Solução de problemas de tempo limite de conexão intermitente entre réplicas de grupo de disponibilidade
Este artigo ajuda você a diagnosticar tempo limite de conexão intermitente que são relatados entre réplicas de grupo de disponibilidade.
Sintomas e efeitos do grupo de disponibilidade intermitente réplica tempo limite de conexão
Consultar réplicas primárias e secundárias retorna resultados diferentes
Cargas de trabalho somente leitura que consultam réplicas secundárias podem consultar dados obsoletos. Se ocorrerem intervalos intermitentes réplica conexão, as alterações nos dados no banco de dados de réplica primário ainda não serão refletidas no banco de dados secundário ao consultar os mesmos dados. Para obter mais informações, consulte a seção Latência de dados na seção réplica secundária.
Grupo de disponibilidade de relatório de diagnóstico não sincronizado
O Always On dashboard em SQL Server Management Studio pode relatar um grupo de disponibilidade não íntegro que tem réplicas para estar em um estado de não sincronização. Você também pode observar as réplicas de relatório Always On dashboard para estar no estado não sincronizador.

Ao examinar os logs de erro SQL Server dessas réplicas, você poderá observar mensagens como as seguintes que indicam que houve um tempo limite de conexão entre as réplicas no grupo de disponibilidade:
Log de erros do réplica primário
2023-02-15 07:10:55.500 spid43s Always On availability groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Log de erros do réplica secundário
2023-02-15 07:11:03.100 spid31s A connection time-out has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Problemas de conexão intermitente podem afetar a preparação de failover de um réplica secundário
Se você configurar o grupo de disponibilidade para failover automático e o parceiro de failover de commit síncrono for desconectado intermitentemente do principal, o failover automático poderá não ter êxito.
Você pode consultar sys.dm_hadr_database_replia_cluster_states para determinar se o banco de dados do grupo de disponibilidade está pronto para failover nesse momento. Aqui está um exemplo dos resultados se o ponto de extremidade de espelhamento foi interrompido no réplica secundário:
SELECT drcs.database_name, drcs.is_failover_ready, ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ar.replica_id=drcs.replica_id
WHERE ars.role_desc='SECONDARY'

