Essa arquitetura fornece orientação para projetar uma carga de trabalho de missão crítica no Azure. Ele usa recursos nativos da nuvem para maximizar a confiabilidade e a eficácia operacional. Ele aplica a metodologia de design para cargas de trabalho de missão crítica Well-Architected a um aplicativo voltado para a Internet, onde a carga de trabalho é acessada por um ponto de extremidade público e não requer conectividade de rede privada com outros recursos da empresa.
Importante
 A orientação é apoiada por uma implementação de exemplo de nível de produção que mostra o desenvolvimento de aplicativos de missão crítica no Azure. Esta implementação pode ser usada como base para o desenvolvimento de soluções adicionais no seu primeiro passo para a produção.
A orientação é apoiada por uma implementação de exemplo de nível de produção que mostra o desenvolvimento de aplicativos de missão crítica no Azure. Esta implementação pode ser usada como base para o desenvolvimento de soluções adicionais no seu primeiro passo para a produção.
Nível de fiabilidade
A confiabilidade é um conceito relativo e, para que uma carga de trabalho seja adequadamente confiável, ela deve refletir os requisitos de negócios em torno dela, incluindo Objetivos de Nível de Serviço (SLO) e Contratos de Nível de Serviço (SLA), para capturar a porcentagem de tempo em que o aplicativo deve estar disponível.
Esta arquitetura visa um SLO de 99,99%, o que corresponde a um tempo de inatividade anual permitido de 52 minutos e 35 segundos. Todas as decisões de projeto englobadas são, portanto, destinadas a cumprir esse SLO alvo.
Gorjeta
Para definir um SLO realista, é importante entender os objetivos de confiabilidade de todos os componentes do Azure e outros fatores dentro do escopo da arquitetura. Para obter mais informações, consulte Recomendações para definir metas de confiabilidade. Esses números individuais devem ser agregados para determinar um SLO composto que deve ser alinhado com as metas de carga de trabalho.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: Design para requisitos de negócios.
Principais estratégias de design
Muitos fatores podem afetar a confiabilidade de um aplicativo, como a capacidade de recuperação de falhas, disponibilidade regional, eficácia de implantação e segurança. Essa arquitetura aplica um conjunto de estratégias de design abrangentes destinadas a abordar esses fatores e garantir que o nível de confiabilidade desejado seja alcançado.
Redundância em camadas
Implante em várias regiões em um modelo ativo-ativo. O aplicativo é distribuído em duas ou mais regiões do Azure que lidam com o tráfego de usuário ativo.
Utilize zonas de disponibilidade para todos os serviços considerados para maximizar a disponibilidade em uma única região do Azure, distribuindo componentes entre data centers fisicamente separados dentro de uma região.
Escolha recursos que suportem a distribuição global.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: distribuição global.
Selos de implantação
Implante um carimbo regional como uma unidade de escala onde um conjunto lógico de recursos pode ser provisionado de forma independente para acompanhar as mudanças na demanda. Cada carimbo também aplica várias unidades de escala aninhadas, como APIs Frontend e processadores em segundo plano que podem ser dimensionados de forma independente.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: arquitetura de unidade de escala.
Implantações confiáveis e repetíveis
Aplicar o princípio de Infraestrutura como código (IaC) usando tecnologias, como Terraform, para fornecer controle de versão e uma abordagem operacional padronizada para componentes de infraestrutura.
Implemente pipelines de implantação azul/verde sem tempo de inatividade. Os pipelines de construção e liberação devem ser totalmente automatizados para implantar carimbos como uma única unidade operacional, usando implantações azuis/verdes com validação contínua aplicada.
Aplique a consistência do ambiente em todos os ambientes considerados, com o mesmo código de pipeline de implantação em ambientes de produção e pré-produção. Isso elimina os riscos associados à implantação e às variações de processo entre ambientes.
