Opções de configuração: Azure Monitor Application Insights for Java
Este artigo mostra como configurar o Azure Monitor Application Insights para Java.
Cadeia de conexão e nome da função
A cadeia de conexão e o nome da função são as configurações mais comuns necessárias para começar:
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
}
}
A cadeia de conexão é necessária. O nome da função é importante sempre que você envia dados de aplicativos diferentes para o mesmo recurso do Application Insights.
Mais informações e opções de configuração são fornecidas nas seções a seguir.
Caminho do arquivo de configuração
Por padrão, o Application Insights Java 3.x espera que o arquivo de configuração seja nomeado applicationinsights.jsone esteja localizado no mesmo diretório que applicationinsights-agent-3.6.2.jar.
Você pode especificar seu próprio caminho de arquivo de configuração usando uma destas duas opções:
APPLICATIONINSIGHTS_CONFIGURATION_FILEvariável de ambienteapplicationinsights.configuration.filePropriedade do sistema Java
Se você especificar um caminho relativo, ele será resolvido em relação ao diretório onde applicationinsights-agent-3.6.2.jar está localizado.
Como alternativa, em vez de usar um arquivo de configuração, você pode especificar todo o conteúdo da configuração JSON por meio da variável APPLICATIONINSIGHTS_CONFIGURATION_CONTENTde ambiente .
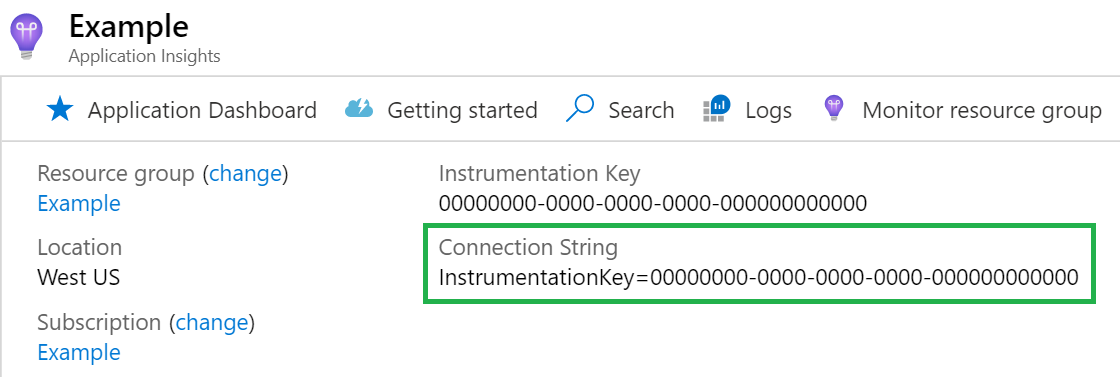
Connection string
A cadeia de conexão é necessária. Você pode encontrar sua cadeia de conexão no recurso do Application Insights.
{
"connectionString": "..."
}
Você também pode definir a cadeia de conexão usando a variável APPLICATIONINSIGHTS_CONNECTION_STRINGde ambiente . Em seguida, ele tem precedência sobre a cadeia de conexão especificada na configuração JSON.
Ou você pode definir a cadeia de conexão usando a propriedade applicationinsights.connection.stringdo sistema Java . Ele também tem precedência sobre a cadeia de conexão especificada na configuração JSON.
Você também pode definir a cadeia de conexão especificando um arquivo para carregar a cadeia de conexão.
Se você especificar um caminho relativo, ele será resolvido em relação ao diretório onde applicationinsights-agent-3.6.2.jar está localizado.
{
"connectionString": "${file:connection-string-file.txt}"
}
O arquivo deve conter apenas a cadeia de conexão e nada mais.
Não definir a cadeia de conexão desativa o agente Java.
Se você tiver vários aplicativos implantados na mesma Java Virtual Machine (JVM) e quiser que eles enviem telemetria para cadeias de conexão diferentes, consulte Substituições de cadeia de conexão (visualização).
Nome da função na nuvem
O nome da função de nuvem é usado para rotular o componente no mapa do aplicativo.
Se você quiser definir o nome da função de nuvem:
{
"role": {
"name": "my cloud role name"
}
}
Se o nome da função de nuvem não estiver definido, o nome do recurso do Application Insights será usado para rotular o componente no mapa do aplicativo.
