Solucionar problemas de coleta de métricas do Prometheus no Azure Monitor
Siga as etapas neste artigo para determinar a causa das métricas do Prometheus não serem coletadas conforme o esperado no Azure Monitor.
O pod de réplica raspa métricas de destinos de kube-state-metricsraspagem personalizados no ama-metrics-prometheus-config configmap e destinos de raspagem personalizados definidos nos Recursos personalizados. Os pods DaemonSet raspam métricas dos seguintes destinos em seus respetivos nós: kubelet, cAdvisor, node-exportere destinos de raspagem personalizados no ama-metrics-prometheus-config-node configmap. O pod que você deseja visualizar os logs e a interface do usuário do Prometheus para ele depende de qual destino de raspagem você está investigando.
Solucionar problemas usando o script do PowerShell
Se você encontrar um erro ao tentar habilitar o monitoramento para seu cluster AKS, siga estas instruções para executar o script de solução de problemas. Esse script foi projetado para fazer um diagnóstico básico para quaisquer problemas de configuração em seu cluster e você pode anexar os arquivos gerados enquanto cria uma solicitação de suporte para uma resolução mais rápida para seu caso de suporte.
Limitação de métricas
O serviço Azure Monitor Managed for Prometheus tem limites padrão e cotas para ingestão. Quando atingir os limites de ingestão, pode ocorrer limitação. Pode solicitar um aumento destes limites. Para obter informações sobre os limites de métricas do Prometheus, consulte Limites de serviço do Azure Monitor.
No portal do Azure, navegue até seu Espaço de Trabalho do Azure Monitor. Vá para Metrics, e selecione as métricas Active Time Series % Utilization e Events Per Minute Received % Utilization. Verifique se ambos estão abaixo de 100%.
Para obter mais informações sobre como monitorar e alertar sobre suas métricas de ingestão, consulte Monitorar a ingestão de métricas do espaço de trabalho do Azure Monitor.
Lacunas intermitentes na recolha de dados métricos
Durante as atualizações do nó, você pode ver uma lacuna de 1 a 2 minutos nos dados de métricas para métricas coletadas de nosso coletor de nível de cluster. Esta lacuna ocorre porque o nó em que é executado está a ser atualizado como parte de um processo de atualização normal. Afeta os destinos em todo o cluster, como kube-state-metrics e destinos de aplicações personalizados especificados. Ocorre quando o cluster é atualizado manualmente ou através de atualização automática. Este comportamento é esperado e ocorre devido ao nó em que é executado estar a ser atualizado. Nenhuma das regras de alerta recomendadas é afetada por este comportamento.
Estado do pod
Verifique o status do pod com o seguinte comando:
kubectl get pods -n kube-system | grep ama-metrics
Quando o serviço está sendo executado corretamente, a seguinte lista de pods no formato ama-metrics-xxxxxxxxxx-xxxxx é retornada:
ama-metrics-operator-targets-*ama-metrics-ksm-*ama-metrics-node-*pod para cada nó no cluster.
Cada estado do pod deve ser Running e ter um número igual de reinicializações para o número de alterações do configmap que foram aplicadas. O pod ama-metrics-operator-targets-* pode ter uma reinicialização extra no início e isso é esperado:

Se cada estado do pod for Running apenas um ou mais pods com reinicializações, execute o seguinte comando:
kubectl describe pod <ama-metrics pod name> -n kube-system
- Este comando fornece o motivo para as reinicializações. As reinicializações do pod são esperadas se as alterações do configmap tiverem sido feitas. Se o motivo da reinicialização for
OOMKilled, o pod não consegue acompanhar o volume de métricas. Veja as recomendações de escala para o volume de métricas.
Se os pods estiverem funcionando conforme o esperado, o próximo lugar para verificar são os logs de contêiner.
Verifique se há configurações de rerotulagem
Se as métricas estiverem faltando, você também pode verificar se tem configurações de rerotulagem. Com as configurações de rerotulagem, certifique-se de que a rerotulagem não filtre os destinos e que os rótulos configurados corretamente correspondam aos destinos. Para obter mais informações, consulte Prometheus relabel config documentation.
Logs de contêiner
Exiba os logs de contêiner com o seguinte comando:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
Na inicialização, todos os erros iniciais são impressos em vermelho, enquanto os avisos são impressos em amarelo. (A visualização dos logs coloridos requer pelo menos a versão 7 do PowerShell ou uma distribuição linux.)
