Guia de arquitetura e design de índices do SQL Server e do SQL do Azure
Aplica-se a: ![]() SQL Server
SQL Server ![]() Banco de dados SQL do Azure
Banco de dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Os índices criados inadequadamente e a falta de índices são as principais fontes de gargalos do aplicativo de banco de dados. A criação eficiente de índices é muito importante para alcançar um bom desempenho de banco de dados e de aplicativo. Este guia de design de índices contém informações sobre a arquitetura de índices e as melhores práticas para ajudar você a criar índices efetivos de acordo com as necessidades de seu aplicativo.
Este guia presume que o leitor tenha uma compreensão geral dos tipos de índices disponíveis. Para obter uma descrição geral dos tipos de índices, consulte Índices.
Este guia aborda os seguintes tipos de índices:
| Formato de armazenamento primário | Tipo de índice |
|---|---|
| Rowstore baseado em disco | |
| Clusterizado | |
| Não clusterizado | |
| Exclusivo | |
| Filtered | |
| Columnstore | |
| Columnstore clusterizado | |
| Columnstore não clusterizado | |
| Com otimização de memória | |
| Hash | |
| Não clusterizado com otimização de memória |
Para obter informações sobre índices XML, consulte Índices XML (SQL Server) e Índices XML seletivos (SQL Server).
Para obter informações sobre índices espaciais, veja Visão geral de índices espaciais.
Para obter informações sobre índices de texto completo, consulte Preencher índices de texto completo.
Noções básicas de design de índices
Pense em um livro normal: no final do livro, há um índice que ajuda a localizar rapidamente as informações dentro dele. O índice é uma lista classificada de palavras-chave e, ao lado de cada palavra-chave, está um conjunto de números de página que aponta para as páginas em que cada palavra-chave pode ser encontrada.
Um índice rowstore não é diferente: ele é uma lista ordenada de valores e, para cada valor, há ponteiros para as páginas de dados em que esses valores estão localizados. O índice propriamente dito é armazenado em páginas, chamadas de páginas de índice. Em um livro normal, se o índice abranger várias páginas e você precisar localizar ponteiros para todas as páginas que contêm a palavra SQL, por exemplo, você precisará folhear até encontrar a página de índice que contém a palavra-chave SQL. Nele, você seguirá os ponteiros para todas as páginas do livro. Isso poderá ser otimizado ainda mais se, no início do índice, você criar uma única página contendo uma lista alfabética do local em que cada letra pode ser encontrada. Por exemplo: "A a D - página 121", "E a G - página 122" e assim por diante. Essa página extra eliminaria a etapa de folhear no índice para encontrar o local inicial. Essa página não existe em livros comuns, mas existe em um índice de rowstore. Essa página única é chamada de página raiz do índice. A página raiz é a página inicial da estrutura de árvore usada por um índice. Seguindo a analogia da árvore, as páginas finais que contêm ponteiros para os dados reais são chamadas de "páginas de folha" da árvore.
Um índice é uma estrutura em disco ou in-memory associada a uma tabela ou exibição que acelera a recuperação de linhas de uma tabela ou exibição. Um índice rowstore contém chaves criadas de uma ou mais colunas da tabela ou exibição. Para índices rowstore, essas chaves são armazenadas em uma estrutura de árvore (árvore B+) que permite ao Mecanismo de Banco de Dados localizar a linha ou as linhas associadas aos valores de chave de modo rápido e eficaz.
Um índice rowstore armazena dados logicamente organizados como uma tabela com linhas e colunas e fisicamente armazenados em um formato de dados de linha chamado rowstore 1 ou armazenados em um formato de dados de coluna chamado columnstore.
A seleção dos índices certos para um banco de dados e sua carga de trabalho é um ato de balanceamento complexo entre a velocidade de consulta e o custo de atualização. Índices rowstore com base em disco limitados ou com poucas colunas na chave de índice exigem menos espaço em disco e sobrecarga de manutenção. Por outro lado, índices amplos cobrem mais consultas. Talvez você precise experimentar vários projetos diferentes antes de encontrar o índice mais eficiente. Os índices podem ser adicionados, modificados e descartados sem afetar o esquema de banco de dados ou o design do aplicativo. Portanto, você não deve hesitar em fazer experiências com diferentes índices.
O otimizador de consultas no Mecanismo de Banco de Dados escolhe de forma confiável o índice mais eficaz na maioria dos casos. Sua estratégia geral de design de índice deve fornecer vários índices para o otimizador de consulta escolher e confiar que ele tomará a decisão certa. Isso reduz o tempo de análise e atinge um bom desempenho em várias situações. Para ver quais índices o otimizador de consultas usa para uma consulta específica, no SQL Server Management Studio, no menu Consulta, selecione Incluir Plano de Execução Real.
Não equipare sempre o uso de índice com bom desempenho e bom desempenho com uso de índice eficiente. Se o uso de um índice sempre ajudasse a produzir o melhor desempenho, a tarefa do otimizador de consulta seria simples. Na realidade, a escolha incorreta de um índice pode causar um desempenho insatisfatório. Portanto, a tarefa do otimizador de consulta é selecionar um índice, ou uma combinação de índices, somente quando isso melhorar o desempenho e evitar a recuperação indexada quando isso prejudicar o desempenho.
1 Rowstore tem sido o modo tradicional de armazenar dados de tabela relacional. Rowstore refere-se à tabela em que o formato de armazenamento de dados subjacente é um heap, uma árvore B+ (índice clusterizado) ou uma tabela com otimização de memória. O rowstore baseado em disco exclui tabelas com otimização de memória.
Tarefas de criação de índice
As seguintes tarefas compõem a estratégia recomendada para criação de índices:
Entenda as características do banco de dados.
- Por exemplo, ele é um banco de dados OLTP (processamento de transações online) com modificações frequentes de dados que precisa manter uma alta taxa de transferência? As tabelas e os índices com otimização de memória são especialmente apropriados para este cenário, fornecendo um design sem travas. Para obter mais informações, consulte Índices em tabelas com otimização de memória ou Diretrizes de design de índice não clusterizado em tabelas com otimização de memória e Diretrizes de design de índice de hash neste guia.
- Ou é um exemplo de um banco de dados DSS (Sistema de Apoio à Decisão) ou data warehouse (OLAP) que precisa processar conjuntos de dados muito grandes rapidamente? Os índices columnstore são especialmente apropriados para conjuntos de dados de data warehouse típicos. Os índices columnstore podem transformar a experiência com data warehouse para usuários proporcionando um desempenho mais rápido para consultas de data warehouse comuns, como filtragem, agregação, agrupamento ou consultas de junção em estrela. Para obter mais informações, consulte Índices columnstore: Visão geral ou Diretrizes de design de índice columnstore neste guia.
Entenda as características das consultas mais usadas. Por exemplo, saber que uma consulta usada com frequência une duas ou mais tabelas ajuda a determinar o melhor tipo de índice a ser usado.
Entenda as características das colunas usadas nas consultas. Por exemplo, um índice é ideal para colunas que têm um tipo de dados inteiro e também são colunas exclusivas ou não nulas. Para colunas que têm subconjuntos de dados bem definidos, você pode usar um índice filtrado no SQL Server 2008 (10.0.x) e versões superiores. Para obter mais informações, consulte Diretrizes de design de índices filtrados neste guia.
Determine quais opções de índice podem aumentar o desempenho na criação ou manutenção do índice. Por exemplo, a criação de um índice clusterizado em uma tabela grande existente se beneficiará da opção de índice
ONLINE. A opçãoONLINEpermite que atividade simultânea nos dados subjacentes continue enquanto o índice está sendo criado ou reconstruído. Para obter mais informações sobre opções de índice, consulte Definir opções de índice.Determine o melhor local de armazenamento para o índice.
Um índice não clusterizado pode ser armazenado no mesmo grupo de arquivos que a tabela subjacente ou em um grupo de arquivos diferente. O local de armazenamento de índices pode melhorar o desempenho de consulta aumentando desempenho de E/S do disco. Por exemplo, o armazenamento de um índice não clusterizado em um grupo de arquivos que está em um disco diferente do grupo de arquivos de tabela pode melhorar o desempenho porque vários discos podem ser lidos ao mesmo tempo. Alternativamente, os índices clusterizados e não clusterizados podem usar um esquema de partição em vários grupos de arquivos. Quando você pensar em particionamento, determine se o índice deve ser alinhado; isto é, particionado essencialmente da mesma maneira que a tabela ou particionado de forma independente. Saiba mais na seção posicionamento do índice em grupos de arquivos ou em esquemas de partições deste artigo.
Ao identificar índices ausentes com DMVs (exibições de gerenciamento dinâmico), como sys.dm_db_missing_index_details e sys.dm_db_missing_index_columns, você poderá receber variações semelhantes de índices na mesma tabela e nas mesmas colunas. Examine os índices existentes na tabela junto com as sugestões de índice ausente para evitar a criação de índices duplicados. Saiba mais em ajustar índices não clusterizados com sugestões de índice ausente.
Diretrizes gerais de design de índices
Administradores de banco de dados experientes podem projetar um bom conjunto de índices, mas essa tarefa é complexa, demorada e propensa a erros até mesmo para bancos de dados e cargas de trabalho moderadamente complexos. Compreender as características de seu banco de dados, consultas e colunas de dados pode lhe ajudar a projetar índices melhores.
Considerações do banco de dados
Quando você projeta um índice, considere as seguintes diretrizes para banco de dados:
Números grandes de índices em uma tabela afetam o desempenho das instruções
INSERT,UPDATE,DELETEeMERGEporque todos os índices precisam ser ajustados adequadamente à medida que os dados são alterados em uma tabela. Por exemplo, se uma coluna for usada em vários índices e você executar uma instruçãoUPDATEque modifica os dados dessa coluna, todos os índices que contêm essa coluna deverão ser atualizados, bem como a coluna na tabela base subjacente (heap ou índice clusterizado).Evite tabelas fortemente atualizadas em cima desindexações e mantenha os índices estreitos, ou seja, com o mínimo de colunas possível.
Use muitos índices para aperfeiçoar o desempenho da consulta em tabelas com baixos requisitos de atualização, mas com grandes volumes de dados. Números de índices elevados podem ajudar o desempenho de consultas que não modificam dados, como instruções
SELECT, porque o otimizador de consulta tem mais índices para escolher e determinar o método de acesso mais rápido.
A indexação de tabelas pequenas pode não ser ideal porque o otimizador de consulta pode levar mais tempo para percorrer o índice em busca de dados do que para executar uma verificação de tabela básica. Portanto, os índices em tabelas pequenas talvez nunca sejam usados, mas ainda devem ser mantidos como dados nas alterações de tabela.
Índices em exibições pode prover ganhos de desempenho significantes quando a exibição contiver agregações, junções de tabela ou uma combinação de agregações e junções. A exibição não precisa ser explicitamente referenciada na consulta para que o otimizador de consulta a utilize.
Os bancos de dados em réplicas primárias no Banco de Dados SQL do Azure geram automaticamente as recomendações de desempenho do assistente de banco de dados para índices. Opcionalmente, você pode habilitar o ajuste automático de índice.
O Repositório de Consultas ajuda a identificar consultas com desempenho abaixo do ideal e fornece um histórico de planos de execução de consultas que documentam os índices selecionados pelo otimizador.
