Visão geral do Fluxo de Dados no DirectShow
[O recurso associado a esta página, DirectShow, é um recurso herdado. Ele foi substituído por MediaPlayer, IMFMediaEngine e Captura de Áudio/Vídeo na Media Foundation. Esses recursos foram otimizados para Windows 10 e Windows 11. A Microsoft recomenda fortemente que o novo código use MediaPlayer, IMFMediaEngine e Captura de Áudio/Vídeo no Media Foundation em vez de DirectShow, quando possível. A Microsoft sugere que o código existente que usa as APIs herdadas seja reescrito para usar as novas APIs, se possível.]
Esta seção fornece uma visão geral ampla de como o fluxo de dados funciona no DirectShow. Os detalhes podem ser encontrados em outras seções da documentação.
Os dados são mantidos em buffers, que são simplesmente matrizes de bytes. Cada buffer é encapsulado por um objeto COM chamado exemplo de mídia, que implementa a interface IMediaSample . Os exemplos são criados por outro tipo de objeto, chamado allocator, que implementa a interface IMemAllocator . Um alocador é atribuído para cada conexão de pino, embora duas ou mais conexões de pino possam compartilhar o mesmo alocador. A imagem a seguir ilustra esse processo.
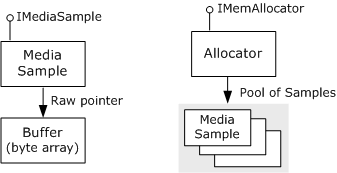
Cada alocador cria um pool de exemplos de mídia e aloca os buffers para cada exemplo. Sempre que um filtro precisa preencher um buffer com dados, ele solicita um exemplo do alocador chamando IMemAllocator::GetBuffer. Se o alocador tiver amostras que não estão sendo usadas por outro filtro no momento, o método GetBuffer retornará imediatamente com um ponteiro para o exemplo. Se todos os exemplos do alocador estiverem em uso, o método será bloqueado até que uma amostra fique disponível. Quando o método retorna um exemplo, o filtro coloca dados no buffer, define os sinalizadores apropriados no exemplo (normalmente incluindo um carimbo de data/hora) e entrega o exemplo downstream.
Quando um filtro de renderizador recebe um exemplo, ele verifica o carimbo de data/hora e mantém-se no exemplo até que o relógio de referência do grafo de filtro indique que os dados devem ser renderizados. Depois que o filtro renderiza os dados, ele libera o exemplo. O exemplo não volta para o pool de exemplos do alocador até que a contagem de referência do exemplo seja zero, o que significa que cada filtro liberou o exemplo. A imagem a seguir ilustra esse processo.
O filtro upstream pode ser executado antes do renderizador, ou seja, ele pode preencher buffers mais rapidamente do que o renderizador os consome. Mesmo assim, os exemplos não são renderizados antecipadamente, pois o renderizador mantém cada um até o horário da apresentação. Além disso, o filtro upstream não substituirá buffers acidentalmente, pois GetSample retorna apenas amostras que, de outra forma, não estão em uso. O valor pelo qual o filtro de upstream pode ser executado antecipadamente é determinado pelo número de amostras no pool do alocador.
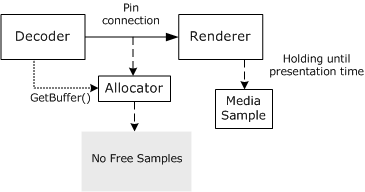
O diagrama anterior mostra apenas um alocador, mas normalmente há vários alocadores por fluxo. Assim, quando o renderizador libera um exemplo, ele pode ter um efeito em cascata. O diagrama a seguir mostra uma situação em que um decodificador mantém um quadro de vídeo compactado enquanto aguarda o renderizador liberar um exemplo. Um filtro de analisador também está aguardando o decodificador liberar um exemplo.

Quando o renderizador libera seu exemplo, a chamada pendente do decodificador para GetBuffer retorna. Em seguida, o decodificador pode decodificar o quadro de vídeo compactado e liberar o exemplo que ele estava segurando, desbloqueando assim a chamada do GetBuffer pendente do analisador.
Tópicos relacionados