Planejamento de capacidade para o Active Directory Domain Services
Este artigo fornece recomendações para o planejamento de capacidade dos Serviços de Domínio do Active Directory (AD DS).
Metas de planejamento da capacidade
O planejamento de capacidade não é o mesmo que solucionar problemas de incidentes de desempenho. As metas de planejamento da capacidade são:
- Implemente e opere um ambiente corretamente.
- Minimize o tempo gasto na solução de problemas de desempenho.
No planejamento de capacidade, uma organização pode ter uma meta de linha de base de 40% de utilização do processador durante os períodos de pico para atender aos requisitos de desempenho do cliente e dar tempo suficiente para atualizar o hardware no datacenter. Enquanto isso, o cliente definiu seu limite de alerta de monitoramento para problemas de desempenho em 90% em um intervalo de cinco minutos.
Quando você excede continuamente o limite de gerenciamento de capacidade, adicionar mais processadores ou processadores mais rápidos para aumentar a capacidade ou dimensionar o serviço em vários servidores seria uma solução. Os limites de alerta de desempenho permitem que você saiba quando precisa tomar medidas imediatas quando problemas de desempenho afetam negativamente a experiência do cliente. Por outro lado, uma solução de problemas estaria mais preocupada em lidar com eventos únicos.
O gerenciamento de capacidade é como as medidas preventivas que você tomaria para evitar um acidente de carro, como direção defensiva, garantir que os freios estejam funcionando corretamente e assim por diante. A solução de problemas de desempenho é mais parecida com um cenário em que a polícia, o corpo de bombeiros e os profissionais médicos de emergência respondem a um acidente.
Nos últimos anos, as diretrizes de planejamento da capacidade para sistemas de expansão mudaram drasticamente. As seguintes alterações nas arquiteturas do sistema desafiam suposições fundamentais sobre o design e o dimensionamento de um serviço:
- Plataformas de servidor de 64 bits
- Virtualização
- Maior atenção ao consumo de energia
- Armazenamento SSD
- Cenários de nuvem
A abordagem do planejamento de capacidade também está mudando de exercícios de planejamento baseados em servidor para exercícios baseados em serviços. Os Serviços de Domínio Active Directory (AD DS), um serviço distribuído maduro que muitos produtos da Microsoft e de terceiros usam como back-end, agora é um dos produtos mais essenciais para garantir que seus outros aplicativos tenham a capacidade necessária para serem executados.
Informações importantes a serem consideradas antes de começar a planejar
Para tirar o máximo proveito deste artigo, você deve fazer o seguinte:
- Certifique-se de ter lido e entendido as Diretrizes de ajuste de desempenho para Windows Server 2012 R2.
- Entenda que a plataforma Windows Server é uma arquitetura baseada em x64. Além disso, você deve entender que as diretrizes deste artigo ainda se aplicam mesmo que seu ambiente do Active Directory esteja instalado no Windows Server 2003 x86 (agora após o fim do ciclo de vida de suporte) e tenha uma DIT (árvore de informações de diretório) menor que 1,5 GB e possa ser facilmente armazenada na memória.
- Entenda que o planejamento de capacidade é um processo contínuo, portanto, você deve revisar regularmente o quão bem o ambiente que você constrói está atendendo às suas expectativas.
- Entenda que a otimização ocorre em vários ciclos de vida de hardware à medida que os custos de hardware mudam. Por exemplo, se a memória ficar mais barata, o custo por núcleo diminuirá ou o preço de diferentes opções de armazenamento mudará.
- Planeje-se para o período de pico diário. Recomendamos que você faça seus planos com base em intervalos de 30 minutos ou 1 hora. Intervalos maiores que uma hora podem se esconder quando o serviço realmente atinge a capacidade máxima, e intervalos menores que 30 minutos podem fornecer informações imprecisas, que fazem com que os aumentos transitórios pareçam mais importantes do que realmente são.
- Planejar para o crescimento ao longo do ciclo de vida do hardware da empresa. Esse planejamento pode incluir estratégias para atualizar ou adicionar hardware de forma escalonada ou uma atualização completa a cada três a cinco anos. Cada plano de crescimento exige que você estime o quanto a carga no Active Directory cresce. Os dados históricos podem ajudá-lo a fazer uma avaliação mais precisa.
- Planejar para tolerância a falhas. Depois de derivar a estimativa N, planeje cenários que incluam N - 1, N - 2 e N - x.
Com base em seu plano de crescimento, adicione servidores extras de acordo com a necessidade organizacional para garantir que a perda de um ou mais servidores não faça com que o sistema exceda as estimativas de capacidade máxima de pico.
Lembre-se também de que você deve integrar seus planos de crescimento e tolerância a falhas. Por exemplo, se você sabe que sua implantação atualmente requer um DC (controlador de domínio) para dar suporte à carga, mas sua estimativa diz que a carga dobrará no próximo ano e exigirá dois DCs para transportar, seu sistema não terá capacidade suficiente para dar suporte à tolerância a falhas. Para evitar essa falta de capacidade, você deve planejar começar com três DCs. Se o seu orçamento não permitir três DCs, você também pode começar com dois DCs e planejar adicionar um terceiro após três ou seis meses.
Observação
Adicionar aplicativos com reconhecimento do Active Directory pode ter um impacto perceptível na carga do DC, seja a carga proveniente dos servidores de aplicativos ou clientes.
O ciclo de planejamento de capacidade em três partes
Antes de iniciar seu ciclo de planejamento, você precisa decidir qual qualidade de serviço sua organização exige. Todas as recomendações e diretrizes neste artigo são para ambientes de desempenho ideal. No entanto, você pode relaxá-los seletivamente nos casos em que não precisa de otimização. Por exemplo, se sua organização precisar de um nível mais alto de simultaneidade e uma experiência de usuário mais consistente, você deverá considerar a configuração de um datacenter. Os datacenters permitem que você preste mais atenção à redundância e minimize os gargalos do sistema e da infraestrutura. Por outro lado, se você estiver planejando uma implantação para um escritório satélite com apenas alguns usuários, não precisará se preocupar tanto com a otimização de hardware e infraestrutura, o que permite escolher opções de custo mais baixo.
Em seguida, você deve decidir se deseja usar máquinas virtuais ou físicas. Do ponto de vista do planejamento de capacidade, não há resposta certa ou errada. No entanto, você precisa ter em mente que cada cenário oferece um conjunto diferente de variáveis para trabalhar.
Os cenários de virtualização oferecem duas opções:
- Mapeamento direto, em que você tem apenas um convidado por host.
- Cenários de host compartilhado, em que você tem vários convidados por host.
Você pode tratar cenários de mapeamento direto de forma idêntica aos hosts físicos. Se você escolher um cenário de host compartilhado, ele apresentará outras variáveis que você deve levar em consideração nas seções posteriores. Os hosts compartilhados também competem por recursos com os Serviços de Domínio do Active Directory (AD DS), o que pode afetar o desempenho do sistema e a experiência do usuário.
Agora que respondemos a essas perguntas, vamos examinar o próprio ciclo de planejamento de capacidade. Cada ciclo de planejamento de capacidade envolve um processo de três etapas:
- Meça o ambiente existente, determine onde estão os gargalos do sistema atualmente e obtenha os fundamentos ambientais necessários para planejar a quantidade de capacidade necessária para sua implantação.
- Determine qual hardware você precisa com base em seus requisitos de capacidade.
- Monitore e valide se a infraestrutura configurada está operando dentro das especificações. Os dados coletados nesta etapa se tornam a linha de base para o próximo ciclo de planejamento de capacidade.
Aplicando o processo
Para otimizar o desempenho, certifique-se de que os seguintes componentes principais estejam corretamente selecionados e ajustados às cargas do aplicativo:
- Memória
- Rede
- Armazenamento
- Processador
- Netlogon
Os requisitos básicos de armazenamento para o AD DS e o comportamento geral do software cliente compatível permitem que ambientes com até 10.000 a 20.000 usuários ignorem o planejamento de capacidade para hardware físico, pois a maioria dos sistemas modernos de classe de servidor já pode lidar com uma carga desse tamanho. No entanto, as tabelas em Tabelas de resumo da coleção de dados explicam como avaliar seu ambiente existente para selecionar o hardware correto. As seções seguintes entram em mais detalhes sobre recomendações de linha de base e princípios específicos do ambiente para hardware para ajudar os administradores do AD DS a avaliar sua infraestrutura.
Outras informações que você deve ter em mente ao planejar:
- Qualquer dimensionamento baseado em dados atuais é preciso apenas para o ambiente atual.
- Ao fazer estimativas, espere que a demanda cresça ao longo do ciclo de vida do hardware.
- Acomode o crescimento futuro determinando se você deve superdimensionar seu ambiente hoje ou adicionar capacidade gradualmente ao longo do ciclo de vida.
- Todos os princípios e metodologias de planejamento de capacidade que você aplicaria a uma implantação física também se aplicam a uma implantação virtualizada. No entanto, ao planejar um ambiente virtualizado, você precisa se lembrar de adicionar a sobrecarga de virtualização a qualquer planejamento ou estimativa relacionada ao domínio.
- O planejamento de capacidade é uma previsão, não um valor perfeitamente correto, portanto, não espere que ele seja perfeitamente preciso. Lembre-se sempre de ajustar a capacidade conforme necessário e validar constantemente se o ambiente está funcionando conforme o esperado.
Tabelas de resumo da coleta de dados
As tabelas a seguir listam e explicam os critérios para determinar suas estimativas de hardware.
Ambiente de trabalho
| Componente | Estimativas |
|---|---|
| Tamanho do Banco de dados/Armazenamento | De 40 KB a 60 KB para cada usuário |
| RAM | Tamanho do banco de dados Recomendações de sistema operacional base Aplicativo de terceiros |
| Rede | 1 GB |
| CPU | 1000 usuários simultâneos para cada núcleo |
Critérios de avaliação de alto nível
| Componente | Critérios de avaliação | Considerações sobre o planejamento |
|---|---|---|
| Tamanho do banco de dados/armazenamento | Desfragmentação offline | |
| Desempenho do banco de dados/armazenamento |
|
|
| RAM |
|
|
| Rede |
|
|
| CPU |
|
|
| Logon de Rede |
|
|
Planejamento
Por muito tempo, a recomendação usual para o dimensionamento do AD DS era colocar tanta RAM quanto o tamanho do banco de dados. Agora que os ambientes do AD DS e o ecossistema que os consome cresceram muito, as coisas mudaram. Embora o aumento do poder de computação e a mudança da arquitetura x86 para x64 tenham tornado os aspectos mais sutis do dimensionamento do desempenho irrelevantes para os clientes que executam o AD DS em máquinas físicas, a virtualização tornou o ajuste uma preocupação muito maior.
Para resolver essas preocupações, as seções a seguir descrevem como determinar e planejar as demandas do Active Directory como um serviço. Você pode aplicar essas diretrizes a qualquer ambiente, independentemente de seu ambiente ser físico, virtualizado ou misto. Para maximizar seu desempenho, sua meta deve ser fazer com que seu ambiente AD DS seja o mais próximo possível do limite do processador.
RAM
Quanto mais armazenamento você puder armazenar em cache na RAM, menos precisará ir para o disco. Para maximizar a escalabilidade do servidor, a quantidade mínima de RAM usada deve ser igual à soma do tamanho atual do banco de dados, o tamanho total do valor do sistema, a quantidade recomendada para o sistema operacional e as recomendações do fornecedor para os agentes (programas antivírus, monitoramento, backup e assim por diante). Você também deve incluir RAM extra para acomodar o crescimento futuro ao longo da vida útil do servidor. Essa estimativa mudará com base no crescimento do banco de dados e nas mudanças ambientais.
Para ambientes em que a maximização da RAM não é econômica ou inviável, como locais satélites ou quando a DIT (Árvore de Informações do Diretório) é muito grande, pule para Armazenamento para garantir que o armazenamento esteja configurado corretamente.
Outra coisa importante a considerar para dimensionar a memória é o tamanho do arquivo de paginação. No dimensionamento de disco, como tudo relacionado à memória, o objetivo é minimizar o uso do disco. Em particular, quanta RAM você precisa para minimizar a paginação? As próximas seções devem fornecer as informações necessárias para responder a essa pergunta. Outras considerações sobre o tamanho da página que não afetam necessariamente o desempenho do AD DS são as recomendações do SO (sistema operacional) e a configuração do sistema para despejos de memória.
Determinar quanta RAM um DC (controlador de domínio) precisa pode ser difícil devido a muitos fatores complexos:
- Os sistemas existentes nem sempre são indicadores confiáveis dos requisitos de RAM porque o LSSAS (Serviço de Subsistema da Autoridade de Segurança Local) limita a RAM sob condições de pressão de memória, esvaziando artificialmente os requisitos.
- Os DCs individuais só precisam armazenar em cache os dados nos quais seus clientes estão interessados. Isso significa que os dados armazenados em cache em diferentes ambientes serão alterados dependendo dos tipos de clientes que eles contêm. Por exemplo, um controlador de domínio em um ambiente com um Exchange Server coletará dados diferentes de um controlador de domínio que autentica apenas usuários.
- A quantidade de esforço necessária para avaliar a RAM para cada controlador de domínio caso a caso geralmente é excessiva e muda à medida que o ambiente muda.
Os critérios por trás das recomendações podem ajudá-lo a tomar decisões mais informadas:
- Quanto mais você armazena em cache na RAM, menos precisa ir para o disco.
- O armazenamento é o componente mais lento de um computador. O acesso a dados em mídia de armazenamento SSD e baseada em eixo é um milhão de vezes mais lento do que o acesso a dados na RAM.
Considerações sobre virtualização para RAM
Seu objetivo para otimizar a RAM é minimizar a quantidade de tempo gasto no disco. Você também deve evitar o comprometimento excessivo de memória no host. Em cenários de virtualização, o comprometimento excessivo de memória é quando o sistema aloca mais RAM para convidados do que o que existe na própria máquina física. Embora o excesso de confirmação não seja um problema por si só, quando a memória total usada por todos os convidados excede a capacidade da RAM do host, isso faz com que o host faça uma paginação. A paginação torna o desempenho associado ao disco nos casos em que o controlador de domínio vai para o NTDS.nit ou arquivo de paginação para obter dados ou o host vai para o disco para tentar acessar os dados da RAM. Como resultado, esse processo diminui muito o desempenho e a experiência geral do usuário.
Exemplo de resumo de cálculo
| Componente | Memória estimada (exemplo) |
|---|---|
| RAM recomendada do sistema operacional base (Windows Server 2008) | 2 GB |
| Tarefas internas do LSASS | 200 MB |
| Agente de monitoramento | 100 MB |
| Antivírus | 100 MB |
| Banco de dados (Catálogo Global) | 8,5 GB |
| Amortecimento para execução do backup, administradores para fazer logon sem impacto | 1 GB |
| Total | 12 GB |
Recomendável: 16 GB
Com o tempo, mais dados são adicionados ao banco de dados, e a vida útil média do servidor é de cerca de três a cinco anos. Com base em uma estimativa de crescimento de 333%, 16 GB é uma quantidade razoável de RAM para colocar em um servidor físico.
Rede
Esta seção trata da avaliação de quanta largura de banda total e capacidade de rede sua implantação precisa, incluindo consultas de cliente, configurações de Política de Grupo e assim por diante. Você pode coletar dados para fazer sua estimativa usando os contadores de desempenho Network Interface(*)\Bytes Received/sec e Network Interface(*)\Bytes Sent/sec. Os intervalos de exemplo para contadores de Adaptador de Rede devem ser de 15, 30 ou 60 minutos. Qualquer coisa menos será muito volátil para boas medições, e qualquer coisa maior suavizará excessivamente os picos diários.
