Linux, quando o síncrono com o failover automático é usado, o valor precisará ser definido como maior que 0 para que o failover automático seja obtido. O 0 no Windows Server é o comportamento no SQL Server 2016 (13.x) e versões anteriores.
Suporte aprimorado ao Coordenador de Transações Distribuídas da Microsoft
Antes do SQL Server 2016 (13.x), implantar FCIs era o único modo de obter disponibilidade no SQL Server para os aplicativos que exigem transações distribuídas, que usam o DTC de modo oculto. Uma transação distribuída pode ser feita de duas maneiras:
- Uma transação que abrange mais de um banco de dados na mesma instância do SQL Server
- Uma transação que abrange mais de uma instância do SQL Server ou possivelmente envolve uma fonte de dados que não seja do SQL Server
O SQL Server 2016 (13.x) introduziu o suporte parcial do DTC com os AGs que abordaram o último cenário. O SQL Server 2017 (14.x) conclui a história dando suporte a ambos os cenários com o DTC.
No SQL Server 2017 (14.x) e versões posteriores, o suporte do DTC também pode ser adicionado a um AG após a criação dele. No SQL Server 2016 (13.x), a habilitação do suporte para o DTC para um AG só podia ser feita quando o AG era criado.
Instâncias de cluster de failover
As instalações de cluster são um recurso do SQL Server desde a versão 6.5. As FCIs são um método comprovado para fornecer disponibilidade para toda a instalação do SQL Server, conhecida como uma instância. Isso significa que tudo dentro da instância, incluindo bancos de dados, trabalhos do SQL Server Agent, servidores vinculados etc., será movido para outro servidor se o servidor adjacente encontrar um problema. Todas as FCIs exigem um tipo de armazenamento compartilhado, mesmo que ele seja fornecido pela rede. Os recursos da FCI só poderão ser executados e controlados por um nó a qualquer momento. No diagrama abaixo, o primeiro nó do cluster é o proprietário da FCI, o que também significa que ele é o proprietário dos recursos de armazenamento compartilhados associados a ele, indicados por uma linha sólida em direção ao armazenamento.

Após um failover, a propriedade é alterada conforme visto no diagrama abaixo.

Não há perda de dados com uma FCI, mas o armazenamento compartilhado subjacente é um ponto único de falha, pois há uma cópia dos dados. Em geral, as FCIs são combinadas com outro método de disponibilidade, como um AG ou o envio de logs, para ter cópias redundantes dos bancos de dados. O método adicional implantado deve usar armazenamento fisicamente separado da FCI. Ao fazer failover em outro nó, a FCI é interrompida em um nó e inicia em outro, de modo semelhante a ligar e desligar um servidor. Uma FCI passa pelo processo de recuperação normal, o que significa que todas as transações que precisam que o roll forward seja efetuado serão revertidas, assim como todas as transações que estão incompletas. Portanto, o banco de dados é consistente de um ponto de dados até o momento da falha ou do failover manual, portanto, sem perda de dados. Os bancos de dados só ficam disponíveis após a conclusão da recuperação, ou seja, o tempo de recuperação dependerá de muitos fatores e geralmente será maior do que a execução de um failover em um AG. A desvantagem de fazer failover em um AG, que talvez seja necessário executar tarefas extras para tornar um banco de dados utilizável, como habilitar um trabalho do SQL Server Agent.
Como um AG, as FCIs eliminam o nó do cluster subjacente que o está hospedando. Uma FCI sempre mantém o mesmo nome. Os aplicativos e usuários finais nunca se conectam aos nós. O nome exclusivo atribuído à FCI é usado. Uma FCI pode participar de um AG como uma das instâncias que hospedam uma réplica primária ou secundária.
A lista a seguir destaca algumas diferenças de FCIs no Windows Server e no Linux:
- No Windows Server, uma FCI faz parte do processo de instalação. Uma FCI no Linux é configurada após a instalação do SQL Server.