Tenha validação contínua integrando testes automatizados como parte dos processos de DevOps, incluindo testes sincronizados de carga e caos, para validar totalmente a integridade do código do aplicativo e da infraestrutura subjacente.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: implantação e teste.
Insights operacionais
Ter espaços de trabalho federados para dados de observabilidade. Os dados de monitoramento para recursos globais e recursos regionais são armazenados de forma independente. Um armazenamento centralizado de observabilidade não é recomendado para evitar um único ponto de falha. A consulta entre espaços de trabalho é usada para obter um coletor de dados unificado e um único painel de vidro para operações.
Construa um modelo de integridade em camadas que mapeie a integridade do aplicativo para um modelo de semáforo para contextualização. As pontuações de integridade são calculadas para cada componente individual e, em seguida, agregadas em um nível de fluxo de usuário e combinadas com os principais requisitos não funcionais, como desempenho, como coeficientes para quantificar a integridade do aplicativo.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: Modelagem de integridade.
Arquitetura

*Faça o download de um arquivo Visio desta arquitetura.
Os componentes dessa arquitetura podem ser amplamente categorizados dessa maneira. Para obter a documentação do produto sobre os serviços do Azure, consulte Recursos relacionados.
Recursos globais
Os recursos globais são de longa duração e partilham a vida útil do sistema. Eles têm a capacidade de estar disponíveis globalmente no contexto de um modelo de implantação multirregional.
Aqui estão as considerações de alto nível sobre os componentes. Para obter informações detalhadas sobre as decisões, consulte Recursos globais.
Balanceador de carga global
Um balanceador de carga global é fundamental para rotear o tráfego de forma confiável para as implantações regionais com algum nível de garantia com base na disponibilidade de serviços de back-end em uma região. Além disso, esse componente deve ter a capacidade de inspecionar o tráfego de entrada, por exemplo, por meio do firewall de aplicativos da Web.
O Azure Front Door é usado como o ponto de entrada global para todo o tráfego HTTP(S) do cliente de entrada, com recursos do Web Application Firewall (WAF) aplicados para proteger o tráfego de entrada da Camada 7. Ele usa TCP Anycast para otimizar o roteamento usando a rede de backbone da Microsoft e permite failover transparente no caso de integridade regional degradada. O roteamento depende de testes de integridade personalizados que verificam a integridade composta dos principais recursos regionais. O Azure Front Door também fornece uma CDN (rede de entrega de conteúdo) interna para armazenar em cache ativos estáticos para o componente de site.
Outra opção é o Gerenciador de Tráfego, que é um balanceador de carga de Camada 4 baseado em DNS. No entanto, a falha não é transparente para todos os clientes, uma vez que a propagação do DNS deve ocorrer.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: roteamento de tráfego global.
Base de Dados
Todo o estado relacionado à carga de trabalho é armazenado em um banco de dados externo, o Azure Cosmos DB for NoSQL. Esta opção foi escolhida porque tem o conjunto de recursos necessários para ajuste de desempenho e confiabilidade, tanto no lado do cliente quanto do servidor. É altamente recomendável que a conta tenha a gravação multimestre habilitada.
Nota
Embora uma configuração de gravação em várias regiões represente o padrão ouro para confiabilidade, há um compromisso significativo no custo, que deve ser devidamente considerado.
A conta é replicada para cada selo regional e também tem redundância zonal habilitada. Além disso, o dimensionamento automático é habilitado no nível do contêiner para que os contêineres dimensionem automaticamente a taxa de transferência provisionada conforme necessário.
Para obter mais informações, consulte Plataforma de dados para cargas de trabalho de missão crítica.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: armazenamento de dados de várias gravações distribuído globalmente.
Registo de contentor
O Registro de Contêiner do Azure é usado para armazenar todas as imagens de contêiner. Ele tem recursos de replicação geográfica que permitem que os recursos funcionem como um único registro, atendendo a várias regiões com registros regionais multimestres.