O failover automático pode não colocar o grupo de disponibilidade online na função primária no computador parceiro de failover se o failover coincidir com um tempo limite de conexão réplica.
O que os erros de tempo limite de conexão indicam?
O valor padrão é de 10 segundos para a configuração do grupo de disponibilidade réplica, SESSION_TIMEOUT. Essa configuração está configurada para cada réplica. Ele determina quanto tempo o réplica aguarda para receber uma resposta de seu parceiro réplica antes de relatar um tempo limite de conexão. Se um réplica não receber resposta do parceiro réplica, ele relatará um tempo limite de conexão no log de erros do Microsoft SQL Server e no log do Aplicativo Windows. O réplica que relata o tempo limite imediatamente tenta se reconectar e continuará a tentar a cada cinco segundos.
Normalmente, o tempo limite de conexão é detectado e relatado por apenas um réplica. No entanto, o tempo limite de conexão pode ser relatado por ambas as réplicas ao mesmo tempo. Há diferentes versões dessa mensagem, dependendo se o tempo limite de conexão ocorreu usando uma conexão estabelecida anteriormente ou uma nova conexão:
Message 35206 A connection timeout has occurred on a previously established connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
Message 35201 A connection timeout has occurred while attempting to establish a connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
O parceiro réplica pode não detectar um tempo limite. Se isso acontecer, ele poderá relatar a mensagem 35201 ou 35206. Se isso não ocorrer, ele relatará uma perda de conexão para cada um dos bancos de dados do grupo de disponibilidade:
Message 35267 Always On Availability Groups connection with primary/secondary database terminated for primary/secondary database '<databasename>' on the availability replica '<replicaname>' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Aqui está um exemplo do que SQL Server relata ao log de erros: se você parar o ponto de extremidade de espelhamento no réplica primário, o réplica secundário detectará um tempo limite de conexão e as mensagens 35206 e 35267 são relatadas no log de erros do réplica secundário:
2023-02-15 07:11:03.100 spid31s A connection timeout has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID:[<replicaid>]. This is an informational message only. No user action is required.
Neste exemplo, o réplica primário não detectou nenhum tempo limite de conexão porque ainda podia se comunicar com o secundário e relatou a mensagem 35267 para cada banco de dados do grupo de disponibilidade (neste exemplo, há apenas um banco de dados, 'agdb'):
2023-02-15 07:10:55.500 spid43s Always On Availability Groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Causas de réplica tempo limite de conexão
Problema do aplicativo
SQL Server pode estar ocupado por vários motivos e não atender à conexão de ponto de extremidade de espelhamento no período do grupo SESSION_TIMEOUT de disponibilidade. Isso causa o tempo limite de conexão. Alguns desses motivos são:
SQL Server experimenta 100% de utilização da CPU. Isso significa que SQL Server ou algum outro aplicativo está conduzindo a CPU por segundos de cada vez.
SQL Server experimenta eventos de agendador não produtivos. SQL Server threads são responsáveis por produzir a CPU (agendador) para outros threads para concluir seu trabalho se um thread não render em tempo hábil.
SQL Server experimenta esgotamento de thread de trabalho, problemas de memória fora da memória ou problemas de aplicativo que afetam sua capacidade de atender à conexão de ponto de extremidade de espelhamento.
Problema de rede
Isso requer que você colete logs de rastreamento de rede nas réplicas primárias e secundárias quando o erro é disparado. Para fazer isso, você pode examinar a latência de rede e os pacotes descartados.
Como diagnosticar réplica tempo limite de conexão
Para o problema dos problemas do aplicativo que impedem SQL Server de atender à conexão com o parceiro réplica, esta seção explica como analisar os logs de SQL Server. Essas dicas podem ajudá-lo a identificar a causa raiz das réplica tempo limite de conexão. Esta seção termina com diretrizes mais avançadas sobre como coletar rastreamentos de rede quando o tempo limite de conexão ocorrer para que você possa marcar a rede status.
Avaliar o tempo e o local das réplica tempo limite de conexão
Examine o histórico, a frequência e as tendências dos tempos limite de conexão. Usar as mensagens encontradas no log de erros SQL Server é uma ótima maneira de fazer isso. Onde os tempos limite de conexão são relatados? Eles são consistentemente relatados nas réplica primárias ou secundárias? Quando ocorreram os erros? Eles ocorreram em uma determinada semana do mês, dia da semana ou hora do dia? Outra manutenção agendada ou o processamento em lote correspondem aos horários em que os tempos limite de conexão são observados? Essa avaliação pode ajudá-lo a escopo e correlacionar os tempos limite de conexão para identificar a causa raiz.
Examinar a sessão de evento estendida AlwaysOn_health
A AlwaysOn_health sessão de evento estendida foi aprimorada para incluir o ucs_connection_setup evento, que é disparado quando um réplica está estabelecendo uma conexão com seu parceiro réplica. Isso pode ser útil ao solucionar problemas de tempo limite de conexão.
Observação
O ucs_connection_setup evento estendido foi adicionado às atualizações cumulativas SQL Server mais recentes. Você deve estar executando as atualizações cumulativas mais recentes para observar este evento estendido.
Consulta Always On exibições de gerenciamento distribuído (DMVs)
Você pode consultar Always On DMVs para obter mais informações sobre o estado conectado do réplica. Essa consulta relata apenas o estado conectado e os erros associados ao tempo limite de conexão no momento em que os problemas ocorrem. Se os problemas de conexão forem intermitentes, a consulta poderá não capturar o estado desconectado facilmente.
SELECT ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
O exemplo a seguir mostra um estado desconectado sustentado porque o ponto de extremidade de espelhamento no réplica primário foi interrompido. Ao consultar o réplica primário, o Always On DMV pode relatar as réplicas primárias e todas as secundárias (o ponto de extremidade está desabilitado no réplica primário).

Ao consultar o réplica secundário, o Always On DMVs relata apenas o réplica secundário.