Você também pode definir o nome da função de nuvem usando a variável APPLICATIONINSIGHTS_ROLE_NAMEde ambiente . Em seguida, ele tem precedência sobre o nome da função de nuvem especificado na configuração JSON.
Ou você pode definir o nome da função de nuvem usando a propriedade applicationinsights.role.namedo sistema Java . Ele também tem precedência sobre o nome da função de nuvem especificado na configuração JSON.
Se você tiver vários aplicativos implantados na mesma JVM e quiser que eles enviem telemetria para nomes de função de nuvem diferentes, consulte Substituições de nome de função de nuvem (visualização).
Instância de função de cloud
A instância de função de nuvem assume como padrão o nome da máquina.
Se você quiser definir a instância de função de nuvem para algo diferente em vez do nome da máquina:
{
"role": {
"name": "my cloud role name",
"instance": "my cloud role instance"
}
}
Você também pode definir a instância de função de nuvem usando a variável APPLICATIONINSIGHTS_ROLE_INSTANCEde ambiente . Em seguida, ele tem precedência sobre a instância de função de nuvem especificada na configuração JSON.
Ou você pode definir a instância da função de nuvem usando a propriedade applicationinsights.role.instancedo sistema Java.
Ele também tem precedência sobre a instância de função de nuvem especificada na configuração JSON.
Amostragem
Nota
A amostragem pode ser uma ótima maneira de reduzir o custo do Application Insights. Certifique-se de configurar sua configuração de amostragem apropriadamente para seu caso de uso.
A amostragem é baseada na solicitação, o que significa que, se uma solicitação for capturada (amostrada), suas dependências, logs e exceções também o serão.
A amostragem também é baseada no ID de rastreamento para ajudar a garantir decisões de amostragem consistentes em diferentes serviços.
A amostragem só se aplica aos logs dentro de uma solicitação. Os logs que não estão dentro de uma solicitação (por exemplo, logs de inicialização) são sempre coletados por padrão. Se quiser fazer uma amostra desses logs, você pode usar substituições de amostragem.
Amostragem limitada à taxa
A partir da versão 3.4.0, a amostragem com taxa limitada está disponível e agora é o padrão.
Se nenhuma amostragem estiver configurada, o padrão agora é amostragem limitada por taxa configurada para capturar no máximo (aproximadamente) cinco solicitações por segundo, juntamente com todas as dependências e logs dessas solicitações.
Essa configuração substitui o padrão anterior, que era capturar todas as solicitações. Se você ainda quiser capturar todas as solicitações, use amostragem de porcentagem fixa e defina a porcentagem de amostragem como 100.
Nota
A amostragem com taxa limitada é aproximada porque internamente ela deve adaptar uma porcentagem de amostragem "fixa" ao longo do tempo para emitir contagens precisas de itens em cada registro de telemetria. Internamente, a amostragem com taxa limitada é ajustada para se adaptar rapidamente (0,1 segundos) a novas cargas de aplicativos. Por esse motivo, você não deve vê-lo exceder a taxa configurada em muito, ou por muito tempo.
Este exemplo mostra como definir a amostragem para capturar no máximo (aproximadamente) uma solicitação por segundo:
{
"sampling": {
"requestsPerSecond": 1.0
}
}
O requestsPerSecond pode ser decimal, para que você possa configurá-lo para capturar menos de uma solicitação por segundo, se desejar. Por exemplo, um valor de 0.5 significa capturar no máximo uma solicitação a cada 2 segundos.
Também é possível definir a porcentagem de amostragem usando a variável APPLICATIONINSIGHTS_SAMPLING_REQUESTS_PER_SECONDde ambiente . Em seguida, ele tem precedência sobre o limite de taxa especificado na configuração JSON.
Amostragem de percentagem fixa
Este exemplo mostra como definir a amostragem para capturar aproximadamente um terço de todas as solicitações:
{
"sampling": {
"percentage": 33.333
}
}
Também é possível definir a porcentagem de amostragem usando a variável APPLICATIONINSIGHTS_SAMPLING_PERCENTAGEde ambiente . Em seguida, ele tem precedência sobre a porcentagem de amostragem especificada na configuração JSON.
Nota
Para a percentagem de amostragem, escolha uma percentagem próxima de 100/N, em que N é um número inteiro. Atualmente, a amostragem não suporta outros valores.