Observação
Em geral, a maior parte do tráfego de rede em um DC é de saída, pois o DC o responde às consultas de cliente. Como resultado, esta seção se concentra principalmente no tráfego de saída. No entanto, também recomendamos que você avalie cada um de seus ambientes quanto ao tráfego de entrada. Você também pode usar as diretrizes deste artigo para avaliar os requisitos de tráfego de rede de entrada. Para mais informações, consulte 92851: o intervalo de porta dinâmica para TCP/IP mudou no Windows Vista e no Windows Server 2008.
Necessidades de Largura de Banda
O planejamento da escalabilidade de rede abrange duas categorias distintas: a quantidade de tráfego e a carga da CPU do tráfego de rede.
Há duas coisas que você precisa levar em consideração ao planejar a capacidade para suporte de tráfego. Primeiro, você precisa saber quanto tráfego de replicação do Active Directory vai entre seus DCs. Em segundo lugar, você deve avaliar o tráfego de cliente para servidor intra-site. O tráfego intra-site recebe principalmente pequenas solicitações de clientes em relação às grandes quantidades de dados que envia de volta aos clientes. 100 MB geralmente são suficientes para ambientes com até 5.000 usuários por servidor. Para ambientes com mais de 5.000 usuários, recomendamos que você use um adaptador de rede de 1 GB e suporte a RSS (Receive Side Scaling).
Para avaliar a capacidade de tráfego intra-site, especialmente em cenários de consolidação de servidor, você deve examinar o contador de desempenho de Network Interface(*)\Bytes/sec em todos os DCs em um site, adicioná-los e dividir a soma pelo número de DCs de destino. Uma maneira fácil de calcular esse número é abrir o Monitor de Confiabilidade e Desempenho do Windows e examinar o modo de exibição Área Empilhada. Certifique-se de que todos os contadores estejam dimensionados da mesma forma.
Vamos dar uma olhada em um exemplo de uma maneira mais complexa de validar se essa regra geral se aplica a um ambiente específico. Neste exemplo, estamos fazendo as seguintes suposições:
- A meta é reduzir o volume para o menor número possível de servidores. Idealmente, um servidor carrega a carga e, em seguida, você implanta um servidor adicional para redundância (cenário n + 1).
- Nesse cenário, o adaptador de rede atual dá suporte a apenas 100 MB e está em um ambiente comutado.
- A utilização máxima da largura de banda de rede de destino é 60% em um cenário n (perda de um DC).
- Cada servidor tem cerca de 10.000 clientes conectados a ele.
Agora, vamos dar uma olhada no que o gráfico no contador Network Interface(*)\Bytes Sent/sec diz sobre este cenário de exemplo:
- O dia útil começa a aumentar por volta das 5h30 e termina às 19h00.
- O período de pico mais movimentado é das 8h às 8h15, com mais de 25 bytes enviados por segundo no controlador de domínio mais movimentado.
Observação
Todos os dados de desempenho são históricos, portanto, o ponto de dados de pico às 8h15 indica a carga das 8h às 8h15.
- Há picos antes das 4h, com mais de 20 bytes enviados por segundo no controlador de domínio mais movimentado, o que pode indicar carga de diferentes fusos horários ou atividade de infraestrutura em segundo plano, como backups. Como o pico às 8h excede essa atividade, não é relevante.
- Existem cinco DCs no site.
- A carga máxima é de cerca de 5,5 MBps por DC, o que representa 44% da conexão de 100 MB. Usando esses dados, podemos estimar que a largura de banda total necessária entre 8h00 e 8h15 é de 28 MBps.
Observação
Os contadores de envio/recebimento do adaptador de rede estão em bytes, mas a largura de banda da rede é medida em bits. Portanto, para calcular a largura de banda total, você precisaria fazer 100 MB ÷ 8 = 12,5 MB e 1 GB ÷ 8 = 128 MB.
Agora que revisamos os dados, que conclusões podemos tirar deles?
- O ambiente atual atende ao nível n + 1 de tolerância a falhas com 60% de utilização alvo. Colocar um sistema offline mudará a largura de banda por servidor de cerca de 5,5 MBps (44%) para cerca de 7 MBps (56%).
- Com base na meta declarada anteriormente de consolidar em um servidor, essa alteração excede a utilização máxima de destino e a possível utilização de uma conexão de 100 MB.
- Com uma conexão de 1 GB, esse valor representa 22% da capacidade total.
- Em condições normais de operação no cenário n + 1, a carga do cliente é distribuída de maneira relativamente uniforme em cerca de 14 MBps por servidor ou 11% da capacidade total.
- Para garantir que você tenha capacidade suficiente enquanto um DC não estiver disponível, as metas operacionais normais por servidor seriam cerca de 30% de utilização da rede ou 38 MBps por servidor. As metas de failover seriam 60% de utilização da rede ou 72 MBps por servidor.
A implantação final do sistema deve ter um adaptador de rede de 1 GB e uma conexão com uma infraestrutura de rede que suportará essa carga. Devido à quantidade de tráfego de rede, a carga da CPU das comunicações de rede pode limitar potencialmente a escalabilidade máxima do AD DS. Você pode usar esse mesmo processo para estimar a comunicação de entrada com o DC. No entanto, na maioria dos cenários, você não precisará calcular o tráfego de entrada porque ele é menor que o tráfego de saída.
É importante garantir que seu hardware suporte RSS em ambientes com mais de 5.000 usuários por servidor. Para cenários de alto tráfego de rede, o balanceamento da carga de interrupção pode ser um gargalo. Você pode detectar possíveis gargalos verificando o contador Processor(*)\% Interrupt Time para ver se o tempo de interrupção está distribuído de forma desigual entre as CPUs. Os NICs (controladores de adaptador de rede) habilitados para RSS podem mitigar essas limitações e aumentar a escalabilidade.
Observação
Você pode adotar uma abordagem semelhante para estimar se precisar de mais capacidade ao consolidar datacenters ou desativar um controlador de domínio em um local satélite. Para estimar a capacidade necessária, basta examinar os dados do tráfego de saída e entrada para os clientes. O resultado é a quantidade de tráfego presente nos links de WAN (rede de longa distância).
Em alguns casos, você pode experimentar mais tráfego do que o esperado porque ele é mais lento, como quando a verificação de certificado falha ao atender a tempos limite agressivos na WAN. Por esse motivo, o dimensionamento e a utilização da WAN devem ser um processo iterativo e contínuo.
Considerações sobre virtualização para largura de banda de rede
As recomendações típicas para um servidor físico são 1 GB para servidores que suportam mais de 5.000 usuários. Depois que vários convidados começarem a compartilhar uma infraestrutura de switch virtual subjacente, você deve prestar atenção extra se o host tem largura de banda de rede adequada para dar suporte a todos os convidados no sistema. Você precisa considerar a largura de banda, independentemente de a rede incluir o controlador de domínio em execução como uma VM em um host com tráfego de rede passando por um comutador virtual ou conectado diretamente a um comutador físico. Os comutadores virtuais são componentes em que o uplink deve suportar a quantidade de dados que a conexão transmite, o que significa que o adaptador de rede do host físico vinculado ao comutador deve ser capaz de suportar a carga CC mais todos os outros convidados que compartilham o comutador virtual conectado ao adaptador de rede físico.
Exemplo de resumo de cálculo de rede
A tabela a seguir contém valores de um cenário de exemplo que podemos usar para calcular a capacidade da rede:
| Sistema | Largura de banda de pico |
|---|---|
| DC 1 | 6.5 MBps |
| DC 2 | 6.25 MBps |
| DC 3 | 6.25 MBps |
| DC 4 | 5.75 MBps |
| DC 5 | 4.75 MBps |
| Total | 28.5 MBps |
Com base nessa tabela, a largura de banda recomendada seria de 72 MBps (28,5 MBps ÷ 40%).
| Contagem do sistema de destino | Largura de banda total (acima) |
|---|---|
| 2 | 28.5 MBps |
| Comportamento normal resultante | 28,5 ÷ 2 = 14,25 MBps |
Como sempre, você deve presumir que a carga de clientes aumentará com o tempo; portanto, planeje esse crescimento o mais cedo possível. Recomendamos que você planeje pelo menos 50% de crescimento estimado do tráfego de rede.
Armazenamento
Há duas coisas que você deve considerar ao planejar a capacidade de armazenamento:
- Capacidade ou tamanho do armazenamento
- Desempenho
Embora a capacidade seja importante, é importante não negligenciar o desempenho. Com os custos atuais de hardware, a maioria dos ambientes não é grande o suficiente para que qualquer um dos fatores seja uma grande preocupação. Portanto, a recomendação usual é apenas colocar tanta RAM quanto o tamanho do banco de dados. No entanto, essa recomendação pode ser um exagero para locais satélites em ambientes maiores.
Dimensionamento
Avaliação do armazenamento
Em comparação com quando o Active Directory chegou pela primeira vez em uma época em que as unidades de 4 GB e 9 GB eram os tamanhos de unidade mais comuns, agora o dimensionamento do Active Directory não é nem mesmo uma consideração para todos, exceto para os maiores ambientes. Com os menores tamanhos de disco rígido disponíveis no intervalo de 180 GB, todo o sistema operacional, SYSVOL e NTDS.dit podem caber facilmente em uma unidade. Como resultado, recomendamos que você evite investir muito nessa área.
Nossa única recomendação é que você garanta que 110% do tamanho do NTS.dit estejam disponíveis para que você possa desfragmentar seu armazenamento. Além disso, você deve tomar as considerações usuais ao acomodar o crescimento futuro.
Se você for avaliar seu armazenamento, primeiro deverá avaliar o tamanho do NTDS.dit e do SYSVOL. Essas medidas ajudarão você a dimensionar as alocações fixas de disco e RAM. Como os componentes são de custo relativamente baixo, você não precisa ser super preciso ao fazer as contas. Para obter mais informações sobre avaliação de armazenamento, consulte Limites de armazenamento e Estimativas de crescimento para usuários e unidades organizacionais do Active Directory.
Observação
Os artigos vinculados no parágrafo anterior são baseados em estimativas de tamanho de dados feitas durante o lançamento do Active Directory no Windows 2000. Ao fazer sua própria estimativa, use tamanhos de objeto que reflitam o tamanho real dos objetos em seu ambiente.
Ao examinar os ambientes existentes com vários domínios, você pode notar variações nos tamanhos dos bancos de dados. Ao identificar essas variações, use o menor GC (catálogo global) e tamanhos não GC.
Os tamanhos do banco de dados podem variar entre as versões do sistema operacional. Os controladores de domínio que executam versões anteriores do sistema operacional, como o Windows Server 2003, têm tamanhos de banco de dados menores do que um que executa uma versão posterior, como o Windows Server 2008 R2. O controlador de domínio com recursos como a Lixeira do Active Directory ou o Roaming de Credenciais habilitado também pode afetar o tamanho do banco de dados.
Observação
- Para novos ambientes, lembre-se de que 100.000 usuários no mesmo domínio consomem cerca de 450 MB de espaço. Os atributos que você preenche podem ter um grande impacto na quantidade total de espaço consumido. Os atributos são preenchidos por muitos objetos de produtos de terceiros e da Microsoft, incluindo o Microsoft Exchange Server e o Lync. Como resultado, recomendamos que você avalie com base no portfólio de produtos do ambiente. No entanto, você também deve ter em mente que fazer as contas e testar estimativas precisas para todos os ambientes, exceto os maiores, pode não valer a pena tempo ou esforço significativo.
- Certifique-se de que o espaço livre disponível seja 110% do tamanho do NTDS.dit para habilitar a desfragmentação offline. Esse espaço livre também permite que você planeje o crescimento ao longo da vida útil do hardware de três a cinco anos do servidor. Se você tiver o armazenamento para isso, alocar espaço livre suficiente para igualar 300% do DIT para armazenamento é uma maneira segura de acomodar o crescimento e a desfragmentação.
Considerações sobre virtualização para armazenamento
Em cenários em que você aloca vários arquivos VHD (Disco Rígido Virtual) para um único volume, você deve usar um disco de estado fixo de pelo menos 210% do tamanho do DIT (100% do DIT + 110% de espaço livre) para garantir que você tenha espaço suficiente reservado para suas necessidades.
Exemplo de resumo de cálculo de armazenamento
A tabela a seguir lista os valores que você usaria para estimar os requisitos de espaço para um cenário de armazenamento hipotético.
| Dados coletados a partir da fase de avaliação | Tamanho |
|---|---|
| Tamanho de NTDS.dit | 35 GB |
| Modificador para permitir o defrag offline | 2,1 GB |
| Armazenamento total necessário | 73,5 GB |
Observação
A estimativa de armazenamento também deve incluir a quantidade de armazenamento necessária para o SYSVOL, o sistema operacional, o arquivo de paginação, arquivos temporários, dados armazenados em cache local, como arquivos do instalador e aplicativos.
Desempenho de armazenamento
Como o componente mais lento em qualquer computador, o armazenamento pode causar o maior impacto adverso na experiência do cliente. Para ambientes grandes o suficiente para que as recomendações de dimensionamento de RAM neste artigo não sejam viáveis, as consequências de ignorar o planejamento de capacidade para armazenamento podem ser devastadoras para o desempenho do sistema. As complexidades e variedades da tecnologia de armazenamento disponível aumentam ainda mais o risco, pois a recomendação típica de colocar o sistema operacional, os logs e o banco de dados em discos físicos separados não se aplica universalmente em todos os cenários.
As recomendações antigas sobre discos presumiam que um disco era um eixo dedicado que permitia E/S isolada. Essa suposição não é mais verdadeira devido à introdução dos seguintes tipos de armazenamento:
- RAID
- Novos tipos de armazenamento e cenários de armazenamento virtualizado e compartilhado
- Eixos compartilhados em uma SAN (Rede de área de armazenamento)
- Arquivo VHD em um armazenamento SAN ou conectado à rede
- Unidades de Estado Sólido (SSDs)
- Arquiteturas de armazenamento em camadas, como armazenamento em cache de camada de armazenamento SSD maior armazenamento baseado em eixo
O armazenamento compartilhado, como RAID, SAN, NAS, JBOD, Espaços de Armazenamento e VHD, pode ser sobrecarregado por outras cargas de trabalho que você coloca no armazenamento de back-end. Esses tipos de armazenamento também apresentam um desafio extra: problemas de SAN, rede ou driver entre o disco físico e o aplicativo AD podem causar limitação e atrasos. Para esclarecer, essas não são configurações ruins, mas são mais complexas, o que significa que você precisa prestar atenção extra para garantir que todos os componentes estejam funcionando conforme o esperado. Para explicações mais detalhadas, consulte o Apêndice C e o Apêndice D mais adiante neste artigo. Além disso, embora os SSDs não sejam limitados por discos rígidos que só podem processar uma E/S por vez, eles ainda têm limitações de E/S que podem ser sobrecarregadas.
Em resumo, o objetivo de todo o planejamento de desempenho de armazenamento, independentemente da arquitetura de armazenamento, é garantir que o número necessário de E/S esteja sempre disponível e que ocorra dentro de um prazo aceitável. Para cenários com armazenamento conectado localmente, consulte o Apêndice C para mais informações sobre design e planejamento. Você pode aplicar os princípios do apêndice a cenários de armazenamento mais complexos, bem como a conversas com fornecedores que dão suporte às suas soluções de armazenamento back-end.
