Solução de problemas do log enviar filas em um grupo de disponibilidade Always On
Este artigo fornece resoluções para problemas relacionados à fila de envio de logs.
O que é o envio de log na fila?
As alterações feitas em um banco de dados de grupo de disponibilidade no réplica primário (como INSERT, UPDATEe DELETE) são gravadas no log de transações e enviadas para as réplicas secundárias do grupo de disponibilidade. A Fila de Envio de Log define o número de registros de log nos arquivos de log do banco de dados primário que não foram enviados para as réplicas secundárias.
Sintomas e efeito da fila de envio de log
A fila de envio de log armazena todos os dados vulneráveis
Se o réplica primário for perdido em um desastre repentino e você falhar na réplica secundária em que essas alterações ainda não chegaram, essas alterações não aparecerão na nova cópia réplica primária do banco de dados. Isso exclui todas as alterações armazenadas quando os backups completos do banco de dados e do log são executados.
O crescimento da fila de envio de logs causa o crescimento crescente do arquivo de log de transações
Para um banco de dados definido em um grupo de disponibilidade, o Microsoft SQL Server deve manter no réplica primário todas as transações no log de transações que ainda não foram entregues às réplicas secundárias. A fila de envio de log representa a quantidade de alterações registradas no réplica primário que não podem ser truncadas durante eventos normais de truncamento de log (por exemplo, durante um backup de log de banco de dados). Uma fila de envio de log grande e crescente pode esgotar o espaço livre na unidade que hospeda o arquivo de log de banco de dados ou pode exceder o tamanho máximo do arquivo de log de transação configurado. Para obter mais informações, consulte Erro 9002 quando o log de transações for grande.
Vários recursos de diagnóstico relatam o log de envio de filas de grupos de disponibilidade
O Always On dashboard nos relatórios de SQL Server Management Studio no log enviar filas. Pode relatar que o grupo de disponibilidade não é íntegro.
Como marcar para a fila de envio de logs
A fila de envio de log é uma medida por banco de dados. Você pode marcar esse valor usando o Always On dashboard no réplica primário ou usando o sys.dm_hadr_database_replica_states Modos de Exibição de Gerenciamento Dinâmico (DMV) no réplica primário ou secundário. Monitor de Desempenho contadores são usados para marcar para enviar filas de envio de log no réplica secundário.
As próximas seções fornecem métodos para monitorar ativamente a fila de envio de log de banco de dados do grupo de disponibilidade.
Consulta sys.dm_hadr_database_replica_state
O sys.dm_hadr_database_replica_states DMV relata uma linha para cada banco de dados do grupo de disponibilidade. Uma coluna nesse relatório é log_send_queue_size. Esse valor é o tamanho da fila de envio de log em quilobytes (KB). Você pode configurar uma consulta, como a consulta a seguir, para monitorar qualquer tendência no tamanho da fila de envio de log. A consulta é executada no réplica primário. Ele usa o is_local=0 predicado para relatar os dados do réplica secundário, em que log_send_queue_size e log_send_rate são relevantes.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Veja como é a saída.

Examine a fila de envio de log no Always On dashboard
Para examinar a fila de envio de logs, siga estas etapas:
Abra o Always On dashboard no SSMS (SQL Server Management Studio) clicando com o botão direito do mouse em um grupo de disponibilidade no SSMS Pesquisador de Objetos.
Selecione Mostrar Painel.
Os bancos de dados do grupo de disponibilidade são listados por último e há alguns dados relatados nos bancos de dados. Embora o KB (Tamanho da Fila de Envio de Log) e a Taxa de Envio de Log (KB/s) não estejam listados por padrão, você pode adicioná-los a essa exibição, conforme mostrado na captura de tela na próxima etapa.
Para adicionar essas colunas, clique com o botão direito do mouse no cabeçalho da coluna de banco de dados do grupo de disponibilidade e selecione na lista de colunas disponíveis.
Para adicionar o Tamanho da Fila de Envio de Log, clique com o botão direito do mouse no cabeçalho mostrado como realçado em vermelho na captura de tela a seguir.

Por padrão, o Always On dashboard atualiza automaticamente esses dados a cada 60 segundos.