- Verifique se há um problema com a obtenção do token de autenticação:
- A mensagem Nenhuma configuração presente para o recurso AKS é registrada a cada 5 minutos.
- O pod é reiniciado a cada 15 minutos para tentar novamente com o erro: Nenhuma configuração presente para o recurso AKS.
- Em caso afirmativo, verifique se a Regra de Coleta de Dados e o Ponto de Extremidade de Coleta de Dados existem no seu grupo de recursos.
- Verifique também se o Espaço de Trabalho do Azure Monitor existe.
- Verifique se você não tem um cluster AKS privado e se ele não está vinculado a um Escopo de Link Privado do Azure Monitor para qualquer outro serviço. Este cenário não é suportado no momento.
Processamento de configuração
Exiba os logs de contêiner com o seguinte comando:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- Verifique se não há erros ao analisar a configuração do Prometheus, mesclar com quaisquer destinos de raspagem padrão habilitados e validar a configuração completa.
- Se você incluiu uma configuração personalizada do Prometheus, verifique se ela é reconhecida nos logs. Em caso negativo:
- Verifique se seu configmap tem o nome correto:
ama-metrics-prometheus-confignokube-systemnamespace. - Verifique se no configmap sua configuração do Prometheus está sob uma seção chamada
prometheus-configcomodatamostrado aqui:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- Verifique se seu configmap tem o nome correto:
- Se você criou Recursos Personalizados, deve ter visto quaisquer erros de validação durante a criação de monitores de pod/serviço. Se você ainda não vir as métricas dos destinos, certifique-se de que os logs não mostrem erros.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- Verifique se não há erros relativos à autenticação com o espaço de
MetricsExtensiontrabalho do Azure Monitor. - Verifique se não há erros de raspagem
OpenTelemetry collectordos alvos.
Execute o seguinte comando:
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- Este comando mostra um erro se houver um problema com a autenticação com o espaço de trabalho do Azure Monitor. O exemplo abaixo mostra logs sem problemas:


Se não houver erros nos logs, a interface Prometheus pode ser usada para depuração para verificar a configuração esperada e os destinos que estão sendo raspados.
Interface Prometheus
Cada ama-metrics-* pod tem a interface de usuário do modo Prometheus Agent disponível na porta 9090.
Os destinos de configuração personalizada e recursos personalizados são raspados pelo ama-metrics-* pod e os alvos de nó pelo ama-metrics-node-* pod.