Devido à quantidade de opções de armazenamento disponíveis atualmente, recomendamos que você consulte suas equipes ou fornecedores de suporte de hardware durante o planejamento para garantir que a solução atenda às necessidades de sua implantação do AD DS. Durante essas conversas, você pode achar úteis os seguintes contadores de desempenho, especialmente quando o banco de dados é muito grande para a RAM:
LogicalDisk(*)\Avg Disk sec/Read(por exemplo, se NTDS.dit estiver armazenado na unidade D, o caminho completo seráLogicalDisk(D:)\Avg Disk sec/Read)LogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
Ao fornecer os dados, você deve se certificar de que eles sejam amostrados em intervalos de 15, 30 ou 60 minutos para fornecer a imagem mais precisa possível do seu ambiente atual.
Avaliando os resultados
Esta seção se concentra nas leituras do banco de dados, pois o banco de dados geralmente é o componente mais exigente. Você pode aplicar a mesma lógica às gravações no arquivo de log substituindo <NTDS Log>)\Avg Disk sec/Write e LogicalDisk(<NTDS Log>)\Writes/sec).
O contador LogicalDisk(<NTDS>)\Avg Disk sec/Read mostra se o armazenamento atual está dimensionado adequadamente. Se o valor for aproximadamente igual ao Tempo de Acesso ao Disco esperado para o tipo de disco, o contador LogicalDisk(<NTDS>)\Reads/sec será uma medida válida. Se os resultados forem aproximadamente iguais ao Tempo de Acesso ao Disco esperado para o tipo de disco, o contador LogicalDisk(<NTDS>)\Reads/sec será uma medida válida. Embora isso possa mudar dependendo das especificações do fabricante do seu armazenamento de back-end, os bons intervalos seriam LogicalDisk(<NTDS>)\Avg Disk sec/Read:
- 7200 rpm: 9 a 12,5 milissegundos (ms)
- 10.000 rpm: 6 a 10 ms
- 15.000 rpm: 4 a 6 ms
- SSD – 1 a 3 ms
Você pode ouvir de outras fontes que o desempenho do armazenamento é degradado em 15 ms a 20 ms. A diferença entre esses valores e os valores na lista anterior é que os valores da lista mostram a faixa de operação normal. Os outros valores são para fins de solução de problemas, que ajudam a identificar quando a experiência do cliente foi degradada o suficiente para se tornar perceptível. Para mais informações, confira o Apêndice C.
LogicalDisk(<NTDS>)\Reads/secé a quantidade de E/S que o sistema está executando no momento.- Se
LogicalDisk(<NTDS>)\Avg Disk sec/Readestiver dentro do intervalo ideal para o armazenamento de back-end, você poderá usarLogicalDisk(<NTDS>)\Reads/secdiretamente para dimensionar o armazenamento. - Se
LogicalDisk(<NTDS>)\Avg Disk sec/Readnão estiver dentro do intervalo ideal para o armazenamento de back-end, E/S adicional será necessária de acordo com a seguinte fórmula:LogicalDisk(<NTDS>)\Avg Disk sec/Read÷ Tempo de acesso ao disco de mídia física ×LogicalDisk(<NTDS>)\Avg Disk sec/Read
- Se
Ao fazer esses cálculos, aqui estão algumas coisas que você deve considerar:
- Se o servidor tiver uma quantidade abaixo do ideal de RAM, os valores resultantes serão muito altos e não serão precisos o suficiente para serem úteis para o planejamento. No entanto, você ainda pode usá-los para prever os piores cenários.
- Se você adicionar ou otimizar a RAM, também diminuirá a quantidade de
LogicalDisk(<NTDS>)\Reads/Secde E/S de leitura. Essa diminuição pode fazer com que a solução de armazenamento não seja tão robusta quanto os cálculos originais adivinhavam. Infelizmente, não podemos dar mais detalhes sobre o que essa declaração significa, pois os cálculos variam muito dependendo dos ambientes individuais, principalmente da carga do cliente. No entanto, recomendamos que você ajuste o tamanho do armazenamento depois de otimizar a RAM.
Considerações sobre virtualização para desempenho
Assim como nas seções anteriores, nosso objetivo aqui é garantir que a infraestrutura compartilhada possa suportar a carga total de todos os consumidores. Você precisa manter essa meta em mente ao planejar os seguintes cenários:
- Um CD físico que compartilha a mesma mídia em uma infraestrutura SAN, NAS ou iSCSI que outros servidores ou aplicativos.
- Um usuário que usa acesso de passagem a uma infraestrutura SAN, NAS ou iSCSI que compartilha a mídia.
- Um usuário que usa um arquivo VHD em mídia compartilhada localmente ou em uma infraestrutura SAN, NAS ou iSCSI.
Do ponto de vista de um usuário convidado, ter que passar por um host para acessar qualquer armazenamento afeta o desempenho, pois o usuário deve percorrer caminhos de código adicionais para obter acesso. O teste de desempenho indica que a virtualização afeta a taxa de transferência com base em quanto do processador o sistema host utiliza. A utilização do processador também é influenciada por quantos recursos o usuário convidado exige do host. Essa demanda contribui para as considerações de Virtualização para processamento que você deve tomar para necessidades de processamento em cenários virtualizados. Para mais informações, confira o Apêndice A.
Para complicar ainda mais as coisas, é preciso considerar quantas opções de armazenamento estão disponíveis atualmente, cada uma com impactos de desempenho totalmente diferentes. Essas opções incluem armazenamento de passagem, adaptadores SCSI e IDE. Ao migrar de um ambiente físico para um virtual, você deve ajustar as diferentes opções de armazenamento para usuários convidados virtualizados usando um multiplicador de 1,10. No entanto, você não precisa considerar ajustes ao transferir entre diferentes cenários de armazenamento, pois se o armazenamento é local, SAN, NAS ou iSCSI é mais importante.
Exemplo de cálculo de virtualização
Determinar a quantidade de E/S necessária para um sistema íntegro em condições operacionais normais:
- LogicalDisk(
<NTDS Database Drive>) ÷ Transferências por segundo durante o período de pico de 15 minutos - Para determinar a quantidade de E/S necessária para armazenamento em que a capacidade do armazenamento subjacente é excedida:
Needed IOPS = (LogicalDisk(
<NTDS Database Drive>)) ÷ Avg Disk Read/sec ÷<Target Avg Disk Read/sec>) × LogicalDisk(<NTDS Database Drive>)\Read/sec
| Contador | Valor |
|---|---|
Actual LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Transfer |
0,02 segundos (20 milissegundos) |
Target LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Transfer |
0,01 segundos |
| Multiplicador para alteração na E/S disponível | 0,02 ÷ 0,01 = 2 |
| Nome do valor | Valor |
|---|---|
LogicalDisk(<NTDS Database Drive>)\Transfers/sec |
400 |
| Multiplicador para alteração na E/S disponível | 2 |
| IOPS total necessário durante o período de pico | 800 |
Para determinar a taxa na qual você deve aquecer o cache:
- Determine o tempo máximo que você considera aceitável para gastar no aquecimento do cache. Em cenários típicos, um período de tempo aceitável seria quanto tempo deve levar para carregar todo o banco de dados de um disco. Em cenários em que a RAM não pode carregar todo o banco de dados, use o tempo necessário para preencher toda a RAM.
- Determine o tamanho do banco de dados, excluindo o espaço que você não planeja usar. Para obter mais informações, consulte Avaliação do armazenamento.
- Divida o tamanho do banco de dados por 8 KB para obter o número total de E/S necessárias para carregar o banco de dados.
- Divida o total de E/S pelo número de segundos no período de tempo definido.
O número calculado é mais preciso, mas pode não ser exato porque você não configurou o ESE (Mecanismo de Armazenamento Extensível) para ter um tamanho de cache fixo, o AD DS removerá as páginas carregadas anteriormente porque usa o tamanho de cache variável por padrão.
| Pontos de dados a serem coletados | Valores |
|---|---|
| Tempo máximo aceitável para inicializar | 10 minutos (600 segundos) |
| Tamanho do banco de dados | 2 GB |
| Etapa de cálculo | Fórmula | Resultado |
|---|---|---|
| Calcular o tamanho do banco de dados em páginas | (2 GB × 1024 × 1024) = Tamanho do banco de dados em KB | 2.097.152 KB |
| Calculo do número de páginas no banco de dados | 2.097.152 KB ÷ 8 KB = Número de páginas | 262.144 páginas |
| Calcular o IOPS necessário para inicializar totalmente o cache | 262.144 páginas ÷ 600 segundos = IOPS necessário | 437 IOPS |
Processando
Avaliação do uso do processador do Active Directory
Para a maioria dos ambientes, o gerenciamento da capacidade de processamento é o componente que merece mais atenção. Ao avaliar quanta capacidade de CPU sua implantação precisa, você deve considerar as duas coisas a seguir:
- Os aplicativos em seu ambiente se comportam conforme o esperado em uma infraestrutura de serviços compartilhados com base nos critérios descritos em Rastreando pesquisas caras e ineficientes? Em ambientes maiores, aplicativos mal codificados podem fazer com que a carga da CPU se torne volátil, consumir uma quantidade excessiva de tempo da CPU às custas de outros aplicativos, aumentar as necessidades de capacidade e distribuir a carga de forma desigual nos DCs.
- O AD DS é um ambiente distribuído com muitos clientes em potencial cujas necessidades de processamento variam muito. Os custos estimados para cada cliente podem variar devido aos padrões de uso e quantos aplicativos estão usando o AD DS. Assim como na rede, você deve abordar a estimativa como uma avaliação da capacidade total necessária no ambiente, em vez de olhar para cada cliente, um de cada vez.
Você só deve fazer essa estimativa depois de concluir sua estimativa de armazenamento , pois não poderá fazer uma estimativa precisa sem dados válidos sobre a carga do processador. Também é importante garantir que os gargalos não estejam sendo causados pelo armazenamento antes de solucionar problemas do processador. À medida que você remove os estados de espera do processador, a utilização da CPU aumenta porque ela não precisa mais aguardar os dados. Portanto, os contadores de desempenho aos quais você deve prestar mais atenção são Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read e Process(lsass)\ Processor Time. Se o contador Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read tiver mais de 10 ou 15 milissegundos, os dados em Process(lsass)\ Processor Time serão artificialmente baixos, e o problema estará relacionado ao desempenho do armazenamento. Recomendamos que você defina intervalos de amostragem para 15, 30 ou 60 minutos para obter os dados mais precisos possíveis.
Visão geral do processamento
A fim de planejar o planejamento da capacidade para controladores de domínio, o poder de processamento exige mais atenção e compreensão. Ao dimensionar sistemas para garantir o desempenho máximo, sempre há um componente que é o gargalo e, em um controlador de domínio de tamanho adequado, esse componente é o processador.
Semelhante à seção de rede em que a demanda do ambiente é revisada site a site, o mesmo deve ser feito na capacidade de computação exigida. Ao contrário da seção de rede, em que as tecnologias de rede disponíveis excedem bastante a demanda normal, preste mais atenção ao dimensionamento da capacidade da CPU. Como qualquer ambiente de tamanho moderado; qualquer coisa acima de alguns milhares de usuários simultâneos pode colocar uma carga significativa na CPU.
Infelizmente, devido à enorme variabilidade de aplicativos cliente que aproveitam o AD, uma estimativa geral de usuários por CPU é lamentavelmente inaplicável a todos os ambientes. Especificamente, as demandas de computação estão sujeitas ao comportamento do usuário e ao perfil do aplicativo. Portanto, cada ambiente precisa ser dimensionado individualmente.
Perfil de comportamento do site de destino
Quando você está planejando a capacidade de um site inteiro, sua meta deve ser um design de capacidade N + 1. Nesse projeto, mesmo que um sistema falhe durante o período de pico, o serviço ainda pode continuar em níveis aceitáveis de qualidade. Em um cenário N, a carga em todas as caixas deve ser inferior a 80% a 100% durante os períodos de pico.
Além disso, os aplicativos e clientes do site usam o método de função DsGetDcName recomendado para localizar DCs, eles já devem estar distribuídos uniformemente com apenas pequenos picos transitórios.
Agora vamos ver dois exemplos de ambientes que estão no alvo e fora do alvo. Primeiro, vamos dar uma olhada em um exemplo de um ambiente que funciona conforme o esperado e não excede a meta de planejamento de capacidade.
Para o primeiro exemplo, estamos fazendo as seguintes suposições:
- Cada um dos cinco DCs no site tem quatro CPUs.
- O uso total da CPU de destino durante o horário comercial é de 40% em condições operacionais normais (N + 1) e, caso contrário, 60% (N). Fora do horário comercial, o uso da CPU desejado é de 80% porque esperamos que o software de backup e outros processos de manutenção consumam todos os recursos disponíveis.
Agora, vamos dar uma olhada no gráfico (Processor Information(_Total)\% Processor Utility), para cada um dos DCs, conforme mostrado na imagem a seguir.
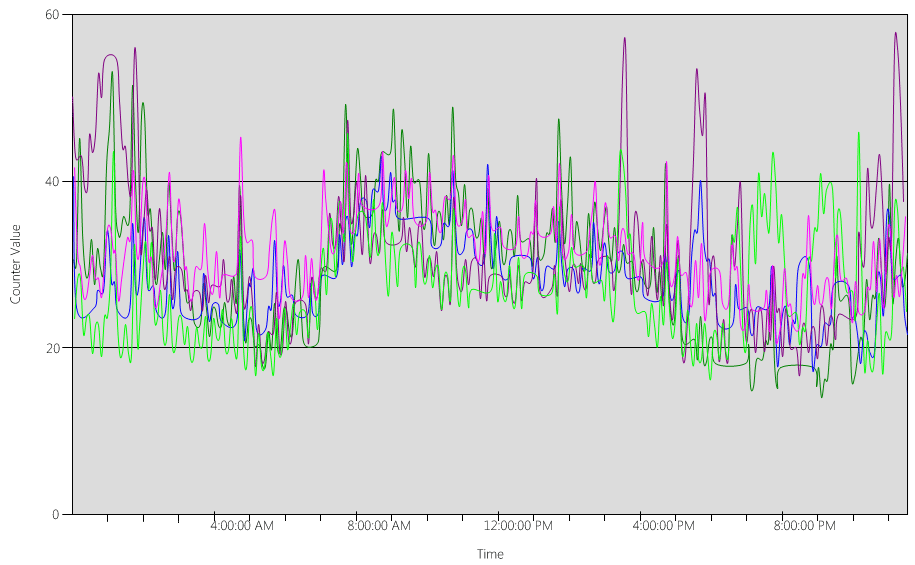
A carga é distribuída de maneira relativamente uniforme, que é o que esperaríamos quando os clientes usam o localizador DC e pesquisas bem escritas.
Em vários intervalos de cinco minutos, há picos de 10%, às vezes até 20%. No entanto, a menos que esses picos façam com que o uso da CPU exceda a meta do plano de capacidade, você não precisa investigá-los.
O período de pico para todos os sistemas é entre 8h e 9h15. O dia útil médio dura das 5h às 17h. Portanto, todos os picos aleatórios de uso da CPU que ocorrem entre 17h e 4h estão fora do horário comercial e, portanto, você não precisa incluí-los em suas preocupações de planejamento de capacidade.
Observação
Em um sistema bem gerenciado, os picos que ocorrem fora do período de pico geralmente são causados por software de backup, verificações antivírus completas do sistema, estoque de hardware ou software, implantação de software ou patch e assim por diante. Como esses picos acontecem fora do horário comercial, eles não contam para exceder as metas de planejamento de capacidade.