Examine a Fila de Envio de Log no Monitor de Desempenho
A fila de envio de log é específica para cada banco de dados de réplica secundário. Portanto, para examinar a fila de envio de log de um banco de dados de grupo de disponibilidade, siga estas etapas:
Abra Monitor de Desempenho no réplica secundário.
Selecione o botão Adicionar (contador).
Em Contadores disponíveis, selecione os contadores SQLServer:Database Replica e Log Send Queue .
Na caixa de lista Instância, selecione o banco de dados do grupo de disponibilidade que você deseja marcar para a fila de envio de log.
Selecione Adicionar e OK.
Veja como pode ser a crescente fila de envio de logs.


Interpretando os valores de fila de envio de log
Esta seção explica como interpretar os valores do tamanho da fila de envio de log.
Quando o envio de logs é ruim? Quanta fila de envio de log deve ser tolerada?
Você pode supor que, se a fila de envio de log estiver relatando um valor de 0, isso significa que nenhuma fila de envio de log está ocorrendo no momento desse relatório. No entanto, quando o ambiente de produção estiver ocupado, você deverá observar que a fila de envio de logs frequentemente relata um valor diferente de zero, mesmo em um ambiente AlwaysOn saudável. Durante a produção típica, você deve esperar observar que esse valor flutua entre 0 e um valor não zero.
Se você observar o aumento da fila de envio de logs ao longo do tempo, será necessária uma investigação adicional. Essa atividade extra indica que algo mudou. Se você observar um crescimento repentino na fila de envio de logs, as seguintes medidas serão úteis para solução de problemas:
- Taxa de envio de log (KB/s) (AlwaysOn dashboard)
- sys.dm_hadr_database_replica_states (DMV)
- Réplica de banco de dados::Transações espelhadas/s (Monitor de Desempenho)
Obter taxas de linha de base para taxa de envio de log e transações espelhadas/s
Durante o desempenho saudável do AlwaysOn, monitore a taxa de envio de log e os valores de transações/s espelhados para seus bancos de dados de grupo de disponibilidade ocupados. Como eles se parecem durante horários comerciais normalmente ocupados? Como eles se parecem durante períodos de manutenção, quando transações grandes geram maior taxa de transferência de transação no sistema? Você pode comparar esses valores ao observar o crescimento da fila de envio de logs para ajudar a determinar o que foi alterado. A carga de trabalho pode ser maior do que o normal. Se a taxa de envio de log for menor do que o normal, uma investigação adicional poderá ser necessária para determinar o motivo.
Os volumes de carga de trabalho importam
Quando você tem cargas de trabalho grandes (como uma instrução UPDATE contra 1 milhão de linhas, uma recompilação de índice em uma tabela de 1 terabyte ou até mesmo um lote ETL que está inserindo milhões de linhas), você deve esperar ver algum log enviar crescimento de fila, imediatamente ou ao longo do tempo. Isso é esperado quando um grande número de alterações é feita repentinamente no banco de dados do grupo de disponibilidade.
Como diagnosticar filas de envio de log
Depois de identificar a fila de envio de log para um banco de dados de grupo de disponibilidade específico, você deve marcar para várias causas raiz possíveis diferentes do problema, conforme discutido nas seções a seguir.
Importante
Para uma saída significativa do tipo de espera, marcar para um aumento na fila de envio de log usando um dos métodos descritos nas seções anteriores ao monitorar as seguintes condições.
O sistema está muito ocupado
Verifique se a carga de trabalho no réplica primário está sobrecarregando as CPUs do sistema. Se você vir um aumento na fila de envio de logs, consulte o sys.dm_os_schedulers DMV e monitore para high runnable_tasks_count. Essa contagem indica tarefas pendentes que foram executadas naquele momento.
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
A tabela a seguir é uma amostra de resultados. Um aumento no runnable_tasks_count valor indica que um grande número de tarefas está aguardando tempo de CPU.