Port-forward para o pod de réplica ou um dos pods de conjunto de daemon para verificar a configuração, a descoberta de serviço e os pontos de extremidade de destinos, conforme descrito aqui, para verificar se as configurações personalizadas estão corretas, se os destinos pretendidos foram descobertos para cada trabalho e se não há erros com a raspagem de destinos específicos.
Execute o comando kubectl port-forward <ama-metrics pod> -n kube-system 9090.
Abra um navegador para o endereço
127.0.0.1:9090/config. Esta interface de usuário tem a configuração de raspagem completa. Verifique se todos os trabalhos estão incluídos na configuração.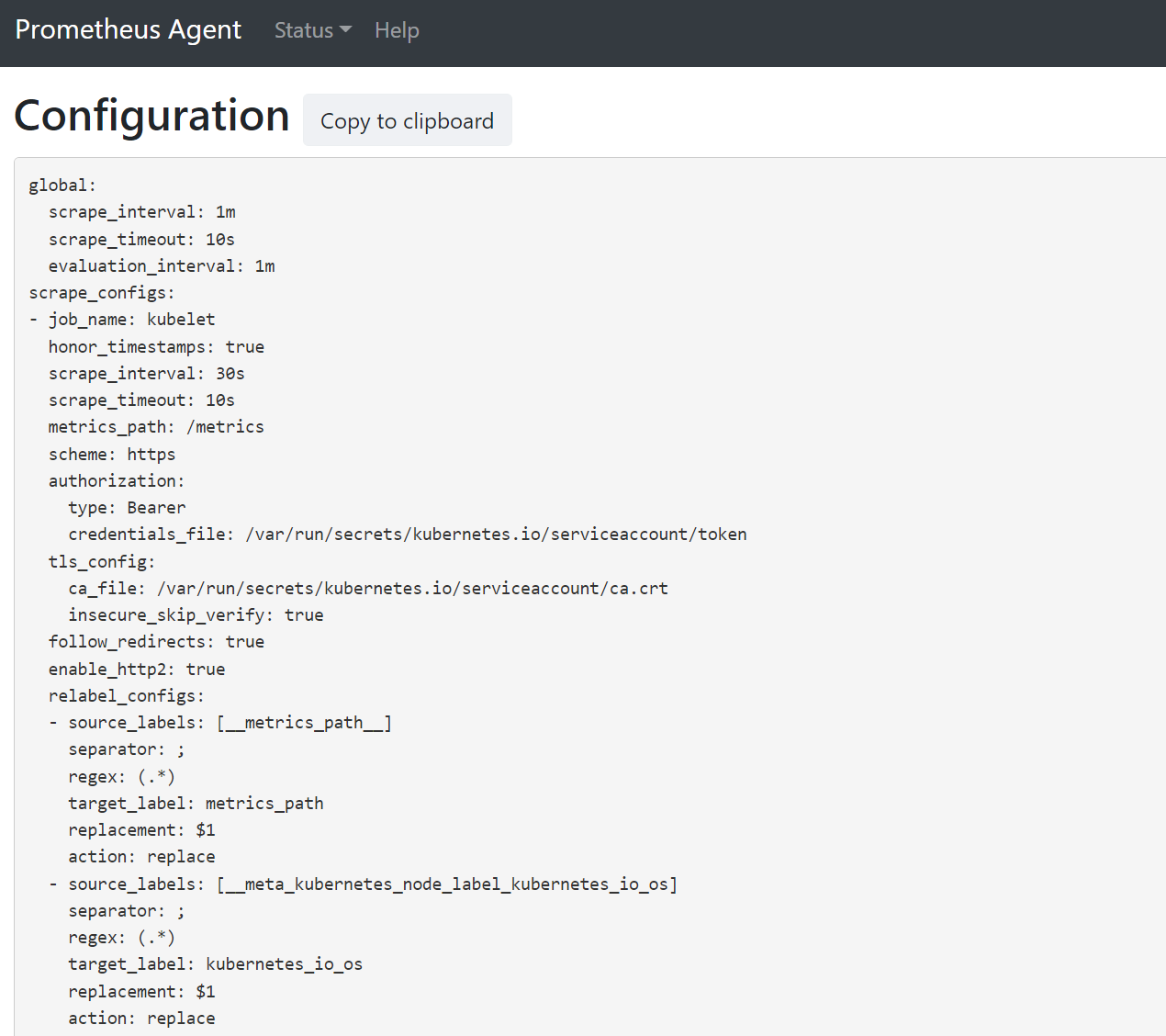
Vá para
127.0.0.1:9090/service-discoverypara exibir os destinos descobertos pelo objeto de descoberta de serviço especificado e quais relabel_configs filtraram os destinos. Por exemplo, ao perder métricas de um determinado pod, você pode descobrir se esse pod foi descoberto e qual é seu URI. Em seguida, você pode usar esse URI ao examinar os destinos para ver se há algum erro de raspagem.
Vá para
127.0.0.1:9090/targetspara ver todos os trabalhos, a última vez que o ponto de extremidade desse trabalho foi raspado e quaisquer erros



Recursos Personalizados
- Se você incluiu Recursos Personalizados, certifique-se de que eles apareçam em configuração, descoberta de serviço e destinos.
Configuração

Deteção de Serviço

Alvos

Se não houver problemas e os alvos pretendidos estiverem sendo raspados, você poderá visualizar as métricas exatas que estão sendo raspadas ativando o modo de depuração.
Modo de depuração
Aviso
Esse modo pode afetar o desempenho e só deve ser habilitado por um curto período de tempo para fins de depuração.
O addon de métricas pode ser configurado para ser executado no modo de depuração alterando a configuração enabled configmap em debug-mode para true seguindo as instruções aqui.
Quando habilitada, todas as métricas do Prometheus que são raspadas são hospedadas na porta 9091. Execute o seguinte comando:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
Vá para 127.0.0.1:9091/metrics em um navegador para ver se as métricas foram raspadas pelo OpenTelemetry Collector. Esta interface de usuário pode ser acessada para todos os ama-metrics-* pods. Se as métricas não estiverem lá, pode haver um problema com o comprimento do nome da métrica ou do rótulo ou com o número de rótulos. Verifique também se excedeu a quota de ingestão para as métricas do Prometheus, conforme especificado neste artigo.
