As arquiteturas de macrodados servem para processar a ingestão, o processamento e a análise de dados que sejam demasiado grandes ou complexos para os sistemas de base de dados tradicionais. O limiar em que as organizações entram no domínio dos macrodados difere consoante as capacidades dos utilizadores e as respetivas ferramentas. Para alguns utilizadores, pode significar centenas de gigabytes de dados, enquanto para outros significa centenas de terabytes. À medida que as ferramentas para trabalhar com grandes conjuntos de dados avançam, o mesmo acontece com o significado de big data. Cada vez mais, este termo está relacionado com o valor que pode extrair dos seus conjuntos de dados através de análise avançada, em vez de se referir estritamente ao tamanho dos dados, embora nestes casos os dados sejam tendencialmente grandes.
Ao longo dos anos, o panorama dos dados mudou. O que pode fazer com os dados, ou o que é esperado que faça, mudou. O custo de armazenamento baixou significativamente, enquanto os meios através dos quais os dados são recolhidos continuam a crescer. Alguns dados são recebidos rapidamente, requerendo constantemente a respetiva recolha e observação. Outros dados são recebidos mais lentamente, mas em segmentos muito grandes, muitas vezes sob a forma de décadas de dados históricos. Poderá deparar-se com um problema de análise avançada ou outro problema que requeira a aprendizagem automática. Estes são os desafios que as arquiteturas de macrodados procuram resolver.
Normalmente, as soluções de macrodados envolvem um ou mais dos seguintes tipos de cargas de trabalho:
- Processamento em lotes de origens de macrodados inativas.
- Processamento em tempo real de macrodados em movimento.
- Exploração interativa de macrodados.
- Análise preditiva e machine learning.
Considere arquiteturas de macrodados quando precisar de:
- Armazenar e processar dados em volumes demasiados grandes para uma base de dados tradicional.
- Transformar dados não estruturados para análises e relatórios.
- Capturar, processar e analisar fluxos independentes de dados em tempo real ou com baixa latência.
Componentes de uma arquitetura de macrodados
O diagrama seguinte mostra os componentes lógicos que se enquadram numa arquitetura de macrodados. As soluções individuais poderão não conter todos os itens neste diagrama.
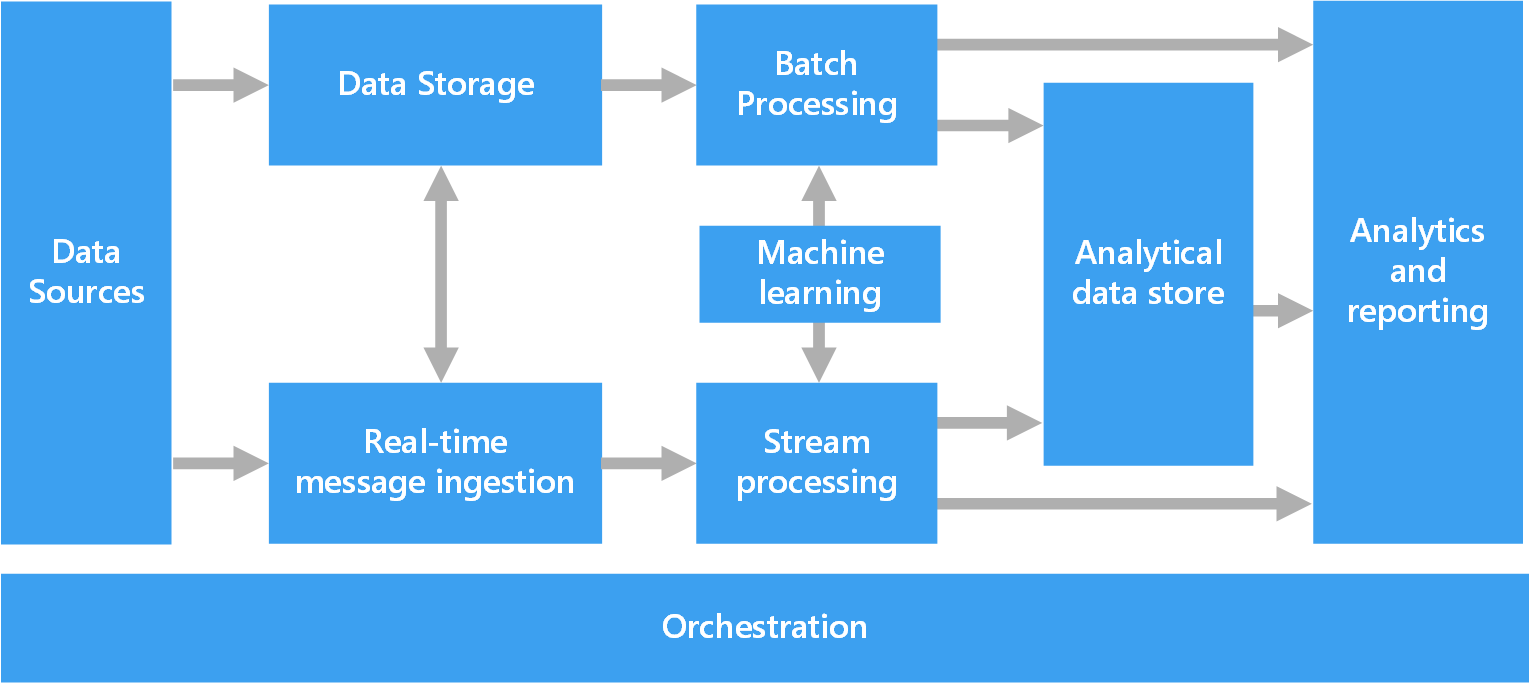
A maioria das arquiteturas de macrodados incluem alguns ou todos os componentes abaixo:
Origens de dados. Todas as soluções de macrodados começam com uma ou mais origens de dados. Exemplos incluem:
- Arquivos de dados de armazenamento, como bases de dados relacionais.
- Ficheiros estáticos produzidos por aplicações, como ficheiros de registo de servidores Web.
- Origens de dados em tempo real, como dispositivos IoT.
Armazenamento de dados. Os dados para as operações de processamento em lotes são, normalmente, armazenados num arquivo de ficheiros distribuído que pode incluir elevados volumes de ficheiros grandes em diferentes formatos. Este tipo de arquivo é, muitas vezes, conhecido como data lake. As opções para implementar este armazenamento incluem contentores do Azure Data Lake Store ou contentores de blobs no Armazenamento do Azure.
Processamento em lotes. Uma vez que os conjuntos de dados são tão grandes, muitas vezes, as soluções de macrodados têm de processar os ficheiros de dados através de tarefas em lote de execução longa para filtrar, agregar e preparar os dados para análise. Normalmente, estes trabalhos envolvem ler os ficheiros de origem, processá-los e escrever a saída em ficheiros novos. As opções incluem executar trabalhos de U-SQL no Azure Data Lake Analytics, utilizar trabalhos de Hive, Pig ou Map/Reduce personalizados num cluster Hadoop do HDInsight ou utilizar programas de Java, Scala ou Python num cluster do HDInsight Spark.
Ingestão de mensagens em tempo real. Se a solução incluir origens em tempo real, a arquitetura tem de ter uma forma de capturar e armazenar as mensagens em tempo real para o processamento de fluxos. Pode ser um arquivo de dados simples, no qual as mensagens recebidas são largadas numa pasta para processamento. No entanto, muitas soluções precisam que o arquivo de ingestão de mensagens funcione como memória intermédia para as mensagens e que suporte o processamento de escalamento horizontal, a entrega fiável e outras semânticas de colocação de mensagens em fila. Esta parte de uma arquitetura de transmissão em fluxo é frequentemente referida como colocação em memória intermédia de fluxo. As opções incluem os Hubs de Eventos do Azure, o Hub IoT do Azure e o Kafka.
Processamento de fluxos. Após a captura das mensagens em tempo real, a solução tem de processá-las ao filtrar, agregar e preparar os dados para análise. Os dados de fluxos processados são, depois, escritos num sink de saída. O Azure Stream Analytics disponibiliza um serviço de processamento em fluxo gerido e baseado em consultas SQL de execução permanente que funcionam em fluxos independentes. Você também pode usar tecnologias de streaming Apache de código aberto, como o Spark Streaming, em um cluster HDInsight.