Examine a sessão de evento estendida Always On
Conecte-se a cada réplica usando Pesquisador de Objetos de SQL Server Management Studio (SSMS) e abra os arquivos de
AlwaysOn_healtheventos estendidos.No SSMS, vá para Abrir Arquivos> e selecione Mesclar Arquivos de Eventos Estendidos.
Selecione o botão Adicionar.
Na caixa de diálogo Abrir Arquivo, navegue até os arquivos no diretório \LOG SQL Server.
Pressione Controle e selecione os arquivos cujo nome começa com 'AlwaysOn_healthxxx.xel'.
Selecione Abrir e selecione OK.
Você deve ver uma nova janela com tabbed no SSMS que mostra os eventos AlwaysOn.
A captura de tela a seguir mostra os
AlwaysOn_healthdados do réplica secundário. A primeira caixa descrita mostra a perda de conexão após o ponto de extremidade no réplica primário ser interrompido. A segunda caixa descrita mostra a falha de conexão que ocorre na próxima vez que o réplica secundário tentar se conectar ao réplica primário.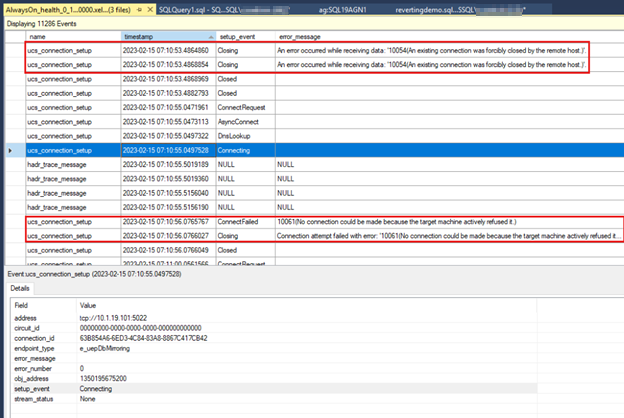

Verifique se eventos não produtivos estão causando tempo limite de conexão
Um dos motivos mais comuns para que um réplica de disponibilidade não possa atender ao parceiro réplica conexão é um agendador que não está rendendo. Para obter mais informações sobre agendadores não produtivos, confira Solução de problemas SQL Server Agendamento e Rendimento.
SQL Server rastreia eventos de agendador não produtivos que são tão curtos quanto 5 a 10 segundos. Ele relata esses eventos no ponto de TrackingNonYieldingScheduler dados na saída do sp_server_diagnostics query_processing componente.
Para marcar para eventos não produtivos que possam causar réplica tempo limite de conexão, siga estas etapas:
Crie um trabalho do SQL Agent que registra a
sp_server_diagnosticscada cinco segundos.Agende esse trabalho no servidor que não relata o tempo limite de conexão. Ou seja, se o Server A réplica relatar o tempo limite de conexão réplica em seu log de erros, configure o trabalho do SQL Agent no réplica de parceiro, Servidor B. Como alternativa, se você estiver vendo o tempo limite de conexão em ambas as réplicas, crie o trabalho em ambas as réplicas.
Execute o arquivo em lote a seguir para criar um trabalho que é executado
sp_server_diagnosticsa cada cinco segundos, acrescenta a saída a um arquivo de texto e, em seguida, inicia o trabalho. O comando no exemplo a seguir ésp_server_diagnostics 5executado a cada cinco segundos. Portanto, não há necessidade de agendar esse trabalho para ser executado a cada cinco segundos, apenas iniciar o trabalho e ele será executado até ser interrompido, a cada cinco segundos:USE [msdb] GO DECLARE @ReturnCode INT SELECT @ReturnCode = 0 DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Run sp_server_diagnostics', @owner_login_name=N'sa', @job_id = @jobId OUTPUT /****** Object: Step [Run SP_SERVER_DIAGNOSTICS] Script Date: 2/15/2023 4:20:41 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Run SP_SERVER_DIAGNOSTICS', @subsystem=N'TSQL', @command=N'sp_server_diagnostics 5', @database_name=N'master', @output_file_name=N'D:\cases\2423\sp_server_diagnostics_output.out', @flags=2 EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' EXEC sp_start_job 'Run sp_server_diagnostics'Observação
Nesses comandos, altere
@output_file_namepara um caminho válido e forneça um nome de arquivo.
Analisar os resultados
Quando um tempo limite de conexão for relatado, observe o carimbo de data/hora do evento de tempo limite mostrado no log de erros SQL Server. Para as réplicas no exemplo a seguir, SQL19AGN1 estava relatando as réplica tempo limite de conexão. Portanto, um trabalho do SQL Agent foi criado no SQL19AGN2, o parceiro réplica. Em seguida, um tempo limite de conexão foi relatado no log de SQL19AGN1 erros às 07:24:31.