Como medida de segurança, permita apenas o acesso às entidades necessárias e autentique esse acesso. Por exemplo, na implementação, o acesso de administrador está desativado. Assim, o cluster de computação pode extrair imagens somente com atribuições de função do Microsoft Entra.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: Registro de contêiner.
Recursos regionais
Os recursos regionais são provisionados como parte de um carimbo de implantação para uma única região do Azure. Estes recursos não partilham nada com os recursos de outra região. Eles podem ser removidos independentemente ou replicados para regiões adicionais. No entanto, partilham recursos globais entre si.
Nessa arquitetura, um pipeline de implantação unificado implanta um carimbo com esses recursos.
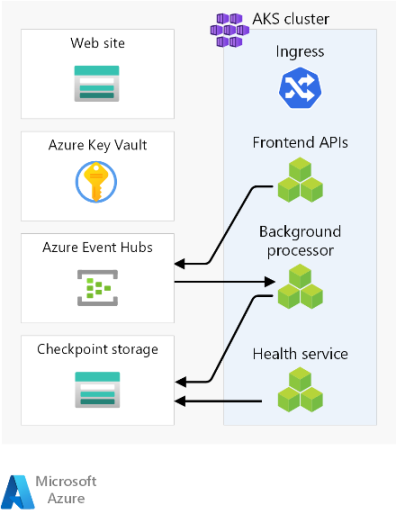
Aqui estão as considerações de alto nível sobre os componentes. Para obter informações detalhadas sobre as decisões, consulte Recursos de selo regionais.
Front-end
Essa arquitetura usa um aplicativo de página única (SPA) que envia solicitações para serviços de back-end. Uma vantagem é que a computação necessária para a experiência do site é descarregada para o cliente em vez de seus servidores. O SPA é hospedado como um site estático em uma Conta de Armazenamento do Azure.
Outra opção são os Aplicativos Web Estáticos do Azure, que introduz considerações adicionais, como a forma como os certificados são expostos, a conectividade com um balanceador de carga global e outros fatores.
O conteúdo estático normalmente é armazenado em cache em um armazenamento próximo ao cliente, usando uma rede de distribuição de conteúdo (CDN), para que os dados possam ser servidos rapidamente sem se comunicar diretamente com os servidores de back-end. É uma maneira econômica de aumentar a confiabilidade e reduzir a latência da rede. Nessa arquitetura, os recursos internos de CDN do Azure Front Door são usados para armazenar em cache conteúdo estático do site na rede de borda.
Cluster de cálculo
A computação de back-end executa um aplicativo composto por três microsserviços e é sem monitoração de estado. Portanto, a conteinerização é uma estratégia apropriada para hospedar o aplicativo. O Serviço Kubernetes do Azure (AKS) foi escolhido porque atende à maioria dos requisitos de negócios e o Kubernetes é amplamente adotado em muitos setores. O AKS suporta topologias avançadas de escalabilidade e implantação. A camada de SLA do AKS Uptime é altamente recomendada para hospedar aplicativos de missão crítica porque fornece garantias de disponibilidade para o plano de controle do Kubernetes.
O Azure oferece outros serviços de computação, como o Azure Functions e os Serviços de Aplicativo do Azure. Essas opções descarregam responsabilidades de gerenciamento adicionais para o Azure ao custo de flexibilidade e densidade.
Nota
Evite armazenar o estado no cluster de computação, tendo em mente a natureza efêmera dos selos. Na medida do possível, persista o estado em um banco de dados externo para manter as operações de dimensionamento e recuperação leves. Por exemplo, no AKS, os pods mudam frequentemente. Anexar o estado aos pods adicionará a carga da consistência dos dados.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: orquestração de contêineres e Kubernetes.
Agente de mensagens regional
Para otimizar o desempenho e manter a capacidade de resposta durante o pico de carga, o projeto usa mensagens assíncronas para lidar com fluxos intensivos do sistema. Como uma solicitação é rapidamente reconhecida de volta às APIs de frontend, a solicitação também é enfileirada em um agente de mensagens. Essas mensagens são posteriormente consumidas por um serviço de back-end que, por exemplo, lida com uma operação de gravação em um banco de dados.
O carimbo inteiro é apátrida, exceto em certos pontos, como este agente de mensagens. Os dados são enfileirados no broker por um curto período de tempo. O agente de mensagens deve garantir pelo menos uma vez a entrega. Isso significa que as mensagens estarão na fila, se o agente ficar indisponível depois que o serviço for restaurado. No entanto, é responsabilidade do consumidor determinar se essas mensagens ainda precisam de processamento. A fila é drenada depois que a mensagem é processada e armazenada em um banco de dados global.
Neste design, os Hubs de Eventos do Azure são usados. Uma conta de Armazenamento do Azure adicional é provisionada para ponto de verificação. Os Hubs de Eventos são a opção recomendada para casos de uso que exigem alta taxa de transferência, como streaming de eventos.
Para casos de uso que exigem garantias de mensagem adicionais, o Barramento de Serviço do Azure é recomendado. Ele permite confirmações em duas fases com um cursor do lado do cliente, bem como recursos como uma fila de letra morta interna e recursos de desduplicação.
Para obter mais informações, consulte Serviços de mensagens para cargas de trabalho de missão crítica.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: arquitetura orientada a eventos fracamente acoplada.
Loja secreta regional
Cada carimbo tem seu próprio Cofre da Chave do Azure que armazena segredos e configuração. Há segredos comuns, como cadeias de conexão com o banco de dados global, mas também há informações exclusivas de um único carimbo, como a cadeia de conexão dos Hubs de Eventos. Além disso, recursos independentes evitam um único ponto de falha.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: Proteção da integridade de dados.
Pipeline de implementação
Os pipelines de compilação e liberação para um aplicativo de missão crítica devem ser totalmente automatizados. Portanto, nenhuma ação deve precisar ser executada manualmente. Esse design demonstra pipelines totalmente automatizados que implantam um carimbo validado de forma consistente sempre. Outra abordagem alternativa é implantar apenas atualizações contínuas em um carimbo existente.
Repositório de código-fonte
O GitHub é usado para controle de código-fonte, fornecendo uma plataforma baseada em git altamente disponível para colaboração em código de aplicativo e código de infraestrutura.
Pipelines de Integração Contínua/Entrega Contínua (CI/CD)
Pipelines automatizados são necessários para criar, testar e implantar uma carga de trabalho de missão em ambientes de pré-produção e produção. O Azure Pipelines foi escolhido devido ao seu rico conjunto de ferramentas que pode ser direcionado ao Azure e a outras plataformas de nuvem.
Outra opção é o GitHub Actions para pipelines de CI/CD. O benefício adicional é que o código-fonte e o pipeline podem ser colocados. No entanto, o Azure Pipelines foi escolhido devido aos recursos de CD mais avançados.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: processos de DevOps.
Agentes de construção
Os agentes de compilação hospedados pela Microsoft são usados por essa implementação para reduzir a complexidade e a sobrecarga de gerenciamento. Os agentes auto-hospedados podem ser usados para cenários que exigem uma postura de segurança reforçada.
Nota
O uso de agentes auto-hospedados é demonstrado na implementação de referência Mission Critical - Connected .
Recursos de observabilidade
Os dados operacionais do aplicativo e da infraestrutura devem estar disponíveis para permitir operações eficazes e maximizar a confiabilidade. Esta referência fornece uma linha de base para alcançar a observabilidade holística de uma aplicação.
Coletor de dados unificado
- O Azure Log Analytics é usado como um coletor unificado para armazenar logs e métricas para todos os componentes de aplicativo e infraestrutura.
- O Azure Application Insights é usado como uma ferramenta de Gerenciamento de Desempenho de Aplicativo (APM) para coletar todos os dados de monitoramento de aplicativos e armazená-los diretamente no Log Analytics.

Os dados de monitorização dos recursos globais e regionais devem ser armazenados de forma independente. Um único armazenamento de observabilidade centralizado não é recomendado para evitar um único ponto de falha. A consulta entre espaços de trabalho é usada para obter um único painel de vidro.
Nessa arquitetura, o monitoramento de recursos dentro de uma região deve ser independente do selo em si, porque se você derrubar um selo, você ainda quer preservar a observabilidade. Cada selo regional tem seu próprio espaço de trabalho dedicado do Application Insights e do Log Analytics. Os recursos são provisionados por região, mas sobrevivem aos selos.
Da mesma forma, os dados de serviços compartilhados, como o Azure Front Door, o Azure Cosmos DB e o Container Registry, são armazenados em uma instância dedicada do Log Analytics Workspace.
Arquivamento e análise de dados
Os dados operacionais que não são necessários para operações ativas são exportados do Log Analytics para as Contas de Armazenamento do Azure para fins de retenção de dados e para fornecer uma fonte analítica para AIOps, que pode ser aplicada para otimizar o modelo de integridade do aplicativo e os procedimentos operacionais.
Consulte Cargas de trabalho de missão crítica bem arquitetadas: ação preditiva e operações de IA.
Fluxos de solicitação e processador
Esta imagem mostra a solicitação e o fluxo do processador em segundo plano da implementação de referência.

A descrição desse fluxo está nas seções a seguir.
Fluxo de solicitações do site
Uma solicitação para a interface do usuário da Web é enviada para um balanceador de carga global. Para essa arquitetura, o balanceador de carga global é o Azure Front Door.
As regras do WAF são avaliadas. As regras WAF afetam positivamente a confiabilidade do sistema, protegendo contra uma variedade de ataques, como cross-site scripting (XSS) e injeção de SQL. O Azure Front Door retornará um erro ao solicitante se uma regra WAF for violada e o processamento for interrompido. Se não houver regras WAF violadas, o Azure Front Door continuará processando.
O Azure Front Door usa regras de roteamento para determinar para qual pool de back-end encaminhar uma solicitação. Como as solicitações são correspondidas a uma regra de roteamento. Nesta implementação de referência, as regras de roteamento permitem que o Azure Front Door roteie solicitações de interface do usuário e de API de front-end para diferentes recursos de back-end. Nesse caso, o padrão "/*" corresponde à regra de roteamento da interface do usuário. Esta regra encaminha a solicitação para um pool de back-end que contém contas de armazenamento com sites estáticos que hospedam o Aplicativo de Página Única (SPA). O Azure Front Door usa a Prioridade e o Peso atribuídos aos back-ends no pool para selecionar o back-end para rotear a solicitação. Métodos de roteamento de tráfego para origem. O Azure Front Door usa testes de integridade para garantir que as solicitações não sejam roteadas para back-ends que não estejam íntegros. O SPA é servido a partir da conta de armazenamento selecionada com site estático.
Nota
Os termos pools de back-end e back-ends no Azure Front Door Classic são chamados de grupos de origem e origens nas camadas Standard ou Premium do Azure Front Door.
O SPA faz uma chamada de API para o host front-end do Azure Front Door. O padrão da URL de solicitação da API é "/api/*".
Fluxo de solicitação de API de front-end
As regras do WAF são avaliadas como na etapa 2.
O Azure Front Door corresponde à solicitação à regra de roteamento de API pelo padrão "/api/*". A regra de roteamento de API roteia a solicitação para um pool de back-end que contém os endereços IP públicos para Controladores de Ingresso NGINX que sabem como rotear solicitações para o serviço correto no Serviço Kubernetes do Azure (AKS). Como antes, o Azure Front Door usa a Prioridade e o Peso atribuídos aos back-ends para selecionar o back-end correto do NGINX Ingress Controller.