Aprendizagem automática. Lendo os dados preparados para análise (de processamento em lote ou fluxo), algoritmos de aprendizado de máquina podem ser usados para construir modelos que podem prever resultados ou classificar dados. Esses modelos podem ser treinados em grandes conjuntos de dados, e os modelos resultantes podem ser usados para analisar novos dados e fazer previsões. Isso pode ser feito usando o Azure Machine Learning
Arquivo de dados analíticos. Muitas soluções de macrodados preparam os dados para análise e, em seguida, disponibilizam os dados processados num formato estruturado que pode ser consultado com ferramentas analíticas. O arquivo de dados analíticos utilizado para disponibilizar estas consultas pode ser um armazém de dados relacional do tipo Kimball, conforme se vê na maioria das soluções de business intelligence (BI) tradicionais. Em alternativa, os dados podem ser apresentados através de uma tecnologia NoSQL de baixa latência, como o HBase, ou de uma base de dados interativa Hive que fornece uma abstração de metadados em ficheiros de dados no arquivo de dados distribuído. O Azure Synapse Analytics fornece um serviço gerido para armazéns de dados com base na cloud e de grande escala. O HDInsight suporta o Interactive Hive, o HBase e o Spark SQL, que também podem ser utilizados para disponibilizar os dados para análise.
Análises e relatórios. O objetivo da maioria das soluções de macrodados é proporcionar informações sobre os dados através de análises e relatórios. Para permitir aos utilizadores analisar os dados, a arquitetura pode incluir uma camada de modelação de dados, como um cubo OLAP multidimensional ou um modelo de dados em tabela no Azure Analysis Services. Também pode suportar business intelligence de gestão personalizada através da utilização das tecnologias de modelação e visualização no Microsoft Power BI ou no Microsoft Excel. As análises e os relatórios também podem assumir a forma de exploração de dados interativa por parte de cientistas de dados ou analistas de dados. Para esses cenários, muitos serviços do Azure oferecem suporte a blocos de anotações analíticos, como o Jupyter, permitindo que esses usuários usem suas habilidades existentes com Python ou Microsoft R. Para exploração de dados em grande escala, você pode usar o Microsoft R Server, autônomo ou com o Spark.
Orquestração. A maioria das soluções de macrodados consiste em operações de processamento de dados repetidas, encapsuladas em fluxos de trabalho, que transformam os dados de origem, movem os dados entre várias origens e sinks, carregam os dados processados para um arquivo de dados analíticos ou enviam os resultados diretamente para um relatório ou dashboard. Para automatizar estes fluxos de trabalho, pode utilizar uma tecnologia de orquestração como o Azure Data Factory ou o Apache Oozie e o Sqoop.
Arquitetura Lambda
Ao trabalhar com conjuntos de dados muito grandes, a execução do tipo de consultas de que os clientes precisam pode demorar muito tempo. Estas consultas não podem ser efetuadas em tempo real e, muitas vezes, necessitam de algoritmos, como o MapReduce, que funcionam em paralelo em todo o conjunto de dados. Os resultados são então armazenados separadamente dos dados não processados e utilizados para consultas.
Uma desvantagem dessa abordagem é que ela introduz latência — se o processamento demorar algumas horas, uma consulta pode retornar resultados com várias horas de idade. Idealmente, gostaria de obter alguns resultados em tempo real (talvez com alguma perda de precisão) e combinar estes resultados com os resultados da análise de lotes.
A arquitetura de lambda, proposta pela primeira vez por Nathan Marz, aborda este problema através da criação de dois caminhos para o fluxo de dados. Todos os dados que entram no sistema passam por estes dois caminhos:
Uma camada de lotes (caminho típico) armazena todos os dados recebidos no respetivo formato não processado e efetua o processamento em lotes dos dados. O resultado deste processamento é armazenado como uma vista de lotes.
Uma camada de velocidade (caminho instantâneo) analisa os dados em tempo real. Esta camada foi concebida para baixa latência, em detrimento da precisão.
A camada de lotes é inserida numa camada de entrega, que indexa a vista de lotes para uma consulta eficiente. A camada de velocidade atualiza a camada de entrega com atualizações incrementais, com base nos dados mais recentes.