- O Linux dá suporte a apenas uma única instalação do SQL Server por host, para que todas as FCIs sejam uma instância padrão. O Windows Server dá suporte a até 25 FCIs por WSFC.
- O nome comum usado pelas FCIs no Linux é definido no DNS e deve ser o mesmo que o recurso criado para a FCI.
Envio de logs
Se os objetivos de ponto de recuperação e de tempo de recuperação forem mais flexíveis ou os bancos de dados não forem considerados altamente críticos, o envio de logs será outro recurso de disponibilidade comprovado no SQL Server. Com base nos backups nativos do SQL Server, o processo de envio de logs automaticamente gera os backups de log de transações, copia-os em uma ou mais instâncias conhecidas como uma espera passiva e aplica automaticamente os backups de log de transações a esse modo de espera. O envio de logs usa trabalhos do SQL Server Agent para automatizar o processo de backup, cópia e aplicação dos backups de log de transações.

Possivelmente, a maior vantagem de usar o envio de logs, de alguma forma, é que ele é responsável por erro humano. O aplicativo dos logs de transações pode estar atrasado. Portanto, se alguém emitir algo parecido com uma ATUALIZAÇÃO sem uma cláusula WHERE, o modo em espera poderá não ter a alteração, então você poderá alternar para ela enquanto repara o sistema primário. Enquanto o envio de logs é fácil de configurar, a troca do primário para um estado de espera passiva, conhecido como uma alteração de função, é sempre manual. Uma alteração de função é iniciada por meio do Transact-SQL e, como um AG, todos os objetos não capturados no log de transações precisam ser sincronizados manualmente. O envio de logs também precisa ser configurado por banco de dados, enquanto um AG individual pode conter vários bancos de dados.
Ao contrário de um AG ou de uma FCI, o envio de logs não tem abstração para uma alteração de função, com a qual os aplicativos precisam conseguir lidar. Podem ser empregadas técnicas como um alias DNS (CNAME), mas há vantagens e desvantagens, como o tempo necessário que o DNS leva para atualizar após a troca.
Recuperação de desastre
Quando seu local de disponibilidade primária passa por um evento catastrófico, como um terremoto ou uma enchente, a empresa deve estar preparada para que seus sistemas fiquem online em outro lugar. Esta seção abordará como os recursos de disponibilidade do SQL Server podem auxiliar nessa continuidade dos negócios.
Grupos de disponibilidade
Um dos benefícios dos AGs é que a alta disponibilidade e a recuperação de desastre podem ser configuradas por meio de um recurso individual. Sem a necessidade de garantir que o armazenamento compartilhado também seja altamente disponível, é mais fácil ter réplicas que são locais em um data center para a alta disponibilidade e remotas em outros dados centers para a recuperação de desastre, cada uma com um armazenamento separado. Ter cópias extras do banco de dados é a desvantagem para garantir a redundância. Um exemplo de um AG que abrange vários data centers é mostrado abaixo. Uma réplica primária é responsável por manter todas as réplicas secundárias sincronizadas.

Fora de um AG com o tipo de cluster Nenhum, um AG exige que todas as réplicas façam parte do mesmo cluster subjacente, seja um WSFC ou uma solução de cluster externo. Isso significa que, no diagrama acima, o WSFC é alongado para funcionar em dois data centers diferentes, o que adiciona complexidade ao processo. independentemente da plataforma (Windows Server ou Linux). Transferir clusters em distância adiciona complexidade.
Introduzido no SQL Server 2016 (13.x), um grupo de disponibilidade distribuído permite que um AG abranja AGs configurados em clusters diferentes. Os AGs distribuídos separam a necessidade de que todos os nós participem do mesmo cluster, o que facilita a configuração de recuperação de desastre. Para obter mais informações sobre os AGs distribuídos, confira Grupos de disponibilidade distribuídos.

