O que é Observabilidade de Rede de Contêineres?
A Observabilidade da Rede de Contêineres é um recurso do pacote Advanced Container Networking Services . Ele o equipa com ferramentas de monitoramento e diagnóstico de próximo nível, fornecendo visibilidade incomparável de suas cargas de trabalho em contêineres. Essas ferramentas permitem que você identifique e solucione problemas de rede com facilidade, garantindo o desempenho ideal para seus aplicativos.
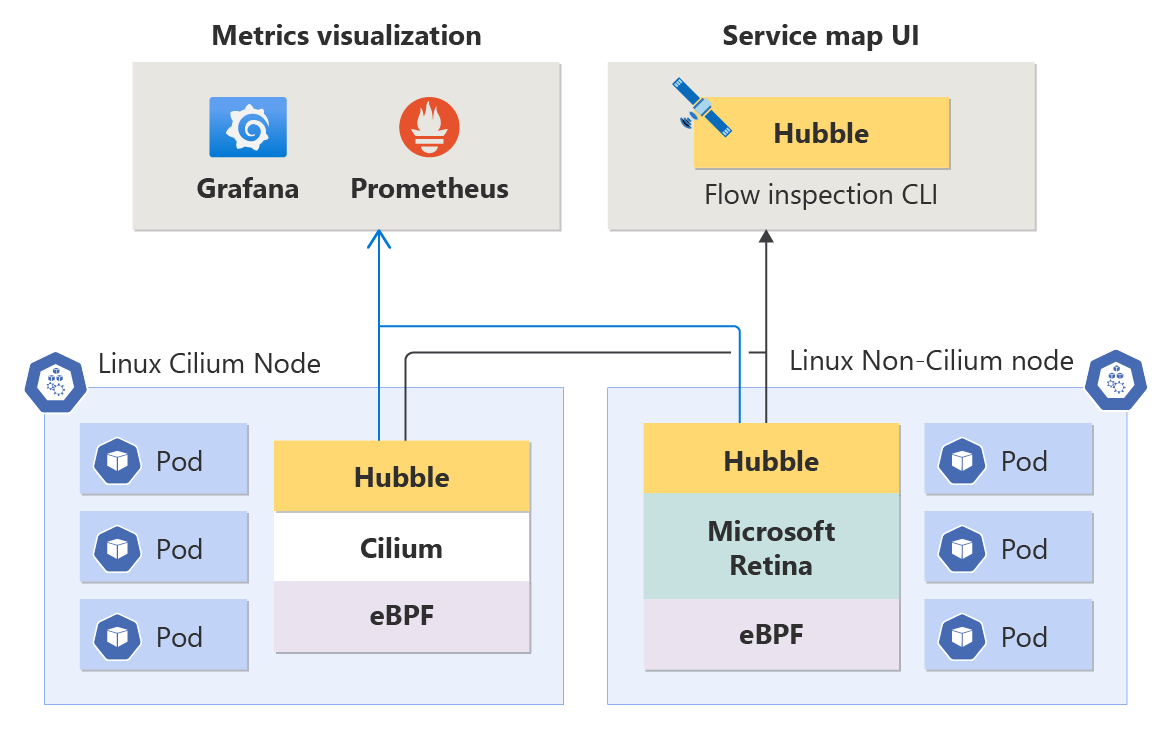
O Container Network Observability é compatível com todas as cargas de trabalho do Linux, integrando-se perfeitamente ao Hubble, independentemente de o plano de dados subjacente ser Cilium ou não-Cilium (ambos são suportados), garantindo flexibilidade para suas necessidades de rede de contêiner.
Nota
Para cenários de plano de dados do Cilium, a Observabilidade de Rede de Contêiner está disponível a partir da versão 1.29 do Kubernetes. A Observabilidade de Rede de Contêineres é suportada em todas as distribuições Linux, incluindo o Azure Linux a partir da versão 2.0.
Características da Observabilidade da Rede de Contêineres
A Observabilidade de Rede de Contêiner oferece os seguintes recursos para monitorar problemas relacionados à rede em seu cluster:
Métricas no nível do nó: Compreender a integridade da sua rede de contêiner no nível do nó é crucial para manter o desempenho ideal do aplicativo. Essas métricas fornecem informações sobre o volume de tráfego, pacotes descartados, número de conexões, etc. por nó. As métricas são armazenadas no formato Prometheus e, como tal, você pode visualizá-las no Grafana.
Métricas do Hubble (DNS e métricas no nível do pod): essas métricas do Prometheus incluem informações do pod de origem e destino, permitindo que você identifique problemas relacionados à rede em um nível granular. As métricas abrangem volume de tráfego, pacotes descartados, redefinições de TCP, fluxos de pacotes L4/L7, etc. Há também métricas de DNS (atualmente apenas para planos de dados não-Cilium), cobrindo erros de DNS e solicitações de DNS sem respostas.
Logs de fluxo do Hubble: os logs de fluxo fornecem visibilidade profunda da atividade de rede do cluster. Todas as comunicações de e para pods são registradas, permitindo que você investigue problemas de conectividade ao longo do tempo. Os logs de fluxo ajudam a responder a perguntas como: o servidor recebeu a solicitação do cliente? Qual é a latência de ida e volta entre a solicitação do cliente e a resposta do servidor?