Considerações de consulta
Quando você projeta um índice, considere as seguintes diretrizes para consultas:
Crie índices não clusterizados nas colunas frequentemente usadas em predicados e condições de junção em consultas. Essas são as colunas SARGable1. No entanto, evite adicionar colunas desnecessárias. Acrescentar muitas colunas de índice pode afetar adversamente o espaço em disco e o desempenho de manutenção de índice.
Cobrindo índices pode melhorar desempenho de consulta porque todos os dados precisaram satisfazer os requisitos da consulta existe dentro do próprio índice. Ou seja, apenas as páginas de índice, e não as páginas de dados da tabela ou do índice clusterizado, são necessárias para recuperar os dados solicitados, portanto reduzindo as operações de E/S gerais do disco. Por exemplo, uma consulta de colunas
AeBem uma tabela que tem um índice de composição criado em colunasA,BeCpode recuperar os dados especificados somente do índice.Índices abrangentes são a designação para um índice não clusterizado que resolve um ou vários resultados de consulta semelhantes diretamente, sem acesso à tabela base e sem incorrer em pesquisas.
Esses índices têm todas as colunas não SARGable necessárias em seu nível de folha. Isso significa que as colunas retornadas por qualquer cláusula
SELECTe todos os argumentosWHEREeJOINsão cobertos pelo índice.Haverá potencialmente muito menos E/S para executar a consulta, se o índice for estreito o suficiente em comparação com as linhas e colunas da tabela em si, o que significa que ele é um subconjunto real do total de colunas.
Considere cobrir índices ao selecionar uma pequena parte de uma tabela grande e quando essa pequena parte for definida por um predicado fixo, como colunas esparsas que contêm apenas alguns valores não NULL, por exemplo.
Escreva consultas que insiram ou modifiquem o máximo de filas possível em uma única instrução, em vez de usar consultas múltiplas para atualizar essas mesmas filas. Ao usar apenas uma instrução, pode-se explorar uma manutenção otimizada do índice.
Avalie o tipo da consulta e como as colunas são usadas na consulta. Por exemplo, uma coluna usada em uma consulta de correspondência exata seria uma boa candidata para um índice clusterizado ou não clusterizado.
1 O termo SARGable em bancos de dados relacionais refere-se a um predicado Search ARGument-able que pode usar um índice para acelerar a execução da consulta.
Considerações sobre colunas
Quando você projeta um índice, considere as seguintes diretrizes para as colunas:
Mantenha o comprimento da chave de índice curto para os índices clusterizados. Além disso, os índices clusterizados se beneficiam do fato de serem criados em colunas exclusivas ou não nulas.
As colunas que são dos tipos de dados ntext, text, image, varchar(max), nvarchar(max) e varbinary(max) não podem ser especificadas como colunas de chave de índice. Entretanto, os tipos de dados varchar(max), nvarchar(max), varbinary(max)e xml podem participar de um índice não clusterizado, como colunas de índice não chave. Para obter mais informações, consulte a seção Índice com colunas incluídas neste guia.
Um tipo de dados xml só pode ser uma coluna de chave em um índice XML. Para obter mais informações, confira Índices XML (SQL Server). O SQL Server 2012 SP1 apresentou um novo tipo de índice XML conhecido como um índice XML seletivo. Esse novo índice pode melhorar o desempenho da consulta em dados armazenados como XML, permitir a indexação mais rápida de grandes cargas de trabalho de dados XML e melhorar a escalabilidade, reduzindo os custos de armazenamento do próprio índice. Para obter mais informações, confira Índices XML seletivos (SXI).
Examine a singularidade da coluna. Um índice exclusivo em vez de um índice não exclusivo na mesma combinação de colunas, provê informações adicional para o otimizador de consulta, o que torna o índice mais útil. Para obter mais informações, consulte Diretrizes de design de índice exclusivo neste guia.
Examine a distribuição de dados na coluna. Frequentemente, uma consulta longa é causada ao se indexar uma coluna com poucos valores exclusivos, ou ao executar uma junção em tal coluna. Esse é um problema fundamental com os dados e a consulta e, em geral, não pode ser resolvido sem a identificação dessa situação. Por exemplo, uma lista telefônica física ordenada alfabeticamente por nome de família não agilizará a localização de uma pessoa se todas as pessoas da cidade se chamarem Smith ou Jones. Para obter mais informações sobre distribuição de dados, consulte Statistics.
Considere o uso de índices filtrados em colunas com subconjuntos bem definidos, por exemplo, colunas esparsas, colunas com grande a maioria dos valores
NULL, colunas com categorias de valores e colunas com intervalos diferentes de valores. Um índice filtrado bem projetado pode melhorar o desempenho da consulta e reduzir os custos de manutenção de índice e de armazenamento.Considere a ordem das colunas se o índice contiver várias colunas. A coluna que é usada na cláusula
WHEREem um critério de consulta igual a (=), maior que (>), menor que (<) ouBETWEEN, ou que participa em uma junção, deve ser posicionada primeiro. Colunas adicionais devem ser ordenadas com base em seu nível de distinção, ou seja, do mais distinto ao menos distinto.Por exemplo, se o índice for definido como
LastName,FirstNameo índice será útil quando o critério de consulta forWHERE LastName = 'Smith'ouWHERE LastName = Smith AND FirstName LIKE 'J%'. No entanto, o otimizador de consulta não usaria o índice para uma consulta que buscasse apenas emFirstName (WHERE FirstName = 'Jane').Considere indexar as colunas computadas. Para obter mais informações, consulte Índices de colunas computadas.
Características do índice
Depois de determinar que um índice é apropriado para uma consulta, você pode selecionar o tipo de índice que melhor se adapta à sua situação. Características de índice incluem a seguinte lista:
- Clusterizado X não clusterizado.
- Exclusivo X não exclusivo
- Única coluna X multicoluna
- Ordem crescente ou decrescente em colunas no índice
- Tabela completa versus filtrada para índices não clusterizados
- Columnstore versus rowstore
- Hash versus não clusterizado para tabelas com otimização de memória
Você também pode personalizar as características de armazenamento inicial do índice para aperfeiçoar seu desempenho ou manutenção definindo uma opção como FILLFACTOR. Além disso, você pode determinar o local de armazenamento de índice usando grupos de arquivos ou esquemas de partição para aperfeiçoar o desempenho.
Posicionamento de índices em esquemas de grupos de arquivos ou partições
À medida que desenvolve sua estratégia de design de índices, considere a colocação dos índices nos grupos de arquivos associados ao banco de dados. A seleção cuidadosa do grupo de arquivos ou esquema de partição pode melhorar o desempenho da consulta.
Por padrão, os índices são armazenados no mesmo grupo de arquivos que a tabela base na qual o índice é criado. Um índice cluster não particionado e a tabela base sempre residem no mesmo grupo de arquivos. No entanto, você pode fazer o seguinte:
- Crie índices não clusterizados em um grupo de arquivos diferente do grupo de arquivos da tabela base ou do índice clusterizado.
- Particione índices cluster e não cluster para que ocupem vários grupos de arquivos.
- Mova uma tabela de um grupo de arquivos para outro descartando o índice cluster e especificando um novo grupo de arquivos ou esquema de partição na cláusula
MOVE TOda instruçãoDROP INDEXou usando a instruçãoCREATE INDEXcom a cláusulaDROP_EXISTING.
Ao criar o índice não cluster em um grupo de arquivos diferente, você pode obter ganhos de desempenho se os grupos de arquivos estiverem usando unidades físicas diferentes com seus próprios controladores. As informações de índices e de dados podem ser lidas em paralelo pelas várias cabeças de disco. Por exemplo, se Table_A no grupo de arquivos f1 e Index_A no grupo de arquivos f2 estiverem ambos sendo usados pela mesma consulta, podem-se obter ganhos de desempenho porque os dois grupos de arquivos estão sendo completamente usados sem contenção. No entanto, se Table_A for pesquisado pela consulta, mas Index_A não for referenciado, somente o grupo de arquivos f1 será usado. Isso não cria nenhum ganho de desempenho.
Como não é possível prever que tipo de acesso ocorrerá e quando ocorrerá, pode ser uma decisão melhor distribuir suas tabelas e índices em todos os grupos de arquivos. Isso garantirá que todos os discos estejam sendo acessados, pois todos os dados e índices estarão distribuídos igualmente por todos os discos, independentemente da maneira como os dados sejam acessados. Essa também é uma abordagem mais simples para os administradores do sistema.
Partições em vários grupos de arquivos
Você também pode considerar o particionamento de índices clusterizados e não clusterizados baseados em disco em vários grupos de arquivos. Os índices particionados são particionados horizontalmente, ou por linha, com base na função de uma partição. A função da partição define como cada linha é mapeada para um conjunto de partições, com base nos valores de certas colunas, chamadas colunas de particionamento. Um esquema de partição especifica o mapeamento das partições para um conjunto de grupos de arquivos.
O particionamento de um índice pode proporcionar os seguintes benefícios:
Proporcionar sistemas evolutivos que tornam grandes índices mais gerenciáveis. Sistemas OLTP, por exemplo, podem implementar aplicativos que reconhecem partição que tratam de índices grandes.
Fazer as consultas serem executadas de maneira mais rápida e eficiente. Quando as consultas acessam várias partições de um índice, o otimizador de consulta pode processar partições individuais ao mesmo tempo e excluir as partições que não são afetadas pela consulta.
Para saber mais, confira Tabelas particionadas e índices.
Diretrizes de design da ordem de classificação do índice
Ao definir índices, confirme se os dados da coluna de chave de índice deverão ser armazenados em ordem crescente ou decrescente. Ascendente é o padrão e mantém a compatibilidade com versões anteriores do Mecanismo de Banco de Dados. A sintaxe das instruções CREATE INDEX, CREATE TABLE e ALTER TABLE oferece suporte às palavras-chave ASC (crescente) e DESC (decrescente) em colunas individuais de índices e restrições.
A especificação da ordem de armazenamento dos valores de chave em um índice é útil quando as consultas que fazem referência à tabela contêm cláusulas ORDER BY que especificam direcionamentos diferentes para a coluna de chave ou as colunas daquele índice. Nesses casos, o índice pode eliminar a necessidade de um operador SORT no plano de consulta, o que torna a consulta mais eficaz. Por exemplo, os compradores do departamento de compras Bicicletas da Adventure Works precisam avaliar a qualidade dos produtos que compram dos fornecedores. Os compradores estão mais interessados em localizar os produtos enviados por esses fornecedores, e que têm alta taxa de rejeição.
Como demonstrado pela consulta a seguir no banco de dados de exemplo AdventureWorks, recuperar os dados para atender esses critérios requer que a coluna Purchasing.PurchaseOrderDetail na tabela RejectedQty seja classificada em ordem decrescente (do maior para o menor) e que a coluna ProductID seja classificada em ordem crescente (do menor para o maior).
SELECT RejectedQty, ((RejectedQty/OrderQty)*100) AS RejectionRate,
ProductID, DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
GO
O plano de execução a seguir dessa consulta mostra que o otimizador de consultas usou um operador SORT para retornar o conjunto de resultados na ordem especificada pela cláusula ORDER BY.

Se um índice rowstore baseado em disco for criado com colunas de chave correspondentes às da cláusula ORDER BY da consulta, o operador SORT poderá ser eliminado no plano de consulta, e ele se tornará mais eficaz.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
GO
Depois que a consulta for novamente executada, o plano de execução a seguir mostra que o operador SORT foi eliminado e que o índice não clusterizado recentemente criado é utilizado.