Sobreposições de amostragem
As substituições de amostragem permitem substituir a porcentagem de amostragem padrão. Por exemplo, pode:
- Defina a percentagem de amostragem como 0, ou algum valor pequeno, para verificações de saúde ruidosas.
- Defina a porcentagem de amostragem como 0, ou algum valor pequeno, para chamadas de dependência barulhentas.
- Defina a percentagem de amostragem para 100 para um tipo de pedido importante. Por exemplo, você pode usar
/loginmesmo que tenha a amostragem padrão configurada para algo inferior.
Para obter mais informações, consulte a documentação Substituições de amostragem.
Métricas do Java Management Extensions
Se você quiser coletar algumas outras métricas JMX (Java Management Extensions):
{
"jmxMetrics": [
{
"name": "JVM uptime (millis)",
"objectName": "java.lang:type=Runtime",
"attribute": "Uptime"
},
{
"name": "MetaSpace Used",
"objectName": "java.lang:type=MemoryPool,name=Metaspace",
"attribute": "Usage.used"
}
]
}
No exemplo de configuração anterior:
nameé o nome da métrica atribuída a esta métrica JMX (pode ser qualquer coisa).objectNameé o Nome do Objeto doJMX MBeanque você deseja coletar. O asterisco de caractere curinga (*) é suportado.attributeé o nome do atributo dentro doJMX MBeanque você deseja coletar.
São suportados valores numéricos e booleanos das métricas JMX. As métricas JMX booleanas são mapeadas para 0 false e 1 para true.
Para obter mais informações, consulte a documentação de métricas JMX.
Dimensões personalizadas
Se quiser adicionar dimensões personalizadas a toda a sua telemetria:
{
"customDimensions": {
"mytag": "my value",
"anothertag": "${ANOTHER_VALUE}"
}
}
Você pode usar ${...} para ler o valor da variável de ambiente especificada na inicialização.
Nota
A partir da versão 3.0.2, se você adicionar uma dimensão personalizada chamada service.version, o valor será armazenado na application_Version coluna da tabela Logs do Application Insights em vez de como uma dimensão personalizada.
Atributo herdado (visualização)
A partir da versão 3.2.0, você pode definir uma dimensão personalizada programaticamente na telemetria de solicitação. Ele garante a herança por dependência e telemetria de log. Todos são capturados no contexto desse pedido.
{
"preview": {
"inheritedAttributes": [
{
"key": "mycustomer",
"type": "string"
}
]
}
}
E então, no início de cada solicitação, ligue:
Span.current().setAttribute("mycustomer", "xyz");
Consulte também: Adicionar uma propriedade personalizada a um Span.
Substituições de cadeia de conexão (visualização)
Esta funcionalidade está em pré-visualização, a partir da versão 3.4.0.
As substituições de cadeia de conexão permitem que você substitua a cadeia de conexão padrão. Por exemplo, pode:
- Defina uma cadeia de conexão para um prefixo
/myapp1de caminho HTTP . - Defina outra cadeia de conexão para outro prefixo
/myapp2/de caminho HTTP.
{
"preview": {
"connectionStringOverrides": [
{
"httpPathPrefix": "/myapp1",
"connectionString": "..."
},
{
"httpPathPrefix": "/myapp2",
"connectionString": "..."
}
]
}
}
Substituições de nome de função na nuvem (visualização)
Esta funcionalidade está em pré-visualização, a partir da versão 3.3.0.
As substituições de nome de função de nuvem permitem que você substitua o nome de função de nuvem padrão. Por exemplo, pode:
- Defina um nome de função de nuvem para um prefixo
/myapp1de caminho HTTP. - Defina outro nome de função de nuvem para outro prefixo
/myapp2/de caminho HTTP.
{
"preview": {
"roleNameOverrides": [
{
"httpPathPrefix": "/myapp1",
"roleName": "Role A"
},
{
"httpPathPrefix": "/myapp2",
"roleName": "Role B"
}
]
}
}
Cadeia de conexão configurada em tempo de execução
A partir da versão 3.4.8, se você precisar da capacidade de configurar a cadeia de conexão em tempo de execução, adicione esta propriedade à sua configuração json:
{
"connectionStringConfiguredAtRuntime": true
}
Adicione applicationinsights-core à sua candidatura:
<dependency>
<groupId>com.microsoft.azure</groupId>
<artifactId>applicationinsights-core</artifactId>
<version></version>
</dependency>
Use o método estático configure(String) na classe com.microsoft.applicationinsights.connectionstring.ConnectionString.
Nota
Qualquer telemetria capturada antes de configurar a cadeia de conexão será descartada, por isso é melhor configurá-la o mais cedo possível na inicialização do aplicativo.
Recolha automática de dependências InProc (pré-visualização)
A partir da versão 3.2.0, se você quiser capturar dependências "InProc" do controlador, use a seguinte configuração:
{
"preview": {
"captureControllerSpans": true
}
}
Carregador SDK do navegador (visualização)
Esse recurso injeta automaticamente o Carregador SDK do navegador nas páginas HTML do seu aplicativo, incluindo a configuração da Cadeia de Conexão apropriada.
Por exemplo, quando seu aplicativo java retorna uma resposta como:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Title</title>
</head>
<body>
</body>
</html>
Ele se modifica automaticamente para retornar:
<!DOCTYPE html>
<html lang="en">
<head>
<script type="text/javascript">
!function(v,y,T){var S=v.location,k="script"
<!-- Removed for brevity -->
connectionString: "YOUR_CONNECTION_STRING"
<!-- Removed for brevity --> }});
</script>
<title>Title</title>
</head>
<body>
</body>
</html>
O script tem como objetivo ajudar os clientes a rastrear os dados do usuário da Web e enviou a telemetria do lado do servidor de coleta de volta para o portal do Azure dos usuários. Os detalhes podem ser encontrados em ApplicationInsights-JS.
Se você quiser ativar esse recurso, adicione a opção de configuração abaixo:
{
"preview": {
"browserSdkLoader": {
"enabled": true
}
}
}
Processadores de telemetria (visualização)
Você pode usar processadores de telemetria para configurar regras que são aplicadas à telemetria de solicitação, dependência e rastreamento. Por exemplo, pode:
- Mascarar dados confidenciais.
- Adicione condicionalmente dimensões personalizadas.
- Atualize o nome da extensão, que é usado para agregar telemetria semelhante no portal do Azure.
- Solte atributos de span específicos para controlar os custos de ingestão.
Para obter mais informações, consulte a documentação do processador de telemetria.
Nota
Se você quiser eliminar extensões específicas (inteiras) para controlar o custo de ingestão, consulte Substituições de amostragem.
Instrumentação personalizada (pré-visualização)
A partir do verion 3.3.1, você pode capturar extensões para um método em seu aplicativo:
{
"preview": {
"customInstrumentation": [
{
"className": "my.package.MyClass",
"methodName": "myMethod"
}
]
}
}
Desativando localmente a amostragem de ingestão (visualização)
Por padrão, quando a porcentagem de amostragem efetiva no agente Java for de 100% e a amostragem de ingestão tiver sido configurada em seu recurso do Application Insights, a porcentagem de amostragem de ingestão será aplicada.
Observe que esse comportamento se aplica à amostragem de taxa fixa de 100% e também se aplica à amostragem limitada quando a taxa de solicitação não excede o limite de taxa (capturando efetivamente 100% durante a janela de tempo deslizante contínua).
A partir da versão 3.5.3, você pode desabilitar esse comportamento (e manter 100% da telemetria nesses casos, mesmo quando a amostragem de ingestão tiver sido configurada no recurso do Application Insights):
{
"preview": {
"sampling": {
"ingestionSamplingEnabled": false
}
}
}
Registo recolhido automaticamente
Log4j, Logback, JBoss Logging e java.util.logging são autoinstrumentados. O registro em log realizado por meio dessas estruturas de registro é coletado automaticamente.
O registro em log só é capturado se:
- Atende ao nível configurado para a estrutura de log.
- Também atende ao nível configurado para o Application Insights.
Por exemplo, se sua estrutura de log estiver configurada para registrar WARN (e você a configurou conforme descrito anteriormente) a partir do pacote com.examplee o Application Insights estiver configurado para capturar INFO (e você configurou como descrito), o Application Insights capturará WARN apenas (e mais grave) do pacote com.example.
O nível padrão configurado para o Application Insights é INFO. Se quiser alterar este nível:
{
"instrumentation": {
"logging": {
"level": "WARN"
}
}
}
Você também pode definir o nível usando a variável APPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_LEVELde ambiente . Em seguida, ele tem precedência sobre o nível especificado na configuração JSON.
Você pode usar esses valores válidos level para especificar no applicationinsights.json arquivo. A tabela mostra como eles correspondem aos níveis de log em diferentes estruturas de log.
| Level | Log4j | Registo | JBoss | JULHO |
|---|---|---|---|---|
| OFF | OFF | OFF | OFF | OFF |
| FATAL | FATAL | ERRO | FATAL | GRAVE |
| ERRO (ou GRAVE) | ERRO | ERRO | ERRO | GRAVE |
| AVISAR (ou AVISO) | ADVERTIR | ADVERTIR | ADVERTIR | AVISO |
| INFORMAÇÃO | INFORMAÇÃO | INFORMAÇÃO | INFORMAÇÃO | INFORMAÇÃO |
| CONFIGURAÇÃO | DEPURAR | DEPURAR | DEPURAR | CONFIGURAÇÃO |
| DEPURAR (ou MULTA) | DEPURAR | DEPURAR | DEPURAR | MULTA |
| FINER | DEPURAR | DEPURAR | DEPURAR | FINER |
| TRACE (ou FINEST) | TRACE | TRACE | TRACE | FINEST |
| TODOS | TODOS | TODOS | TODOS | TODOS |
Nota
Se um objeto de exceção for passado para o registrador, a mensagem de log (e os detalhes do objeto de exceção) aparecerão no portal do Azure sob a exceptions tabela em vez da traces tabela. Se você quiser ver as mensagens de log nas traces tabelas e exceptions , você pode escrever uma consulta Logs (Kusto) para união entre elas. Por exemplo:
union traces, (exceptions | extend message = outerMessage)
| project timestamp, message, itemType
Marcadores de log (visualização)
A partir da versão 3.4.2, você pode capturar os marcadores de log para Logback e Log4j 2:
{
"preview": {
"captureLogbackMarker": true,
"captureLog4jMarker": true
}
}
Outros atributos de log para Logback (visualização)
A partir da versão 3.4.3, você pode capturar FileName, ClassName, MethodName, e , para LineNumberLogback:
{
"preview": {
"captureLogbackCodeAttributes": true
}
}
Aviso
A captura de atributos de código pode adicionar uma sobrecarga de desempenho.
Nível de registro em log como uma dimensão personalizada
A partir da versão 3.3.0, LoggingLevel não é capturado por padrão como parte da dimensão personalizada Rastreamentos porque esses dados já estão capturados SeverityLevel no campo.
Se necessário, você pode reativar temporariamente o comportamento anterior:
{
"preview": {
"captureLoggingLevelAsCustomDimension": true
}
}
Métricas do micrômetro coletadas automaticamente (incluindo métricas do atuador de inicialização da mola)
Se seu aplicativo usa o micrômetro, as métricas enviadas para o registro global do micrômetro são coletadas automaticamente.
Além disso, se o seu aplicativo usa o Spring Boot Actuator, as métricas configuradas pelo Spring Boot Actuator também são coletadas automaticamente.
Para enviar métricas personalizadas usando micrômetro:
Adicione o micrômetro ao seu aplicativo, conforme mostrado no exemplo a seguir.
<dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-core</artifactId> <version>1.6.1</version> </dependency>Use o registro global do micrômetro para criar um medidor, conforme mostrado no exemplo a seguir.
static final Counter counter = Metrics.counter("test.counter");Use o contador para registrar métricas usando o comando a seguir.
counter.increment();As métricas são ingeridas na tabela customMetrics , com tags capturadas
customDimensionsna coluna. Você também pode exibir as métricas no explorador de métricas sob oLog-based metricsnamespace de métricas.Nota
O Application Insights Java substitui todos os caracteres não alfanuméricos (exceto traços) no nome da métrica do micrômetro por sublinhados. Como resultado, a métrica anterior
test.counteraparecerá comotest_counter.
Para desativar a coleta automática de métricas do micrômetro e métricas do atuador de inicialização da mola:
Nota
As métricas personalizadas são cobradas separadamente e podem gerar custos extras. Certifique-se de verificar as informações de preços. Para desativar as métricas do Micrometer e do Spring Boot Actuator, adicione a seguinte configuração ao seu arquivo de configuração.
{
"instrumentation": {
"micrometer": {
"enabled": false
}
}
}
Mascaramento de consulta de conectividade de banco de dados Java
Os valores literais nas consultas JDBC (Java Database Connectivity) são mascarados por padrão para evitar a captura acidental de dados confidenciais.
A partir da versão 3.4.0, esse comportamento pode ser desabilitado. Por exemplo:
{
"instrumentation": {
"jdbc": {
"masking": {
"enabled": false
}
}
}
}
Mascaramento de consulta Mongo
Os valores literais nas consultas Mongo são mascarados por padrão para evitar a captura acidental de dados confidenciais.
A partir da versão 3.4.0, esse comportamento pode ser desabilitado. Por exemplo:
{
"instrumentation": {
"mongo": {
"masking": {
"enabled": false
}
}
}
}
Cabeçalhos de HTTP
A partir da versão 3.3.0, você pode capturar cabeçalhos de solicitação e resposta na telemetria do servidor (solicitação):
{
"preview": {
"captureHttpServerHeaders": {
"requestHeaders": [
"My-Header-A"
],
"responseHeaders": [
"My-Header-B"
]
}
}
}
Os nomes dos cabeçalhos não diferenciam maiúsculas de minúsculas.
Os exemplos anteriores são capturados sob os nomes http.request.header.my_header_a das propriedades e http.response.header.my_header_b.
Da mesma forma, você pode capturar cabeçalhos de solicitação e resposta na telemetria do cliente (dependência):
{
"preview": {
"captureHttpClientHeaders": {
"requestHeaders": [
"My-Header-C"
],
"responseHeaders": [
"My-Header-D"
]
}
}
}
Novamente, os nomes dos cabeçalhos não diferenciam maiúsculas de minúsculas. Os exemplos anteriores são capturados sob os nomes http.request.header.my_header_c das propriedades e http.response.header.my_header_d.
Códigos de resposta do servidor HTTP 4xx
Por padrão, as solicitações do servidor HTTP que resultam em códigos de resposta 4xx são capturadas como erros.
A partir da versão 3.3.0, você pode alterar esse comportamento para capturá-los como sucesso:
{
"preview": {
"captureHttpServer4xxAsError": false
}
}
Suprimir telemetria específica de coleta automática
A partir da versão 3.0.3, a telemetria de coleta automática específica pode ser suprimida usando estas opções de configuração:
{
"instrumentation": {
"azureSdk": {
"enabled": false
},
"cassandra": {
"enabled": false
},
"jdbc": {
"enabled": false
},
"jms": {
"enabled": false
},
"kafka": {
"enabled": false
},
"logging": {
"enabled": false
},
"micrometer": {
"enabled": false
},
"mongo": {
"enabled": false
},
"quartz": {
"enabled": false
},
"rabbitmq": {
"enabled": false
},
"redis": {
"enabled": false
},
"springScheduling": {
"enabled": false
}
}
}
Você também pode suprimir essas instrumentações definindo estas variáveis de ambiente como false:
APPLICATIONINSIGHTS_INSTRUMENTATION_AZURE_SDK_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_CASSANDRA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JDBC_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JMS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_KAFKA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MICROMETER_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MONGO_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_RABBITMQ_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_REDIS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_SPRING_SCHEDULING_ENABLED
Em seguida, essas variáveis têm precedência sobre as variáveis habilitadas especificadas na configuração JSON.
Nota
Se você estiver procurando por um controle mais refinado, por exemplo, para suprimir algumas chamadas de redis, mas não todas as chamadas de redis, consulte Substituições de amostragem.
Pré-visualização de instrumentações
A partir da versão 3.2.0, você pode habilitar as seguintes instrumentações de visualização:
{
"preview": {
"instrumentation": {
"akka": {
"enabled": true
},
"apacheCamel": {
"enabled": true
},
"grizzly": {
"enabled": true
},
"ktor": {
"enabled": true
},
"play": {
"enabled": true
},
"r2dbc": {
"enabled": true
},
"springIntegration": {
"enabled": true
},
"vertx": {
"enabled": true
}
}
}
}
Nota
A instrumentação Akka está disponível a partir da versão 3.2.2. A instrumentação da biblioteca HTTP Vertx está disponível a partir da versão 3.3.0.
Intervalo métrico
Por padrão, as métricas são capturadas a cada 60 segundos.
A partir da versão 3.0.3, você pode alterar este intervalo:
{
"metricIntervalSeconds": 300
}
A partir da versão 3.4.9 GA, você também pode definir o metricIntervalSeconds usando a variável APPLICATIONINSIGHTS_METRIC_INTERVAL_SECONDSde ambiente . Em seguida, ele tem precedência sobre o metricIntervalSeconds especificado na configuração JSON.