CLI do Hubble: A CLI (Interface de Linha de Comando) do Hubble pode recuperar logs de fluxo em todo o cluster com filtragem e formatação personalizáveis.
Interface do usuário do Hubble: A interface do usuário do Hubble é uma interface amigável baseada em navegador para explorar a atividade da rede do cluster. Ele cria um gráfico de conexão de serviço com base em logs de fluxo e exibe logs de fluxo para o namespace selecionado. Os usuários são responsáveis pelo provisionamento e gerenciamento da infraestrutura necessária para executar a interface do usuário do Hubble.
Principais benefícios da observabilidade da rede de contêineres
CNI-Agnostic: suportado em todas as variantes do Azure CNI, incluindo kubenet.
Cilium e Non-Cilium: Fornece uma experiência uniforme e perfeita em planos de dados Cilium e não-Cilium.
Observação de rede baseada em eBPF: aproveita o eBPF (Berkeley Packet Filter estendido) para desempenho e escalabilidade para identificar possíveis gargalos e problemas de congestionamento antes que eles afetem o desempenho do aplicativo. Obtenha informações sobre os principais indicadores de integridade da rede, incluindo volume de tráfego, pacotes descartados e informações de conexão.
Visibilidade profunda da atividade da rede: entenda como seus aplicativos estão se comunicando entre si por meio de logs de fluxo de rede detalhados.
Opções simplificadas de armazenamento e visualização de métricas: escolha entre:
- Azure Managed Prometheus e Grafana: o Azure gere a infraestrutura e a manutenção, permitindo que os utilizadores se concentrem na configuração e visualização de métricas.
- Bring Your Own (BYO) Prometheus e Grafana: Os usuários implantam e configuram suas próprias instâncias e gerenciam a infraestrutura subjacente.
Métricas
Métricas no nível do nó
As métricas a seguir são agregadas por nós. Todas as métricas incluem rótulos:
clusterinstance(Nome do nó)
Para cenários de plano de dados da Cilium, a Observabilidade de Rede de Contêiner fornece métricas apenas para Linux, o Windows não é suportado no momento. O Cilium expõe várias métricas, incluindo as seguintes usadas pela Observabilidade da Rede de Contêineres.
| Nome da Métrica | Description | Etiquetas Extras | Linux | Windows |
|---|---|---|---|---|
| cilium_forward_count_total | Contagem total de pacotes encaminhados | direction |
✅ | ❌ |
| cilium_forward_bytes_total | Contagem total de bytes encaminhados | direction |
✅ | ❌ |
| cilium_drop_count_total | Contagem total de pacotes descartados | direction, reason |
✅ | ❌ |
| cilium_drop_bytes_total | Total de bytes caídos | direction, reason |
✅ | ❌ |
Métricas de nível de pod (métricas do Hubble)
As métricas a seguir são agregadas por pod (as informações do nó são preservadas). Todas as métricas incluem rótulos:
clusterinstance(Nome do nó)sourceoudestination
Para o tráfego de saída, haverá um source rótulo com namespace/nome do pod de origem.
Para o tráfego de entrada, haverá um destination rótulo com namespace/nome do pod de destino.
| Nome da Métrica | Description | Etiquetas Extras | Linux | Windows |
|---|---|---|---|---|
| hubble_dns_queries_total | Total de solicitações DNS por consulta | source ou destination, query, qtypes (tipo de consulta) |
✅ | ❌ |
| hubble_dns_responses_total | Total de respostas DNS por consulta/resposta | source ou destination, query, qtypes (tipo de consulta), rcode (código de retorno), ips_returned (número de IPs) |
✅ | ❌ |
| hubble_drop_total | Contagem total de pacotes descartados | source ou destination, protocol, reason |
✅ | ❌ |
| hubble_tcp_flags_total | Total de pacotes TCP contam por sinalizador. | source ou destination, flag |
✅ | ❌ |
| hubble_flows_processed_total | Total de fluxos de rede processados (tráfego L4/L7) | source ou destination, protocol, verdict, type, subtype |
✅ | ❌ |
Limitações
- As métricas de nível de pod estão disponíveis apenas no Linux.
- O plano de dados Cilium é suportado a partir do Kubernetes versão 1.29.
- Os rótulos métricos podem ter diferenças sutis entre os clusters Cilium e non-Cilium.
- Para clusters baseados em Cilium, as métricas de DNS só estão disponíveis para pods que têm políticas de rede Cilium (CNP) configuradas em seus clusters.
- Os logs de fluxo não estão atualmente disponíveis na nuvem com ar comprimido.
- O relé do Hubble pode falhar se um dos agentes do nó do Hubble cair e pode causar interrupções na CLI do Hubble.
Escala
O Azure gerenciado Prometheus e o Grafana impõem limitações de escala específicas do serviço. Para obter mais informações, consulte Raspar métricas do Prometheus em escala no Azure Monitor.
Preços
Importante
Advanced Container Networking Services é uma oferta paga. Para obter mais informações sobre preços, consulte Advanced Container Networking Services - Pricing.
Próximos passos
- Para criar um cluster AKS com Observabilidade de Rede de Contêiner, consulte Configurar a Observabilidade de Rede de Contêiner para o Serviço Kubernetes do Azure (AKS).

Azure Kubernetes Service