Guia de início rápido: criar um detetor de objetos com o site da Visão Personalizada
Este guia de início rápido explica como usar o site Visão Personalizada para criar um modelo de detetor de objetos. Depois de criar um modelo, você pode testá-lo com novas imagens e integrá-lo em seu próprio aplicativo de reconhecimento de imagem.
Pré-requisitos
- Uma subscrição do Azure. Você pode criar uma conta gratuita.
- Um conjunto de imagens com as quais treinar seu modelo de detetor. Você pode usar o conjunto de imagens de exemplo no GitHub. Ou, você pode escolher suas próprias imagens usando as seguintes dicas.
- Um navegador da Web compatível.
Criar recursos de Visão Personalizada
Para usar o serviço de Visão Personalizada, você precisa criar recursos de treinamento e previsão de Visão Personalizada no Azure. No portal do Azure, use a página Criar Visão Personalizada para criar um recurso de treinamento e um recurso de previsão.
Criar um novo projeto
No navegador da Web, navegue até o site da Visão Personalizada. Entre com a mesma conta que você usou para entrar no portal do Azure.
Para criar seu primeiro projeto, selecione Novo projeto. A caixa de diálogo Criar novo projeto é exibida.
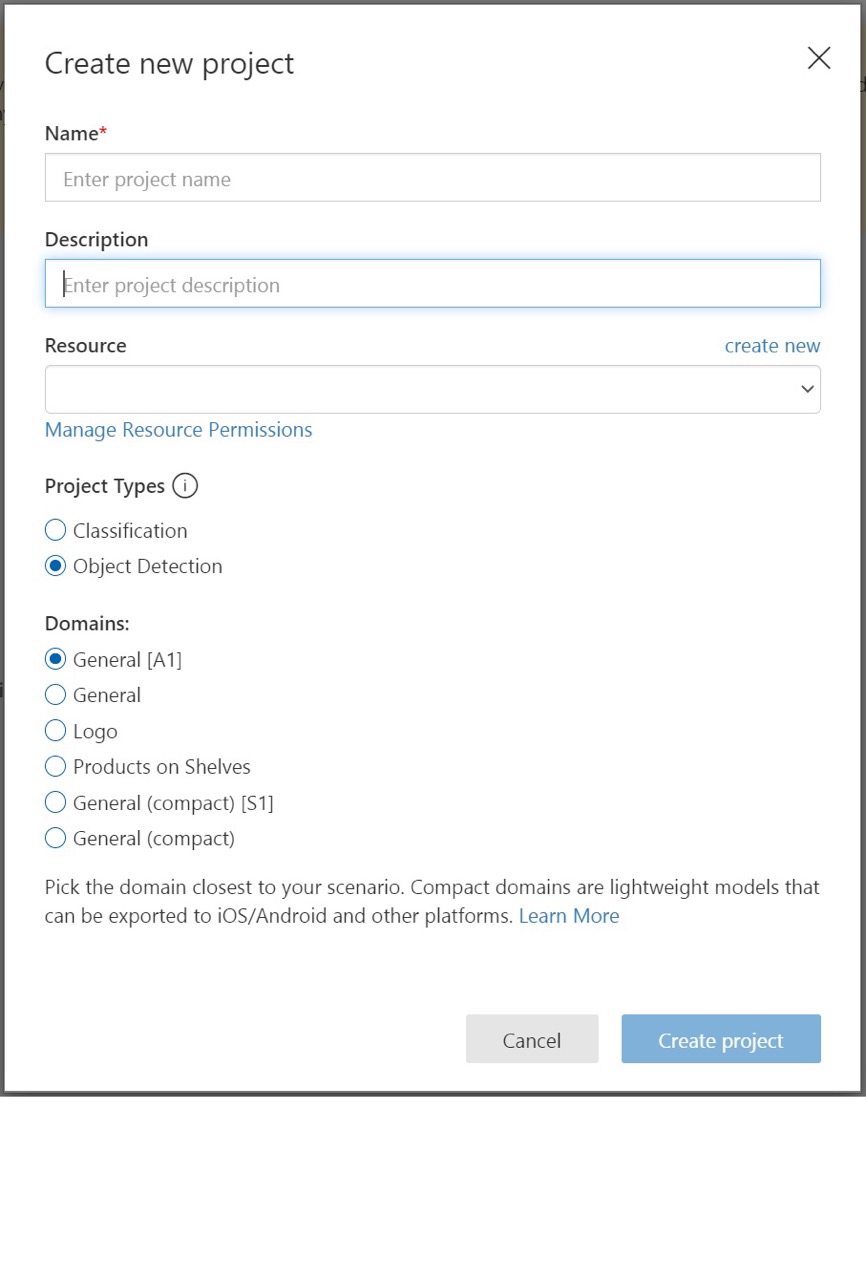
Insira um nome e uma descrição para o projeto. Em seguida, selecione seu recurso de treinamento Visão Personalizada. Se sua conta conectada estiver associada a uma conta do Azure, a lista suspensa Recurso exibirá todos os seus recursos compatíveis do Azure.
Nota
Se nenhum recurso estiver disponível, confirme que iniciou sessão no customvision.ai com a mesma conta que utilizou para iniciar sessão no portal do Azure. Além disso, confirme que selecionou o mesmo Diretório no site da Visão Personalizada que o diretório no portal do Azure onde seus recursos da Visão Personalizada estão localizados. Em ambos os sites, você pode selecionar seu diretório no menu suspenso da conta no canto superior direito da tela.
Em Tipos de Projeto, selecione Deteção de Objetos.
Selecione um dos domínios disponíveis. Cada domínio otimiza o detetor para tipos específicos de imagens, conforme descrito na tabela a seguir. Você pode alterar o domínio mais tarde, se desejar.
Domínio Propósito General (Geral) Otimizado para uma ampla gama de tarefas de deteção de objetos. Se nenhum dos outros domínios for apropriado ou se você não tiver certeza sobre qual domínio escolher, selecione o domínio Geral . Logótipo Otimizado para encontrar logotipos de marcas em imagens. Produtos nas prateleiras Otimizado para detetar e classificar produtos em prateleiras. Domínios compactos Otimizado para as restrições de deteção de objetos em tempo real em dispositivos móveis. Os modelos gerados por domínios compactos podem ser exportados para serem executados localmente. Por fim, selecione Criar projeto.
Escolha imagens de treinamento
No mínimo, você deve usar pelo menos 30 imagens por tag no conjunto de treinamento inicial. Você também deve coletar algumas imagens extras para testar seu modelo depois que ele for treinado.
Para treinar o seu modelo de forma eficaz, use imagens com variedade visual. Selecione imagens que variam por:
- ângulo da câmara
- iluminação
- Contexto geral
- estilo visual
- sujeito(s) individual(ais/agrupado(s)
- size
- tipo
Além disso, certifique-se de que todas as suas imagens de treinamento atendam aos seguintes critérios:
- deve ser .jpg, .png, .bmp ou formato .gif
- não superior a 6 MB de tamanho (4 MB para imagens de previsão)
- não menos de 256 pixels na borda mais curta; todas as imagens com menos de 256 pixels são automaticamente dimensionadas pelo serviço Visão Personalizada
Carregar e etiquetar imagens
Nesta seção, você carrega e marca manualmente as imagens para ajudar a treinar o detetor.
Para adicionar imagens, selecione Adicionar imagens e, em seguida, selecione Procurar ficheiros locais. Selecione Abrir para carregar as imagens.
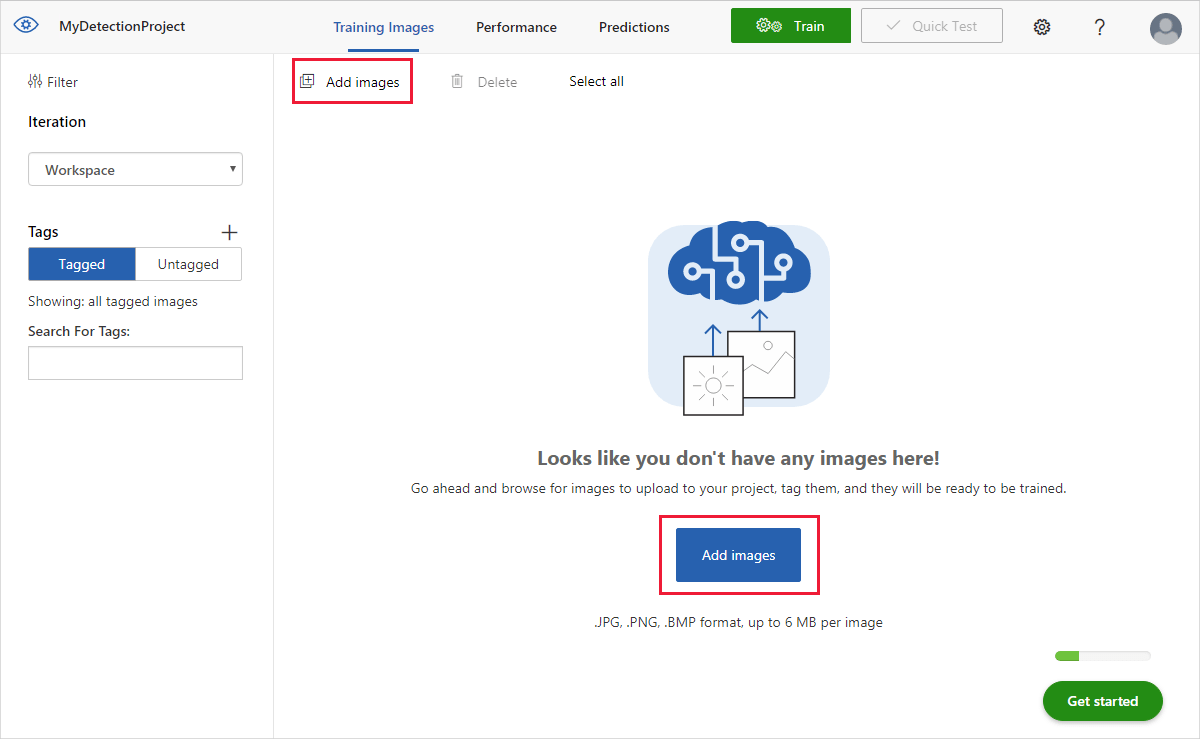
Você verá as imagens carregadas na seção Não marcadas da interface do usuário. A próxima etapa é marcar manualmente os objetos que você deseja que o detetor aprenda a reconhecer. Selecione a primeira imagem para abrir a janela de diálogo de marcação.
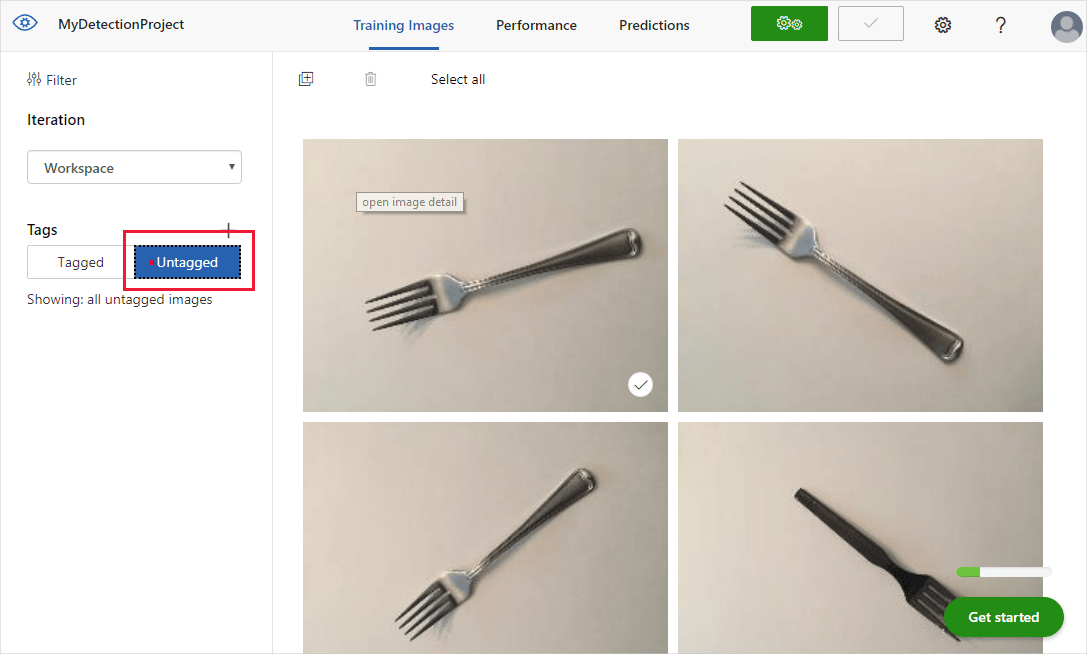
Selecione e arraste um retângulo ao redor do objeto na imagem. Em seguida, insira um novo nome de tag com o + botão ou selecione uma tag existente na lista suspensa. É importante marcar todas as ocorrências dos objetos que você deseja detetar, porque o detetor usa a área de fundo não marcada como um exemplo negativo no treinamento. Quando terminar de marcar, selecione a seta à direita para salvar as tags e passar para a próxima imagem.

Para carregar outro conjunto de imagens, volte ao topo desta secção e repita os passos.
Treinar o detetor
Para treinar o modelo do detetor, selecione o botão Trem . O detetor usa todas as imagens atuais e suas tags para criar um modelo que identifica cada objeto marcado. Este processo pode demorar vários minutos.

O processo de treinamento deve levar apenas alguns minutos. Durante esse período, as informações sobre o processo de treinamento são exibidas na guia Desempenho .
Avalie o detetor
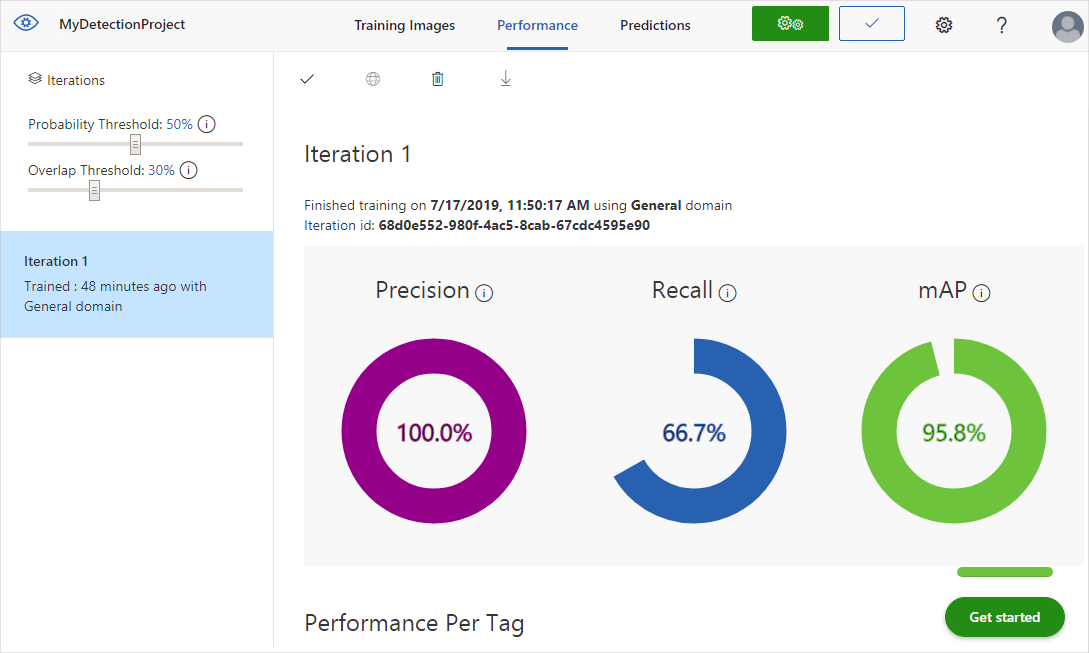
Após a conclusão do treinamento, o desempenho do modelo é calculado e exibido. O serviço Visão Personalizada usa as imagens enviadas para treinamento para calcular a precisão, a recuperação e a precisão média média. Precisão e recall são duas medidas diferentes da eficácia de um detetor:
- A precisão indica a fração de classificações identificadas que estavam corretas. Por exemplo, se o modelo identificasse 100 imagens como cães, e 99 delas fossem realmente de cães, então a precisão seria de 99%.
- Recall indica a fração de classificações reais que foram corretamente identificadas. Por exemplo, se houvesse realmente 100 imagens de maçãs, e o modelo identificasse 80 como maçãs, o recall seria de 80%.
- A precisão média é o valor médio da precisão média (AP). O AP é a área sob a curva de precisão/recall (precisão plotada contra recall para cada previsão feita).
Limiar de probabilidade
Observe o controle deslizante Limiar de Probabilidade no painel esquerdo da guia Desempenho . Este é o nível de confiança que uma previsão precisa ter para ser considerada correta (para fins de precisão de cálculo e recordação).
Quando você interpreta chamadas de previsão com um limite de alta probabilidade, elas tendem a retornar resultados com alta precisão às custas da recuperação — as classificações detetadas estão corretas, mas muitas permanecem não detetadas. Um limiar de baixa probabilidade faz o oposto – a maioria das classificações reais são detetadas, mas há mais falsos positivos dentro desse conjunto. Com isso em mente, você deve definir o limite de probabilidade de acordo com as necessidades específicas do seu projeto. Mais tarde, quando você estiver recebendo resultados de previsão no lado do cliente, você deve usar o mesmo valor de limite de probabilidade que você usou aqui.
Limiar de sobreposição
O controle deslizante Limiar de sobreposição lida com o quão correta uma previsão de objeto deve ser para ser considerada correta no treinamento. Ele define a sobreposição mínima permitida entre a caixa delimitadora do objeto previsto e a caixa delimitadora real inserida pelo usuário. Se as caixas delimitadoras não se sobreporem a este grau, a previsão não é considerada correta.
Gerenciar iterações de treinamento
Cada vez que você treina seu detetor, você cria uma nova iteração com suas próprias métricas de desempenho atualizadas. Você pode exibir todas as suas iterações no painel esquerdo da guia Desempenho . No painel esquerdo, você também encontrará o botão Excluir , que pode ser usado para excluir uma iteração se ela estiver obsoleta. Ao excluir uma iteração, você exclui todas as imagens associadas exclusivamente a ela.
Para saber como acessar seus modelos treinados programaticamente, consulte Usar seu modelo com a API de previsão.
Próximo passo
Neste guia de início rápido, você aprendeu como criar e treinar um modelo de detetor de objetos usando o site Visão Personalizada. Em seguida, obtenha mais informações sobre o processo iterativo de melhoria do seu modelo.
Para obter uma visão geral, consulte O que é Visão Personalizada?