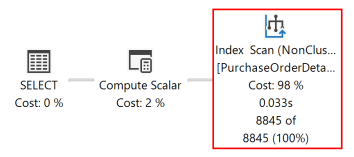
O Mecanismo de Banco de Dados pode se mover com a mesma eficiência em qualquer direção. Um índice definido como (RejectedQty DESC, ProductID ASC) ainda pode ser usado para uma consulta na qual a direção de classificação das colunas na cláusula ORDER BY é invertida. Por exemplo, uma consulta com a cláusula ORDER BY ORDER BY RejectedQty ASC, ProductID DESC pode utilizar o índice.
A ordem de classificação só pode ser especificada para colunas de chave no índice. A exibição de catálogo sys.index_columns e a função INDEXKEY_PROPERTY relatam se a coluna de índice está armazenada em ordem crescente ou decrescente.
Se você estiver acompanhando os exemplos de código no banco de dados de exemplo AdventureWorks, poderá descartar o IX_PurchaseOrderDetail_RejectedQty com o seguinte Transact-SQL:
DROP INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail;
GO
Metadados
Use essas exibições de metadados para ver os atributos de índices. Mais informações arquitetônicas são inseridas em algumas dessas exibições.
Em índices columnstore, todas as colunas são armazenadas nos metadados como colunas incluídas. O índice columnstore não tem colunas de chave.
- sys.column_store_dictionaries
- sys.column_store_row_groups
- sys.column_store_segments
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
- sys.dm_db_index_operational_stats
- sys.dm_db_index_physical_stats
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.hash_indexes
- sys.index_columns
- sys.indexes
- sys.internal_partitions
- sys.memory_optimized_tables_internal_attributes
- sys.partitions
orientações de design de índice clusterizado
Os índices clusterizados classificam e armazenam as linhas de dados da tabela com base em seus valores de chave. Pode haver apenas um índice clusterizado por tabela, porque as próprias linhas de dados podem ser classificadas apenas em uma única ordem. Com poucas exceções, toda tabela deve ter um índice clusterizado definido na coluna, ou colunas, que ofereça o seguinte:
Pode ser usado para consultas frequentemente usadas.
Oferece um alto grau de exclusividade.
Observação
Quando você cria uma restrição
PRIMARY KEY, um índice exclusivo na coluna, ou colunas, é criado automaticamente. Por padrão, esse índice é cluster. Porém, você pode especificar um índice não clusterizado ao criar a restrição.Pode ser usado em consultas de intervalo.
Se o índice clusterizado não for criado com a propriedade UNIQUE, o Mecanismo de Banco de Dados adicionará automaticamente uma coluna de 4 bytes de indicador de exclusividade à tabela. Quando necessário, o Mecanismo de Banco de Dados adiciona automaticamente um valor de indicador de exclusividade a uma linha para tornar cada chave exclusiva. Essa coluna e seus valores são usados internamente e não podem ser vistos ou acessados pelos usuários.
Arquitetura de índice clusterizado
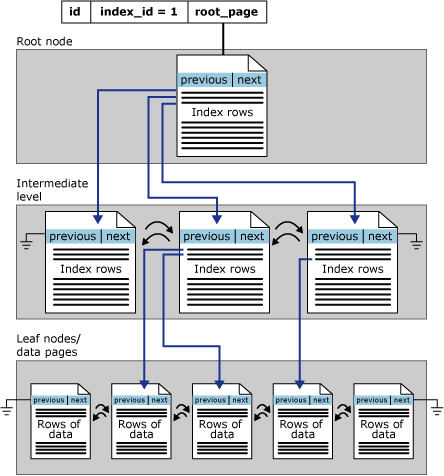
Os índices rowstore são organizados como árvores B+. Cada página em uma árvore B+ de índice é chamada de nó do índice. O nó superior da árvore B+ é chamado de nó raiz. Os nós inferiores no índice são chamados de nós folha. Quaisquer níveis de índice entre os nós raiz e folha são coletivamente conhecidos como níveis intermediários. Em um índice clusterizado, os nós folha contêm as páginas de dados da tabela subjacente. Os nós de nível intermediário e raiz contêm páginas de índice com linhas de índice. Cada linha de índice contém um valor de chave e um ponteiro para uma página de nível de intermediário na árvore B+ ou uma linha de dados no nível folha do índice. As páginas em cada nível do índice são vinculadas em uma lista duplamente vinculada.
Os índices clusterizados têm uma linha em sys.partitions, com index_id = 1 para cada partição usada pelo índice. Por padrão, um índice clusterizado tem um único particionamento. Quando um índice clusterizado tem particionamentos múltiplos, cada particionamento tem uma estrutura de árvore B+ que contém os dados para aquele particionamento específico. Por exemplo, se um índice clusterizado tiver quatro particionamentos, haverá quatro estruturas de árvore B+; uma em cada particionamento.
Dependendo dos tipos de dados no índice clusterizado, cada estrutura de índice clusterizado tem uma ou mais unidades de alocação para armazenar e gerenciar os dados de uma partição específica. No mínimo, cada índice clusterizado tem uma unidade de alocação IN_ROW_DATA por partição. O índice clusterizado também tem uma unidade de alocação LOB_DATA por partição se contiver colunas de objetos grandes (LOB). Ele também tem uma unidade de alocação ROW_OVERFLOW_DATA por partição se contiver colunas de comprimento variável que excedam o limite de tamanho de linha de 8.060 bytes.
As páginas da cadeia de dados e as linhas são classificadas pelo valor da chave de índice clusterizado. Todas as inserções são feitas no ponto em que o valor de chave da linha inserida se ajusta à sequência de classificação entre as linhas existentes.
Esta ilustração mostra a estrutura de um índice clusterizado em um único particionamento.
Considerações de consulta
Antes de criar índices clusterizados, entenda como seus dados são acessados. Considere utilizar um índice clusterizado para consultas que façam o seguinte:
Retornam um intervalo de valores usando os operadores como
BETWEEN,>,>=,<e<=.Depois que a linha com o primeiro valor for encontrada usando o índice cluster, garante-se que as linhas com valores indexados subsequentes estejam fisicamente adjacentes. Por exemplo, se uma consulta recuperar registros entre um intervalo de números de ordem de vendas, um índice clusterizado na coluna
SalesOrderNumberpoderá localizar rapidamente a linha que contém o número de ordem de vendas inicial e em seguida recuperará todas as linhas sucessivas na tabela, até que o último número de ordem de vendas seja alcançado.Retornam grandes conjuntos de resultados.
Usam cláusulas
JOIN. Normalmente, elas são colunas de chave estrangeira.Usam cláusulas
ORDER BYouGROUP BY.Um índice nas colunas especificadas na cláusula
ORDER BYouGROUP BYpode remover a necessidade do Mecanismo de Banco de Dados de classificar os dados, uma vez que as linhas já estão classificadas. Isso melhora o desempenho da consulta.
Considerações sobre colunas
Geralmente, você deve definir a chave de índice clusterizado com o menor número de colunas possível. Considere colunas que tenham um ou mais dos seguintes atributos:
Sejam exclusivas ou contenham muitos valores distintos
Por exemplo, uma ID de funcionário identifica os funcionários de maneira exclusiva. Um índice clusterizado ou uma restrição PRIMARY KEY na coluna
EmployeeIDmelhorará o desempenho de consultas que pesquisam informações de funcionário com base no número de ID do funcionário. Como alternativa, um índice clusterizado poderia ser criado emLastName,FirstName,MiddleNameporque os registros dos funcionários são agrupados e consultados frequentemente dessa maneira e a combinação dessas colunas ainda ofereceria um grau alto de diferença.Dica
Se não for especificado de outra forma, ao criar uma restrição PRIMARY KEY, o Mecanismo de Banco de Dados criará um índice clusterizado para dar suporte a essa restrição.
Embora um uniqueidentifier possa ser usado para impor exclusividade como uma
PRIMARY KEY, ele não é uma chave de clustering eficiente.Se estiver usando um uniqueidentifier como a
PRIMARY KEY, a recomendação é criá-lo como um índice não clusterizado e usar outra coluna, como umIDENTITYpara criar o índice clusterizado.Sejam acessadas sequencialmente
Por exemplo, um ID de produto identifica produtos de maneira exclusiva na tabela
Production.Productno banco de dadosAdventureWorks2022. Consultas nas quais uma pesquisa sequencial seja especificada, tais comoWHERE ProductID BETWEEN 980 and 999, se beneficiariam de um índice clusterizado emProductID. Isso ocorre porque as linhas seriam armazenadas em ordem classificada nessa coluna de chave.Definido como
IDENTITY.Frequentemente usado para classificar os dados recuperados de uma tabela.
Pode ser uma boa ideia agrupar (classificar fisicamente) a tabela nessa coluna, para economizar o custo de uma operação de classificação todas as vezes que a coluna for consultada.
Índices clusterizados não são uma boa opção para os seguintes atributos:
Colunas que sofrem mudanças frequentes
Isso faz com que toda a linha se mova, pois o Mecanismo de Banco de Dados deve manter os valores de dados de uma linha em ordem física. Essa é uma consideração importante em sistemas de processamento de transações de alto volume nos quais os dados sejam normalmente voláteis.
Chaves largas
Chaves largas são uma combinação de várias colunas ou de várias colunas de tamanho grande. Os valores de chave do índice clusterizado são usados por todos os índices não clusterizados como chaves de pesquisa. Todo índice não clusterizado definido na mesma tabela será significativamente maior porque as entradas de índice não clusterizado contêm a chave de cluster e também as colunas de chave definidas para aquele índice não clusterizado.
Diretrizes de design de índices não clusterizados
Um índice rowstore não clusterizado baseado em disco contém os valores de chave do índice e os localizadores de linha que apontam para a localização de armazenamento dos dados da tabela. Você pode criar vários índices não clusterizados em uma tabela ou exibição indexada. Em geral, os índices não clusterizados devem ser projetados para melhorar o desempenho de consultas usadas com frequência que não são cobertas pelo índice clusterizado.
Semelhante à maneira como o índice de um livro é usado, o otimizador de consulta procura um valor de dados pesquisando o índice não clusterizado para encontrar o local do valor de dados na tabela e, depois, recupera os dados diretamente daquele local. Isso faz com que os índices não clusterizados sejam a opção ideal para consultas de correspondência exata, uma vez que o índice contém entradas que descrevem o local preciso na tabela dos valores de dados pesquisados pelas consultas. Por exemplo, para consultar a tabela HumanResources.Employee de todos os funcionários que reportam para um determinado gerente, o otimizador de consulta pode usar o índice não clusterizado IX_Employee_ManagerID, que tem ManagerID como sua coluna de chave. O otimizador de consulta pode localizar rapidamente todas as entradas no índice que correspondem ao ManagerIDespecificado. Cada entrada do índice aponta para a página e a linha exatas na tabela ou índice clusterizado, em que os dados correspondentes podem ser localizados. Depois que o otimizador de consulta localizar todas as entradas no índice, poderá ir diretamente para a página e a linha exatas e recuperar os dados.