Instâncias de cluster de failover
As FCIs podem ser usadas para recuperação de desastres. Do mesmo modo que ocorre em um AG normal, o mecanismo do cluster subjacente também precisa ser estendido para todas as localizações, o que adiciona complexidade ao processo. Há uma consideração adicional sobre as FCIs: o armazenamento compartilhado. Os mesmos discos precisam estar disponíveis nos sites primário e secundário. Um método externo, como a funcionalidade fornecida pelo fornecedor de armazenamento na camada de hardware ou o uso da Réplica de armazenamento no Windows Server, é necessário para garantir que os discos usados pela FCI existam em outro lugar.

Envio de logs
O envio de logs é um dos métodos mais antigos para fornecer recuperação de desastres aos bancos de dados do SQL Server. Em geral, o envio de logs é usado com AGs e FCIs para fornecer uma recuperação de desastre econômica e mais simples. Por outro lado, o uso de outras opções pode ser complexo, devido ao ambiente, às habilidades administrativas ou ao orçamento. Similar à história de alta disponibilidade para envio de logs, muitos ambientes atrasarão o carregamento de um log de transações para responsabilizar por erro humano.
Migrações e atualizações
Durante a implantação de novas instâncias ou a atualização de instâncias antigas, uma empresa não pode tolerar interrupções prolongadas. Esta seção abordará como os recursos de disponibilidade do SQL Server podem ser usados para minimizar o tempo de inatividade em uma alteração de arquitetura planejada, troca de servidor, alteração da plataforma (como Windows Server para Linux ou vice-versa) ou durante a aplicação de patch.
Observação
Outros métodos, como o uso de backups e a restauração deles em outro lugar, também podem ser usados para migrações e atualizações. Eles não são abordados neste artigo.
Grupos de disponibilidade
Uma instância existente que contém um ou mais AGs pode ser atualizada in-loco para versões posteriores do SQL Server. Enquanto isso requer algum tempo de inatividade, com a quantidade certa de planejamento, ela pode ser minimizada.
Se a meta é a migração para novos servidores e a não alteração da configuração (incluindo o sistema operacional ou a versão do SQL Server), esses servidores podem ser adicionados como nós ao cluster subjacente existente e adicionados ao AG. Depois que as réplicas estiverem no estado correto, poderá ocorrer um failover manual para um novo servidor e os antigos poderão ser removidos do AG, sendo, por fim, desativados.
Os grupos de disponibilidade distribuídos também são outro método para migrar para uma nova configuração ou atualizar o SQL Server. Como um AG distribuído dá suporte a diferentes AGs subjacentes em arquiteturas diferentes, por exemplo, você poderá alterar do SQL Server 2016 (13.x) em execução no Windows Server 2012 R2 para o SQL Server 2017 (14.x) em execução no Windows Server 2016.
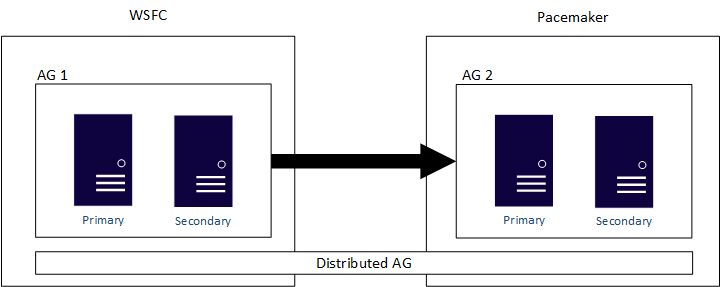
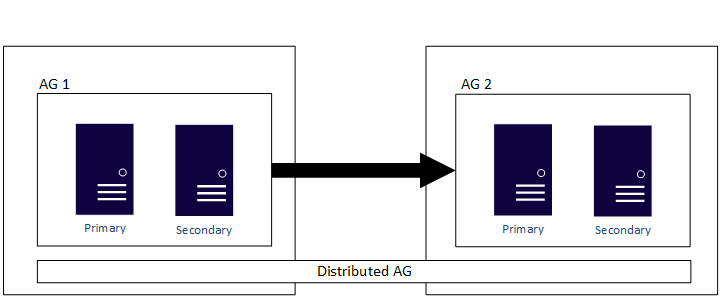
Por fim, os AGs com o tipo de cluster Nenhum também podem ser usados para a migração ou a atualização. Não é possível combinar tipos de clusters em uma configuração típica de AG, ou seja, todas as réplicas precisam ser do tipo Nenhum. Um AG distribuído pode ser usado para abranger os AGs configurados com diferentes tipos de clusters. Esse método também tem suporte em todas as plataformas de sistema operacional diferentes.
Todas as variantes de AGs para as migrações e as atualizações permitem que a parte mais demorada do trabalho seja feita ao longo do tempo: a sincronização de dados. Quando chegar a hora de iniciar a troca para a nova configuração, a transferência será uma breve interrupção versus um longo período de tempo de inatividade em que todo o trabalho, incluindo a sincronização de dados, precisa ser concluído.
Os AGs podem fornecer o tempo de inatividade mínimo durante a aplicação de patch do sistema operacional subjacente fazendo failover manual da réplica primária para a secundária enquanto a aplicação de patch estiver sendo concluída. Da perspectiva do sistema operacional, isso seria mais comum no Windows Server, já que frequentemente, mas nem sempre, a manutenção do sistema operacional subjacente pode exigir uma reinicialização. Às vezes, a aplicação de patch no Linux precisa de uma reinicialização, mas isso pode ser pouco frequente.
A aplicação de patch nas instâncias do SQL Server que participam de um grupo de disponibilidade também pode minimizar o tempo de inatividade, dependendo da complexidade da arquitetura do AG. Para que seja aplicado um patch nos servidores que participam de um AG, uma réplica secundária é corrigida primeiro. Depois que o número correto de réplicas for corrigido, a réplica primária terá o failover feito manualmente para outro nó a fim de fazer a atualização. Qualquer réplica secundária restante, neste ponto, também pode ser atualizada.
Instâncias de cluster de failover
As FCIs por si sós não conseguem ajudar na migração ou na atualização tradicional. Um AG ou o envio de logs precisa ser configurado para os bancos de dados na FCI e todos os outros objetos considerados. No entanto, as FCIs no Windows Server ainda são uma opção popular para quando os Windows Servers subjacentes precisam ser corrigidos. Um failover manual pode ser iniciado, o que significa uma breve interrupção, em vez de fazer com que a instância fique completamente indisponível o tempo todo em que o Windows Server está sendo corrigido. Uma FCI pode ser atualizada localmente para versões posteriores do SQL Server. Para obter informações, consulte Atualizar uma Instância de Cluster de Failover do SQL Server.
Envio de logs
O envio de logs ainda é uma opção popular para migrar e atualizar bancos de dados. Semelhante aos AGs, mas desta vez usando o log de transações como o método de sincronização, a propagação de dados pode ser iniciada bem antes da troca do servidor. No momento da troca, depois que todo o tráfego for interrompido na origem, um log de transações final precisará ser obtido, copiados e aplicado à nova configuração. Nesse momento, o banco de dados pode ser colocado online. Em geral, o envio de logs é mais tolerante a redes mais lentas e, embora a troca possa ser um pouco mais longa do que aquela feita com um AG ou um AG distribuído, ela geralmente é medida em minutos, não em horas, dias ou semanas.
Semelhante aos AGs, o envio de logs pode fornecer uma forma para alternar para outro servidor no caso de uma aplicação de patch.
Outros métodos de implantação do SQL Server e disponibilidade
Há dois outros métodos de implantação do SQL Server no Linux: contêineres e uso do Azure (ou outro provedor de nuvem pública). A necessidade geral para disponibilidade, como apresentado neste documento, existe independentemente de como o SQL Server é implantado. Esses dois métodos têm algumas considerações especiais quando se trata de tornar o SQL Server altamente disponível.
Opções de HA/DR e contêineres do SQL Server
A implantação de contêiner do SQL Server é uma nova maneira de implantar o SQL Server em Linux. Um contêiner é uma imagem completa do SQL Server que está para ser executada.
Dependendo da plataforma de contêiner usada, por exemplo, ao usar um orquestrador de contêineres como o Kubernetes, se o contêiner for perdido, ele poderá ser implantado novamente e anexado ao armazenamento compartilhado que foi usado. Embora isso forneça um pouco de resiliência, haverá um tempo de inatividade associado à recuperação de banco de dados e isso não será, de fato, altamente disponível como seria se um grupo de disponibilidade ou uma FCI fosse usada.
Se você estiver procurando configurar a alta disponibilidade para os contêineres do SQL Server implantados em plataformas de Kubernetes ou não Kubernetes, use o DH2i DxEnterprise como uma das soluções de clustering, com base no qual você poderá configurar um AG no modo de alta disponibilidade. Essa opção fornece o RPO (objetivo de ponto de recuperação) e o RTO (objetivo de tempo de recuperação) esperados de uma solução de alta disponibilidade.
Implantação de IaaS baseada em Linux
As máquinas virtuais Linux IaaS podem ser implantadas com o SQL Server instalado usando o Azure. Assim como as instalações baseadas no local, uma instalação com suporte exige o uso de STONITH (Shoot the Other Node in the Head), que é externo ao agente de cluster em si. O STONITH é fornecido por meio de agentes de disponibilidade de isolamento. Algumas distribuições os enviam como parte da plataforma, enquanto outras contam com fornecedores externos de hardware e software. Verifique sua distribuição Linux preferencial para ver quais formatos de STONITH são fornecidos para que uma solução com suporte seja implantada na nuvem pública.
Os guias de instalação do SQL Server em Linux estão disponíveis para as seguintes distribuições:
- Início Rápido: Instalar o SQL Server e criar um banco de dados no Red Hat
- Início Rápido: Instalar o SQL Server e criar um banco de dados no Ubuntu
- Início Rápido: instalar o SQL Server e criar um banco de dados no SUSE Linux Enterprise Server
Escala de leitura
Desde o lançamento das réplicas secundárias no SQL Server 2012 (11.x), elas têm a capacidade de serem usadas para consultas somente leitura. Há duas maneiras de fazer isso com um AG: permitindo o acesso direto ao secundário, bem como configurando o roteamento somente leitura, que exige o uso do ouvinte. O SQL Server 2016 (13.x) introduziu a capacidade de balancear a carga de conexões somente leitura por meio do ouvinte usando um algoritmo de round robin, permitindo que as solicitações somente leitura sejam distribuídas entre todas as réplicas de leitura.
Observação
As réplicas secundárias para leitura são um recurso disponível apenas na edição Enterprise, e cada instância que hospeda uma réplica de leitura precisará ter uma licença do SQL Server.
A escala de cópias de leitura de um banco de dados por meio de AGs foi primeiramente introduzida com os AGs distribuídos no SQL Server 2016 (13.x). Isso permitiria que as empresas tivessem cópias de somente leitura do banco de dados não apenas localmente, mas regional e globalmente com uma quantidade mínima de configuração e reduziria o tráfego de rede e a latência ao executar as consultas localmente. Cada réplica primária de um AG pode propagar dois outros AGs, mesmo que ela não seja a cópia de leitura/gravação completa, ou seja, cada AG distribuído pode dar suporte a até 27 cópias dos dados de leitura.

Do SQL Server 2017 (14.x) em diante, é possível criar uma solução somente leitura quase em tempo real com os AGs configurados com o tipo de cluster Nenhum. Se a meta é usar AGs para réplicas secundárias para leitura e não para disponibilidade, isso elimina a complexidade do uso de um WSFC ou de uma solução de cluster externo no Linux, além de oferecer os benefícios de leitura de um AG em um método de implantação mais simples.
A única ressalva é que não há clusters subjacentes com um tipo de cluster None. Desse modo, configurar um roteamento somente leitura é um pouco diferente. Da perspectiva do SQL Server, um ouvinte ainda é necessário para encaminhar as solicitações, embora não exista nenhum cluster. Em vez de configurar um ouvinte tradicional, o endereço IP ou o nome da réplica primária são usados. Depois a réplica primária será usada para rotear solicitações somente leitura.
Uma espera passiva para envio de logs pode tecnicamente ser configurada para uso legível ao restaurar o banco de dados WITH STANDBY. No entanto, como os logs de transações exigem o uso exclusivo do banco de dados para restauração, isso significa que usuários não podem acessar o banco de dados enquanto isso acontece. Isso tornará o envio de logs uma solução abaixo do ideal, especialmente se os dados quase em tempo real forem necessários.
Um aspecto que deve ser observado em todos os cenários de escala de leitura com AGs é que, ao contrário do uso da replicação transacional na qual todos os dados são dinâmicos, cada réplica secundária não está em um estado no qual os índices exclusivos possam ser aplicados: a réplica é uma cópia exata da primária. Se algum índice for necessário para relatórios ou se os dados precisarem ser processados, eles precisarão ser criados nos bancos de dados na réplica primária. Se você precisar dessa flexibilidade, a replicação será uma solução melhor para dados legíveis.
Interoperabilidade de distribuição do Linux e de multiplataforma
Como o SQL Server agora é compatível com o Windows Server e o Linux, esta seção abordará os cenários em que eles podem funcionar em conjunto para obter disponibilidade, entre outras finalidades, bem como a história de soluções que vão incorporar mais de uma distribuição do Linux.
Observação
Não há nenhum cenário no qual uma FCI ou um AG baseado em WSFC funcionará com uma FCI ou um AG baseado em Linux diretamente. Um WSFC não pode ser estendido por um nó do Pacemaker e vice-versa.
Grupos de disponibilidade distribuídos
Os AGs distribuídos foram projetados para abranger as configurações do AG, sejam esses dois clusters subjacentes abaixo dos AGs dois WSFCs diferentes, distribuições do Linux ou um esteja em um WSFC e o outro no Linux. Um AG distribuído será o principal método para ter uma solução multiplataforma. Um AG distribuído também é a principal solução para migrações, como a conversão de uma infraestrutura do SQL Server baseada no Windows Server para uma baseada em Linux, se isso for o que a sua empresa deseja fazer. Conforme indicado acima, os AGs e, especialmente, os AGs distribuídos, minimizarão o tempo que um aplicativo estará indisponível para uso. Um exemplo de um AG distribuído que abrange um WSFC e o Pacemaker é mostrado abaixo.
Caso um AG seja configurado com o tipo de cluster Nenhum, ele pode abranger o Windows Server e o Linux, bem como várias distribuições do Linux. Como essa não é, de fato, uma configuração de alta disponibilidade, ela não deve ser usada para implantações críticas, mas para cenários de escala de leitura ou migração/atualização.
Envio de logs
Como o envio de logs é baseado em backup e restauração, não há diferenças nos bancos de dados, nas estruturas de arquivos, entre outros, do SQL Server no Windows Server em comparação com o SQL Server em Linux. Isso significa que o envio de logs pode ser configurado entre uma instalação do SQL Server baseada no Windows Server e uma baseada no Linux, bem como entre distribuições do Linux. Todo o resto permanece o mesmo. A única ressalva é que o envio de logs, assim como um AG, não funciona quando a fonte tem uma versão principal superior do SQL Server em relação a um destino que tem uma versão inferior do SQL Server.
Resumo
As instâncias e os bancos de dados do SQL Server 2017 (14.x) e versões posteriores podem se tornar altamente disponíveis por meio dos mesmos recursos no Windows Server e no Linux. Além de cenários de disponibilidade padrão de recuperação de desastres e alta disponibilidade local, o tempo de inatividade associado a migrações e atualizações pode ser minimizado com os recursos de disponibilidade do SQL Server. Os AGs também podem fornecer cópias adicionais de um banco de dados como parte da mesma arquitetura para escalar horizontalmente cópias de leitura. Se você estiver implantando uma nova solução ou considerando fazer uma atualização, o SQL Server tem a disponibilidade e a confiabilidade de que você precisa.