Em seguida, a saída do trabalho do SQL Agent que executa sp_server_diagnostics é verificada na hora relatada, examinando especificamente o TrackingNonYieldingScheduler ponto de dados na saída do query_processing componente. A saída relata que um agendador não produtivo foi rastreado (como um valor hexadecimal não zero) no servidor SQL19AGN2 (às 07:24:33) na época em que o tempo limite de conexão réplica foi relatado em SQL19AGN1 (às 07:24:31).
Observação
A saída a seguir sp_server_diagnostics é concatenada para mostrar os create_time resultados (carimbo de data/ query_processing TrackingNonYieldingScheduler hora).

Investigar um evento de agendador não produtivo
Se você verificou nas etapas de diagnóstico anteriores que um evento não produtivo causou o tempo limite de conexão réplica:
Identifique as cargas de trabalho que estão em execução no SQL Server no momento em que os eventos não produtivos são executados.
Semelhante ao réplica tempo limite de conexão, procure tendências nesses eventos durante o mês, dia ou semana em que eles ocorrem.
Colete o rastreamento do monitor de desempenho no sistema no qual o evento não produtivo foi detectado.
Colete contadores de desempenho de chave para recursos do sistema, incluindo Processador::% Tempo do Processador, Memória::MBytes Disponíveis, Disco Lógico::Comprimento da Fila de Disco do Avg e Disco Lógico::Disco Avg s/Transferência.
Se for necessário, abra um SQL Server incidente de suporte para obter mais assistência para encontrar a causa raiz desses eventos que não produzem. Compartilhe os logs coletados para análise posterior.
Coleta avançada de dados: coletar rastreamento de rede durante o tempo limite de conexão
Se o diagnóstico anterior do aplicativo SQL Server não tiver gerado uma causa raiz, você deverá marcar a rede. A análise bem-sucedida da rede requer que você colete um rastreamento de rede que abrange o tempo limite da conexão.
O procedimento a seguir inicia um rastreamento de rede do Windows netsh nas réplicas nas quais os tempos limite de conexão são relatados nos logs de erro SQL Server. Uma tarefa de evento agendada pelo Windows é disparada quando um dos erros de conexão SQL Server é registrado no log do aplicativo. A tarefa agendada executa um comando para interromper o rastreamento de netsh rede para que os dados de rastreamento de rede chave não sejam substituídos. Essas etapas também assumem um caminho de *F:* para o lote e os logs de rastreamento. Ajuste esse caminho ao seu ambiente.
Inicie um rastreamento de rede, conforme mostrado no snippet de código a seguir, nas duas réplicas nas quais ocorrem os tempos limite de conexão:
netsh trace start capture=yes persistent=yes overwrite=yes maxsize=500 tracefile=f:\trace.etlCrie tarefas agendadas pelo Windows que interrompem o
netshrastreamento nos eventos 35206 ou 35267. Você pode criar essas tarefas em uma linha de comando administrativa:schtasks /Create /tn Event35206Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35206] /f /RL HIGHEST schtasks /Create /tn Event35267Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35267] /f /RL HIGHESTDepois que o evento ocorrer e os rastreamentos de rede forem interrompidos e capturados, você poderá excluir as
ONEVENTtarefas:PS C:\Users\sqladmin> Schtasks /Delete /tn Event35206Task /F PS C:\Users\sqladmin> Schtasks /Delete /tn Event35267Task /F
A análise do rastreamento de rede está fora do escopo dessa solução de problemas. Se você não conseguir interpretar o rastreamento de rede, entre em contato com a equipe de suporte do Microsoft SQL Server e forneça o rastreamento junto com outros arquivos de log solicitados para análise de causa raiz.
O que mais posso fazer para atenuar o tempo limite de conexão?
O grupo de disponibilidade padrão, SESSION_TIMEOUT, está configurado por 10 segundos. Você pode ser capaz de reduzir o tempo limite de conexão ajustando o grupo de disponibilidade réplica SESSION_TIMEOUT propriedade. Essa configuração é por réplica. Ajuste-o para a réplica secundária primária e cada réplica secundária afetada. Aqui está um exemplo da sintaxe. O valor padrão SESSION_TIMEOUT é 10. Portanto, você pode usar 15 como o próximo valor.
ALTER AVAILABILITY GROUP ag
MODIFY REPLICA ON 'SQL19AGN1' WITH (SESSION_TIMEOUT = 15);