Arquitetura de índice não clusterizado
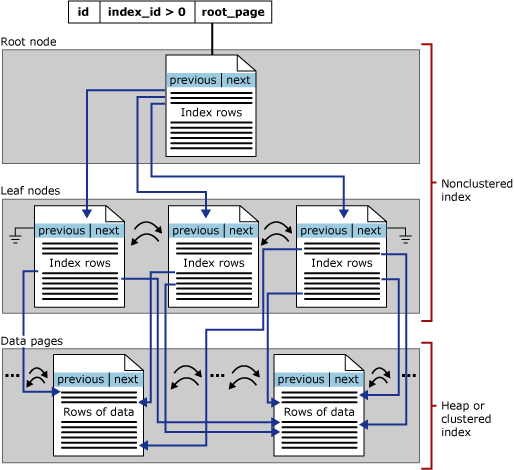
Os índices rowstore não clusterizados baseados em disco têm a mesma estrutura de árvore B+ que os índices clusterizados, com exceção das seguintes diferenças significativas:
As linhas de dados da tabela subjacente não são classificadas e armazenadas em ordem com base em suas chaves não clusterizadas.
O nível de folha de um índice não clusterizado é constituído de páginas de índice, em vez de páginas de dados. As páginas de índice no nível folha de um índice não clusterizado contêm colunas de chave e colunas incluídas.
Os localizadores de linha, em linhas de índice não clusterizado, são um ponteiro para uma linha ou uma chave de índice clusterizado para uma linha, como descrito a seguir.
Se a tabela for um heap, o que significa que ela não tem um índice clusterizado, o localizador de linha é um ponteiro para a linha. O ponteiro é criado a partir do ID (identificador), do número da página e do número da linha na página do arquivo. O ponteiro inteiro é conhecido como RID (Identificação de Linha).
Se a tabela tiver um índice clusterizado, ou o índice estiver em uma exibição indexada, o localizador de linha será a chave de índice clusterizado da linha.
Os localizadores de linha também garantem exclusividade das linhas de índice não clusterizado. A tabela a seguir descreve como o Mecanismo de Banco de Dados adiciona localizadores de linha a índices não clusterizados:
| Tipo de tabela | Tipo de índice não clusterizado | Localizador de linha |
|---|---|---|
| Heap | ||
| Não exclusivo | RID adicionado às colunas de chave | |
| Exclusivo | RID adicionado às colunas incluídas | |
| Índice clusterizado exclusivo | ||
| Não exclusivo | Chaves de índice clusterizados adicionadas às colunas de chave | |
| Exclusivo | Chaves de índice clusterizado adicionadas às colunas incluídas | |
| Índice clusterizado não exclusivo | ||
| Não exclusivo | Chaves de índice clusterizado e indicador de exclusividade (quando presente) adicionados às colunas de chave | |
| Exclusivo | Chaves de índice clusterizado e indicador de exclusividade (quando presente) adicionados às colunas incluídas |
O Mecanismo de Banco de Dados nunca armazena uma determinada coluna duas vezes em um índice não clusterizado. A ordem da chave do índice especificada pelo usuário ao criar um índice não clusterizado é sempre respeitada: todas as colunas do localizador de linhas que precisarem ser adicionadas à chave de um índice não clusterizado serão adicionadas no final da chave, após as colunas especificadas na definição do índice. As colunas de localizador de linha baseadas em chave do índice clusterizado em um índice não clusterizado podem ser usadas pelo otimizador de consulta, independentemente de serem especificadas explicitamente na definição do índice.
Os exemplos a seguir mostram como os localizadores de linha são implementados em índices não clusterizados:
| Índice clusterizado | Definição de índice não clusterizado | Definição de índice não clusterizado com localizadores de linha | Explicação |
|---|---|---|---|
Índice clusterizado exclusivo com colunas de chave (A, B, C) |
Índice não exclusivo não clusterizado com colunas de chave (B, A) e colunas incluídas (E, G) |
Colunas de chave (B, A, C) e colunas incluídas (E, G) |
O índice não clusterizado é não exclusivo, portanto, o localizador de linha precisa estar presente nas chaves de índice. As colunas B e A do localizador de linha já estão presentes, portanto, somente a coluna c é adicionada. A coluna c é adicionada ao final da lista de colunas de chave. |
Índice clusterizado exclusivo com a coluna de chave (A) |
Índice não exclusivo não clusterizado com colunas de chave (B, C) e coluna incluída (A) |
Colunas de chave (B, C, A) |
O índice não clusterizado é não exclusivo, portanto, o localizador de linha é adicionado à chave. A coluna A ainda não foi especificada como uma coluna-chave, portanto, é adicionada ao final da lista de colunas de chave. Agora a coluna A está na chave, portanto, não há necessidade de armazená-la como uma coluna incluída. |
Índice clusterizado exclusivo com uma coluna de chave (A,B) |
Índice não clusterizado exclusivo com uma coluna de chave (C) |
Colunas de chave (C) e colunas incluídas (A,B) |
O índice não clusterizado é exclusivo, portanto, o localizador de linha é adicionado a colunas incluídas. |
Os índices não clusterizados têm uma linha em sys.partitions com index_id > 1 para cada partição usada pelo índice. Por padrão, um índice não clusterizado tem uma única partição. Quando um índice não clusterizado tem várias partições, cada partição tem uma estrutura de árvore B+ que contém linhas de índice para aquela partição específica. Por exemplo, se um índice não clusterizado tiver quatro partições, haverá quatro estruturas de árvore B+, uma em cada partição.
Dependendo dos tipos de dados no índice não clusterizado, cada estrutura de índice não clusterizado tem uma ou mais unidades de alocação para armazenar e gerenciar os dados de uma partição específica. No mínimo, cada índice não clusterizado tem uma unidade de alocação IN_ROW_DATA por partição que armazena as páginas da árvore B+ do índice. O índice não clusterizado também tem uma unidade de alocação LOB_DATA por partição se contiver colunas de objetos grandes (LOB). Além disso, ele tem uma unidade de alocação ROW_OVERFLOW_DATA por partição se contiver colunas de comprimento variável que excedam o limite de tamanho de linha de 8.060 bytes.
A ilustração a seguir mostra a estrutura de um índice não clusterizado em uma única partição.
Considerações do banco de dados
Considere as características do banco de dados ao criar índices não clusterizados.
Os bancos de dados ou as tabelas com baixos requisitos de atualização, mas volumes grandes de dados, podem se beneficiar de muitos índices não clusterizados para aprimorar o desempenho da consulta. Considere a criação de índices filtrados para subconjuntos bem definidos de dados para aprimorar o desempenho da consulta, reduzir os custos de armazenamento de índice e reduzir os custos de manutenção de índice comparados a índices não clusterizados de tabela completa.
Os aplicativos do Sistema de Suporte a Decisões e os bancos de dados que contêm fundamentalmente dados somente leitura podem se beneficiar de vários índices não clusterizados. O otimizador de consulta tem mais índices para escolher e determinar o método de acesso mais rápido, e as características de baixa atualização do banco de dados significam que a manutenção do índice não impedirá o desempenho.
Os aplicativos de Processamento de Transações online (OLTP) e os bancos de dados que contêm tabelas com grandes atualizações devem evitar a superindexação. Adicionalmente, os índices deveriam ser restritos, ou seja, com o mínimo possível de colunas.
Números grandes de índices em uma tabela afetam o desempenho das instruções
INSERT,UPDATE,DELETEeMERGEporque todos os índices precisam ser ajustados adequadamente à medida que os dados são alterados em uma tabela.
Considerações de consulta
Antes de criar índices não clusterizados, é preciso entender como os dados são acessados. Considere usar um índice não clusterizado para consultas com os seguintes atributos:
Usam cláusulas
JOINouGROUP BY.Crie vários índices não clusterizados em colunas envolvidas em operações de junção e de agrupamento e um índice clusterizado em qualquer coluna de chave estrangeira.
Consultas que não retornam grandes conjuntos de resultados.
Crie índices filtrados para abranger consultas que retornam um subconjunto bem definido de linhas de uma tabela grande.
Dica
Normalmente, a cláusula
WHEREda instruçãoCREATE INDEXcorresponde à cláusulaWHEREde uma consulta que está sendo abordada.Contêm colunas frequentemente envolvidas nas condições de pesquisa de uma consulta, como uma cláusula
WHERE, que retorna correspondências exatas.Dica
Considere o custo versus benefício ao adicionar novos índices. Pode ser preferível para consolidar as necessidades de consulta adicionais em um índice existente. Por exemplo, considere a adição de uma ou duas colunas extras de nível de folha a um índice existente, se isso permitir a cobertura de várias consultas críticas, em vez de ter uma cobertura exata de índice por consulta crítica.
Considerações sobre colunas
Considere as colunas que tenham um ou mais destes atributos:
Cubra a consulta.
São obtidos ganhos de desempenho quando o índice contém todas as colunas da consulta. O otimizador de consulta pode localizar todos os valores da coluna dentro do índice; os dados da tabela ou do índice clusterizado não são acessados, resultando em menos operações de E/S em disco. Use índice com colunas incluídas para adicionar colunas de cobertura, em vez de criar uma ampla chave de índice.
Se a tabela tiver um índice clusterizado, a coluna ou as colunas definidas no índice clusterizado serão adicionadas automaticamente a cada índice não clusterizado na tabela. Isso pode produzir uma consulta coberta sem especificar as colunas de índice clusterizado na definição do índice não clusterizado. Por exemplo, se uma tabela tiver um índice clusterizado na coluna
C, um índice não exclusivo e não clusterizado nas colunasBeAterá como valores de chave as colunasB,AeC. Para obter mais informações, visite Arquitetura de índice não clusterizado.Muitos valores distintos, como uma combinação de nome de família e nome, caso um índice clusterizado seja usado em outras colunas.
Se houver muito poucos valores distintos, como apenas
1e0, a maioria das consultas não usará o índice porque uma varredura de tabela geralmente é mais eficiente. Para esse tipo de dados, considere a possibilidade de criar um índice filtrado em um valor distinto que ocorra somente em algumas linhas. Por exemplo, se a maioria dos valores for0, o otimizador de consulta poderá usar um índice filtrado para as linhas de dados que contêm1.
Usar colunas incluídas para estender índices não clusterizados
Você pode estender a funcionalidade de índices não clusterizados acrescentando colunas de não chave ao nível folha do índice não cluster. Ao incluir colunas não chave, você pode criar você índices não clusterizados que abrangem mais consultas. Isto porque as colunas não chave têm os seguintes benefícios:
Elas podem ser tipos de dados não permitidos como colunas de chave de índice.
Elas não são consideradas pelo Mecanismo de Banco de Dados ao calcular o número de colunas de chave de índice ou o tamanho da chave de índice.
Um índice com colunas não chave incluídas pode melhorar o desempenho de consulta significativamente quando todas as colunas na consulta forem incluídas no índice como colunas de chave ou não chave. Ganhos de desempenho são obtidos porque o otimizador de consulta pode localizar todos os valores da coluna dentro do índice; os dados da tabela ou do índice clusterizado não são acessados, resultando em menos operações de E/S em disco.
Observação
Quando um índice contém todas colunas referenciadas pela consulta, ele costuma ser referenciado como abrangendo a consulta.
Enquanto as colunas de chave são armazenadas em todos os níveis do índice, as colunas não chave são armazenadas apenas em nível folha.