Como cada sistema tem cerca de 40% e todos têm o mesmo número de CPUs, se um deles ficar off-line, os sistemas restantes serão executados a cerca de 53%. O Sistema D tem uma carga de 40% que é dividida uniformemente e adicionada à carga existente de 40% do Sistema A e C. Essa suposição linear não é perfeitamente precisa, mas fornece precisão suficiente para medir.
Em seguida, vejamos um exemplo de um ambiente que não tem um bom uso da CPU e excede a meta de planejamento de capacidade.
Neste exemplo, temos dois DCs rodando a 40%. Um controlador de domínio fica offline, o que faz com que o uso estimado da CPU no controlador de domínio restante atinja 80%. Esse nível de uso da CPU excede em muito o limite do plano de capacidade e começa a limitar a quantidade de reserva dinâmica para os 10% a 20% do perfil de carga. Como resultado, cada pico poderia potencialmente levar o CD a 90% ou até 100% durante o cenário N, reduzindo sua capacidade de resposta.
Calculando as demandas de CPU
O contador de desempenho Process\% Processor Time rastreia a quantidade total de tempo que todos os threads do aplicativo gastam na CPU e, em seguida, divide essa soma pela quantidade total de tempo do sistema que passou. Um aplicativo multi-threaded em um sistema com várias CPUs pode exceder 100% do tempo de CPU, e você interpretaria seus dados de maneira muito diferente do contador Processor Information\% Processor Utility. Na prática, o contador Process(lsass)\% Processor Time rastreia quantas CPUs rodando a 100% o sistema requer para suportar as demandas de um processo. Por exemplo, se o contador tiver um valor de 200%, isso significa que o sistema precisa de duas CPUs em execução a 100% para dar suporte à carga total do AD DS. Embora uma CPU rodando a 100% da capacidade seja a mais econômica em termos de consumo de energia, pelos motivos descritos no Apêndice A, um sistema multi-threaded é mais responsivo quando seu sistema não está rodando a 100%.
Para acomodar picos transitórios na carga do cliente, recomendamos que você direcione uma CPU de período de pico entre 40% e 60% da capacidade do sistema. Por exemplo, no primeiro exemplo em Perfil de comportamento do site de destino, você precisaria de 3,33 CPUs (meta de 60%) a 5 CPUs (meta de 40%) para dar suporte à carga do AD DS. Você deve adicionar capacidade extra de acordo com as demandas do sistema operacional e quaisquer outros agentes necessários, como antivírus, backup, monitoramento e assim por diante. Embora você deva avaliar o impacto dos agentes nos agentes da CPU por ambiente, geralmente você pode alocar entre 5% e 10% para processos de agente em uma única CPU. Para revisitar nosso exemplo, precisaríamos de 3,43 (meta de 60%) a 5,1 (meta de 40%) de CPUs para suportar a carga durante os períodos de pico.
Agora, vamos dar uma olhada em um exemplo de cálculo para um processo específico. Nesse caso, estamos analisando o processo LSASS.
Calcular o uso da CPU para o processo LSASS
Neste exemplo, o sistema é um cenário N + 1 em que um servidor carrega a carga do AD DS enquanto um servidor extra está lá para redundância.
O gráfico a seguir mostra o tempo do processador para o processo LSASS em todos os processadores deste cenário de exemplo. Esses dados foram coletados do contador de desempenho Process(lsass)\% Processor Time.
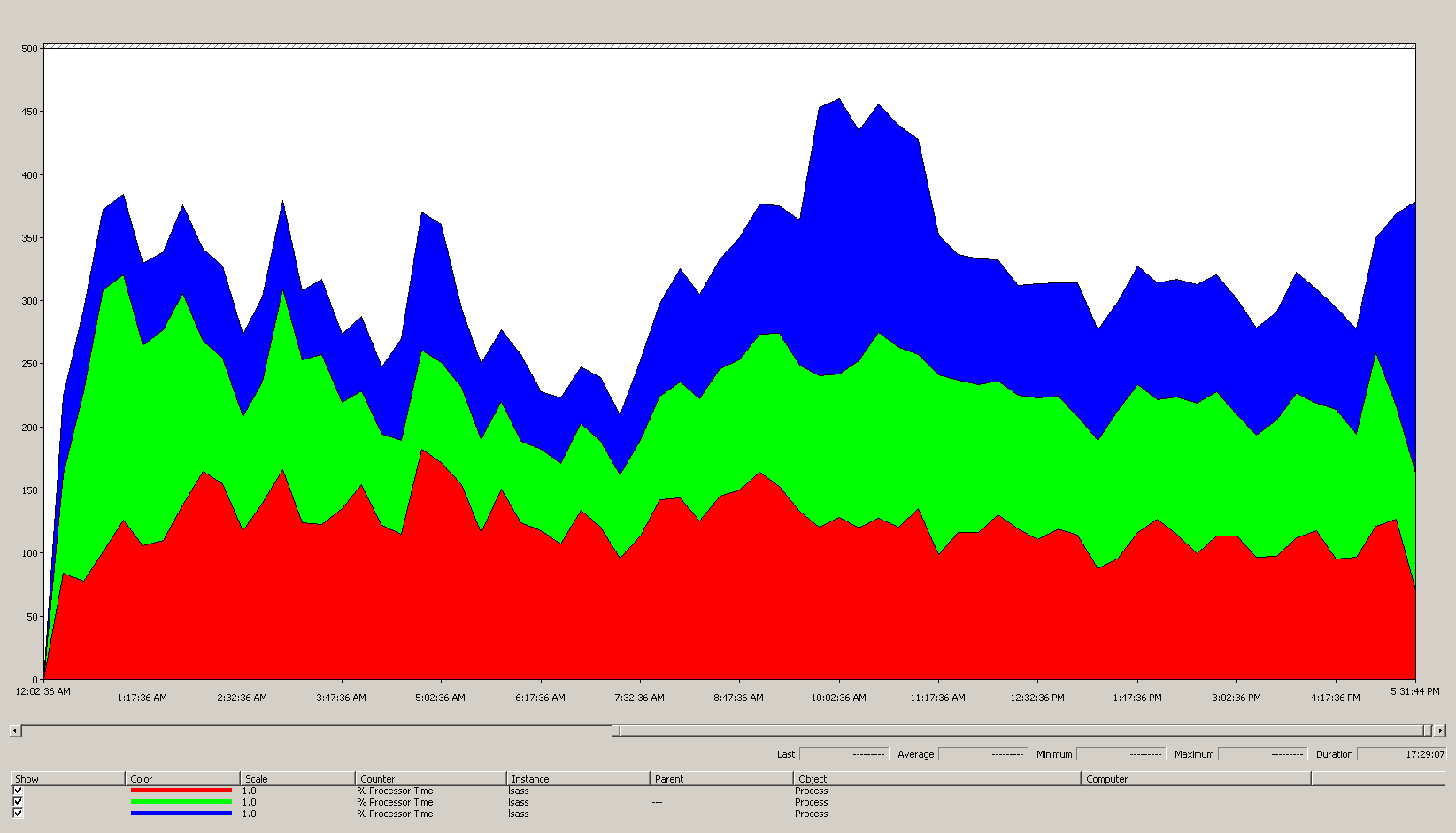
Aqui está o que este gráfico nos diz sobre o ambiente do cenário:
- Há três controladores de domínio no site.
- O dia útil começa a acelerar por volta das 7h e termina às 19h.
- O período mais movimentado do dia é a partir das 9h30 às 11h.
Observação
Todos os dados de desempenho são históricos. O ponto de dados de pico às 9h15 indica a carga das 9h às 9h15.
- Picos antes das 7h podem indicar carga extra de diferentes fusos horários ou atividades de infraestrutura em segundo plano, como backups. No entanto, como esse pico é menor do que o pico de atividade às 9h30, não é motivo de preocupação.
Na carga máxima, o processo lsass consome cerca de 4,85 CPUs rodando a 100%, o que seria 485% em uma única CPU. Esses resultados sugerem que o site do cenário precisa de cerca de 12/25 CPUs para lidar com o AD DS. Quando você traz a capacidade extra recomendada de 5% a 10% para processos em segundo plano, o servidor precisa de 12,30 a 12,25 CPUs para suportar sua carga atual. As estimativas que antecipam o crescimento futuro tornam esse número ainda maior.
Quando ajustar pesos LDAP
Há determinados cenários em que você deve considerar o ajuste de LdapSrvWeight. No contexto do planejamento de capacidade, você o ajustaria quando seus aplicativos, cargas de usuário ou recursos subjacentes do sistema não estivessem equilibrados uniformemente.
As seções a seguir descrevem dois cenários de exemplo em que você deve ajustar os pesos do LDAP (Lightweight Directory Access Protocol).
Exemplo 1: ambiente do emulador PDC
Se você estiver usando um emulador de PDC (Controlador de Domínio Primário), o comportamento do usuário ou do aplicativo distribuído de forma desigual poderá afetar vários ambientes ao mesmo tempo. Os recursos de CPU no emulador PDC geralmente são mais demandados do que em qualquer outro lugar na implantação porque várias ferramentas e ações são direcionadas a ele, como ferramentas de gerenciamento de Diretiva de Grupo, segundas tentativas de autenticação, estabelecimento de confiança e assim por diante.
- Você deve ajustar seu emulador PDC somente se houver uma diferença perceptível na utilização da CPU. O ajuste deve reduzir a carga no emulador PDC e aumentar a carga em outros DCs, permitindo uma distribuição de carga mais uniforme.
- Nesses casos, defina o valor para
LDAPSrvWeightentre 50 e 75 para o emulador PDC.
| Sistema | Utilização da CPU com padrões | New LdapSrvWeight | Nova utilização da CPU estimada |
|---|---|---|---|
| DC 1 (Emulador de PDC) | 53% | 57 | 40% |
| DC 2 | 33% | 100 | 40% |
| DC 3 | 33% | 100 | 40% |
O problema é que, se a função de emulador PDC for transferida ou apreendida, especialmente para outro controlador de domínio no site, a utilização da CPU aumentará drasticamente no novo emulador PDC.
Neste cenário de exemplo, supomos com base no perfil de comportamento do site de destino que todos os três controladores de domínio neste site tenham quatro CPUs. Em condições normais, o que aconteceria se um desses DCs tivesse oito CPUs? Haveria dois CDs com 40% de utilização e um com 20% de utilização. Embora essa configuração não seja necessariamente ruim, há uma oportunidade aqui para você usar o ajuste de peso LDAP para equilibrar melhor a carga.
Exemplo 2: ambiente com diferentes contagens de CPU
Quando você tem servidores com diferentes contagens e velocidades de CPU no mesmo site, você precisa garantir que eles estejam distribuídos uniformemente. Por exemplo, se o seu site tiver dois servidores de oito núcleos e um servidor de quatro núcleos, o servidor de quatro núcleos terá apenas metade do poder de processamento dos outros dois servidores. Se a carga do cliente for distribuída uniformemente, isso significa que o servidor de quatro núcleos precisa trabalhar duas vezes mais do que os dois servidores de oito núcleos para gerenciar sua carga de CPU. Além disso, se um dos servidores de oito núcleos ficar offline, o servidor de quatro núcleos ficará sobrecarregado.
| Sistema | Informações do processador\ % Utilitário do processador(_Total) Utilização da CPU com padrões |
New LdapSrvWeight | Nova utilização da CPU estimada |
|---|---|---|---|
| 4-CPU DC 1 | 40 | 100 | 30% |
| 4-CPU DC 2 | 40 | 100 | 30% |
| 8-CPU DC 3 | 20 | 200 | 30% |
O planejamento de um cenário "N+ 1" é de suma importância. O impacto de um DC ficando offline deve ser calculado para cada cenário. No cenário imediatamente anterior, em que a distribuição de carga é uniforme, para garantir uma carga de 60% durante um cenário "N", com a carga balanceada uniformemente em todos os servidores, a distribuição é boa, pois as taxas permanecem consistentes. Quando você olha para o cenário de ajuste do emulador PDC ou qualquer cenário geral em que a carga do usuário ou do aplicativo está desequilibrada, o efeito é muito diferente:
| Sistema | Utilização ajustada | New LdapSrvWeight | Nova utilização estimada |
|---|---|---|---|
| DC 1 (Emulador de PDC) | 40% | 85 | 47% |
| DC 2 | 40% | 100 | 53% |
| DC 3 | 40% | 100 | 53% |
Considerações sobre virtualização para processamento
Quando você está planejando a capacidade de um ambiente virtualizado, há dois níveis que você precisa considerar: o nível do host e o nível do convidado. No nível do host, você deve identificar os períodos de pico do seu ciclo de negócios. Como o agendamento de threads de convidado na CPU para uma máquina virtual é semelhante à obtenção de threads do AD DS na CPU para um computador físico, ainda recomendamos que você use de 40% a 60% do host subjacente. No nível do convidado, como os princípios subjacentes de agendamento de threads permanecem inalterados, também recomendamos que você mantenha o uso da CPU dentro do intervalo de 40% a 60%.
Em um cenário mapeado diretamente com um convidado por host, você deve trazer todas as estimativas de planejamento de capacidade feitas nas seções anteriores para fazer sua estimativa. Para um cenário de host compartilhado, há cerca de 10% de impacto na eficiência dos processadores subjacentes, o que significa que, se um site precisar de 10 CPUs em uma meta de 40%, o número recomendado de CPUs virtuais que você deve alocar em todos os N convidados seria 11. Em sites com distribuições mistas de servidores físicos e virtuais, esse modificador se aplica apenas às VMs (máquinas virtuais). Por exemplo, em um cenário N + 1, um servidor físico ou mapeado diretamente com 10 CPUs é quase igual a um convidado com 11 CPUs em um host com mais 11 CPUs reservadas para o DC.
Enquanto você está analisando e calculando quantas CPUs você precisa para suportar a carga do AD DS, lembre-se de que, se você planeja comprar hardware físico, os tipos de hardware disponíveis no mercado podem não ser mapeados exatamente de acordo com suas estimativas. No entanto, você não tem esse problema ao usar a virtualização. O uso de VMs diminui o esforço necessário para adicionar capacidade de computação a um site, pois você pode adicionar quantas CPUs com as especificações exatas desejar a uma VM. No entanto, a virtualização não elimina sua responsabilidade de avaliar com precisão quanta capacidade de computação você precisa para garantir que seu hardware subjacente esteja disponível quando os convidados precisarem de mais CPU. Como sempre, lembre-se de planejar com antecedência o crescimento.
Exemplo de resumo de cálculo de virtualização
| Sistema | CPU de pico |
|---|---|
| DC 1 | 120% |
| DC 2 | 147% |
| DC 3 | 218% |
| Uso total da CPU | 485% |
| Contagem de sistemas de destino | Largura de banda total (acima) |
|---|---|
| CPUs necessárias em 40% dos destinos | 4.85 ÷ .4 = 12.25 |
Ao planejar com antecedência o crescimento neste cenário, se você assumir que a demanda crescerá 50% nos próximos três anos, você precisa ter certeza de que tem 18.375 CPUs (12.25 × 1.5) nesse momento. Como alternativa, você pode revisar a demanda após o primeiro ano e, em seguida, adicionar capacidade extra com base no que os resultados indicam.
Carga de autenticação de cliente entre relações de confiança para NTLM
Avaliação da carga de autenticação de cliente entre relações de confiança
Muitos ambientes podem ter um ou mais domínios conectados por uma relação de confiança. As solicitações de autenticação para identidades em outros domínios que não usam Kerberos precisam atravessar uma relação de confiança usando um canal seguro entre dois controladores de domínio. O controlador de domínio que o usuário está tentando acessar no site se conecta a outro controlador de domínio localizado no domínio de destino ou em algum lugar mais adiante no caminho em direção ao domínio de destino. Quantas chamadas o controlador de domínio pode fazer para o outro controlador de domínio no domínio confiável é controlada pela configuração *MaxConcurrentAPI. Para garantir que o canal seguro possa lidar com a quantidade de carga necessária para que os DCs se comuniquem entre si, você pode ajustar MaxConcurrentAPI ou, se estiver em uma floresta, criar relações de confiança de atalho. Saiba mais sobre como determinar o volume de tráfego entre relações de confiança em Como fazer o ajuste de desempenho para autenticação NTLM usando a configuração MaxConcurrentApi.
Assim como nos cenários anteriores, você deve coletar dados durante os períodos de pico do dia para que sejam úteis.
Observação
Cenários intrafloresta e interfloresta podem fazer com que a autenticação atravesse várias relações de confiança, o que significa que você precisa ajustar durante cada estágio do processo.
Planejamento da virtualização
Há algumas coisas que você deve ter em mente ao planejar a capacidade para virtualização:
- Muitos aplicativos usam a autenticação NTLM (Network Level Trust Manager) por padrão ou em determinadas configurações.
- À medida que o número de clientes ativos aumenta, também aumenta a necessidade de os servidores de aplicativos terem mais capacidade.
- Às vezes, os clientes mantêm as sessões abertas por um tempo limitado e, em vez disso, se reconectam regularmente para serviços como sincronização de e-mail.
- Os servidores proxy da Web que exigem autenticação para acesso à Internet podem causar alta carga NTLM.
Esses aplicativos podem criar uma grande carga para autenticação NTLM, o que coloca um estresse significativo nos DCs, especialmente quando usuários e recursos estão em domínios diferentes.
Há muitas abordagens que você pode adotar para gerenciar a carga de confiança cruzada, que muitas vezes você pode e deve usar em conjunto ao mesmo tempo:
- Reduza a autenticação de cliente de confiança cruzada localizando os serviços que um usuário consome no domínio em que está localizado.
- Aumente o número de canais seguros disponíveis. Esses canais são chamados de relações de confiança de atalho e são relevantes para o tráfego intrafloresta e entre florestas.
- Ajuste as configurações padrão para MaxConcurrentAPI.
Para ajustar MaxConcurrentAPI em um servidor existente, use a seguinte equação:
New_MaxConcurrentApi_setting ≥ (semaphore_acquires + semaphore_time-outs) × average_semaphore_hold_time ÷ time_collection_length
Para saber mais, confira Artigo da KB 2688798: como fazer o ajuste de desempenho para autenticação NTLM usando a configuração MaxConcurrentApi.
Considerações sobre virtualização
Não há considerações especiais que você precise fazer, pois a virtualização é uma configuração de ajuste do sistema operacional.
Exemplo de cálculo de ajuste de virtualização
| Data type | Valor |
|---|---|
| Aquisições de semáforo (mínimo) | 6,161 |
| Aquisições de semáforo (máximo) | 6,762 |
| Tempos limite de semáforo | 0 |
| Tempo médio de espera do semáforo | 0,012 |
| Duração da coleta (segundos) | 1:11 minutos (71 segundos) |
| Fórmula (da KB 2688798) | ((6762 - 6161) + 0) × 0.012 / |
| Valor mínimo para MaxConcurrentAPI | ((6762 - 6161) + 0) × 0.012 ÷ 71 = .101 |
Para esse sistema nesse período, os valores padrão são aceitáveis.
Monitoramento para cumprimento das metas de planejamento da capacidade
Ao longo deste artigo, discutimos como o planejamento e o dimensionamento estão direcionados às metas de utilização. A tabela a seguir resume os limites recomendados que você deve monitorar para garantir que os sistemas estejam operando conforme o esperado. Lembre-se de que esses não são limites de desempenho, apenas limites de planejamento de capacidade. Um servidor operando além desses limites ainda funcionará, mas você precisa validar se seus aplicativos estão funcionando conforme o esperado antes de começar a ver problemas de desempenho à medida que a demanda do usuário aumenta. Se os aplicativos estiverem corretos, você deve começar a avaliar as atualizações de hardware ou outras alterações de configuração.
| Categoria | Contador de desempenho | Intervalo/amostragem | Destino | Aviso |
|---|---|---|---|---|
| Processador | Processor Information(_Total)\% Processor Utility |
60 min | 40% | 60% |
| RAM (Windows Server 2008 R2 ou anterior) | Memória/MB disponível | < 100 MB | N/D | < 100 MB |
| RAM (Windows Server 2012) | Memória\Tempo de vida médio do cache(s) Em espera de longo prazo | 30 min | Deve ser testado | Deve ser testado |
| Rede | Adaptador de rede(*)/Bytes enviados/s Adaptador de rede(*)/Bytes recebidos/s |
30 min | 40% | 60% |
| Armazenamento | LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/ReadLogicalDisk(( |
60 min | 10 ms | 15 ms |
| Serviços do AD | Netlogon(*)\Tempo médio de espera do semáforo | 60 min | 0 | 1 segundo |
Apêndice A: critérios de dimensionamento da CPU
Este apêndice discute termos e conceitos úteis que podem ajudá-lo a estimar as necessidades de dimensionamento de CPU do seu ambiente.
Definições: dimensionamento da CPU
Um processador (microprocessador) é um componente que lê e executa instruções de programa.
Um processador multicore tem várias CPUs no mesmo circuito integrado.
Um sistema com várias CPUs tem várias CPUs que não estão no mesmo circuito integrado.
Um processador lógico é um processador que possui apenas um mecanismo de computação lógica da perspectiva do sistema operacional.
Essas definições incluem hyper-threaded, um núcleo no processador multi-core ou um processador single core.
Como os sistemas de servidor atuais têm vários processadores, vários processadores multi-core e hyper-threading, essas definições são generalizadas para cobrir ambos os cenários. Usamos o termo "processador lógico" porque ele representa a perspectiva do sistema operacional e do aplicativo dos mecanismos de computação disponíveis.
Paralelismo no nível do thread
Cada thread é uma tarefa independente, pois cada thread tem sua própria pilha e instruções. O AD DS é multi-threaded, e você pode ajustar o número de threads disponíveis seguindo as instruções em Como exibir e definir a política LDAP no Active Directory usando Ntdsutil.exe, ele é bem dimensionado em vários processadores lógicos.
Paralelismo no nível de dados
O paralelismo no nível de dados é quando um serviço compartilha dados entre muitos threads para o mesmo processo e compartilha muitos threads em vários processos. O processo do AD DS sozinho contaria como um serviço que compartilha dados em vários threads para um único processo. Todas as alterações nos dados são refletidas em todos os threads em execução em todos os níveis do cache, em todos os núcleos e em todas as atualizações na memória compartilhada. O desempenho pode diminuir durante as operações de gravação porque todos os locais de memória se ajustam às alterações antes que o processamento da instrução possa continuar.
Velocidade da CPU x considerações de vários núcleos
Geralmente, processadores lógicos mais rápidos reduzem o tempo necessário para processar uma série de instruções. Mais processadores lógicos significam que você pode executar mais tarefas ao mesmo tempo. No entanto, essas regras não se aplicam a cenários mais complexos, como buscar dados da memória compartilhada, aguardar o paralelismo no nível dos dados e a sobrecarga de gerenciar vários threads ao mesmo tempo. Como resultado, a escalabilidade em sistemas multi-core não é linear.
Para entender por que essa mudança acontece, é útil pensar nesses cenários como uma rodovia. Cada thread é um carro individual, cada pista é um núcleo e o limite de velocidade é a velocidade do clock.
Se houver apenas um carro na estrada, não importa se há 2 ou 12 pistas. A velocidade desse carro segue o limite permitido.
Se os dados de que o thread precisa não estiverem disponíveis imediatamente, o thread não poderá processar instruções até buscar os dados relevantes da memória. É como se um segmento da rodovia fosse fechado. Mesmo que haja apenas um carro na rodovia, o limite de velocidade não afetará sua capacidade de viajar, porque ele não pode ir a lugar nenhum até que a estrada seja reaberta.
À medida que o número de carros aumenta, a sobrecarga que a rodovia precisa para gerenciar o número de carros também aumenta. Os motoristas precisam se concentrar mais ao dirigir na estrada durante o trânsito da hora do rush, em oposição ao final da noite, quando a estrada está quase vazia. Além disso, dirigir em uma rodovia de duas pistas, em que você só precisa se preocupar com uma outra faixa, requer menos foco do que dirigir em uma rodovia de seis pistas, onde você tem cinco outras faixas de tráfego para prestar atenção.
Em resumo, as perguntas sobre se você deve adicionar mais processadores ou processadores mais rápidos foram altamente subjetivas e devem ser consideradas caso a caso. Para o AD DS em particular, as necessidades de processamento dependem de fatores ambientais e podem variar de servidor para servidor em um único ambiente. Como resultado, as seções anteriores deste artigo não investiram muito em fazer cálculos super precisos. Ao tomar decisões de compra orientadas pelo orçamento, recomendamos que você primeiro otimize o uso do processador em 40% ou em qualquer número que seu ambiente específico exigir. Se o seu sistema não estiver otimizado, você não se beneficiará tanto com a compra de processadores adicionais.
Observação
A Lei de Amdahl e a Lei de Gustafson são os conceitos relevantes.
Tempo de resposta e como os níveis de atividade do sistema afetam o desempenho
A teoria das filas é o estudo matemático das filas de espera ou filas. Na teoria das filas para computação, a lei de utilização é representada pela equação t:
U k = B ÷ T
Em que U k é a porcentagem de utilização, B é a quantidade de tempo gasto ocupado e T é o tempo total gasto observando o sistema. Em um contexto da Microsoft, isso significa o número de threads de intervalo de 100 nanossegundos (ns) que estão em um estado em execução dividido por quantos intervalos de 100 ns estavam disponíveis no intervalo de tempo especificado. Essa é a mesma fórmula que calcula a porcentagem de utilização do processador mostrada em Objeto do processador e PERF_100NSEC_TIMER_INV.
A teoria das filas também fornece a fórmula: N = U k ÷ (1 - U k) para estimar o número de itens em espera com base na utilização, em que N é o comprimento da fila. O gráfico dessa equação em todos os intervalos de utilização fornece as estimativas a seguir de tempo de fila para entrar no processador em qualquer carga de CPU.
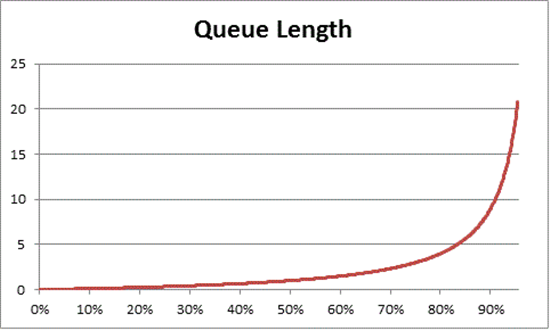
Com base nessa estimativa, podemos observar que, após 50% de carga da CPU, a espera média geralmente inclui um outro item na fila e aumenta rapidamente para 70% de utilização da CPU.
Para entender como a teoria do enfileiramento se aplica à implantação do AD DS, vamos retornar à metáfora da rodovia que usamos em Considerações sobre a velocidade da CPU x considerações de vários núcleos.
Os horários mais movimentados no meio da tarde cairiam em algum lugar na faixa de capacidade de 40% a 70%. Há tráfego suficiente para que sua capacidade de escolher uma faixa para dirigir não seja severamente restrita. Embora a chance de outro motorista atrapalhar seja alta, ainda não é preciso fazer o mesmo esforço para encontrar uma lacuna segura entre outros carros na pista, como acontece durante a hora do rush.
À medida que a hora do rush se aproxima, o sistema viário se aproxima de 100% da capacidade. Mudar de faixa durante a hora do rush é muito desafiador porque os carros estão tão próximos que você não tem tanto espaço de manobra ao mudar de faixa.
É por isso que estimar médias de longo prazo para capacidade em 40% permite mais espaço para picos de carga anormais, sejam esses picos transitórios, como consultas mal codificadas que demoram um pouco para serem executadas ou intermitências anormais na carga geral, como o pico de atividade na manhã seguinte a um fim de semana de feriado.
A declaração anterior considera o cálculo da porcentagem do tempo do processador como sendo o mesmo que a equação da lei de utilização. Esta versão simplificada destina-se a apresentar o conceito a novos usuários. No entanto, para matemática mais avançada, você pode usar as seguintes referências como guia:
- Traduzindo o PERF_100NSEC_TIMER_INV
- B = O número de intervalos de 100 ns que o thread ocioso gasta no processador lógico. A alteração na variável X no cálculo de PERF_100NSEC_TIMER_INV
- T = o número total de intervalos de 100 ns em um determinado intervalo de tempo. A alteração na variável Y no cálculo de PERF_100NSEC_TIMER_INV.
- U k = A porcentagem de utilização do processador lógico pelo thread ocioso ou % de tempo ocioso.
- Estimando os cálculos:
- U k = 1 – %Processor Time
- %Processor Time = 1 – U k
- %Processor Time = 1 – B / T
- %Processor Time = 1 – X1 – X0 / Y1 – Y0
Aplicar esses conceitos ao planejamento de capacidade
A matemática na seção anterior provavelmente faz com que determinar quantos processadores lógicos você precisa em um sistema pareça muito complexo. Como resultado, sua abordagem para dimensionar o sistema deve se concentrar em determinar a utilização máxima alvo com base na carga atual e, em seguida, calcular o número de processadores lógicos necessários para atingir essa meta. Além disso, sua estimativa não precisa ser perfeitamente exata. Embora as velocidades do processador lógico tenham um impacto significativo na sincronização, o desempenho também pode ser afetado por outras áreas:
- Eficiência de cache
- Requisitos de coerência de memória
- Agendamento e sincronização de threads
- Cargas de cliente balanceadas com defeito
Como o poder de computação é relativamente baixo, não vale a pena investir muito tempo no cálculo do número perfeitamente exato de CPUs de que você precisa.
Também é importante lembrar que a recomendação de 40%, neste caso, não é um requisito obrigatório. Nós o usamos como um começo razoável para fazer cálculos. Diferentes tipos de usuários do AD precisam de diferentes níveis de capacidade de resposta. Pode até haver cenários em que os ambientes podem ser executados com 80% ou até 90% de utilização em uma média sustentada sem que o aumento dos tempos de espera para acesso ao processador afete visivelmente o desempenho do cliente.
Existem também outras áreas no sistema que são muito mais lentas do que o processador lógico que você também deve ajustar, incluindo acesso à RAM, acesso ao disco e transmissão de respostas pela rede. Por exemplo:
Se você adicionar processadores a um sistema executado com 90% de utilização vinculada ao disco, isso provavelmente não melhorará significativamente o desempenho. Se você observar o sistema mais de perto, há muitos threads que nem estão entrando no processador porque estão aguardando a conclusão das operações de E/S.
Resolver problemas associados ao disco pode significar que os threads anteriormente presos no estado de espera deixaram de ficar presos, criando mais competição pelo tempo de CPU. Como resultado, a utilização de 90% passará para 100%. Você precisa ajustar ambos os componentes para reduzir a utilização a níveis gerenciáveis.
Observação
O contador
Processor Information(*)\% Processor Utilitypode exceder 100% com sistemas que possuem um modo Turbo. O modo Turbo permite que a CPU exceda a velocidade nominal do processador por curtos períodos. Se precisar de mais informações, consulte a documentação dos fabricantes da CPU e as descrições dos contadores.
A discussão de considerações de utilização de todo o sistema também envolve controladores de domínio como convidados virtualizados. O tempo de resposta e como os níveis de atividade do sistema afetam o desempenho se aplicam ao host e ao convidado em um cenário virtualizado. Em um host com apenas um convidado, um DC ou sistema tem quase o mesmo desempenho que teria em hardware físico. Adicionar mais convidados aos hosts aumenta a utilização do host subjacente, aumentando também os tempos de espera para ter acesso aos processadores. Portanto, você deve gerenciar a utilização do processador lógico nos níveis de host e convidado.
Vamos revisitar a metáfora da rodovia das seções anteriores, só que desta vez vamos imaginar a VM convidada como um ônibus expresso. Os ônibus expressos, ao contrário do transporte público ou dos ônibus escolares, vão direto para o destino do passageiro sem fazer paradas.
Vamos imaginar quatro cenários:
- Os horários fora de pico de um sistema são como andar de ônibus expresso tarde da noite. Quando o motociclista entra, quase não há outros passageiros e a estrada está quase vazia. Como o ônibus não precisa enfrentar trânsito, a corrida é fácil e tão rápida quanto se o passageiro tivesse dirigido até lá em seu próprio carro. No entanto, o tempo de viagem do passageiro também é limitado pelo limite de velocidade local.
- Fora do horário de pico, quando a utilização da CPU de um sistema é muito alta, é como uma corrida noturna quando a maioria das pistas da rodovia está fechada. Mesmo que o ônibus em si esteja quase vazio, a estrada ainda está congestionada por causa do trânsito restante devido às faixas restritas. Embora o passageiro seja livre para se sentar onde quiser, o tempo real da viagem é determinado pelo trânsito fora do ônibus.
- Um sistema com alta utilização da CPU durante os horários de pico é como um ônibus lotado na hora do rush. Não só a viagem demora mais, mas entrar e sair do ônibus é mais difícil porque o ônibus está lotado de outros passageiros. Adicionar mais processadores lógicos ao sistema convidado para tentar acelerar os tempos de espera seria como tentar resolver o problema de trânsito adicionando mais ônibus. O problema não é o número de ônibus, mas quanto tempo leva a viagem.
- Um sistema com alta utilização da CPU fora do horário de pico é como o mesmo ônibus lotado em uma estrada quase vazia à noite. Embora os passageiros possam ter problemas para encontrar assentos ou entrar e sair do ônibus, a viagem é bastante tranquila quando o ônibus pega todos os passageiros. Esse cenário é o único em que o desempenho melhoraria adicionando mais ônibus.
Com base nos exemplos anteriores, você pode ver que há muitos cenários entre 0% e 100% de utilização que têm graus variados de impacto no desempenho. Além disso, adicionar mais processadores lógicos não melhora necessariamente o desempenho fora de cenários muito específicos. Deve ser bastante simples aplicar esses princípios à meta recomendada de 40% de utilização da CPU para hosts e convidados.
Apêndice B: considerações sobre diferentes velocidades de processadores
No processamento, assumimos que o processador está sendo executado a 100% da velocidade do clock enquanto você coleta dados e que todos os sistemas de substituição têm a mesma velocidade de processamento. Apesar dessas suposições não serem precisas, especialmente para Windows Server 2008 R2 e versões posteriores, em que o plano de energia padrão é equilibrado, essas suposições ainda funcionam para estimativas conservadoras. Embora os possíveis erros possam aumentar, apenas a margem de segurança aumenta à medida que as velocidades do processador aumentam.
- Por exemplo, em um cenário que exige 11,25 CPUs, se os processadores funcionassem na metade da velocidade em que você coletou seus dados, a estimativa mais precisa de sua demanda seria 5,125 ÷ 2.
- É impossível garantir que dobrar a velocidade do clock dobre a quantidade de processamento que ocorre dentro do período de tempo registrado. A quantidade de tempo que os processadores gastam esperando pela RAM ou outros componentes permanece praticamente a mesma. Portanto, processadores mais rápidos podem gastar uma porcentagem maior de tempo ocioso enquanto aguardam o sistema buscar dados. Recomendamos que você fique com o menor denominador comum, mantenha suas estimativas conservadoras e evite presumir uma comparação linear entre as velocidades do processador que possa tornar seus resultados incorretos.
Se as velocidades do processador no hardware de substituição forem menores do que no hardware atual, você deverá aumentar proporcionalmente a estimativa de quantos processadores são necessários. Por exemplo, vejamos um cenário em que você calcula que são necessários 10 processadores para sustentar a carga do seu site. Os processadores atuais rodam a 3,3 GHz, e os processadores pelos quais você pretende substituí-los rodam a 2,6 GHz. Substituir apenas os 10 processadores originais daria a você uma redução de 21% na velocidade. Para aumentar a velocidade, você precisa obter pelo menos 12 processadores em vez de 10.
No entanto, essa variabilidade não altera as metas de utilização do processador de gerenciamento de capacidade. As velocidades do clock do processador se ajustam dinamicamente com base na demanda de carga, portanto, executar o sistema sob cargas mais altas faz com que a CPU passe mais tempo em um estado de velocidade de clock mais alto. O objetivo final é que a CPU tenha 40% de utilização em um estado de velocidade de clock de 100% durante o horário comercial de pico. Menos do que isso gerará economia de energia ao limitar as velocidades da CPU durante cenários fora de pico.
Observação
Você pode desativar o gerenciamento de energia nos processadores durante a coleta de dados definindo o plano de energia como Alto desempenho. Desativar o gerenciamento de energia fornece leituras mais precisas do consumo de CPU no servidor de destino.
Para ajustar as estimativas para diferentes processadores, recomendamos que você use o benchmark SPECint_rate2006 da Standard Performance Evaluation Corporation. Para usar esse benchmark:
Acesse o site da Standard Performance Evaluation Corporation (SPEC).
Selecione Resultados.
Digite CPU2006 e selecione Pesquisar.
No menu suspenso de Configurações disponíveis, selecione Todas as CPU2006 SPEC.
No campo Pesquisar solicitação de formulário, selecione Simples e, em seguida, selecione Agora!.
Em Solicitação simples, insira os critérios de pesquisa para o processador de destino. Por exemplo, se estiver à procura de um processador ES-2630, no menu suspenso, selecione Processador e, em seguida, insira o nome do processador no campo de pesquisa. Quando terminar, selecione Executar busca simples.
Procure a configuração do servidor e do processador nos resultados da pesquisa. Se o mecanismo de pesquisa não retornar uma correspondência exata, procure a correspondência mais próxima possível.
Registre os valores nas colunas Resultado e # Núcleos.
Determine o modificador usando esta equação:
((Valor da pontuação por núcleo da plataforma de destino) × (MHz por núcleo da plataforma de linha de base)) ÷ ((valor de pontuação de linha de base por núcleo) × (MHz por núcleo da plataforma de destino))
Por exemplo, veja como você encontraria o modificador para um processador ES-2630:
(35.83 × 2000) ÷ (33.75 × 2300) = 0.92
Multiplique o número de processadores que você estima que precisa com este modificador.
Para o exemplo do processador ES-2630, 0,92 × 10,3 = 10,35 processadores.
Apêndice C: como o sistema operacional interage com o armazenamento
Os conceitos da teoria de enfileiramento discutidos em Tempo de resposta e como os níveis de atividade do sistema afetam o desempenho também se aplicam ao armazenamento. Você precisa se familiarizar com a forma como seu sistema operacional lida com a E/S para aplicar esses conceitos de forma eficaz. Nos sistemas operacionais Windows, o sistema operacional cria uma fila que contém solicitações de E/S para cada disco físico. No entanto, um disco físico não é necessariamente um único disco. O sistema operacional também pode registrar uma agregação de eixos em um controlador de matriz ou SAN como um disco físico. Os controladores de matriz e SANs também podem agregar vários discos em um único conjunto de matrizes, dividi-lo em várias partições e usar cada partição como um disco físico, conforme mostrado na imagem a seguir.
Nesta ilustração, os dois eixos são espelhados e divididos em áreas lógicas para armazenamento de dados, rotulados como Dados 1 e Dados 2. O sistema operacional registra cada uma dessas áreas lógicas como discos físicos separados.
Agora que esclarecemos o que define um disco físico, você também deve se familiarizar com os termos a seguir para entender melhor as informações deste Apêndice.
- Um eixo é o dispositivo fisicamente instalado no servidor.
- Uma matriz é uma coleção de eixos agregados pelo controlador.
- Uma partição de matriz é um particionamento da matriz agregada.
- Um LUN (Número de Unidade Lógica) é uma matriz de dispositivos SCSI conectados a um computador. Este artigo usa esses termos ao falar sobre SANs.
- Um disco inclui qualquer eixo ou partição que o sistema operacional registra como um único disco físico.
- Uma partição é um particionamento lógico do que o sistema operacional registra como um disco físico.
Considerações sobre arquitetura de sistema operacional
O sistema operacional cria uma fila de E/S FIFO (First In, First Out) para cada disco registrado. Esses discos podem ser eixos, matrizes ou partições de matriz. Quando se trata de como o sistema operacional lida com E/S, quanto mais filas ativas, melhor. Quando o sistema operacional serializa a fila FIFO, ele deve processar todas as solicitações de E/S FIFO emitidas para o subsistema de armazenamento em ordem de chegada. Quando o sistema operacional correlaciona cada disco com um eixo ou matriz, ele mantém uma fila de E/S para cada conjunto exclusivo de discos, eliminando a competição por recursos escassos de E/S entre os discos e isolando a demanda de E/S em um único disco. No entanto, o Windows Server 2008 introduziu uma exceção na forma de priorização de E/S. Os aplicativos projetados para usar E/S de baixa prioridade são movidos para o final da fila, independentemente de quando o sistema operacional os recebeu. Os aplicativos não codificados especificamente para usar a configuração de baixa prioridade possuem prioridade normal como padrão.
Introdução aos subsistemas de armazenamento simples
Nesta seção, falamos sobre subsistemas de armazenamento simples. Vamos começar com um exemplo: um único disco rígido dentro de um computador. Se dividirmos esse sistema em seus principais componentes do subsistema de armazenamento, vamos obter o seguinte:
- Um HD SCSI ultrarrápido de 10.000 RPM (o SCSI ultrarrápido tem uma taxa de transferência de 20 MBps)
- Um barramento SCSI (o cabo)
- Um adaptador SCSI ultrarrápido
- Um barramento PCI de 32 bits e 33 MHz
Observação
Este exemplo não reflete o cache de disco em que o sistema normalmente mantém os dados de um cilindro. Nesse caso, a primeira E/S precisa de 10 ms, e o disco lê todo o cilindro. Todas as outras E/Ss sequenciais são satisfeitas pelo cache. Como resultado, os caches em disco podem melhorar o desempenho sequencial de E/S.
Depois de identificar os componentes, você pode começar a ter uma ideia da quantidade de dados que o sistema pode transmitir e quanta E/S ele pode suportar. A quantidade de E/S e a quantidade de dados que podem transitar pelo sistema estão relacionadas entre si, mas não têm o mesmo valor. Essa correlação depende do tamanho do bloco e de a E/S do disco ser aleatória ou sequencial. O sistema grava todos os dados no disco como um bloco, mas aplicativos diferentes podem usar tamanhos de bloco diferentes.
Em seguida, vamos analisar esses itens componente por componente.
Momentos de acesso ao disco rígido
O disco rígido médio de 10.000 RPM tem um tempo de busca de 7 ms e um tempo de acesso de 3 ms. O tempo de busca é a quantidade média de tempo que o cabeçote de leitura ou gravação leva para se mover para um local no prato. O tempo de acesso é a quantidade média de tempo que leva para o cabeçote ler ou gravar os dados no disco, uma vez que está no local correto. Portanto, o tempo médio para ler um bloco único de dados em um HD de 10.000 RPM inclui tempos de busca e acesso para um total de aproximadamente 10 ms ou 0,010 segundo por bloco de dados.
Quando cada acesso ao disco exige que o cabeçote se mova para um novo local no disco, o comportamento de leitura ou gravação é chamado de aleatório. Quando todas as E/S são aleatórias, um HD de 10.000 RPM pode suportar aproximadamente 100 E/S por segundo (IOPS).
Quando todas as E/S ocorrem de setores adjacentes no disco rígido, chamamos de E/S sequencial. A E/S sequencial não tem tempo de busca porque, após a conclusão da primeira E/S, o cabeçote de leitura ou gravação está no início de onde o disco rígido está armazenando o próximo bloco de dados. Por exemplo, um HD de 10.000 RPM é capaz de suportar aproximadamente 333 E/S por segundo, com base na seguinte equação:
1.000 ms por segundo ÷ 3 ms por E/S
Até agora, a taxa de transferência do disco rígido não foi relevante para o nosso exemplo. Não importa o tamanho do disco rígido, a quantidade real de IOPS que o HD de 10.000 RPM pode suportar é sempre de cerca de 100 E/S aleatórias ou 300 sequenciais. À medida que os tamanhos dos blocos mudam com base em qual aplicativo está gravando na unidade, a quantidade de dados extraídos por E/S também muda. Por exemplo, se o tamanho do bloco for de 8 KB, 100 operações de E/S lerão ou gravarão no disco rígido um total de 800 KB. No entanto, se o tamanho do bloco for de 32 KB, 100 E/S lerão ou gravarão 3.200 KB (3,2 MB) no disco rígido. Se a taxa de transferência SCSI exceder a quantidade total de dados transferidos, obter uma taxa de transferência mais rápida não mudará nada. Para obter mais informações, confira as tabelas a seguir:
| Descrição | busca de 7.200 RPM e 9 ms, acesso de 4 ms | busca de 10.000 RPM e 7 ms, acesso de 3 ms | busca de 15.000 RPM e 4 ms, acesso de 2 ms |
|---|---|---|---|
| E/S Aleatória | 80 | 100 | 150 |
| E/S Sequencial | 250 | 300 | 500 |
| Unidade de 10.000 RPM | Tamanho do bloco de 8 KB (Jet do Active Directory) |
|---|---|
| E/S Aleatória | 800 KB/s |
| E/S Sequencial | 2400 KB/s |
O backplane SCSI
A forma como o backplane SCSI, que neste cenário de exemplo é o cabo chato, afeta a taxa de transferência do subsistema de armazenamento depende do tamanho do bloco. Quanta E/S o barramento pode suportar se a E/S estiver em blocos de 8 KB? Nesse cenário, o barramento SCSI é de 20 MBps ou 20.480 KB/s. 20480 KB/s divididos em blocos de 8 KB produz um máximo de aproximadamente 2.500 IOPS compatíveis com o barramento SCSI.
Observação
As figuras na tabela a seguir representam um cenário de exemplo. Atualmente, a maioria dos dispositivos de armazenamento conectados usa o PCI Express, que fornece uma taxa de transferência muito maior.
| E/S compatível com o barramento SCSI por tamanho de bloco | Tamanho do bloco de 2 KB | Tamanho do bloco de 8 KB (AD Jet) (SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20 Mbps | 10.000 | 2\.500 |
| 40 MBps | 20,000 | 5\.000 |
| 128 MBps | 65.536 | 16.384 |
| 320 MBps | 160.000 | 40.000 |
Como mostra a tabela anterior, em nosso cenário de exemplo, o barramento nunca é um gargalo porque o máximo do eixo é de 100 E/S, muito abaixo de qualquer um dos limites listados.
Observação
Nesse cenário, estamos assumindo que o barramento SCSI é 100% eficiente.
O adaptador SCSI
Para determinar quanta E/S o sistema pode suportar, você deve verificar as especificações do fabricante. Direcionar solicitações de E/S para o dispositivo apropriado requer poder de processamento, portanto, a quantidade de E/S que o sistema pode suportar depende do adaptador SCSI ou do processador do controlador de matriz.
Neste cenário de exemplo, estamos supondo que o sistema possa lidar com 1.000 E/S.
O barramento PCI
O barramento PCI é um componente frequentemente esquecido. Neste cenário de exemplo, o barramento PCI não é o gargalo. No entanto, à medida que os sistemas são expandidos, isso pode se tornar um gargalo no futuro.
Podemos ver o quanto um barramento PCI pode transferir dados em nosso cenário de exemplo usando esta equação:
32 bits ÷ 8 bits por byte × 33 MHz = 133 MBps
Portanto, podemos supor que um barramento PCI de 32 bits operando a 33 Mhz pode transferir 133 MBps de dados.
Observação
O resultado dessa equação representa o limite teórico dos dados transferidos. Na realidade, a maioria dos sistemas atinge apenas cerca de 50% do limite máximo. Em determinados cenários de intermitência, o sistema pode atingir 75% do limite por curtos períodos.
Um barramento PCI de 64 bits e 66 MHz pode suportar um máximo teórico de 528 MBps com base nesta equação:
64 bits ÷ 8 bits por byte × 66 Mhz = 528 MBps
Quando você adiciona qualquer outro dispositivo, como um adaptador de rede ou um segundo controlador SCSI, ele reduz a largura de banda disponível para o sistema, pois todos os dispositivos compartilham a largura de banda e podem competir entre si por recursos de processamento limitados.
Analisar subsistemas de armazenamento para encontrar gargalos
Nesse cenário, o eixo é o fator limitante para a quantidade de E/S que você pode solicitar. Como resultado, esse gargalo também limita a quantidade de dados que o sistema pode transmitir. Como nosso exemplo é um cenário do AD DS, a quantidade de dados transmissíveis é de 100 E/S aleatórias por segundo em incrementos de 8 KB, para um total de 800 KB por segundo quando você acessa o banco de dados do Jet. Por outro lado, a taxa de transferência máxima para um eixo configurado para alocar exclusivamente em arquivos de log seria limitada a 300 E/S sequenciais por segundo em parcelas de 8 KB, totalizando 2.400 KB ou 2,4 MB por segundo.
Agora que analisamos os componentes de nossa configuração de exemplo, vamos analisar uma tabela que mostra onde os gargalos podem ocorrer à medida que adicionamos e alteramos componentes no subsistema de armazenamento.
| Observações | Análise de gargalo | Disco | Barramento | Adaptador | Barramento PCI |
|---|---|---|---|---|---|
| Essa é a configuração do controlador de domínio depois de adicionar um segundo disco. A configuração de disco representa o gargalo em 800 KB/s. | Adicionar um disco (Total=2) A E/S é aleatória Tamanho do bloco de 4 KB HD de 10.000 RPM |
E/S total de 200 800 KB/s total. |
|||
| Após adicionar sete discos, a configuração de disco ainda representa o gargalo em 3200 KB/s. | Adicionar sete discos (Total=8) A E/S é aleatória Tamanho do bloco de 4 KB HD de 10.000 RPM |
Total de E/S de 800. 3200 KB/s total |
|||
| Depois de alterar a E/S para sequencial, o adaptador de rede se torna o gargalo porque está limitado a 1000 IOPS. | Adicionar sete discos (Total=8) A E/S é sequencial Tamanho do bloco de 4 KB HD de 10.000 RPM |
E/S de 2400 sequenciais podem ser lidas/gravadas em disco, controlador limitado a 1000 IOPS | |||
| Depois de substituir o adaptador de rede por um adaptador SCSI que dá suporte a 10.000 IOPS, o gargalo retorna à configuração do disco. | Adicionar sete discos (Total=8) A E/S é aleatória Tamanho do bloco de 4 KB HD de 10.000 RPM Atualizar adaptador SCSI (agora dá suporte à E/S de 10.000) |
Total de E/S de 800. 3.200 KB/s total |
|||
| Depois de aumentar o tamanho do bloco para 32 KB, o barramento se torna o gargalo porque suporta apenas 20 MBps. | Adicionar sete discos (Total=8) A E/S é aleatória Tamanho do bloco de 32 KB HD de 10.000 RPM |
Total de E/S de 800. 25.600 KB/s (25 MBps) podem ser lidos/gravados no disco. O barramento suporta apenas 20 MBps |
|||
| Depois de atualizar o barramento e adicionar mais discos, o disco continua sendo o gargalo. | Adicionar 13 discos (Total=14) Adicionar o segundo adaptador SCSI com 14 discos A E/S é aleatória Tamanho do bloco de 4 KB HD de 10.000 RPM Atualizar para o barramento SCSI de 320 MBps |
E/S de 2.800 11.200 KB/s (10,9 MBps) |
|||
| Depois de alterar E/S para sequencial, o disco continua sendo o gargalo. | Adicionar 13 discos (Total=14) Adicionar o segundo adaptador SCSI com 14 discos A E/S é sequencial Tamanho do bloco de 4 KB HD de 10.000 RPM Atualizar para o barramento SCSI de 320 MBps |
E/S de 8.400 33.600 KB/s (32.8 MB/s) |
|||
| Após adicionar discos rígidos mais rápidos, o disco continua sendo o gargalo. | Adicionar 13 discos (Total=14) Adicionar o segundo adaptador SCSI com 14 discos A E/S é sequencial Tamanho do bloco de 4 KB HD de 15.000 RPM Atualizar para o barramento SCSI de 320 MBps |
E/S de 14.000 56.000 KB/s (54,7 MBps) |
|||
| Depois de aumentar o tamanho do bloco para 32 KB, o barramento PCI se torna o gargalo. | Adicionar 13 discos (Total=14) Adicionar o segundo adaptador SCSI com 14 discos A E/S é sequencial Tamanho do bloco de 32 KB HD de 15.000 RPM Atualizar para o barramento SCSI de 320 MBps |
E/S de 14.000 448.000 KB/s (437 MBps) é o limite de leitura/gravação do eixo. O barramento PCI suporta um máximo teórico de 133 MBps (75% de eficiência na melhor das hipóteses). |
Introdução ao RAID
Quando você introduz um controlador de matriz em seu subsistema de armazenamento, ele não muda drasticamente sua natureza. O controlador de matriz substitui apenas o adaptador SCSI nos cálculos. No entanto, o custo de leitura e gravação de dados no disco quando você usa os vários níveis de matriz muda.
No RAID 0, a gravação de dados os distribui em todos os discos do conjunto RAID. Durante uma operação de leitura ou gravação, o sistema extrai dados ou os envia para cada disco, aumentando a quantidade de dados que o sistema pode transmitir durante esse período de tempo específico. Portanto, neste exemplo em que estamos usando unidades de 10.000 RPM, o uso de RAID 0 permitiria que você executasse 100 operações de E/S. A quantidade total de E/S que o sistema suporta é de N eixos vezes 100 E/S por segundo por eixo ou N eixos × 100 E/S por segundo por eixo.

No RAID 1, o sistema espelha ou duplica dados em um par de eixos para redundância. Quando o sistema executa uma operação de leitura de E/S, ele pode ler dados de ambos os eixos no conjunto. Esse espelhamento disponibiliza a capacidade de E/S para ambos os discos durante uma operação de leitura. No entanto, o RAID 1 não oferece nenhuma vantagem de desempenho às operações de gravação, porque o sistema também precisa espelhar os dados gravados no par de eixos. Embora o espelhamento não faça com que as operações de gravação demorem mais, ele impede que o sistema faça mais de uma operação de leitura ao mesmo tempo. Portanto, cada operação de E/S de gravação custa duas operações de E/S de leitura.
A equação a seguir calcula quantas operações de E/S estão ocorrendo nesse cenário:
E/S de leitura + 2 × E/S de gravação = Total consumida de E/S de disco disponível
Quando você sabe a proporção de leituras e gravações e o número de eixos em sua implantação, é possível usar esta equação para calcular quanta E/S sua matriz pode suportar:
IOPS máximas por eixo × 2 eixos × [(% de leituras + % de gravações) ÷ (% de leituras + 2 × % de gravações)] = IOPS totais
Um cenário que usa RAID 1 e RAID 0 se comporta exatamente como RAID 1 no custo das operações de leitura e gravação. No entanto, agora a E/S é distribuída em cada conjunto espelhado. Isso significa que a equação mudará para:
IOPS máximas por eixo × 2 eixos × [(% de leituras + % de gravações) ÷ (% de leituras + 2 × % de gravações)] = E/S total
Em um conjunto RAID 1, quando você distribui o número N de conjuntos RAID 1, o total de E/S que sua matriz pode processar torna-se N × E/S por conjunto RAID 1:
N × {IOPS máximas por eixo × 2 eixos × [(% de leituras + % de gravações) ÷ (% de leituras + 2 × % de gravações)] } = IOPS totais
Às vezes, chamamos de RAID 5 N + 1 RAID porque o sistema distribui os dados em N eixos e grava informações de paridade no eixo + 1. No entanto, o RAID 5 usa mais recursos ao executar uma E/S de gravação do que o RAID 1 ou RAID 1 + 0. O RAID 5 executa o seguinte processo toda vez que o sistema operacional envia uma E/S de gravação para a matriz:
- Leia os dados antigos.
- Leia a paridade antiga.
- Grave os novos dados.
- Grave a nova paridade.
Cada solicitação de E/S de gravação que o sistema operacional envia ao controlador de matriz requer quatro operações de E/S para ser concluída. Portanto, as solicitações de gravação RAID N + 1 levam quatro vezes mais tempo do que uma E/S de leitura para serem concluídas. Em outras palavras, para determinar quantas solicitações de E/S do sistema operacional se transformam em quantas solicitações os eixos recebem, use esta equação:
E/S de leitura + 4 × E/S de gravação = E/S total
Da mesma forma, em um conjunto RAID 1 em que você sabe a proporção de leituras para gravações e quantos eixos existem, você pode usar esta equação para identificar quanta E/S sua matriz pode suportar:
IOPS por eixo × (eixos – 1) × [(% de leituras + % de gravações) ÷ (% de leituras + 4 × % de gravações)] = IOPS totais
Observação
O resultado da equação anterior não inclui a unidade perdida para a paridade.
Introdução ao SANs
Quando você introduz uma SAN (rede de área de armazenamento) em seu ambiente, isso não afeta os princípios de planejamento que descrevemos nas seções anteriores. No entanto, você deve levar em conta que a SAN pode alterar o comportamento de E/S de todos os sistemas conectados a ela. Uma das principais vantagens de usar uma SAN é que ela oferece mais redundância em relação ao armazenamento conectado interna ou externamente, mas também significa que o planejamento de capacidade precisa levar em conta as necessidades de tolerância a falhas. Além disso, à medida que você introduz mais componentes em seu sistema, também precisa levar em consideração essas novas peças em seus cálculos.
Agora, vamos dividir uma SAN em seus componentes:
- O disco rígido SCSI ou Fibre Channel
- O backplane do canal da unidade de armazenamento
- As próprias unidades de armazenamento
- O módulo do controlador de armazenamento
- Um ou mais switches SAN
- Um ou mais adaptadores de barramento de host (HBAs)
- O barramento de PCI (interconexão de componente periférico)
Ao projetar um sistema para redundância, você deve incluir componentes extras para garantir que seu sistema continue funcionando durante um cenário de crise em que um ou mais dos componentes originais param de funcionar. No entanto, ao planejar a capacidade, você precisa excluir componentes redundantes dos recursos disponíveis para obter uma estimativa precisa da capacidade de linha de base do sistema, pois esses componentes geralmente não ficam online, a menos que haja uma emergência. Por exemplo, se sua SAN tiver dois módulos controladores, você só precisará usar um ao calcular a taxa de transferência total de E/S disponível, pois o outro não será ativado a menos que o módulo original pare de funcionar. Você também não deve incluir o switch SAN redundante, a unidade de armazenamento ou os eixos nos cálculos de E/S.
Além disso, como seu planejamento de capacidade considera apenas períodos de pico de uso, você não deve fatorar componentes redundantes em seus recursos disponíveis. O pico de utilização não deve exceder 80% de saturação do sistema para acomodar intermitências ou outro comportamento incomum do sistema.
Ao analisar o comportamento do disco rígido SCSI ou Fibre Channel, você deve analisá-lo de acordo com os princípios descritos nas seções anteriores. Apesar de cada protocolo ter suas próprias vantagens e desvantagens, o que mais limita o desempenho por disco são as limitações mecânicas do disco rígido.
Ao analisar o canal na unidade de armazenamento, você deve adotar a mesma abordagem que usou ao calcular quantos recursos estavam disponíveis no barramento SCSI: dividir a largura de banda pelo tamanho do bloco. Por exemplo, se sua unidade de armazenamento tiver seis canais, cada um com suporte a uma taxa de transferência máxima de 20 MBps, a quantidade total de E/S e transferência de dados disponíveis será de 100 MBps. O motivo pelo qual o total é 100 MBps em vez de 120 MBps é porque a taxa de transferência total do canal de armazenamento não deve exceder o valor da taxa de transferência que usaria se um dos canais fosse desligado repentinamente, deixando apenas cinco canais em funcionamento. Obviamente, esse exemplo também pressupõe que o sistema está distribuindo uniformemente a carga e a tolerância a falhas em todos os canais.
A capacidade de transformar o exemplo anterior em um perfil de E/S depende do comportamento do aplicativo. Para a E/S do Active Directory Jet, o valor máximo seria de aproximadamente 12.500 E/S por segundo ou 100 MBps ÷ 8 KB por E/S.
Para entender que taxa de transferência seus módulos controladores suportam, você também precisa obter as especificações do fabricante. Neste exemplo, a SAN tem dois módulos de controlador que dão suporte à E/S de 7.500 cada. Se você não estiver usando redundância, a taxa de transferência total do sistema será de 15.000 IOPS. No entanto, em um cenário em que a redundância é necessária, você calcularia a taxa de transferência máxima com base nos limites de apenas um dos controladores, que é 7.500 IOPS. Supondo que o tamanho do bloco seja de 4 KB, esse limite está bem abaixo do máximo de 12.500 IOPS que os canais de armazenamento podem suportar e, portanto, é o gargalo em sua análise. No entanto, para fins de planejamento, a E/S máxima desejada para a qual você deve se planejar é de 10.400 E/S.
Quando os dados saem do módulo controlador, eles transmitem uma conexão Fibre Channel classificada em 1 GBps ou 128 MBps. Como essa quantidade excede a largura de banda total de 100 MBps em todos os canais da unidade de armazenamento, ela não causará gargalos no sistema. Além disso, como essa transmissão está em apenas um dos dois Fibre Channels devido à redundância, se uma conexão Fibre Channel parar de funcionar, a conexão restante ainda terá capacidade suficiente para suportar a demanda de transferência de dados.
Em seguida, os dados passam por um switch SAN a caminho do servidor. O switch limita a quantidade de E/S que consegue suportar porque precisa processar a solicitação de entrada e encaminhá-la para a porta apropriada. No entanto, só é possível saber o limite do switch se observar as especificações do fabricante. Por exemplo, se o sistema tiver dois switches e cada switch conseguir trabalhar com 10.000 IOPS, a taxa de transferência total será de 20.000 IOPS. Com base nas regras de tolerância a falhas, se um switch parar de funcionar, a taxa de transferência total do sistema será de 10.000 IOPS. Portanto, em circunstâncias normais, você não deve usar mais de 80% de utilização ou 8.000 E/S.
Por fim, o HBA instalado no servidor também limita a quantidade de E/S que ele pode suportar. Normalmente, você instala um segundo HBA para redundância, mas, como acontece com o switch SAN, quando você calcula a quantidade de E/S que o sistema pode suportar, a taxa de transferência total é de N - 1 HBA.
Considerações sobre armazenamento em cache
Os caches são um dos componentes que podem afetar significativamente o desempenho geral em qualquer lugar do sistema de armazenamento. No entanto, uma análise detalhada dos algoritmos de cache está além do escopo deste artigo. Em vez disso, forneceremos uma lista rápida de coisas que você deve saber sobre o cache em subsistemas de disco.
- O cache melhora a E/S de gravação sequencial sustentada porque armazena em buffer muitas operações de gravação menores em blocos de E/S maiores. Também transfere as operações para o armazenamento em alguns blocos grandes em vez de muitos blocos minúsculos. Essa otimização reduz o total de operações de E/S aleatórias e sequenciais, disponibilizando mais recursos para outras operações de E/S.
- O cache não melhora a taxa de transferência de E/S de gravação sustentada no subsistema de armazenamento porque armazena em buffer apenas as gravações até que os eixos estejam disponíveis para confirmar os dados. Quando toda a E/S disponível dos eixos é saturada por dados por longos períodos de tempo, o cache eventualmente é preenchido. Para esvaziar o cache, você deve fornecer E/S suficiente para a limpeza do cache, fornecendo eixos extras ou dando tempo suficiente entre as intermitências para que o sistema se atualize.
- Caches maiores permitem que mais dados sejam armazenados em buffer, o que significa que o cache pode suportar períodos mais longos de saturação.
- Em subsistemas de armazenamento típicos, o sistema operacional experimenta um desempenho de gravação aprimorado com caches, pois o sistema só precisa gravar os dados no cache. No entanto, quando a mídia subjacente estiver saturada com operações de E/S, o cache será preenchido e o desempenho de gravação retornará à velocidade normal do disco.
- Quando você armazena E/S de leitura em cache, o cache é mais útil quando você armazena dados sequencialmente na mesa e permite que o cache leia adiante. A leitura antecipada é quando o cache pode ser movido imediatamente para o próximo setor, como se o próximo setor contivesse os dados que o sistema solicitará em seguida.
- Quando a E/S de leitura é aleatória, o cache no controlador da unidade não aumenta a quantidade de dados que o disco pode ler. Se o tamanho do cache baseado em sistema operacional ou aplicativo for maior que o tamanho do cache baseado em hardware, qualquer tentativa de aumentar a velocidade de leitura do disco não alterará nada.
- No Active Directory, o cache é limitado apenas pela quantidade de RAM que o sistema contém.
Considerações sobre SSD
As unidades de estado sólido (SSDs) são fundamentalmente diferentes dos discos rígidos baseados em eixo. Os SSDs suportam volumes maiores de E/S com menor latência. Embora os SSDs possam ser caros com base no custo por Gigabyte, eles são muito baratos em termos de custo por E/S. No entanto, o planejamento de capacidade com SSDs envolve fazer a si mesmo as mesmas perguntas que você faria sobre eixos: quantas IOPS eles podem suportar e qual é a latência dessas IOPS?
Aqui estão algumas coisas que você deve considerar ao pensar em SSDs:
- Tanto as IOPS quanto a latência estão sujeitas aos designs do fabricante. Em alguns casos, certos designs de SSD podem ter um desempenho pior do que as tecnologias baseadas em eixo. Ao tentar decidir se você deve usar SSD ou eixos, você deve ler e validar as especificações do fabricante unidade por unidade, em vez de presumir que todas as tecnologias funcionam de uma determinada maneira.
- Os tipos de IOPS podem ter valores diferentes, caso sejam lidos ou gravados. Os serviços do AD DS são predominantemente baseados em leitura e, portanto, são menos afetados pela tecnologia de gravação que você usa em comparação com outros cenários de aplicativo.
- A resistência de gravação é a suposição de que as células SSD têm uma vida útil limitada e acabarão se desgastando depois de muito uso. Para unidades de banco de dados, um perfil de E/S predominantemente de leitura estende a resistência de gravação das células até o ponto em que você não precisa se preocupar muito com a resistência de gravação.
Resumo
Imagine o armazenamento como o encanamento interno de uma casa. As IOPS da mídia em que você armazena seus dados é como o ralo principal da casa. Quando o ralo principal fica entupido ou limitado pelo tamanho ou colapso do cano, os ralos ficam cheios de água e não funcionam corretamente quando a casa usa muita água. Esse cenário é como quando um ambiente compartilhado tem um ou mais sistemas usando armazenamento compartilhado na mesma SAN, NAS ou iSCSI com a mesma mídia subjacente. Como a demanda do usuário excede a capacidade do sistema de acompanhar, o desempenho é prejudicado.
Da mesma forma, em nosso cenário de encanamento imaginário, você pode adotar abordagens diferentes para resolver entupimentos e outros problemas de desempenho:
- Para consertar um cano de drenagem colapsado ou um ralo muito pequeno, você precisa substituir os canos por outros que funcionem e tenham o tamanho correto. Em termos de armazenamento compartilhado, é como adicionar novo hardware ou redistribuir o uso nos sistemas compartilhados em toda a infraestrutura.
- Desentupir um ralo requer identificar os problemas subjacentes e suas localizações e, em seguida, remover com a ferramenta apropriada. Por exemplo, um entupimento relativamente simples no ralo da pia da cozinha precisa apenas de um desentupidor ou um limpador de ralo, enquanto entupimentos mais complexos que envolvem um objeto preso podem exigir uma cobra de drenagem. Da mesma forma, em um sistema de armazenamento compartilhado, identificar a causa dos problemas de desempenho ajuda a descobrir se você precisa criar um backup no nível do sistema, sincronizar verificações de antivírus em todos os servidores ou sincronizar o software de desfragmentação executado durante os períodos de pico.
Na maioria dos projetos de encanamento, vários ralos alimentam o ralo principal. Quando um ralo fica entupido, a água só fica presa atrás de onde está o entupimento. Se uma junção entope, todos os drenos atrás desse ponto de junção param de drenar. Em um cenário de armazenamento, uma junção entupida é como um switch sobrecarregado, um problema de compatibilidade de driver ou tarefas de software não sincronizadas. Você deve medir o tamanho de IOPS e E/S para determinar se o sistema de armazenamento pode lidar com a carga e, em seguida, ajustar o sistema conforme necessário.
Apêndice D: solução de problemas de armazenamento em ambientes em que mais RAM não é uma opção
Muitas recomendações de armazenamento antes do armazenamento virtualizado serviam a dois propósitos:
- Isolar a E/S para evitar que problemas de desempenho no eixo do sistema operacional afetassem o desempenho do banco de dados e dos perfis de E/S.
- Aproveitar o aumento de desempenho que os discos rígidos e caches baseados em eixo podem proporcionar ao sistema quando usados com a E/S sequencial dos arquivos de log do AD DS. Isolar a E/S sequencial em uma unidade física separada também pode aumentar a taxa de transferência.
Com as novas opções de armazenamento, muitas suposições fundamentais por trás das recomendações de armazenamento anteriores não são mais verdadeiras. Cenários de armazenamento virtualizado, como iSCSI, SAN, NAS e arquivos de imagem de Disco Virtual, geralmente compartilham mídia de armazenamento subjacente em vários hosts. Essa diferença nega as suposições de que você deve isolar a E/S e otimizar a E/S sequencial. Agora, outros hosts que acessam a mídia compartilhada podem reduzir a capacidade de resposta ao controlador de domínio.
Ao planejar a capacidade do desempenho do armazenamento, você deve considerar três coisas:
- Estado de cache frio
- Estado de cache quente
- Backup e restauração
O estado de cache frio é quando você reinicializa inicialmente o controlador de domínio ou reinicia o serviço do Active Directory, portanto, não há dados do Active Directory na RAM. Um estado de cache quente é quando o controlador de domínio está operando em um estado estável e armazenou o banco de dados em cache. Em termos de design de desempenho, aquecer um cache frio é como um sprint, enquanto executar um servidor com um cache totalmente aquecido é como uma maratona. Definir esses estados e os diferentes perfis de desempenho que eles geram é importante, pois você precisa considerá-los ao estimar a capacidade. Por exemplo, só porque você tem RAM suficiente para armazenar em cache todo o banco de dados durante um estado de cache quente não ajuda a otimizar o desempenho durante o estado de cache frio.
Para ambos os cenários de cache, o mais importante é a rapidez com que o armazenamento pode mover dados do disco para a memória. Quando você aquece o cache, com o tempo, o desempenho melhora à medida que as consultas reutilizam dados, a taxa de ocorrências do cache aumenta e a frequência de acesso ao disco para recuperar dados diminui. Como resultado, os impactos adversos no desempenho de ter que acessar o disco também diminuem. Quaisquer degradações de desempenho são temporárias e geralmente desaparecem quando o cache atinge seu estado quente e o tamanho máximo permitido pelo sistema.
Você pode medir a rapidez com que o sistema pode obter dados do disco medindo o IOPS disponível no Active Directory. A quantidade de IOPS disponíveis também está sujeita a quantas IOPS estão disponíveis no armazenamento subjacente. Do ponto de vista do planejamento, como o aquecimento do cache e os estados de backup ou restauração são eventos excepcionais que geralmente ocorrem fora do horário de pico e estão sujeitos à carga do DC, não podemos fornecer recomendações gerais além de apenas entrar nesses estados fora do horário de pico.
Na maioria dos cenários, o AD DS é predominantemente de leitura de E/S com uma proporção de 90% de leitura para 10% de gravação. A E/S de leitura é o gargalo típico para a experiência do usuário, enquanto a E/S de gravação é o gargalo que degrada o desempenho da gravação. Os caches tendem a fornecer um benefício mínimo para a leitura de E/S porque as operações de E/S para o arquivo NTDS.dit são predominantemente aleatórias. Portanto, sua principal prioridade é garantir que você configure corretamente o armazenamento do perfil de E/S de leitura.
Em condições normais de operação, sua meta de planejamento de armazenamento é minimizar os tempos de espera para que o sistema retorne solicitações do AD DS para o disco. O número de operações de E/S pendentes deve ser menor ou igual ao número de caminhos no disco. Para cenários de monitoramento de desempenho, geralmente recomendamos que o contador LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read tenha menos de 20 ms. Você deve definir o limite operacional muito mais baixo, o mais próximo possível da velocidade de armazenamento, dentro de um intervalo de dois a seis milissegundos, dependendo do tipo de armazenamento.
O gráfico de linhas a seguir mostra a medição da latência do disco em um sistema de armazenamento.
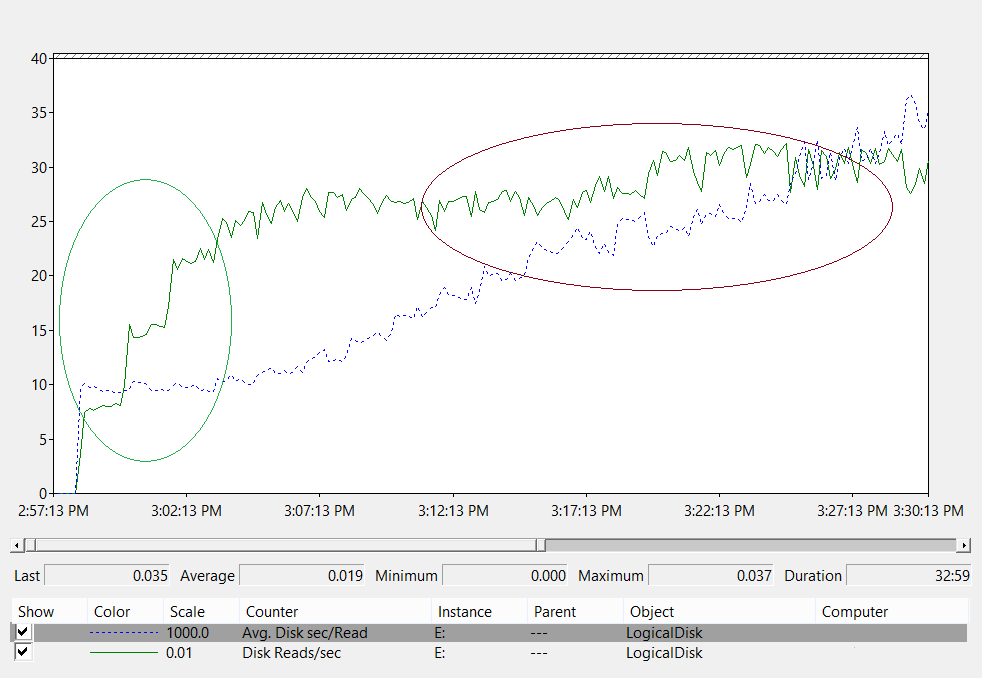
Vamos analisar este gráfico de linhas:
- A área à esquerda do gráfico circulada em verde mostra que a latência é consistente em 10 ms à medida que a carga aumenta de 800 IOPS para 2.400 IOPS. Essa área é a linha de base para a rapidez com que o armazenamento subjacente pode processar uma solicitação de E/S. No entanto, essa linha de base é afetada pelo tipo de solução de armazenamento que você usa.
- A área no lado direito do gráfico circulada em bordô mostra a taxa de transferência do sistema entre a linha de base e o final da coleta de dados. A taxa de transferência em si não muda, mas a latência aumenta. Essa área demonstra como as solicitações passam mais tempo aguardando na fila para serem enviadas ao subsistema de armazenamento sempre que os volumes de solicitação excedem os limites físicos do armazenamento subjacente.
Agora, vamos pensar sobre o que esses dados nos dizem.
Primeiro, vamos supor que um usuário que consulta a associação de um grupo grande exija que o sistema leia 1 MB de dados do disco. Você pode avaliar a quantidade de E/S necessária e quanto tempo as operações levarão com estes valores:
- O tamanho de cada página de banco de dados do Active Directory é de 8 KB.
- O número mínimo de páginas que o sistema precisa ler é 128.
- Portanto, na área de base no diagrama, o sistema deve levar pelo menos 1,28 segundo para carregar os dados do disco e devolvê-los ao cliente. Na marca de 20 ms, em que a taxa de transferência vai bem além do máximo recomendado, o processo leva 2,5 segundos.
Com base nesses números, você pode calcular a rapidez com que o cache aquecerá usando esta equação:
2.400 IOPS × 8 KB por E/S
Depois de realizar esse cálculo, podemos dizer que a taxa de aquecimento do cache nesse cenário é de 20 MBps. Em outras palavras, o sistema carrega cerca de 1 GB de banco de dados na RAM a cada 53 segundos.
Observação
É normal ver a latência aumentar por curtos períodos enquanto os componentes estão lendo ou gravando agressivamente no disco. Por exemplo, a latência aumenta quando o sistema está fazendo backup ou o AD DS executa a coleta de lixo. Você deve fornecer espaço adicional para esses eventos periódicos além de suas estimativas de uso originais. Seu objetivo é fornecer taxa de transferência suficiente para acomodar esses picos sem afetar o funcionamento geral.
Há um limite físico para a rapidez com que o cache aquece com base em como você projeta o sistema de armazenamento. A única coisa que pode aquecer o cache até a taxa que o armazenamento subjacente pode acomodar são as solicitações de entrada do cliente. A execução de scripts para tentar pré-aquecer o cache durante os horários de pico compete com as solicitações reais do cliente, aumenta a carga geral, carrega dados que não são relevantes para as solicitações do cliente e degrada o desempenho. Recomendamos que você evite usar medidas artificiais para aquecer o cache.