Para solicitações GET, a API de front-end executa operações de leitura em um banco de dados. Para essa implementação de referência, o banco de dados é uma instância global do Azure Cosmos DB. O Azure Cosmos DB tem vários recursos que o tornam uma boa escolha para uma carga de trabalho de missão crítica, incluindo a capacidade de configurar facilmente regiões de várias gravações, permitindo failover automático para leituras e gravações em regiões secundárias. A API usa o SDK do cliente configurado com lógica de repetição para se comunicar com o Azure Cosmos DB. O SDK determina a ordem ideal das regiões disponíveis do Azure Cosmos DB com as quais se comunicar com base no parâmetro ApplicationRegion.
Para solicitações POST ou PUT, a API de Frontend executa gravações em um agente de mensagens. Na implementação de referência, o agente de mensagens é Hubs de Eventos do Azure. Você pode escolher o Service Bus alternativamente. Mais tarde, um manipulador lerá mensagens do agente de mensagens e executará todas as gravações necessárias no Azure Cosmos DB. A API usa o SDK do cliente para executar gravações. O cliente pode ser configurado para tentativas.
Fluxo do processador em segundo plano
Os processadores em segundo plano processam mensagens do agente de mensagens. Os processadores em segundo plano usam o SDK do cliente para executar leituras. O cliente pode ser configurado para tentativas.
Os processadores em segundo plano executam as operações de gravação apropriadas na instância global do Azure Cosmos DB. Os processadores em segundo plano usam o SDK do cliente configurado com nova tentativa para se conectar ao Azure Cosmos DB. A lista de regiões preferidas do cliente pode ser configurada com várias regiões. Nesse caso, se uma gravação falhar, a nova tentativa será feita na próxima região preferida.
Estruturar áreas
Sugerimos que você explore essas áreas de design para obter recomendações e orientação de práticas recomendadas ao definir sua arquitetura de missão crítica.
| Área de design | Description |
|---|---|
| Conceção de aplicações | Padrões de design que permitem dimensionamento e tratamento de erros. |
| Plataforma de aplicação | Opções de infraestrutura e mitigações para possíveis casos de falha. |
| Plataforma de dados | Opções em tecnologias de armazenamento de dados, informadas pela avaliação do volume, velocidade, variedade e veracidade necessárias. |
| Rede e conectividade | Considerações de rede para rotear o tráfego de entrada para carimbos. |
| Modelagem de saúde | Considerações de observabilidade por meio da análise de impacto do cliente correlacionaram o monitoramento para determinar a integridade geral do aplicativo. |
| Implantação e teste | Estratégias para pipelines de CI/CD e considerações de automação, com cenários de teste incorporados, como testes de carga sincronizados e testes de injeção de falhas (caos). |
| Segurança | Mitigação de vetores de ataque através do modelo Microsoft Zero Trust. |
| Procedimentos operacionais | Processos relacionados à implantação, gerenciamento de chaves, patches e atualizações. |
** Indica as considerações da área de design que são específicas para esta arquitetura.
Recursos relacionados
Para obter a documentação do produto sobre os serviços do Azure usados nessa arquitetura, consulte estes artigos.
- Azure Front Door
- BD do Cosmos para o Azure
- Azure Container Registry
- Log Analytics do Azure
- Azure Key Vault
- Azure Service Bus
- Azure Kubernetes Service
- Azure Application Insights
- Hubs de Eventos do Azure
- Armazenamento de Blobs do Azure
Implantar esta arquitetura
Implante a implementação de referência para obter uma compreensão completa dos recursos considerados, incluindo como eles são operacionalizados em um contexto de missão crítica. Ele contém um guia de implantação destinado a ilustrar uma abordagem orientada a soluções para o desenvolvimento de aplicativos de missão crítica no Azure.
Próximos passos
Se você quiser estender a arquitetura de linha de base com controles de rede no tráfego de entrada e saída, consulte esta arquitetura.