Tutorial: criar um modelo preditivo no R com o aprendizado de máquina do SQL
Aplica-se a: ![]() SQL Server 2016 (13.x) e versões posteriores
SQL Server 2016 (13.x) e versões posteriores ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Na parte três desta série de tutoriais de quatro partes, você treinará um modelo preditivo em R e, na próxima parte desta série, você implantará esse modelo em um banco de dados do SQL Server com o Serviços de Machine Learning ou em Clusters de Big Data.
Na parte três desta série de tutoriais de quatro partes, você treinará um modelo preditivo em R e, na próxima parte desta série, você implantará esse modelo em um banco de dados do SQL Server com os Serviços de Machine Learning.
Na parte três desta série de tutoriais de quatro partes, você treinará um modelo preditivo em R e, na próxima parte desta série, você implantará esse modelo em um banco de dados com o SQL Server R Services.
Na parte três desta série de tutoriais de quatro partes, você treinará um modelo preditivo em R e, na próxima parte desta série, você implantará esse modelo em um banco de dados da Instância Gerenciada de SQL do Azure com os Serviços de Machine Learning.
Neste artigo, você aprenderá a:
- Treinar dois modelos de machine learning
- Fazer previsões de ambos os modelos
- Compare os resultados para escolher o modelo mais preciso
Na parte um, você aprendeu a restaurar o banco de dados de exemplo.
Na parte dois, você aprendeu a carregar os dados de um banco de dados em uma estrutura de dados do Python e a prepará-los no R.
Na parte quatro, você aprenderá a armazenar o modelo em um banco de dados e, em seguida, criará procedimentos armazenados com base nos scripts do Python desenvolvidos nas partes dois e três. Os procedimentos armazenados serão executados no servidor para fazer previsões com base em novos dados.
Pré-requisitos
A parte três desta série de tutoriais pressupõe que você atendeu aos pré-requisitos da parte um e concluiu as etapas na parte dois.
Treinar dois modelos
Para encontrar o melhor modelo para os dados de aluguel de esqui, crie dois modelos diferentes (regressão linear e árvore de decisão) e veja qual deles está prevendo com mais precisão. Você usará o quadro de dados rentaldata que você criou na primeira parte desta série.
#First, split the dataset into two different sets:
# one for training the model and the other for validating it
train_data = rentaldata[rentaldata$Year < 2015,];
test_data = rentaldata[rentaldata$Year == 2015,];
#Use the RentalCount column to check the quality of the prediction against actual values
actual_counts <- test_data$RentalCount;
#Model 1: Use lm to create a linear regression model, trained with the training data set
model_lm <- lm(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
#Model 2: Use rpart to create a decision tree model, trained with the training data set
library(rpart);
model_rpart <- rpart(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
Fazer previsões de ambos os modelos
Use uma função de previsão para prever as contagens de aluguel usando cada modelo treinado.
#Use both models to make predictions using the test data set.
predict_lm <- predict(model_lm, test_data)
predict_lm <- data.frame(RentalCount_Pred = predict_lm, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
predict_rpart <- predict(model_rpart, test_data)
predict_rpart <- data.frame(RentalCount_Pred = predict_rpart, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
#To verify it worked, look at the top rows of the two prediction data sets.
head(predict_lm);
head(predict_rpart);
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 27.45858 42 2 11 4 0 0
2 387.29344 360 3 29 1 0 0
3 16.37349 20 4 22 4 0 0
4 31.07058 42 3 6 6 0 0
5 463.97263 405 2 28 7 1 0
6 102.21695 38 1 12 2 1 0
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 40.0000 42 2 11 4 0 0
2 332.5714 360 3 29 1 0 0
3 27.7500 20 4 22 4 0 0
4 34.2500 42 3 6 6 0 0
5 645.7059 405 2 28 7 1 0
6 40.0000 38 1 12 2 1 0
Compare os resultados
Agora você deseja ver qual dos modelos fornece as melhores previsões. Uma maneira rápida e fácil de fazer isso é usar uma função de plotagem básica para exibir a diferença entre os valores reais de seus dados de treinamento e os valores previstos.
#Use the plotting functionality in R to visualize the results from the predictions
par(mfrow = c(1, 1));
plot(predict_lm$RentalCount_Pred - predict_lm$RentalCount, main = "Difference between actual and predicted. lm")
plot(predict_rpart$RentalCount_Pred - predict_rpart$RentalCount, main = "Difference between actual and predicted. rpart")
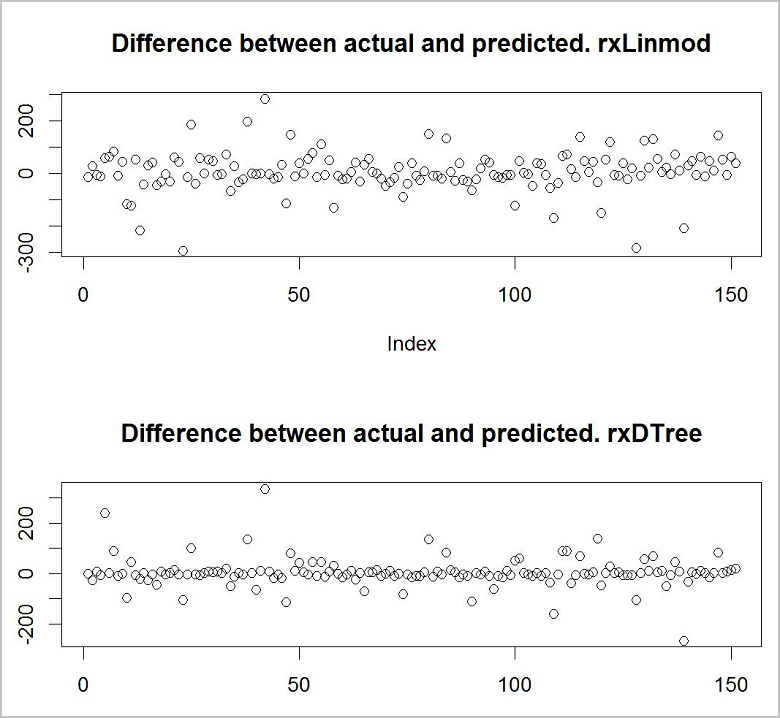
Parece que o modelo de árvore de decisão é mais preciso dos dois.
Limpar os recursos
Se você não continuar com este tutorial, exclua o banco de dados TutorialDB.
Próximas etapas
Na parte três desta série de tutoriais, você aprendeu a:
- Treinar dois modelos de machine learning
- Fazer previsões de ambos os modelos
- Compare os resultados para escolher o modelo mais preciso
Para implantar o modelo de machine learning que você criou, siga a parte quatro desta série de tutoriais: