Treinar um modelo de fala personalizado
Neste artigo, você aprenderá a treinar um modelo personalizado para melhorar a precisão de reconhecimento do modelo base da Microsoft. A precisão e a qualidade do reconhecimento de fala de um modelo de fala personalizado permanecem consistentes, mesmo quando um novo modelo base é lançado.
Nota
Você paga pelo uso do modelo de fala personalizado e pela hospedagem de pontos finais. Você também será cobrado pelo treinamento de modelo de fala personalizado se o modelo base tiver sido criado em 1º de outubro de 2023 e posterior. Você não será cobrado pelo treinamento se o modelo base tiver sido criado antes de outubro de 2023. Para obter mais informações, consulte Preços do Azure AI Speech e a seção Cobrar pela adaptação no guia de migração de fala para texto 3.2.
O treinamento de um modelo é normalmente um processo iterativo. Primeiro, selecione um modelo base que seja o ponto de partida para um novo modelo. Você treina um modelo com conjuntos de dados que podem incluir texto e áudio e, em seguida, testa. Se a qualidade ou precisão do reconhecimento não atender aos seus requisitos, você poderá criar um novo modelo com mais dados de treinamento ou dados modificados e, em seguida, testar novamente.
Você pode usar um modelo personalizado por um tempo limitado depois que ele foi treinado. Você deve recriar e adaptar periodicamente seu modelo personalizado a partir do modelo base mais recente para aproveitar a precisão e a qualidade aprimoradas. Para obter mais informações, consulte Ciclo de vida do modelo e do ponto final.
Importante
Se você treinar um modelo personalizado com dados de áudio, escolha uma região de recurso de fala com hardware dedicado para treinar dados de áudio. Depois que um modelo é treinado, você pode copiá-lo para um recurso de Fala em outra região, conforme necessário.
Em regiões com hardware dedicado para treinamento de fala personalizado, o serviço de fala usará até 100 horas de seus dados de treinamento de áudio e pode processar cerca de 10 horas de dados por dia. Consulte as notas de rodapé na tabela de regiões para obter mais informações.
Criar um modelo
Depois de carregar conjuntos de dados de treinamento, siga estas instruções para começar a treinar seu modelo:
Inicie sessão no Speech Studio.
Selecione Fala> personalizada Seu nome >de projeto Treinar modelos personalizados.
Selecione Treinar um novo modelo.
Na página Selecione um modelo de linha de base, selecione um modelo base e selecione Avançar. Se não tiver certeza, selecione o modelo mais recente no topo da lista. O nome do modelo base corresponde à data em que foi lançado no formato AAAAMMDD. Os recursos de personalização do modelo base são listados entre parênteses após o nome do modelo no Speech Studio.
Importante
Tome nota do Prazo de validade para a data de adaptação . Esta é a última data em que você pode usar o modelo base para treinamento. Para obter mais informações, consulte Ciclo de vida do modelo e do ponto final.
Na página Escolher dados, selecione um ou mais conjuntos de dados que você deseja usar para treinamento. Se não houver conjuntos de dados disponíveis, cancele a configuração e vá para o menu Conjuntos de dados de fala para carregar conjuntos de dados.
Introduza um nome e uma descrição para o seu modelo personalizado e, em seguida, selecione Seguinte.
Opcionalmente, marque a caixa Adicionar teste na próxima etapa . Se você pular esta etapa, poderá executar os mesmos testes mais tarde. Para obter mais informações, consulte Qualidade de reconhecimento de teste e Modelo de teste quantitativamente.
Selecione Salvar e fechar para iniciar a compilação do seu modelo personalizado.
Regresse à página Treinar modelos personalizados .
Importante
Tome nota da data de validade . Esta é a última data em que você pode usar seu modelo personalizado para reconhecimento de fala. Para obter mais informações, consulte Ciclo de vida do modelo e do ponto final.
Para criar um modelo com conjuntos de dados para treinamento, use o spx csr model create comando. Construa os parâmetros de solicitação de acordo com as seguintes instruções:
- Defina o
projectparâmetro como a ID de um projeto existente. Esse parâmetro é recomendado para que você também possa exibir e gerenciar o modelo no Speech Studio. Você pode executar ospx csr project listcomando para obter projetos disponíveis. - Defina o parâmetro necessário
datasetpara a ID de um conjunto de dados que você deseja usar para treinamento. Para especificar vários conjuntos de dados, defina odatasetsparâmetro (plural) e separe os IDs com um ponto-e-vírgula. - Defina o parâmetro necessário
language. A localidade do conjunto de dados deve corresponder à localidade do projeto. A localidade não pode ser alterada posteriormente. O parâmetro Speech CLIlanguagecorresponde àlocalepropriedade na solicitação e resposta JSON. - Defina o parâmetro necessário
name. Este parâmetro é o nome exibido no Speech Studio. O parâmetro Speech CLInamecorresponde àdisplayNamepropriedade na solicitação e resposta JSON. - Opcionalmente, você pode definir a
basepropriedade. Por exemplo:--base 5988d691-0893-472c-851e-8e36a0fe7aaf. Se você não especificar obase, o modelo base padrão para a localidade será usado. O parâmetro Speech CLIbasecorresponde àbaseModelpropriedade na solicitação e resposta JSON.
Aqui está um exemplo de comando da CLI de Fala que cria um modelo com conjuntos de dados para treinamento:
spx csr model create --api-version v3.2 --project YourProjectId --name "My Model" --description "My Model Description" --dataset YourDatasetId --language "en-US"
Nota
Neste exemplo, o base não está definido, portanto, o modelo base padrão para a localidade é usado. O URI do modelo base é retornado na resposta.
Deverá receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Importante
Anote a data na adaptationDateTime propriedade. Esta é a última data em que você pode usar o modelo base para treinamento. Para obter mais informações, consulte Ciclo de vida do modelo e do ponto final.
Anote a data na transcriptionDateTime propriedade. Esta é a última data em que você pode usar seu modelo personalizado para reconhecimento de fala. Para obter mais informações, consulte Ciclo de vida do modelo e do ponto final.
A propriedade de nível self superior no corpo da resposta é o URI do modelo. Use este URI para obter detalhes sobre o projeto, o manifesto e as datas de substituição do modelo. Você também usa esse URI para atualizar ou excluir um modelo.
Para obter ajuda da CLI de fala com modelos, execute o seguinte comando:
spx help csr model
Para criar um modelo com conjuntos de dados para treinamento, use a operação Models_Create da API REST de fala para texto. Construa o corpo da solicitação de acordo com as seguintes instruções:
- Defina a
projectpropriedade como o URI de um projeto existente. Essa propriedade é recomendada para que você também possa exibir e gerenciar o modelo no Speech Studio. Você pode fazer uma solicitação de Projects_List para obter projetos disponíveis. - Defina a propriedade required
datasetspara o URI dos conjuntos de dados que você deseja usar para treinamento. - Defina a propriedade necessária
locale. A localidade do modelo deve corresponder à localidade do projeto e do modelo base. A localidade não pode ser alterada posteriormente. - Defina a propriedade necessária
displayName. Esta propriedade é o nome exibido no Speech Studio. - Opcionalmente, você pode definir a
baseModelpropriedade. Por exemplo:"baseModel": {"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"}. Se você não especificar obaseModel, o modelo base padrão para a localidade será usado.
Faça uma solicitação HTTP POST usando o URI, conforme mostrado no exemplo a seguir. Substitua YourSubscriptionKey pela chave de recurso Fala, substitua YourServiceRegion pela região de recurso Fala e defina as propriedades do corpo da solicitação conforme descrito anteriormente.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Model",
"description": "My Model Description",
"baseModel": null,
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Nota
Neste exemplo, o baseModel não está definido, portanto, o modelo base padrão para a localidade é usado. O URI do modelo base é retornado na resposta.
Deverá receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/5988d691-0893-472c-851e-8e36a0fe7aaf"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd:copy",
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9e240dc1-3d2d-4ac9-98ec-1be05ba0e9dd/files"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"properties": {
"deprecationDates": {
"transcriptionDateTime": "2026-07-15T00:00:00Z"
},
"customModelWeightPercent": 30,
"features": {
"supportsTranscriptions": true,
"supportsEndpoints": true,
"supportsTranscriptionsOnSpeechContainers": false,
"supportedOutputFormats": [
"Display",
"Lexical"
]
}
},
"lastActionDateTime": "2024-07-14T21:38:40Z",
"status": "Running",
"createdDateTime": "2024-07-14T21:38:40Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Importante
Anote a data na adaptationDateTime propriedade. Esta é a última data em que você pode usar o modelo base para treinamento. Para obter mais informações, consulte Ciclo de vida do modelo e do ponto final.
Anote a data na transcriptionDateTime propriedade. Esta é a última data em que você pode usar seu modelo personalizado para reconhecimento de fala. Para obter mais informações, consulte Ciclo de vida do modelo e do ponto final.
A propriedade de nível self superior no corpo da resposta é o URI do modelo. Use este URI para obter detalhes sobre o projeto, o manifesto e as datas de substituição do modelo. Você também usa esse URI para atualizar ou excluir o modelo.
Copiar um modelo
Você pode copiar um modelo para outro projeto que usa a mesma localidade. Por exemplo, depois que um modelo é treinado com dados de áudio em uma região com hardware dedicado para treinamento, você pode copiá-lo para um recurso de fala em outra região, conforme necessário.
Siga estas instruções para copiar um modelo para um projeto em outra região:
- Inicie sessão no Speech Studio.
- Selecione Fala> personalizada Seu nome >de projeto Treinar modelos personalizados.
- Selecione Copiar para.
-
Na página Copiar modelo de fala, selecione uma região de destino onde deseja copiar o modelo.

- Selecione um recurso de Fala na região de destino ou crie um novo recurso de Fala.
- Selecione um projeto onde você deseja copiar o modelo ou crie um novo projeto.
- Selecione Copiar.

Depois que o modelo for copiado com êxito, você será notificado e poderá visualizá-lo no projeto de destino.
Não há suporte para copiar um modelo diretamente para um projeto em outra região com a CLI de fala. Você pode copiar um modelo para um projeto em outra região usando o Speech Studio ou a API REST de fala para texto.
Para copiar um modelo para outro recurso de fala, use a operação Models_Copy da API REST de fala para texto. Construa o corpo da solicitação de acordo com as seguintes instruções:
- Defina a propriedade required
targetSubscriptionKeycomo a chave do recurso Speech de destino.
Faça uma solicitação HTTP POST usando o URI, conforme mostrado no exemplo a seguir. Use a região e o URI do modelo do qual você deseja copiar. Substitua YourModelId pela ID do modelo, substitua YourSubscriptionKey pela chave de recurso Fala, substitua YourServiceRegion pela região do recurso Fala e defina as propriedades do corpo da solicitação conforme descrito anteriormente.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"targetSubscriptionKey": "ModelDestinationSpeechResourceKey"
} ' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models/YourModelId:copy"
Nota
Somente a targetSubscriptionKey propriedade no corpo da solicitação tem informações sobre o recurso de fala de destino.
Deverá receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/eb5450a7-3ca2-461a-b2d7-ddbb3ad96540"
},
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae/manifest",
"copy": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae:copy"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-22T23:15:27Z",
"status": "NotStarted",
"createdDateTime": "2022-05-22T23:15:27Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description",
"customProperties": {
"PortalAPIVersion": "3",
"Purpose": "",
"VadKind": "None",
"ModelClass": "None",
"UsesHalide": "False",
"IsDynamicGrammarSupported": "False"
}
}
Conectar um modelo
Os modelos podem ter sido copiados de um projeto usando a CLI de fala ou a API REST, sem estarem conectados a outro projeto. Conectar um modelo é uma questão de atualizar o modelo com uma referência ao projeto.
Se você for solicitado no Speech Studio, poderá conectá-los selecionando o botão Conectar .
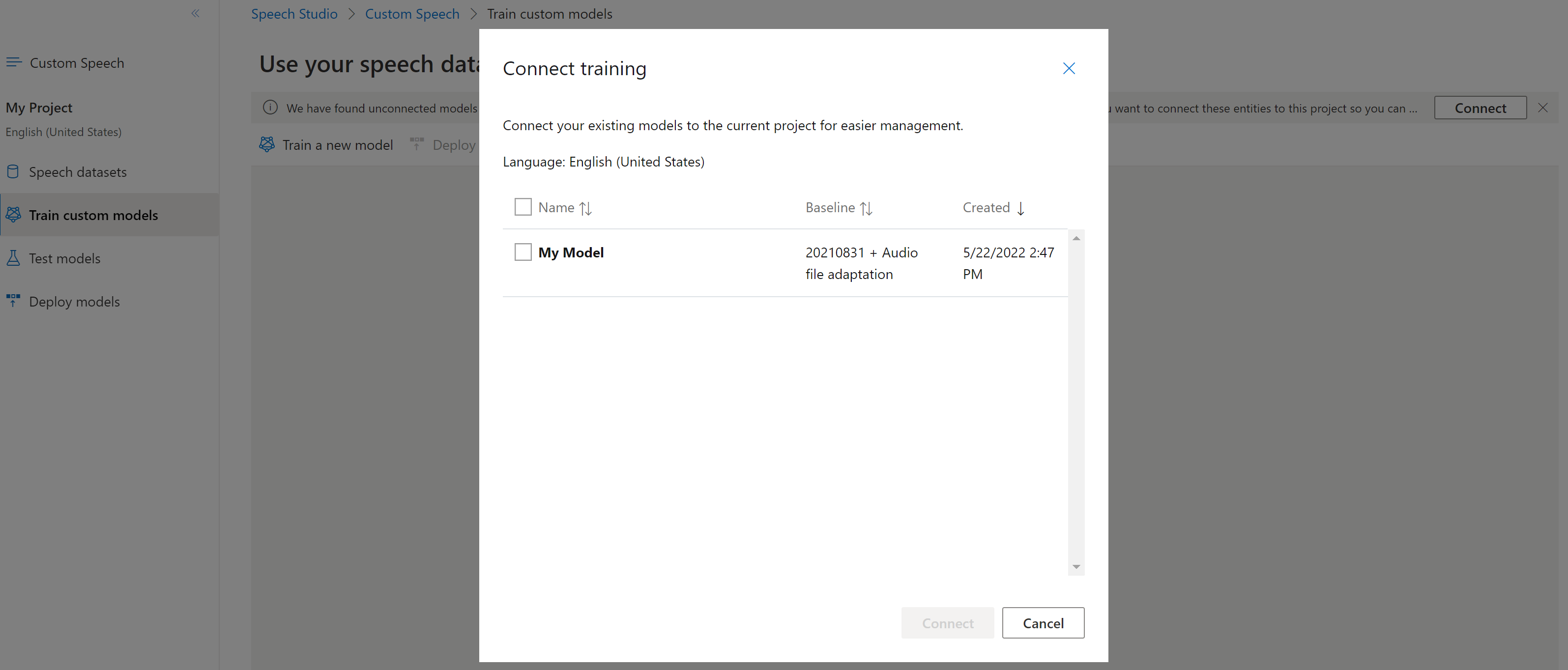
Para conectar um modelo a um projeto, use o spx csr model update comando. Construa os parâmetros de solicitação de acordo com as seguintes instruções:
- Defina o
projectparâmetro para o URI de um projeto existente. Esse parâmetro é recomendado para que você também possa exibir e gerenciar o modelo no Speech Studio. Você pode executar ospx csr project listcomando para obter projetos disponíveis. - Defina o parâmetro necessário
modelIdpara a ID do modelo que você deseja conectar ao projeto.
Aqui está um exemplo de comando da CLI de fala que conecta um modelo a um projeto:
spx csr model update --api-version v3.2 --model YourModelId --project YourProjectId
Deverá receber um corpo de resposta no seguinte formato:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}
Para obter ajuda da CLI de fala com modelos, execute o seguinte comando:
spx help csr model
Para conectar um novo modelo a um projeto do recurso Fala onde o modelo foi copiado, use a operação Models_Update da API REST de fala para texto. Construa o corpo da solicitação de acordo com as seguintes instruções:
- Defina a propriedade necessária
projectpara o URI de um projeto existente. Essa propriedade é recomendada para que você também possa exibir e gerenciar o modelo no Speech Studio. Você pode fazer uma solicitação de Projects_List para obter projetos disponíveis.
Faça uma solicitação HTTP PATCH usando o URI, conforme mostrado no exemplo a seguir. Use o URI do novo modelo. Você pode obter a nova ID do modelo da self propriedade do corpo da resposta Models_Copy . Substitua YourSubscriptionKey pela chave de recurso Fala, substitua YourServiceRegion pela região de recurso Fala e defina as propriedades do corpo da solicitação conforme descrito anteriormente.
curl -v -X PATCH -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/models"
Deverá receber um corpo de resposta no seguinte formato:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
}