| scheduler_address | scheduler_id | cpu_id | status | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | VISÍVEL OFFLINE | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | VISIBLE ONLINE | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | VISIBLE ONLINE | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | VISIBLE ONLINE | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | VISIBLE ONLINE | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | VISIBLE ONLINE | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | VISIBLE ONLINE | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | VISÍVEL | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | VISIBLE ONLINE | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | VISIBLE ONLINE | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | VISIBLE ONLINE | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | VISIBLE ONLINE | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | VISIBLE ONLINE | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | VISIBLE ONLINE | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | VISIBLE ONLINE | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | VISIBLE ONLINE | 104 | 16 | 116 | 103 |
Solução: se você detectar alto runnable_task_count, reduza a carga de trabalho no sistema ou aumente o número de CPUs disponíveis para o sistema.
Latência de rede
Essa condição é especialmente comum se o réplica secundário for fisicamente remoto do réplica primário. Grupos de disponibilidade de vários sites permitem que os clientes implantem cópias de dados comerciais em vários sites para recuperação de desastres e relatórios. Isso disponibiliza alterações quase em tempo real para as cópias dos dados de produção em locais remotos.
Se um réplica secundário estiver hospedado longe do réplica primário, a fila de envio de logs poderá ser causada pela latência de rede e pela incapacidade de enviar alterações para o secundário remoto tão rápido quanto está sendo produzido no banco de dados réplica primário.
Importante
SQL Server usa uma única conexão para sincronizar as alterações das réplicas primárias para as secundárias. Portanto, se um réplica secundário for remoto, a largura do pipe não afetará a quantidade de dados que SQL Server pode enviar. Em vez disso, essa quantidade depende mais da latência de rede no pipe (velocidade de conexão).
Teste para latência de rede
Verificar se as configurações de controle de fluxo contribuem para a latência de rede
Os grupos de disponibilidade do Microsoft SQL Server usam portões de controle de fluxo para evitar o consumo excessivo de recursos de rede, memória e outros recursos em todas as réplicas de disponibilidade. Esses portões de controle de fluxo não afetam o estado de integridade de sincronização das réplicas de disponibilidade. No entanto, eles podem afetar o desempenho geral dos bancos de dados de disponibilidade, incluindo o RPO.
Versões posteriores do SQL Server alterar os limites nos quais o controle de fluxo é inserido. Isso pode ajudar a aliviar o efeito que o controle de fluxo tem sobre sintomas como o envio de logs na fila. Para obter mais informações sobre o controle de fluxo e o histórico de alterações nos limites de controle de fluxo, confira Portões de controle de fluxo.
Você pode monitorar o controle de fluxo usando Monitor de Desempenho para capturar dados no réplica primário. Para monitorar o controle de fluxo de banco de dados, adicione contadores SQLServer:Réplica de Banco de Dados e selecione os contadores Atraso do Controle de Fluxo de Banco de Dados e Controles de Fluxo de Banco de Dados/s . Na caixa de diálogo Instância, selecione o banco de dados do grupo de disponibilidade que você deseja marcar para o controle de fluxo de banco de dados. Para detectar e monitorar a disponibilidade réplica controle de fluxo, adicione contadores SQLServer:Availability Replica e selecione os contadores Tempo de Controle de Fluxo (ms/s) e Controle de Fluxo/s.
Verificar se o congestionamento do Windows Restart contribui para a latência de rede