A configuração se aplica às seguintes métricas:
- Contadores de desempenho padrão: por exemplo, CPU e memória
- Métricas personalizadas padrão: por exemplo, tempo de coleta de lixo
- Métricas JMX configuradas: consulte a seção de métricas JMX
- Métricas do micrômetro: consulte a seção Métricas do micrômetro coletadas automaticamente
Heartbeat
Por padrão, o Application Insights Java 3.x envia uma métrica de pulsação uma vez a cada 15 minutos. Se estiver a utilizar a métrica de batimento cardíaco para disparar alertas, pode aumentar a frequência deste batimento cardíaco:
{
"heartbeat": {
"intervalSeconds": 60
}
}
Nota
Não é possível aumentar o intervalo para mais de 15 minutos porque os dados de pulsação também são usados para acompanhar o uso do Application Insights.
Autenticação
Nota
O recurso de autenticação é GA desde a versão 3.4.17.
Você pode usar a autenticação para configurar o agente para gerar credenciais de token necessárias para a autenticação do Microsoft Entra. Para obter mais informações, consulte a documentação de autenticação .
Proxy HTTP
Se seu aplicativo estiver protegido por um firewall e não puder se conectar diretamente ao Application Insights, consulte os endereços IP usados pelo Application Insights.
Para contornar esse problema, você pode configurar o Application Insights Java 3.x para usar um proxy HTTP.
{
"proxy": {
"host": "myproxy",
"port": 8080
}
}
Você também pode definir o proxy http usando a variável APPLICATIONINSIGHTS_PROXYde ambiente , que assume o formato https://<host>:<port>. Em seguida, ele tem precedência sobre o proxy especificado na configuração JSON.
Você pode fornecer um usuário e uma senha para seu proxy com a variável de APPLICATIONINSIGHTS_PROXY ambiente: https://<user>:<password>@<host>:<port>.
O Application Insights Java 3.x também respeita as propriedades globais https.proxyHost e https.proxyPort do sistema, se estiverem definidas, e http.nonProxyHosts, se necessário.
Recuperação de falhas de ingestão
Quando o envio de telemetria para o serviço Application Insights falha, o Application Insights Java 3.x armazena a telemetria no disco e continua tentando novamente a partir do disco.
O limite padrão para persistência de disco é 50 Mb. Se você tiver um alto volume de telemetria ou precisar se recuperar de interrupções mais longas da rede ou do serviço de ingestão, poderá aumentar esse limite a partir da versão 3.3.0:
{
"preview": {
"diskPersistenceMaxSizeMb": 50
}
}
Autodiagnóstico
"Autodiagnóstico" refere-se ao registro interno do Application Insights Java 3.x. Essa funcionalidade pode ser útil para detetar e diagnosticar problemas com o próprio Application Insights.
Por padrão, o Application Insights Java 3.x registra no nível INFO do arquivo applicationinsights.log e do console, correspondendo a esta configuração:
{
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}
No exemplo de configuração anterior:
levelpode ser um dosOFF,ERROR,WARN,INFO,DEBUG, ouTRACE.pathpode ser um caminho absoluto ou relativo. Os caminhos relativos são resolvidos em relação ao diretório ondeapplicationinsights-agent-3.6.2.jarestá localizado.
A partir da versão 3.0.2, você também pode definir o autodiagnóstico level usando a variável APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_LEVELde ambiente . Em seguida, ele tem precedência sobre o nível de autodiagnóstico especificado na configuração JSON.
A partir da versão 3.0.3, você também pode definir o local do arquivo de autodiagnóstico usando a variável APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_FILE_PATHde ambiente . Em seguida, ele tem precedência sobre o caminho do arquivo de autodiagnóstico especificado na configuração JSON.
Correlação de telemetria
A correlação de telemetria está habilitada por padrão, mas você pode desativá-la na configuração.
{
"preview": {
"disablePropagation": true
}
}
Um exemplo
Este exemplo mostra a aparência de um arquivo de configuração com vários componentes. Configure opções específicas com base nas suas necessidades.
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
},
"sampling": {
"percentage": 100
},
"jmxMetrics": [
],
"customDimensions": {
},
"instrumentation": {
"logging": {
"level": "INFO"
},
"micrometer": {
"enabled": true
}
},
"proxy": {
},
"preview": {
"processors": [
]
},
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}