Usar colunas incluídas para evitar limites de tamanho
Você pode incluir colunas não chave em um índice não clusterizado para evitar exceder as limitações do tamanho atual do índice, de um máximo de 16 colunas de chave, e um máximo de tamanho chave de índice de 900 bytes. O Mecanismo de Banco de Dados não considera as colunas que não são chaves ao calcular o número de colunas de chave de índice ou o tamanho da chave de índice.
Por exemplo, suponha que você quer indexar as colunas seguintes na tabela Document :
Title NVARCHAR(50)
Revision NCHAR(5)
FileName NVARCHAR(400)
Como os tipos de dados nchar e nvarchar exigem 2 bytes para cada caractere, um índice que contém essas três colunas ultrapassaria em 10 bytes a limitação de tamanho de 900 bytes (455 * 2). Ao usar a cláusula INCLUDE da declaração CREATE INDEX , a chave de índice pode ser definida como uma coluna não chave (Title, Revision) e FileName . Dessa forma, o tamanho da chave do índice seria de 110 bytes (55 * 2), e o índice ainda conteria todas as colunas necessárias. A seguinte declaração cria tal índice.
CREATE INDEX IX_Document_Title
ON Production.Document (Title, Revision)
INCLUDE (FileName);
GO
Se você estiver acompanhando os exemplos de código, poderá soltar esse índice usando esta instrução Transact-SQL:
DROP INDEX IX_Document_Title
ON Production.Document;
GO
Índice com diretrizes das colunas incluídas
Quando você projeta índices não clusterizados com colunas incluídas, considere as seguintes diretrizes:
As colunas não chave estão definidas na cláusula
INCLUDEda instruçãoCREATE INDEX.As colunas não chave só podem ser definidas em índices não clusterizados em tabelas, ou em exibições indexadas.
São permitidos todos os tipos de dados, exceto text, ntexte image.
As colunas computadas que são determinísticas e precisas ou imprecisas podem ser colunas incluídas. Para obter mais informações, consulte Índices de colunas computadas.
Assim como com as colunas de chave, as colunas computadas derivadas dos tipos de dados image, ntexte text podem ser colunas não chave (incluídas), desde que o tipo de dados da coluna computada seja permitido como uma coluna de índice não chave.
Os nomes das colunas não podem ser especificados na lista
INCLUDEe na lista de colunas de chave.Os nomes das colunas não podem ser repetidos na lista
INCLUDE.
Diretrizes do tamanho da coluna
Pelo menos uma coluna de chave deve ser definida. O número de máximo de colunas não chave é de 1.023 colunas. Esse é o número máximo de colunas de tabela menos 1.
As colunas de chave de índice, exceto as não chave, devem seguir as restrições de tamanho de índice de no máximo 16 colunas de chave, e um tamanho total de chave de índice de no máximo 900 bytes.
O tamanho total de todas as colunas não chave está limitado somente pelo tamanho especificado das colunas na cláusula
INCLUDE; por exemplo, as colunas varchar(max) estão limitadas a 2 GB.
Diretrizes de modificação de coluna
Quando você modifica uma coluna de tabela que estava definida como uma coluna incluída, as restrições seguintes se aplicam:
As colunas que não são chaves não podem ser eliminadas da tabela, a menos que o índice seja eliminado primeiro.
As colunas não de chave não podem ser alteradas, exceto para fazer o seguinte:
Alterar a nulidade da coluna
NOT NULLatéNULL.Aumente o tamanho das colunas varchar, nvarcharou varbinary .
Observação
Estas restrições de modificação de coluna também se aplicam para indexar colunas de chave.
Recomendações sobre design
Redesenhe índices não clusterizados com um comprimento de chave de índice, de tal forma que apenas as colunas usadas para buscas e pesquisas sejam colunas de chave. Faça todas as outras colunas que abrangem a consulta colunas não chave incluídas. Dessa forma, você tem todas as colunas necessárias para cobrir a consulta, mas a chave do índice propriamente dita é pequena e eficiente.
Por exemplo, suponha que você quer projetar um índice para abranger a consulta seguinte.
SELECT AddressLine1, AddressLine2, City, StateProvinceID, PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
GO
Para abranger a consulta, cada coluna deve ser definida no índice. Embora você possa definir todas as colunas como colunas de chave, o tamanho chave seria de 334 bytes. Em razão da única coluna usada como critério de pesquisa ser a coluna PostalCode , que tem um comprimento de 30 bytes, um melhor design de índice definiria PostalCode como sendo a coluna de chave e incluiria todas as outras colunas como colunas que não são colunas de chave.
A seguinte declaração cria um índice com colunas incluídas para abranger a consulta.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Para validar se o índice abrange a consulta, crie o índice e exiba o plano de execução estimado.
Se o plano de execução mostrar apenas um operador SELECT e um operador Index Seek para o índice IX_Address_PostalCode, isso significa que a consulta foi abrangida pelo índice.
Você pode soltar o índice com a seguinte instrução:
DROP INDEX IX_Address_PostalCode
ON Person.Address;
GO
Considerações sobre o desempenho
Evite a adição desnecessária de colunas. Adicionar muitas colunas de índice, sejam elas chave ou não, pode gerar as seguintes implicações no desempenho:
Menos linhas de índice cabem em uma página. Isto poderia criar aumentos de E/S e eficiência de cache reduzida.
É necessário mais espaço em disco para armazenar o índice. Em particular, acrescentar os tipos de dados varchar(max), nvarchar(max), varbinary(max)ou xml como colunas de índice não chave pode aumentar significativamente os requisitos de espaço em disco. Isto porque os valores de coluna são copiados no nível folha de índice. Portanto, eles residem no índice e na tabela base.
A manutenção do índice pode aumentar o tempo necessário para executar modificações, inserções, atualizações ou exclusões, para a tabela subjacente ou exibição indexada.
É preciso determinar se os ganhos no desempenho da consulta compensam o efeito no desempenho durante a modificação de dados e nos requisitos adicionais de espaço em disco.
Diretrizes de design de índice exclusivo
Um índice exclusivo garante que a chave de índice não contém nenhum valor duplicado e, portanto, cada linha na tabela é exclusiva de algum modo. Especificar um índice exclusivo só faz sentido quando a exclusividade for uma característica dos próprios dados. Por exemplo, se você quiser garantir que os valores na coluna NationalIDNumber na tabela HumanResources.Employee sejam exclusivos, quando a chave primária for EmployeeID, crie uma restrição UNIQUE na coluna NationalIDNumber. Se o usuário tentar inserir o mesmo valor nessa coluna para mais de um funcionário, será exibida uma mensagem de erro, e o valor duplicado não será inserido.
Com índices exclusivos de multicolunas, o índice garante que cada combinação de valores na chave de índice é exclusivo. Por exemplo, se um índice exclusivo for criado em uma combinação de colunas LastName, FirstNamee MiddleName , duas linhas na tabela não poderão ter a mesma combinação de valores que essas colunas.
Tanto os índices clusterizados quanto os não clusterizados podem ser exclusivos. Se os dados na coluna forem exclusivos, você poderá criar um índice clusterizado exclusivo e vários índices exclusivos não clusterizados na mesma tabela.
Os benefícios dos índices exclusivos incluem o seguinte:
- A integridade de dados das colunas definidas é garantida.
- São fornecidas informações úteis adicionais ao otimizador de consultas.
Criar uma restrição PRIMARY KEY ou UNIQUE automaticamente gera um índice exclusivo nas colunas especificadas. Não há nenhuma diferença significativa entre criar uma restrição UNIQUE e criar um índice exclusivo independente de uma restrição. A validação de dados ocorre da mesma maneira e o otimizador de consulta não diferencia entre um índice exclusivo criado por uma restrição ou criado manualmente. Entretanto, você deverá criar uma restrição UNIQUE ou PRIMARY KEY na coluna quando o objetivo for a integridade de dados. Ao fazer isso, o objetivo do índice se tornará claro.
Considerações
Não é possível criar um índice exclusivo, uma restrição
UNIQUEou uma restriçãoPRIMARY KEYse houver valores de chave duplicados nos dados.Se os dados forem exclusivos e você quiser impor exclusividade, criar um índice exclusivo em vez de um índice não exclusivo, na mesma combinação de colunas, fornecerá informações adicionais para otimizador de consultas que poderá produzir planos de execução mais eficientes. Criar um índice exclusivo (preferivelmente criando uma restrição
UNIQUE) é recomendável nesse caso.Um índice não clusterizado exclusivo pode conter colunas não chave incluídas. Para obter mais informações, consulte Índice com colunas incluídas.
Diretrizes de design de índice filtrado
Um índice filtrado é um índice não clusterizado otimizado, criado especialmente para consultas que fazem seleções a partir de um subconjunto bem-definido de dados. Ele usa um predicado de filtro para indexar uma parte das linhas da tabela. Um índice filtrado bem projetado pode melhorar o desempenho da consulta e reduzir os custos de manutenção e armazenamento do índice em comparação com os índices de tabela completa.
Os índices filtrados podem oferecer as seguintes vantagens com relação aos índices de tabela completa:
Melhor desempenho de consultas e qualidade de plano
Um índice filtrado bem projetado melhora o desempenho das consultas e a qualidade do plano de execução porque é menor do que um índice não clusterizado de tabela completa e possui estatísticas filtradas. As estatísticas filtradas são mais precisas do que as estatísticas de tabela completa, pois abrangem apenas as linhas do índice filtrado.
Redução dos custos de manutenção do índice
A manutenção do índice é feita apenas quando as instruções DML (linguagem de manipulação de dados) afetam os dados do índice. Um índice filtrado reduz os custos de manutenção em comparação com o índice não clusterizado de tabela completa porque é menor e a manutenção é feita somente quando seus dados são afetados. É possível ter um grande número de índices filtrados, especialmente quando eles contêm dados que são raramente afetados. Do mesmo modo, se um índice filtrado tiver apenas dados afetados com frequência, seu tamanho reduzido diminuirá o custo de atualização das estatísticas.
Redução dos custos de armazenamento do índice
A criação de um índice filtrado pode reduzir o armazenamento em disco para índices não clusterizados quando um índice de tabela completa não é necessário. É possível substituir um índice não clusterizado de tabela completa por vários índices filtrados sem aumentar de forma significativa os requisitos de armazenamento.
Os índices filtrados são úteis quando as colunas contêm subconjuntos de dados bem definidos, a que as consultas fazem referência em instruções SELECT. Os exemplos são:
- Colunas esparsas que contêm apenas alguns valores não
NULL. - Colunas heterogêneas que contêm categorias de dados.
- Colunas que contêm intervalos de valores como quantias em dinheiro, hora e datas.
- Partições de tabela definidas pela lógica de comparação simples para obter valores de coluna.
O custo de manutenção reduzido dos índices filtrados é mais perceptível quando o número de linhas do índice é pequeno, se comparado a um índice de tabela completa. Se o índice filtrado incluir a maioria das linhas da tabela, sua manutenção poderá ser mais cara do que a do índice de tabela completa. Nesse caso, você deve usar um índice de tabela completa em vez do índice filtrado.
Os índices filtrados são definidos em uma tabela e são compatíveis apenas com operadores de comparação simples. Se você precisar de uma expressão de filtro que referencie várias tabelas ou que tenha uma lógica complexa, deverá criar uma exibição.
Considerações sobre o design
Para criar índices filtrados eficazes, é importante entender quais consultas o aplicativo usa e como elas se relacionam com os subconjuntos de dados. Alguns exemplos de dados com subconjuntos bem-definidos são as colunas com valores predominantemente NULL, as colunas com categorias de valores heterogêneas e as colunas com intervalos de valores diferentes. As considerações sobre criação a seguir apresentam uma variedade de cenários em que um índice filtrado pode ser vantajoso com relação aos índices de tabela completa.
Dica
A definição do índice columnstore não clusterizado dá suporte ao uso de uma condição filtrada. Para minimizar o impacto no desempenho da adição de um índice columnstore em uma tabela OLTP, use uma condição filtrada para criar um índice columnstore não clusterizado apenas nos dados inativos da sua carga de trabalho operacional.
Índices filtrados de subconjuntos de dados
Quando uma coluna tem apenas alguns valores relevantes para consultas, você pode criar um índice filtrado no subconjunto de valores. Por exemplo, se os valores de uma coluna forem predominantemente NULL e a consulta selecionar apenas valores não NULL, será possível criar um índice filtrado para linhas de dados não NULL. O índice resultante é menor e custa menos para ser mantido do que um índice não clusterizado de tabela completa definido nas mesmas colunas de chave.
Por exemplo, o banco de dados de exemplo AdventureWorks tem uma tabela Production.BillOfMaterials com 2.679 linhas. A coluna EndDate tem apenas 199 linhas que contêm um valor não NULL e outras 2.480 linhas que contêm NULL. O índice filtrado a seguir abrange consultas que retornam as colunas definidas no índice e que selecionam apenas linhas com valor não NULL para EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
GO
O índice filtrado FIBillOfMaterialsWithEndDate é válido para a consulta a seguir. Exiba o plano de execução estimado para determinar se o otimizador de consulta usou o índice filtrado.
SELECT ProductAssemblyID, ComponentID, StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
GO
Para obter mais informações sobre como criar índices filtrados e definir a expressão de predicado do índice filtrado, consulte Criar índices filtrados.
Índices filtrados para dados heterogêneos
Quando a tabela contém linhas de dados heterogêneos, é possível criar um índice filtrado para uma ou mais categorias de dados.
Por exemplo, a cada produto listado na tabela Production.Product é atribuído um ProductSubcategoryIDque, por sua vez, está associado às categorias de produtos Bikes, Components, Clothing ou Accessories. Essas categorias são heterogêneas porque os valores de suas colunas na tabela Production.Product não estão intimamente correlacionados. Por exemplo, as colunas Color, ReorderPoint, ListPrice, Weight, Classe Style têm características exclusivas para cada categoria de produto. Suponha que haja consultas frequentes para acessórios, que têm subcategorias entre 27 e 36, inclusive. É possível aprimorar o desempenho das consultas sobre acessórios criando um índice filtrado nas subcategorias de acessórios, conforme ilustrado no exemplo a seguir.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
Include (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
GO
O índice filtrado FIProductAccessories abrange a seguinte consulta porque os resultados da consulta estão contidos no índice e o plano de consulta não inclui uma pesquisa de tabela base. Por exemplo, a expressão de predicado da consulta ProductSubcategoryID = 33 é um subconjunto do predicado de índice filtrado ProductSubcategoryID >= 27 e ProductSubcategoryID <= 36, as colunas ProductSubcategoryID e ListPrice no predicado de consulta são ambas colunas de chave no índice, e o nome é armazenado no nível folha do índice como uma coluna incluída.
SELECT Name, ProductSubcategoryID, ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33 AND ListPrice > 25.00;
GO
Colunas de chave
Uma prática recomendada é incluir um pequeno número de colunas de chave ou incluídas em uma definição de índice filtrado e inserir apenas as colunas necessárias para o otimizador de consulta escolher o índice filtrado para o plano de execução da consulta. O otimizador de consulta pode escolher um índice filtrado para a consulta, independentemente de ele cobrir ou não a consulta. No entanto, é mais provável que o otimizador de consulta escolha um índice filtrado se ele abranger a consulta.
Em alguns casos, um índice filtrado abrange a consulta sem incluir as colunas na expressão do índice filtrado como colunas de chave ou incluídas na definição do índice filtrado. As diretrizes a seguir explicam quando uma coluna em uma expressão de índice filtrado deve ser uma coluna de chave ou incluída na definição do índice filtrado. Os exemplos se referem ao índice filtrado FIBillOfMaterialsWithEndDate que foi criado anteriormente.
Uma coluna na expressão do índice filtrado não precisa ser uma chave ou uma coluna incluída na definição do índice filtrado se a expressão do índice filtrado for equivalente ao predicado da consulta e a consulta não retornar a coluna na expressão do índice filtrado com os resultados da consulta. Por exemplo, FIBillOfMaterialsWithEndDate abrange a seguinte consulta porque o predicado da consulta é equivalente à expressão do filtro e EndDate não é retornado com os resultados da consulta. FIBillOfMaterialsWithEndDate não precisa de EndDate como uma chave ou coluna incluída na definição do índice filtrado.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Uma coluna na expressão do índice filtrado deve ser uma chave ou uma coluna incluída na definição do índice filtrado se o predicado da consulta usar a coluna em uma comparação que não seja equivalente à expressão do índice filtrado. Por exemplo, FIBillOfMaterialsWithEndDate é válido para a consulta a seguir, porque seleciona um subconjunto de linhas do índice filtrado. No entanto, ele não abrange a consulta a seguir porque EndDate é usado na comparação EndDate > '20040101', que não é equivalente à expressão do índice filtrado. O processador de consultas não pode executar essa consulta sem consultar os valores de EndDate. Portanto, EndDate deve ser uma coluna de chave ou incluída na definição do índice filtrado.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
A coluna na expressão do índice filtrado deverá ser uma coluna de chave ou incluída na definição do índice filtrado se fizer parte do conjunto de resultados da consulta. Por exemplo, FIBillOfMaterialsWithEndDate não abrange a consulta a seguir porque ela retorna a coluna EndDate nos resultados da consulta. Portanto, EndDate deve ser uma coluna de chave ou incluída na definição do índice filtrado.
SELECT ComponentID, StartDate, EndDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
A chave do índice clusterizado da tabela não precisa ser uma chave ou uma coluna incluída na definição do índice filtrado. A chave de índice clusterizado é incluída automaticamente em todos os índices não clusterizados, inclusive índices filtrados.
Para soltar os índices FIBillOfMaterialsWithEndDate e FIProductAccessories, execute as seguintes instruções:
DROP INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials;
GO
DROP INDEX FIProductAccessories
ON Production.Product;
GO
Operadores de conversão de dados no predicado do filtro
Se o operador de comparação especificado na expressão de índice filtrado do índice filtrado resultar em uma conversão de dados implícita ou explícita, ocorrerá um erro se a conversão ocorrer no lado esquerdo de um operador de comparação. Uma solução seria gravar a expressão do índice filtrado com o operador de conversão de dados (CAST ou CONVERT) à direita do operador de comparação.
O exemplo a seguir cria uma tabela com vários tipos de dados.
CREATE TABLE dbo.TestTable (
a INT,
b VARBINARY(4)
);
GO
Na definição de índice filtrado a seguir, a coluna b é convertida implicitamente em um tipo de dados de número inteiro para comparação com a constante 1. Isso gera a mensagem de erro 10611 porque a conversão ocorre à esquerda do operador no predicado filtrado.
CREATE NONCLUSTERED INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = 1;
GO
A solução é converter a constante à direita para o mesmo tipo da coluna b, como mostra o seguinte exemplo:
CREATE INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = CONVERT(VARBINARY(4), 1);
GO
A movimentação da conversão de dados da esquerda para a direita de um operador de comparação pode alterar o significado da conversão. No exemplo anterior, quando o operador CONVERT foi adicionado à direita, a comparação mudou de uma comparação de número inteiro para uma comparação varbinary.
Solte os objetos criados neste exemplo executando a seguinte instrução:
DROP TABLE TestTable;
GO
Arquitetura de índices columnstore
Um índice columnstore é uma tecnologia para armazenamento, recuperação e gerenciamento de dados usando um formato de dados colunar, chamado columnstore. Para saber mais, confira Índices columnstore: Visão geral.
Para obter informações sobre a versão e descobrir o que há de novo, visite Novidades nos Índices columnstore.
Conhecer esses conceitos básicos facilita a compreensão de outros artigos de columnstore que explicam como usá-los de maneira eficaz.
O armazenamento de dados usa compactação de columnstore e rowstore
Em discussões sobre índices columnstore, usamos os termos rowstore e columnstore para enfatizar o formato do armazenamento de dados. Os índices columnstore usam os dois tipos de armazenamento.
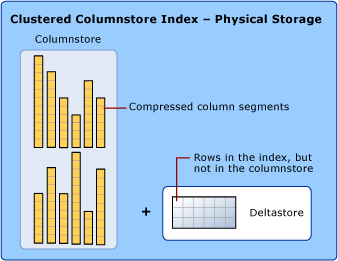
Um columnstore são dados logicamente organizados como uma tabela com linhas e colunas e fisicamente armazenados em um formato de dados com reconhecimento de coluna.
Um índice columnstore armazena fisicamente a maioria dos dados no formato columnstore. No formato columnstore, os dados são compactados e descompactados como colunas. Não há necessidade de descompactar outros valores em cada linha que não sejam solicitados pela consulta. Isso acelera a verificação de uma coluna inteira de uma tabela grande.
Um rowstore são dados logicamente organizados como uma tabela com linhas e colunas e fisicamente armazenados em um formato de dados com reconhecimento de linha. Essa tem sido a maneira tradicional de armazenar dados de tabelas relacionais, como um índice de heap ou árvore B+ clusterizado.
Um índice columnstore também armazena fisicamente algumas linhas em um formato de rowstore, chamado deltastore. O deltastore, também chamado de delta rowgroups, é um local de retenção para linhas que são muito poucas em número para se qualificarem para a compactação em columnstore. Cada rowgroup delta é implementado como um índice de árvore B+ clusterizado.
O deltastore é um local de espera para linhas que são muito poucas para serem compactadas no columnstore. O deltastore armazena as linhas no formato rowstore.
Para obter mais informações sobre os termos e conceitos de columnstore, consulte Índices de columnstore: visão geral.
Operações são executadas em rowgroups e em segmentos de colunas
O índice columnstore agrupa linhas em unidades gerenciáveis. Cada uma dessas unidades é chamada de um rowgroup. Para melhor desempenho, o número de linhas em um rowgroup é grande o suficiente para melhorar as taxas de compactação e pequeno o suficiente para beneficiar-se de operações na memória.
Por exemplo, o índice columnstore executa estas operações em rowgroups:
- Compacta rowgroups no columnstore. A compactação é executada em cada segmento de coluna dentro de um rowgroup.
- Mescla rowgroups durante uma operação de
ALTER INDEX ... REORGANIZE, incluindo a remoção de dados excluídos. - Cria novos rowgroups durante uma operação
ALTER INDEX ... REBUILD. - Relata a integridade e a fragmentação do rowgroup nas DMVs (exibições de gerenciamento dinâmico).
O deltastore é composto de um ou mais rowgroups chamados rowgroups delta. Cada rowgroup delta é um índice de árvore B+ clusterizado que armazena pequenas cargas e inserções em massa até que o rowgroup contenha 1.048.576 linhas; nesse momento, um processo chamado motor de tupla compacta automaticamente o rowgroup fechado em um columnstore.
Para obter mais informações sobre os status de rowgroup, consulte sys.dm_db_column_store_row_group_physical_stats.
Dica
Ter muitos rowgroups pequenos diminui a qualidade do índice columnstore. Um operação de reorganização mesclará rowgroups menores seguindo uma política de limite interno que determina como remover linhas excluídas e combinar os rowgroups compactados. Após uma mesclagem, a qualidade do índice deve melhorar.
No SQL Server 2019 (15.x) e versões posteriores, o motor de tupla recebe a ajuda de uma tarefa de mesclagem em segundo plano que compacta automaticamente os rowgroups delta OPEN menores que existem há algum tempo, conforme determinado por um limite interno, ou mescla os rowgroups COMPRESSED dos quais foi excluído um número grande de linhas.
Cada coluna tem alguns de seus valores em cada rowgroup. Esses valores são chamados de segmentos de coluna. Cada rowgroup contém um segmento de coluna para cada coluna na tabela. Cada coluna tem um segmento de coluna em cada rowgroup.
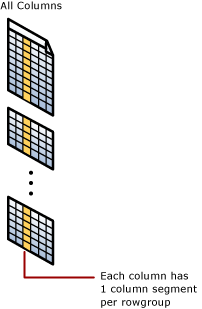
Quando o índice columnstore compacta um rowgroup, ele compacta cada segmento de coluna separadamente. Para descompactar uma coluna inteira, o índice columnstore só precisa descompactar um segmento de coluna de cada rowgroup.
Para obter mais informações sobre os termos e conceitos de columnstore, consulte Índices de columnstore: visão geral.
Cargas e inserções pequenas vão para o deltastore
Um índice columnstore melhora a compactação e o desempenho do columnstore por compactar pelo menos 102.400 linhas por vez no índice columnstore. Para compactar linhas em massa, o índice columnstore acumula pequenas cargas e insere no deltastore. As operações de deltastore são tratadas em segundo plano. Para retornar os resultados corretos da consulta, o índice columnstore clusterizado combina os resultados da consulta de columnstore e deltastore.
As linhas vão para o deltastore quando:
- São inseridas com a instrução
INSERT INTO ... VALUES. - Estão no final de uma carga em massa e em número menor de 102.400.
- São atualizadas. Cada atualização é implementada como uma exclusão e uma inserção.
O deltastore também armazena uma lista de IDs de linhas excluídas que foram marcadas como excluídas, mas ainda não foram excluídas fisicamente do columnstore.
Para obter mais informações sobre os termos e conceitos de columnstore, consulte Índices de columnstore: visão geral.
Quando os rowgroups delta estão cheios, eles são compactados no columnstore
Os índices columnstore clusterizados coletam até 1.048.576 linhas em cada rowgroup delta antes de compactar o rowgroup no columnstore. Isso melhora a compactação do índice columnstore. Quando um rowgroup delta alcança o número máximo de linhas, ele faz a transição do estado OPEN para CLOSED. Um processo em segundo plano chamado de motor de tupla verifica os rowgroups fechados. Se o processo encontrar um rowgroup fechado, ele o compactará e o armazenará no columnstore.
Quando um rowgroup delta é compactado, o grupo de rowgroup delta existente faz a transição para o estado TOMBSTONE para ser removido posteriormente pelo motor de tupla quando não há nenhuma referência a ele, e o novo rowgroup compactado é marcado como COMPRESSED.
Para obter mais informações sobre os status de rowgroup, consulte sys.dm_db_column_store_row_group_physical_stats.
Você pode forçar rowgroups delta para o columnstore usando ALTER INDEX para reccompilar ou reorganizar o índice. Se houver pressão na memória durante a compactação, o índice columnstore poderá reduzir o número de linhas no grupo de linhas compactado.
Para obter mais informações sobre os termos e conceitos de columnstore, consulte Índices de columnstore: visão geral.
Cada partição de tabela tem seus próprios rowgroups e rowgroups delta
O conceito de particionamento é o mesmo em um índice clusterizado, um heap e um índice columnstore. Particionar uma tabela divide a tabela em grupos menores de linhas de acordo com um intervalo de valores de coluna. Geralmente, ele é usado para gerenciar os dados. Por exemplo, você pode criar uma partição para cada ano de dados e usar a alternância de partição para arquivar dados em um armazenamento mais barato. A alternância de partição funciona em índices columnstore e facilita a movimentação de uma partição de dados para outro local.
Os rowgroups sempre são definidos dentro de uma partição de tabela. Quando um índice columnstore é particionado, cada partição tem seus próprios rowgroups compactados e rowgroups delta.
Dica
Considere o uso do particionamento de tabela se houver a necessidade de remover dados do columnstore. A alternância e o truncamento de partições que não sejam mais necessárias é uma estratégia eficiente para excluir dados sem gerar a fragmentação introduzida por ter rowgroups menores.
Cada partição pode ter vários rowgroups delta
Cada partição pode ter mais de um rowgroup delta. Quando o índice columnstore precisar adicionar dados a um rowgroup delta e o rowgroup delta estiver bloqueado, o índice columnstore tentará obter um bloqueio em um rowgroup delta diferente. Se não houver nenhum rowgroup delta disponível, o índice columnstore criará um novo rowgroup delta. Por exemplo, uma tabela com 10 partições poderia facilmente ter 20 ou mais rowgroups delta.
Combinar índices columnstore e rowstore na mesma tabela
Um índice não clusterizado contém uma cópia de parte ou de todas as linhas e colunas na tabela subjacente. O índice é definido como uma ou mais colunas da tabela e tem uma condição opcional que filtra as linhas.
Você pode criar um índice columnstore não clusterizado atualizável em uma tabela rowstore. O índice columnstore armazena uma cópia dos dados, portanto, você precisa de armazenamento extra. No entanto, os dados no índice columnstore serão compactados em um tamanho menor do que a tabela rowstore precisa. Com isso, você pode executar análises no índice columnstore e transações no índice rowstore ao mesmo tempo. O repositório de colunas é atualizado quando dados são alterados na tabela rowstore, assim, ambos os índices trabalham com os mesmos dados.
Você pode ter um ou mais índices rowstore não clusterizados em um índice columnstore. Fazendo isso, você pode executar buscas de tabela eficientes no columnstore subjacente. Outras opções também são disponibilizadas. Por exemplo, você pode impor uma restrição de chave primária usando uma restrição UNIQUE na tabela rowstore. Como um valor não exclusivo não é inserido na tabela rowstore, o Mecanismo de Banco de Dados não pode inserir o valor no columnstore.
Considerações sobre o desempenho
A definição do índice columnstore não clusterizado dá suporte ao uso de uma condição filtrada. Para minimizar o impacto no desempenho da adição de um índice columnstore em uma tabela OLTP, use uma condição filtrada para criar um índice columnstore não clusterizado apenas nos dados inativos da sua carga de trabalho operacional.
Uma tabela na memória pode ter um índice columnstore. Você pode criá-lo quando a tabela for criada ou adicioná-lo mais tarde com ALTER TABLE (Transact-SQL). Antes do SQL Server 2016 (13.x), somente uma tabela baseada em disco podia ter um índice columnstore.
Para obter mais informações, confira Índices columnstore – Desempenho de consultas.
Diretrizes de design
- Uma tabela rowstore pode ter um índice columnstore não clusterizado atualizável. Antes do SQL Server 2014 (12.x), o índice columnstore não clusterizado era somente leitura.
Para obter mais informações, consulte Índices columnstore – Diretrizes de design.
Diretrizes de design de índice de hash
Todas as tabelas com otimização de memória devem ter pelo menos um índice, porque são os índices que conectam as linhas. Em uma tabela com otimização de memória, cada índice também tem otimização de memória. Índices de hash são um dos tipos de índice possíveis em uma tabela com otimização de memória. Para obter mais informações, consulte Índices em tabelas com otimização de memória.
Aplica-se a: SQL Server, Banco de Dados SQL do Azure e Instância Gerenciada de SQL do Azure.
Arquitetura de índice de hash
Um índice de hash consiste em uma matriz de ponteiros e cada elemento da matriz é chamado um bucket de hash.
- Cada bucket tem 8 bytes, que são usados para armazenar o endereço de memória de uma lista de links de entradas de chave.
- Cada entrada é um valor de uma chave de índice, mais o endereço de sua linha correspondente na tabela com otimização de memória subjacente.
- Cada um dos pontos de entrada para a próxima entrada em uma lista de links de entradas, todos encadeados no bucket atual.
O número de buckets deve ser especificado no momento da definição do índice:
- Quanto menor a proporção de buckets para linhas ou valores distintos, maior será a lista média de links de bucket.
- Listas de links curtas executam com mais rapidez do que listas de links longas.
- O número máximo de buckets em índices de hash é de 1.073.741.824.
Dica
Para determinar o endereço BUCKET_COUNT correto para seus dados, consulte Configurar a contagem de buckets do índice de hash.
A função de hash é aplicada às colunas de chave do índice e o resultado da função determina em qual bucket a chave se enquadra. Cada bucket tem um ponteiro para linhas cujos valores de chave de hash são mapeados para o bucket.
A função de hash usada para índices de hash tem as seguintes características:
- O Mecanismo de Banco de Dados tem uma função de hash que é usada para todos os índices de hash.
- A função de hash é determinística. O mesmo valor de chave de entrada sempre é mapeado para o mesmo bucket no índice de hash.
- Várias chaves de índice podem ser mapeadas para o mesmo bucket de hash.
- A função de hash é equilibrada, o que significa que a distribuição de valores de chave do índice em buckets de hash geralmente segue uma distribuição de Poisson ou curva de sino, não uma distribuição linear simples.
- A distribuição de Poisson não é uma distribuição uniforme. Os valores de chave do índice não são distribuídos uniformemente nos buckets de hash.
- Se duas chaves de índice forem mapeadas para o mesmo bucket de hash, haverá uma colisão de hash. Um número grande de colisões de hash pode afetar o desempenho das operações de leitura. Uma meta realista é que 30% dos compartimentos contenham dois valores de chave diferentes.
A interação entre o índice de hash e os buckets é resumida na imagem a seguir.
Configurar a contagem de buckets do índice de hash
O número de buckets do índice de hash é especificado no momento da criação do índice e pode ser alterado com a sintaxe ALTER TABLE...ALTER INDEX REBUILD.
Na maioria dos casos, o ideal é que a contagem de buckets deve estar entre 1 e 2 vezes o número de valores distintos na chave de índice.
Talvez nem sempre seja possível prever quantos valores determinada chave de índice tem ou terá. Normalmente, o desempenho ainda é bom se o valor BUCKET_COUNT estiver dentro de 10 vezes o número real de valores de chave, e superestimar é geralmente melhor do que subestimar.
Um número muito pequeno de buckets tem as seguintes desvantagens:
- Mais colisões de hash de valores de chave distintos.
- Cada valor distinto é forçado a compartilhar o mesmo bucket com um valor distinto diferente.
- O comprimento médio de cadeia por bucket aumenta.
- Quanto maior é a cadeia de bucket, mais lentas são as pesquisas de igualdade no índice.
Um número muito grande de buckets tem as seguintes desvantagens:
- Um número de buckets muito alto pode resultar em mais buckets vazios.
- Buckets vazios afetam o desempenho de verificações de índice completas. Se elas forem executadas regularmente, considere escolher uma contagem de buckets próximo ao número de valores de chave de índice distintos.
- Buckets vazios usam a memória, embora cada bucket use apenas 8 bytes.
Observação
A adição de mais buckets não contribui para reduzir o encadeamento de entradas que compartilham um valor duplicado. A taxa de duplicação de valor é usada para decidir se um hash é o tipo de índice apropriado, não para calcular o número de buckets.
Considerações sobre o desempenho
O desempenho de um índice de hash é:
- Excelente quando o predicado na cláusula
WHEREespecifica um valor exato para cada coluna na chave de índice de hash. Um índice de hash reverterá para um exame de acordo com um predicado de desigualdade. - Fraco quando o predicado na cláusula
WHEREprocura um intervalo de valores na chave de índice. - Ruim quando o predicado na cláusula
WHEREestipula um valor específico para a primeira coluna de uma chave de índice de hash de duas colunas, mas não especifica um valor para as outras colunas da chave.
Dica
O predicado deve incluir todas as colunas na chave de índice de hash. O índice de hash requer uma chave (para submeter a hash) para realizar a busca no índice.
Se uma chave de índice consistir em duas colunas e a cláusula WHERE fornecer apenas a primeira coluna, o Mecanismo de Banco de Dados não terá uma chave completa para fazer o hash. Isso resultará em um plano de consulta de exame de índice.
Se um índice de hash for usado e o número de chaves de índice exclusivo for 100 vezes (ou mais) a contagem de linhas, considere a possibilidade de aumentar o número de buckets para evitar cadeias de linhas grandes ou use um índice não clusterizado.
Considerações sobre a declaração
Um índice de hash apenas pode existir em uma tabela com otimização de memória. Ele não pode existir em uma tabela baseada em disco.
Um índice de hash pode ser declarado como:
UNIQUE, ou nonunique como padrão.NONCLUSTERED, que é o padrão.
A sintaxe de exemplo a seguir cria um índice de hash fora da instrução CREATE TABLE:
ALTER TABLE MyTable_memop
ADD INDEX ix_hash_Column2 UNIQUE
HASH (Column2) WITH (BUCKET_COUNT = 64);
Versões de linha e coleta de lixo
Em uma tabela com otimização de memória, quando uma linha é afetada por um UPDATE, a tabela cria uma versão atualizada da linha. Durante a transação de atualização, é possível que outras sessões consigam ler a versão mais antiga da linha, evitando a lentidão de desempenho associada a um bloqueio de linha.
O índice de hash também poderia ter versões diferentes de suas entradas para acomodar a atualização.
Posteriormente, quando as versões mais antigas não forem mais necessárias, um thread de GC (coleta de lixo) percorrerá os buckets e suas listas de links para limpar as entradas antigas. A execução do thread da GC é melhor se os tamanhos de cadeia de lista de link são curtos. Para obter mais informações, confira Coleta de lixo de OLTP in-memory.
Diretrizes de design de índices não clusterizados com otimização de memória
Índices não clusterizados são um dos tipos de índice possíveis em uma tabela com otimização de memória. Para obter mais informações, consulte Índices em tabelas com otimização de memória.
Aplica-se a: SQL Server, Banco de Dados SQL do Azure e Instância Gerenciada de SQL do Azure.
Arquitetura de índice não clusterizado na memória
Índices não clusterizados na memória são implementados com uma estrutura de dados chamada árvore Bw, originalmente concebida e descrita pela Microsoft Research em 2011. Uma árvore Bw é uma variação livre de bloqueios e travas de uma árvore B. Para obter mais informações, consulte A árvore Bw: uma árvore B para novas plataformas de hardware.
Em um nível alto, a árvore BW pode ser interpretada como um mapa de páginas organizadas por ID de página (PidMap), um recurso para alocar e reutilizar IDs de página (PidAlloc) e um conjunto de páginas vinculadas no mapa de páginas umas às outras. Esses três subcomponentes de alto nível formam a estrutura básica interna de uma árvore Bw.
A estrutura é semelhante a uma árvore B normal, pois cada página tem um conjunto de valores de chave ordenados e existem níveis no índice que apontam para um nível inferior e os níveis folha apontam para uma linha de dados. Entretanto, há várias diferenças.
Assim como os índices de hash, várias linhas de dados podem ser vinculadas (versões). Os ponteiros de página entre os níveis são IDs de página lógicas, que são deslocamentos em uma tabela de Mapeamento de Página, que, por sua vez, tem o endereço físico de cada página.
Não existem atualizações in-loco de páginas de índice. Novas páginas delta são introduzidas para essa finalidade.
- Nenhum bloqueio ou trava é necessário para atualizações de página.
- Páginas de índice não têm um tamanho fixo.
O valor de chave em cada página de nível não-folha representado é o valor mais alto que o filho para o qual ele aponta contém, e cada linha também contém o ID lógico da página. Nas páginas no nível de folha, juntamente com o valor de chave, ele contém o endereço físico da linha de dados.
Pesquisas de pontos são semelhantes às árvores B, exceto pelo fato de que, como as páginas são vinculadas em apenas uma direção, o Mecanismo de Banco de Dados do SQL Server segue ponteiros de página à direita, em que cada página não-folha tem o valor mais alto de seu filho, em vez do valor mais baixo, como em uma árvore B.
Se uma página em nível de folha precisar ser alterada, o Mecanismo de Banco de Dados do SQL Server não modificará a página propriamente dita. Em vez disso, o Mecanismo de Banco de Dados do SQL Server cria um registro delta que descreve a alteração e o anexa à página anterior. Em seguida, ele também atualizará o endereço da tabela de mapa da página anterior para o endereço do registro delta, que agora se torna o endereço físico dessa página.
Há três operações diferentes que podem ser necessárias para gerenciar a estrutura de uma árvore Bw: consolidação, divisão e mesclagem.
Fusão de delta
Uma cadeia grande de registros delta pode acabar prejudicando o desempenho de pesquisas, pois isso pode significar que estamos percorrendo cadeias longas durante a pesquisa por meio de um índice. Se um novo registro delta for adicionado a uma cadeia que já tem 16 elementos, as alterações nos registros delta serão consolidadas na página de índice referenciada e, em seguida, a página será recriada, incluindo as alterações indicadas pelo novo registro delta que dispararam a consolidação. A página recém-recriada tem a mesma ID de página, mas um novo endereço de memória.
Dividir página
Uma página de índice na árvore Bw cresce conforme a necessidade, desde o armazenamento de uma única linha até o armazenamento de um máximo de 8 KB. Depois que a página de índice aumentar para 8 KB, uma nova inserção de uma única linha fará com que a página de índice seja dividida. Para uma página interna, isso significa que não há mais espaço para adicionar outro valor de chave e ponteiro, e para uma página folha, significa que a linha seria muito grande para caber na página depois que todos os registros delta fossem incorporados. As informações estatísticas no cabeçalho da página para uma página de folha controlam a quantidade de espaço necessária para consolidar os registros delta. Essas informações são ajustadas à medida que cada novo registro delta é adicionado.
Uma operação de tempo parcial é feita em duas etapas atômicas. No diagrama a seguir, suponha que uma página-folha force uma divisão porque uma chave com valor 5 está sendo inserida e existe uma página não-folha apontando para o final da página atual em nível de folha (valor de chave 4).

Etapa 1: alocar duas novas páginas P1 e P2 e dividir as linhas da página P1 antiga nessas novas páginas, incluindo a linha recém-inserida. Um novo slot na tabela de mapeamento de página é usado para armazenar o endereço físico da página P2. Essas páginas, P1 e P2, ainda não estão acessíveis a nenhuma operação simultânea. Além disso, o ponteiro lógico de P1 para P2 é definido. Em seguida, em uma etapa atômica, atualize a tabela de mapeamento de página para alterar o ponteiro do antigo P1 para o novo P1.
Etapa 2: a página não folha aponta para P1, mas não há ponteiro direto de uma página não folha para P2. P2 só é acessível por meio de P1. Para criar um ponteiro de uma página não-folha para P2, aloque uma nova página não-folha (página de índice interno), copie todas as linhas da página não-folha antiga e adicione uma nova linha para apontar para P2. Uma vez feito isso, em uma etapa atômica, atualize a tabela de mapeamento de página para alterar o ponteiro da página não-folha antiga para a nova página não-folha.
Mesclar página
Quando uma operação DELETE resulta em uma página com menos de 10% do tamanho máximo de página (atualmente 8 KB) ou com uma única linha, essa página é mesclada com uma página contígua.
Quando uma linha é excluída de uma página, um registro delta para a exclusão é adicionado. Além disso, é feita uma verificação para determinar se a página de índice (página não-folha) se qualifica para mesclagem. Essa verificação verifica se o espaço restante após a exclusão da linha é menor que 10% do tamanho máximo da página. Se ela se qualificar, a Mesclagem será executada em três etapas atômicas.
Na figura abaixo, suponha que uma operação DELETE exclua o valor da chave 10.

Etapa 1: uma página delta que representa o valor de chave 10 (triângulo azul) é criada e seu ponteiro na página não folha Pp1 é definido para a nova página delta. Além disso, uma página especial delta de mesclagem (triângulo verde) é criada e é vinculada para apontar para a página delta. Nesse estágio, as duas páginas (página delta e página delta de mesclagem) não são visíveis para nenhuma transação simultânea. Em uma etapa atômica, o ponteiro para a página de nível de folha P1 na tabela de mapeamento de página é atualizado para apontar para a página de mesclagem delta. Após essa etapa, a entrada do valor de chave 10 em Pp1 agora apontará para a página delta de mesclagem.
Etapa 2: a linha que representa o valor de chave 7 na página não folha Pp1 precisa ser removida e a entrada do valor-chave 10 atualizada para apontar para P1. Para isso, uma nova página não folha Pp2 é alocada e todas as linhas de Pp1 são copiadas, exceto a linha que representa o valor de chave 7; em seguida, a linha do valor de chave 10 é atualizada para apontar para a página P1. Feito isso, em uma etapa atômica, a entrada da tabela de mapeamento de página que aponta para Pp1 é atualizada para apontar para Pp2. Pp1 não é mais acessível.
Etapa 3: as páginas de nível de folha P2 e P1 são mescladas e as páginas delta são removidas. Para fazer isso, uma nova página P3 é alocada e as linhas de P2 e P1 são mescladas e as alterações da página delta são incluídas no novo P3. Em seguida, em uma etapa atômica, a entrada da tabela de mapeamento de página que aponta para a página P1 é atualizada para apontar para a página P3.
Considerações sobre o desempenho
O desempenho de um índice não clusterizado é melhor do que o de índices de hash não clusterizados ao consultar uma tabela com otimização de memória com predicados de desigualdade.
Uma coluna em uma tabela com otimização de memória pode fazer parte de um índice de hash e de um índice não clusterizado.
Quando uma coluna de chave em um índice não clusterizado tem muitos valores duplicados, o desempenho pode diminuir para atualizações, inserções e exclusões. Uma maneira de melhorar o desempenho nessa situação é adicionar uma coluna que tenha melhor seletividade na chave do índice.
Conteúdo relacionado
- CREATE INDEX (Transact-SQL)
- Otimizar a manutenção do índice para melhorar o desempenho da consulta e reduzir o consumo de recursos
- Tabelas e índices particionados
- Índices em tabelas com otimização de memória
- Visão geral: índices columnstore
- Índices em colunas computadas
- Ajustar índices não clusterizados com sugestões de índice ausente