Problemas de desempenho de rede que causam filas de envio de log podem ser disparados com a configuração TCP de reinicialização do Windows de congestionamento definida como True. Essa foi a configuração padrão no Windows Server 2016. Verifique se a reinicialização da janela de congestionamento está definida como False em servidores Windows que hospedam réplicas de grupo de disponibilidade nas quais a fila de envio de logs é observada.
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart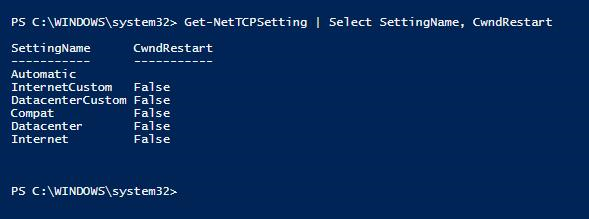
Para obter mais informações sobre como definir a propriedade TCP Congestion Windows Restart como False, consulte Set-NetTCPSetting (NetTCPIP).
Consulte Também Monitorar o desempenho de grupos de disponibilidade Always On para obter informações sobre o processo de sincronização. Este artigo também mostra como calcular algumas das principais métricas e fornece links para alguns dos cenários comuns de solução de problemas de desempenho.
Usar ping para obter um exemplo de latência
Em uma linha de comando no nó1 (réplica primário), ping node2 (réplica secundário):
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101msTestar a taxa de transferência de rede do primário para o secundário usando ferramenta independente
Use uma ferramenta como nTttcp para detectar independentemente a taxa de transferência de rede entre as réplicas primária e secundária usando uma única conexão. A latência de rede é uma causa comum para a fila de envio de logs. As etapas a seguir mostram como usar uma ferramenta independente, como o NTttcp, para medir a taxa de transferência de rede.
Importante
SQL Server envia alterações do réplica primário para o réplica secundário usando uma única conexão. Na seção a seguir, configuramos e executamos o NTttcp para usar uma única conexão (da mesma maneira que SQL Server) para comparar a taxa de transferência com precisão.
Você pode baixar o NTttcp do Github – microsoft/ntttcp.
Para executar o NTttcp, siga estas etapas:
Baixe e copie a ferramenta para os servidores primários e secundários baseados em SQL Server.
No servidor de réplica secundário, abra uma janela de prompt de comando elevada, altere o diretório para a pasta de ferramenta NTttcp e execute o seguinte comando:
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60Observação
Neste comando,
<secondaryipaddress>é um espaço reservado para o endereço IP real do servidor de réplica secundário.No servidor de réplica primário, abra uma janela de prompt de comando elevada, altere o diretório para a pasta de ferramenta NTttcp e execute o seguinte comando especificando novamente o endereço IP real do servidor de réplica secundário:
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60As capturas de tela a seguir mostram o NTttcp em execução nas réplicas secundárias e primárias. Devido à latência de rede, a ferramenta pode enviar apenas 739 KB/s de dados. Isso é o que você pode esperar que SQL Server seja capaz de enviar.
NTttcp na Réplica Secundária
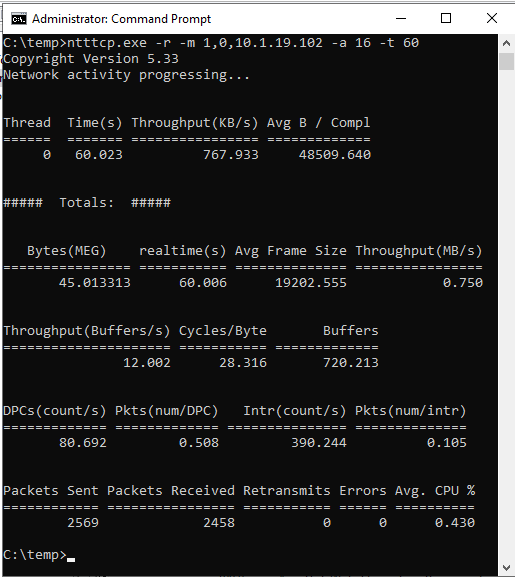
NTttcp na Réplica Primária

Examinar contadores de Monitor de Desempenho
Verifique quais relatórios NTttcp. Uma transação grande é executada em SQL Server no réplica primário. Depois de iniciar Monitor de Desempenho no réplica primário, adicione o contador Interface de Rede::Bytes Enviado/s. Este contador confirma que o réplica primário pode enviar cerca de 777 KB/s de dados. Isso é semelhante ao valor de 739 KB/s relatado pelo teste NTttcp.

Também é útil comparar o valor SQL Server::D atabases::Log Bytes Flushed/s no réplica primário com SQL Server::D atabase Replica::Log Bytes Recebidos/s para o mesmo banco de dados no réplica secundário. Em média, observamos ~20 MB/s de alterações criadas no banco de dados "agdb". No entanto, o réplica secundário está recebendo, em média, apenas 5,4 MB de alterações. Isso fará com que o log envie filas no réplica primário de alterações pendentes no log de transações de banco de dados que ainda não foram enviadas para o réplica secundário.
Bytes de log de réplica primárias liberados/s para o banco de dados "agdb"

Bytes de log de réplica secundários recebidos/s para o agdb de banco de dados