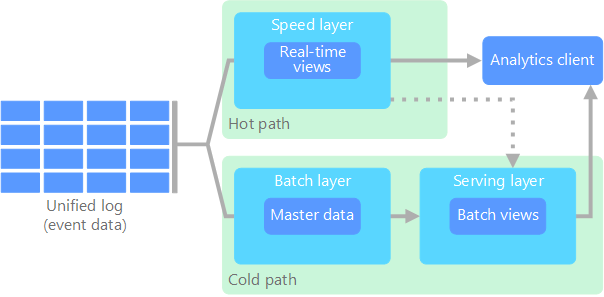
Os dados que fluem para o caminho instantâneo são restringidos pelos requisitos de latência impostos pela camada de velocidade, para que possam ser processados o mais rapidamente possível. Muitas vezes, isto requer um compromisso de algum nível de precisão a favor dos dados que ficam prontos o mais rapidamente possível. Por exemplo, considere um cenário de IoT em que um grande número de sensores de temperatura está a enviar dados de telemetria. A camada de velocidade pode ser utilizada para processar uma janela deslizante de tempo dos dados recebidos.
Os dados que fluem para o caminho típico, por outro lado, não estão sujeitos aos mesmos requisitos de latência baixa. Isto permite a computação com precisão elevada em grandes conjuntos de dados, o que pode ser muito exigente em termos de tempo.
Os caminhos instantâneos e típicos acabam por convergir na aplicação cliente de análise. Se o cliente precisar da apresentação atempada mas potencialmente menos precisa dos dados em tempo real, obterá o resultado do caminho instantâneo. Caso contrário, seleciona os resultados do caminho típico para apresentar dados menos atempados mas mais exatos. Por outras palavras, o caminho instantâneo inclui dados de uma janela de tempo relativamente pequena, após a qual os resultados podem ser atualizados com os dados mais exatos do caminho típico.
Os dados não processados armazenados na camada de lotes são imutáveis. Os dados recebidos são sempre anexados aos dados existentes e os dados anteriores nunca são substituídos. Quaisquer alterações ao valor de um dado específico são armazenadas como um novo registo de evento com carimbo de data/hora. Isto permite o reprocessamento em qualquer ponto no tempo do histórico dos dados recolhidos. A capacidade de reprocessar a vista de lotes dos dados não processados originais é importante, porque permite a criação de novas vistas à medida que o sistema evolui.
Arquitetura Kappa
Uma desvantagem da arquitetura de lambda é a sua complexidade. A lógica de processamento aparece em dois lugares diferentes — os caminhos frio e quente — usando estruturas diferentes. Isto dá origem a lógica de computação duplicada e à complexidade de gerir a arquitetura dos dois caminhos.
A arquitetura de kappa foi proposta por Jay Kreps como alternativa à arquitetura de lambda. Tem os mesmos objetivos básicos da arquitetura de lambda, mas com uma distinção importante: todos os dados fluem através de um caminho único, com um sistema de processamento de fluxos.
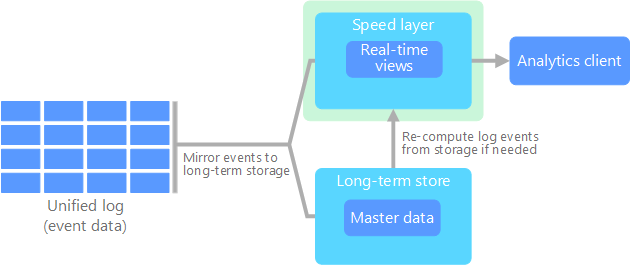
Existem algumas semelhanças com a camada de lotes da arquitetura de lambda, uma vez que os dados de eventos são imutáveis e são todos recolhidos, ao invés de um subconjunto. Os dados são ingeridos como um fluxo de eventos para um registo distribuído e unificado com tolerância a falhas. Estes eventos são ordenados e o estado atual de um evento é alterado apenas por um novo evento que está a ser anexado. Da mesma forma que na camada de velocidade de uma arquitetura de lambda, todo o processamento de eventos é efetuado no fluxo de entrada e é persistente como uma vista em tempo real.