Nomes de métricas, nomes de rótulos e valores de rótulos
Atualmente, a raspagem de métricas tem as limitações da tabela a seguir:
| Property | Limite |
|---|---|
| Comprimento do nome do rótulo | Menor ou igual a 511 caracteres. Quando esse limite é excedido para qualquer série temporal em um trabalho, todo o trabalho de raspagem falha e as métricas são descartadas desse trabalho antes da ingestão. Você pode ver up=0 para esse trabalho e também o Ux de destino mostra o motivo para up=0. |
| Comprimento do valor do rótulo | Menor ou igual a 1023 caracteres. Quando esse limite é excedido para qualquer série temporal em um trabalho, toda a raspagem falha e as métricas são descartadas desse trabalho antes da ingestão. Você pode ver up=0 para esse trabalho e também o Ux de destino mostra o motivo para up=0. |
| Número de rótulos por série cronológica | Menor ou igual a 63. Quando esse limite é excedido para qualquer série temporal em um trabalho, todo o trabalho de raspagem falha e as métricas são descartadas desse trabalho antes da ingestão. Você pode ver up=0 para esse trabalho e também o Ux de destino mostra o motivo para up=0. |
| Comprimento do nome métrico | Menor ou igual a 511 caracteres. Quando esse limite é excedido para qualquer série temporal em um trabalho, apenas essa série específica é descartada. MetricextensionConsoleDebugLog tem rastreamentos para a métrica descartada. |
| Nomes de rótulos com invólucros diferentes | Dois rótulos dentro da mesma amostra métrica, com invólucros diferentes, são tratados como tendo rótulos duplicados e são descartados quando ingeridos. Por exemplo, a série my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} temporal é descartada devido a rótulos duplicados desde ExampleLabel e examplelabel são vistos como o mesmo nome de rótulo. |
Verificar a quota de ingestão na área de trabalho do Azure Monitor
Se vir métricas perdidas, pode primeiro verificar se os limites de ingestão estão a ser excedidos para o seu espaço de trabalho do Azure Monitor. No portal do Azure, você pode verificar o uso atual de qualquer Espaço de Trabalho do monitor do Azure. Você pode ver as métricas de uso atuais no Metrics menu do espaço de trabalho do Azure Monitor. As métricas de utilização a seguir estão disponíveis como métricas padrão para cada espaço de trabalho do Azure Monitor.
- Série Temporal Ativa - O número de séries temporais únicas recentemente ingeridas no espaço de trabalho nas 12 horas anteriores
- Limite de séries temporais ativas - O limite do número de séries temporais exclusivas que podem ser ativamente ingeridas no espaço de trabalho
- % de utilização de séries temporais ativas - A percentagem de séries cronológicas ativas atuais que estão a ser utilizadas
- Eventos por minuto ingeridos - O número de eventos (amostras) por minuto recebidos recentemente
- Limite de Eventos por Minuto Ingerido - O número máximo de eventos por minuto que podem ser ingeridos antes de serem acelerados
- Eventos por minuto ingeridos % de utilização - A porcentagem do limite de taxa de ingestão métrica atual sendo utilizada
Para evitar a limitação de ingestão de métricas, você pode monitorar e configurar um alerta sobre os limites de ingestão. Veja Monitorizar limites de ingestão.
Consulte as cotas de serviço e limites para cotas padrão e também para entender o que pode ser aumentado com base no seu uso. Você pode solicitar aumento de cota para espaços de trabalho do Azure Monitor usando o Support Request menu para o espaço de trabalho do Azure Monitor. Certifique-se de incluir a ID, a ID interna e o Local/Região do espaço de trabalho do Azure Monitor na solicitação de suporte, que você pode encontrar no menu 'Propriedades' do espaço de trabalho do Azure Monitor no portal do Azure.
Falha na criação do Azure Monitor Workspace devido à avaliação da Política do Azure
Se a criação do Espaço de Trabalho do Azure Monitor falhar com um erro dizendo "O recurso 'resource-name-xyz' foi não permitido pela política", pode haver uma política do Azure que esteja impedindo que o recurso seja criado. Se houver uma política que imponha uma convenção de nomenclatura para seus recursos ou grupos de recursos do Azure, você precisará criar uma isenção para a convenção de nomenclatura para a criação de um Espaço de Trabalho do Azure Monitor.
Quando você cria um espaço de trabalho do Azure Monitor, por padrão, uma regra de coleta de dados e um ponto de extremidade de coleta de dados no formato "azure-monitor-workspace-name" serão criados automaticamente em um grupo de recursos no formato "MA_azure-monitor-workspace-name_location_managed". Atualmente, não há como alterar os nomes desses recursos e você precisará definir uma isenção na Política do Azure para isentar os recursos acima da avaliação da política. Consulte Estrutura de isenção da Política do Azure.