Se precisar de reprocessar todo o conjunto de dados (equivalente ao que a camada de lotes faz na arquitetura de lambda), basta reproduzir o fluxo, normalmente utilizando o paralelismo para concluir a computação de forma atempada.
Internet das Coisas (IoT)
De uma perspetiva prática, a Internet das Coisas (IoT) representa qualquer dispositivo que esteja ligado à Internet. Isto inclui o seu PC, telemóvel, relógio inteligente, termóstato inteligente, frigorífico inteligente, automóvel ligado, implantes de monitorização cardíaca e tudo o que estabeleça ligação à Internet e envie ou receba dados. O número de dispositivos ligados aumenta diariamente, bem como a quantidade de dados recolhidos dos mesmos. Muitas vezes, estes dados são recolhidos em ambientes altamente restritos, por vezes, de alta latência. Noutros casos, os dados são enviados de ambientes de latência baixa por milhares ou milhões de dispositivos, que requerem a capacidade de rapidamente incorporar os dados e processá-los em conformidade. Por conseguinte, é necessário um planeamento adequado para processar estas restrições e os requisitos exclusivos.
As arquiteturas condicionadas por eventos estão no centro das soluções de IoT. O diagrama seguinte mostra uma arquitetura lógica possível para IoT. O diagrama realça os componentes de transmissão em fluxo de eventos da arquitetura.
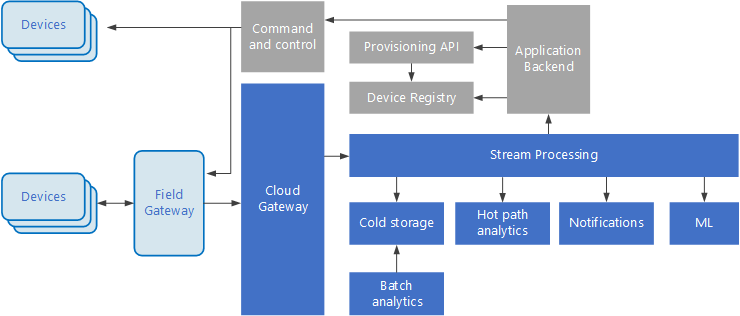
O gateway de cloud ingere os eventos de dispositivos no limite da cloud, através de um sistema de mensagens fiável de baixa latência.
Os dispositivos podem enviar eventos diretamente para o gateway de cloud ou através de um gateway de campo. Um gateway de campo é um software ou dispositivo especializado, normalmente na mesma localização dos dispositivos, que recebe eventos e os reencaminha para o gateway de cloud. O gateway de campo também pode pré-processar os eventos de dispositivos não processados, ao executar funções como a filtragem, a agregação ou a transformação de protocolos.
Após a ingestão, os eventos passam por um ou mais processadores de fluxos que podem encaminhar os dados (por exemplo, para o armazenamento) ou realizar análises e outros processamentos.
Seguem-se alguns tipos comuns de processamento. (Esta lista não é de todo exaustiva.)
Escrita de dados de eventos no armazenamento amovível, para arquivo ou análise de lotes.
Análise de caminhos de acesso frequente, mediante a análise do fluxo de eventos (quase) em tempo real, para detetar anomalias, reconhecer padrões ao longo de períodos de tempo sucessivos ou acionar alertas quando ocorre uma condição específica no fluxo.
Processamento de tipos especiais de mensagens sem ser de telemetria provenientes dos dispositivos, como notificações e alarmes.
Aprendizagem automática (Machine Learning).
As caixas apresentadas com um sombreado cinzento mostram os componentes de um sistema de IoT que não estão diretamente relacionados com a transmissão em fluxo de eventos, mas são incluídos aqui a fim de proporcionar uma perspetiva completa.
O registo de dispositivos é uma base de dados de dispositivos aprovisionados, incluindo os IDs dos dispositivos e, normalmente, os metadados dos dispositivos, como a localização.
A API de aprovisionamento é uma interface externa comum para aprovisionar e registar novos dispositivos.
Algumas soluções de IoT permitem o envio de mensagens de comando e controlo para os dispositivos.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Zoiner Tejada - Brasil | CEO e Arquiteto
Próximos passos
Consulte os seguintes serviços relevantes do Azure: