Objetivos de nível de serviço de monitoramento de nuvem
Este artigo faz parte de uma série no guia de monitoramento de nuvem.
Nas seções abaixo, você aprenderá sobre os princípios fundamentais dos objetivos de nível de serviço e como implementá-los e aplicá-los.
Descrição geral
Os objetivos de nível de serviço (SLOs) são metas mensuráveis para os principais indicadores de nível de serviço (SLIs) centrados no cliente. Eles medem a experiência do cliente em relação a uma carga de trabalho de negócios ou infraestrutura e determinam se o provedor de serviços da empresa atende às promessas feitas em um contrato de nível de serviço (SLA) formalmente negociado ou em um acordo informal entre todas as partes.
Como agente de serviços, você confia no compromisso da Microsoft com a confiabilidade dos serviços, conforme definido nos contratos de nível de serviço da Microsoft para serviços do Azure. Isso permite que você se concentre em suas responsabilidades na cadeia de serviços, como monitoramento sintético, conectividade de rede e segurança e conformidade.
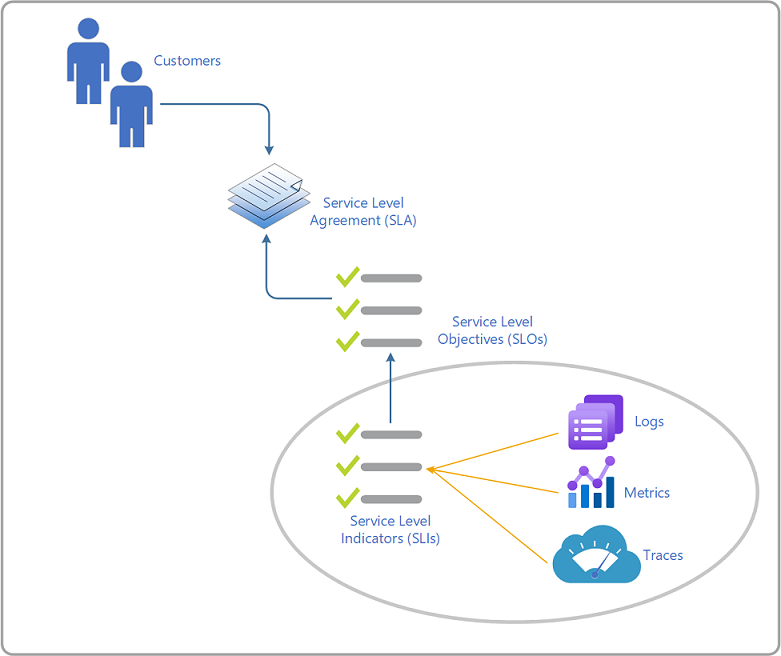
Terminologia
Abaixo estão as definições para cada um desses termos e uma breve descrição. Estas definições são retiradas do Manual SRE da Google.
| Termo | Description |
|---|---|
| Acordo de nível de serviço (SLA) | Normalmente, um compromisso vinculativo entre um prestador de serviços e um cliente. Normalmente, um acordo inclui as consequências do incumprimento das metas do SLO . Aspetos particulares do serviço são a qualidade, a disponibilidade e as responsabilidades, conforme acordado entre o prestador de serviços e o consumidor do serviço. |
| Monitorização | A prática de coletar dados quantitativos em tempo real sobre serviços e sistemas. |
| Métricas | Mede o comportamento relevante do serviço e pode ser agregado em indicadores de nível de serviço (SLIs), que são processados e agregados para medir o estado operacional atual de um serviço e quantificar seu comportamento. Os SLIs são os indicadores principais e em tempo real da saúde atual de um serviço. |
| Registos | Começa com o código e relata informações sobre uma execução individual de um caminho de código ou evento discreto. Use essas informações para ajudar a solucionar problemas e trabalhar para identificar problemas de causa raiz que afetam a experiência do cliente e a confiabilidade do serviço medida por SLIs/SLOs. |
| Objetivo de nível de serviço (SLO) | Um valor-alvo para o nível de serviço, medido por indicadores de nível de serviço (SLIs), que define expectativas sobre o desempenho de um serviço. Os SLOs rastreiam especificamente a experiência do cliente de ponta a ponta. Para estabelecer bons SLOs, você normalmente começa definindo a experiência desejada e, em seguida, instrumenta o código de serviço para medir essa experiência (coletar SLIs relevantes) e definir o objetivo de como você atende às expectativas do cliente ou não. |
| Indicador de nível de serviço (SLI) | Uma métrica que quantifica a qualidade ou fiabilidade do serviço. No mínimo, quatro SLIs comuns são avaliados: disponibilidade, latência, taxa de transferência e taxa de erro. |
| Disponibilidade | Geralmente refere-se à percentagem mensurável ou observável de tempo em que um sistema está operacional e funcional. Você mede a disponibilidade como um destino voltado para o cliente para a continuidade da experiência, que é afetada por um ou mais problemas de confiabilidade (e outros modos de falha relacionados a alterações de configuração, atualizações aplicadas e muito mais). |
| Orçamento de erro | A porcentagem do buffer restante em relação ao SLO. Os orçamentos de erro são a ferramenta que o DevOps usa para equilibrar a confiabilidade do serviço com o ritmo da inovação. |
O objetivo dos SLOs
Os SLOs servem a muitos propósitos essenciais no desenvolvimento e operações de cargas de trabalho em nuvem, incluindo:
- Quase em tempo real (NRT): Para dar uma visão NRT da saúde de um serviço conforme experimentado por um cliente.
- Redução do tempo de notificação (TTN): Conduza a notificação automatizada de problemas de serviço aos clientes, reduzindo significativamente o tempo de notificação (TTN).
- Sinal principal para os clientes: Atue como um sinal primário para as operações de implantação, impulsionando a reversão automatizada se ocorrerem problemas, expondo assim menos clientes a possíveis problemas.
- Verificação de alterações: forneça a validação de que as alterações alcançaram a melhoria esperada da experiência do cliente.
- Determinar prioridades: ajude as equipes a entender se devem criar recursos ou trabalhar na confiabilidade.
- Informações sobre a integridade do serviço: permita discussões objetivas e focadas no cliente sobre a integridade do serviço.
- Reduza o tempo de análise: acelere a mitigação e a análise de causa raiz (RCA) dos problemas do cliente, direcionando o foco para o serviço responsável.
- Dependências arquitetônicas: atuam como uma entrada essencial nas decisões de arquitetura quando os serviços assumem dependências.
- Cria confiança: Fornece uma compreensão compartilhada das medidas de saúde, o que gera confiança entre as equipes.
- Trazer transparência: Exponha os mesmos SLIs que usamos para administrar nossos negócios aos nossos clientes para que eles possam administrar os deles.
- Painel único de vidro: habilite um painel único horizontal de vidro para os serviços e suas dependências e silos de decomposição.
Usando SLOs para conduzir seu processo de engenharia, o DevOps e a TI podem obter uma compreensão antecipada da integridade do aplicativo ou serviço de infraestrutura que criam ou migram no Azure. Isso pode ser usado para orientar as decisões humanas e automatizadas que precisam ser tomadas sobre a confiabilidade desses serviços. Esta transformação na prática de engenharia terá um impacto significativo na fiabilidade desses serviços a curto prazo.
Como definir SLOs?
O objetivo de um SLO é obter sinais claros que meçam com precisão a qualidade da perspetiva do cliente. Cada equipe de serviço cria um pequeno conjunto de Objetivos de Nível de Serviço (SLOs) que definem o intervalo permitido para as métricas mensuráveis mais importantes do serviço, conforme experimentado pelo consumidor do serviço. Um SLO é uma meta numérica definida para uma métrica emitida por um serviço. As métricas associadas a essa meta podem ser monitoradas para determinar se o serviço está íntegro.
Por exemplo, aqui está um exemplo simplificado de um SLO para um aplicativo interno baseado na Web de controle de tempo - As solicitações nos últimos 5 minutos são atendidas em menos de 1000 milissegundos no percentil 99.
As métricas são agregações de dados de séries temporais chamadas Indicadores de Nível de Serviço (SLIs). Onde os SLIs estão reunidos importa muito. No exemplo acima, se o cliente interage com o serviço usando uma API, medir a latência do sistema e o tempo para processar solicitações são SLIs precisos. No entanto, se o cliente interage com o serviço usando um portal da Web, o tempo total para atender a solicitação também deve incluir o desempenho JavaScript da página da Web.
O foco para os proprietários de serviços é determinar o seguinte:
- Quais cenários são indicadores críticos da integridade do serviço na perspetiva do cliente,
- Onde reunir os SLIs para que estejam o mais próximo possível da experiência do cliente, e
- Quais devem ser os SLOs para esses SLIs?
Os SLOs podem ser definidos com uma abordagem gradual para impulsionar a realização ou são prescritos diretamente pela empresa. Você usa os SLOs definidos por um serviço para tomar decisões arquitetônicas sobre como criá-los. Portanto, é essencial escolher cuidadosamente quais cenários medir e qual o prazo para medi-los. Para resumir, um SLO é composto pelos seguintes valores:
- Um SLI. Por exemplo, a proporção de solicitações suficientemente rápidas, medida a partir do balanceador de carga, é inferior a 400 ms.
- Uma duração. O período de tempo em que uma métrica é medida.
- Um alvo. Por exemplo, uma porcentagem de destino de solicitações rápidas para o total de solicitações (como 90%) que você espera atender por uma determinada duração.
Tipos de SLOs
Se você olhar para todo o setor, existem dois tipos de SLOs:
SLOs centrados em serviços - Esses SLOs são objetivos táticos que as equipes definem para melhorar a qualidade de seu serviço ao longo do tempo gradualmente. Eles são projetados para serem metas pragmáticas alcançáveis em um marco de engenharia. Por exemplo, se um serviço está atualmente atingindo 99,7% de disponibilidade, a equipe pode definir uma meta para atingir 99,9% de disponibilidade no próximo trimestre.
SLOs centrados no cliente - Esses SLOs definem o estado ou objetivo futuro ideal. Neste ponto, mais investimentos em qualidade seriam considerados desnecessários, porque você está atendendo plenamente às expectativas dos clientes.
Por exemplo, se o seu cliente espera que um serviço comercial ou de infraestrutura que você opera forneça 99,99% de disponibilidade, e o serviço atualmente atinge apenas 99,8% de disponibilidade, o SLO centrado no cliente ainda é de 99,99%.
Definir SLOs adequados leva tempo. O primeiro passo é conversar com seus clientes e entender o que seus usuários querem do serviço para derivar uma pequena seleção de indicadores e documentá-lo. Aprenda os cenários e as tolerâncias de como eles usam seu serviço e o que seu serviço precisa oferecer para executar seus negócios com sucesso. Esta é geralmente uma experiência iterativa, com suas expectativas variando de eu quero 100% de disponibilidade em todas as condições, sem impacto para o nosso fluxo de receita, até o gerenciamento de expectativas variantes entre segmentos de clientes.
As abordagens de monitoramento que analisam apenas a integridade do serviço (ou instância de serviço) são vulneráveis a problemas de experiência do cliente ausentes em ambas as extremidades do espectro; A integridade do serviço nem sempre está correlacionada com a qualidade da experiência do cliente. Isso ocorre porque há características de comportamento diferentes entre um serviço PaaS e SaaS do Azure, a configuração desses serviços do Azure, como e onde (ou seja, qual região) seus recursos são implantados e a adição de seu código/lógica personalizado, o que adiciona mais complexidade.
Ao definir um SLO, é importante lembrar que o(s) seu(s) provedor(es) de nuvem dependem(são) do seu SLA. Contabilize os contratos de nível de serviço especificados para cada um dos seus serviços. Para o Azure, consulte Contratos de Nível de Serviço (SLA) para Serviços Online
Como você define SLIs?
Uma especificação SLI é uma declaração formal das expectativas dos usuários sobre uma dimensão de confiabilidade específica para o seu serviço, como latência ou disponibilidade.
Comece de forma simples, selecionando as métricas certas para medir e coletar, e não complique demais coletando muitas métricas que não são significativas. Certifique-se de que os SLIs definidos tenham uma relação direta com a experiência do cliente. É por isso que é essencial entender a perspetiva dos usuários para começar com apenas alguns indicadores.
Se o seu serviço é restrito a recursos de alguma forma, como memória ou CPU, então sua saturação também pode ser um excelente SLI. No entanto, a saturação não deve ser usada como um SLO, uma vez que não corresponde diretamente a uma experiência de usuário ruim (um serviço pode ter alta utilização de memória, mas os usuários não são afetados).
Recomendamos que você crie até três indicadores. Mais de três indicadores raramente acrescentam valor significativo. Muitas vezes, um número excessivo de indicadores pode significar que você inclui sintomas de indicadores primários. O tráfego e a saturação devem ser adicionais a esses três indicadores principais, uma vez que descrevem a carga de serviço e apoiam a interpretação de outros indicadores de serviço.
Como implementar SLOs?
Os SLIs que mais importam são os que representam mais claramente um impacto no seu serviço do ponto de vista do seu cliente. Para muitos serviços, isso inclui latência, taxa de transferência, taxa de erro e disponibilidade. Se o seu serviço tiver considerações especiais que afetem a experiência do cliente, os SLIs para essas áreas também devem ser medidos. Por exemplo, a latência de processamento de ponta a ponta para um serviço de mensagens é um indicador direto da experiência do cliente e deve ser coberta por um SLI.
Exemplos de SLO
Os Recursos Humanos estão interessados em modernizar a sua aplicação interna baseada na Web de controlo de tempo e em alojá-la na nuvem do Azure com a ajuda da TI empresarial. Eles querem que o serviço continue alcançando todos os usuários da organização, por isso estão interessados no seguinte:
- Relatórios de uso e quantos usuários estão usando o serviço ao longo do tempo.
- Monitoramento regular de integridade, como disponibilidade, desempenho, segurança e conformidade (garantia de serviço).
- Custo, como o custo mensal de um serviço.
- Cibersegurança, em termos de controlo de acesso a recursos e dados seguindo uma estratégia de segurança Zero Trust.
Como vemos nesses exemplos acima, as categorias e exemplos de SLO/SLI são necessários para definir no início do design do serviço. Isso não é nada diferente dos serviços locais que você vem criando.
Tabelas SLO/categorias SLI
Os exemplos que se seguem não são, de modo algum, uma lista exaustiva. Embora os SLOs de confiabilidade e manutenibilidade sejam marcas dos sistemas há décadas, você pode definir SLOs que incluam medidas de cibersegurança, qualidade e experiência do usuário e custo.
Serviços
As medidas típicas de alto nível de um serviço ou sistema são geralmente codificadas em contratos de serviço. A maioria dos contratos modernos mede a disponibilidade como o SLO principal e usa medidas simples de tempo de inatividade com base em itens-chave de carga de trabalho ou unidades de produção, como tokens de autenticação, caixas de correio ou contas de armazenamento.
| Categoria | Description | Exemplo |
|---|---|---|
| Disponibilidade | Tempo de inatividade simples ou tempo médio entre manutenção ou disponibilidade operacional (MTBM/(MTBM+MDT)) | 99,99% num período mensal |
| Capacidade | Garanta o desempenho adequado, máximo ou ótimo de negócios e serviços, taxa de transferência, armazenamento, pessoas, largura de banda, demanda, recursos e funções de serviço. Inclui mão de obra e limites de tempo para servir como gatilhos. | % de utilização (CPU, armazenamento, memória, latência, taxa de transferência, dimensionamento) |
| Segurança | Ameaças e vulnerabilidades ativas (internas e externas) que podem ou estão causando danos aos negócios, ativos e dados. | Deteção da ameaça de HAFNIUM |
| Conformidade | Atualizações, níveis de manutenção, conformidade de proteção, desvio de configuração desejado | 99,5% de atualizações atendidas em todos os ativos |
| Continuidade | Capacidade de sobreviver e recuperar de grandes desastres e eventos externos. | Tempo (reconstituição) |
| Quality of Service (QoS) | Características da experiência real dos usuários ao longo do tempo. | Qualidade das chamadas das equipas - perda de < pacotes recebidos 2% |
Fiabilidade
A confiabilidade, o SLO clássico, implica o grau de confiabilidade, durabilidade e qualidade ao longo do tempo de sistemas, serviços, recursos ou componentes para falhas e failovers, com esforço de gerenciamento aplicado para resolver falhas (como criar mais redundância ou adicionar uma rede de entrega de conteúdo) para aumentar o tempo operacional ou a disponibilidade. Também pode significar a precisão, fidelidade, integridade e confiabilidade dos dados usados para medir SLOs. Pode significar a probabilidade clássica de que um sistema irá executar a função pretendida sob condições especificadas, tais como tensão de temperatura. A resiliência também inclui fatores de projeto integrados ou recursos que fornecem adaptabilidade, como dimensionamento, resfriamento, balanceamento de carga, recuperação, demanda imprevisível, desempenho degradado sob estresse severo e design para continuidade em desastres maiores (geralmente um SLO separado).
| Categoria | Description | Exemplo |
|---|---|---|
| Taxa de Falhas | Número de falhas ao longo do total de horas de funcionamento | 5 falhas em 973 hrs nosso .00514 |
| Tempo médio entre falhas (MTBF) | MTBF é o inverso da taxa de falha | 194.6 horas |
Capacidade de Manutenção
Combine SLOs de suporte para processos de gerenciamento de serviços de TI, como gerenciamento de incidentes e problemas, juntamente com SLOs de confiabilidade, para que a medição de disponibilidade possa ser alcançada.
| Categoria | Description | Exemplo |
|---|---|---|
| Desempenho de incidentes de serviço | Por categoria, produto ou prioridade. | Medidas de tempo e custo para cada fase do ciclo de vida do incidente. |
| Desempenho de incidentes de segurança | Por categoria, produto ou prioridade. | Medidas de tempo e custo para cada fase do ciclo de vida do incidente. |
| Tempo médio de reparação do componente (MTTR) | Desde a deteção de eventos até a restauração ou remediação. | |
| Tempo médio entre manutenção (MTBM) | Tempo médio ou médio entre todas as ações de manutenção, incluindo ações preventivas onde ocorre o trabalho normal de produção. | Ver Tempo de atraso de manutenção |
| Tempo de atraso de manutenção (MDT) | Tempo total desde a deteção até a recuperação, incluindo atraso logístico e administrativo. | Tempo para substituir o hardware para incluir pedido, envio e instalação. |
Experiência do cliente
| Categoria | Description | Exemplo |
|---|---|---|
| Débito | A quantidade, taxa ou velocidade da carga de trabalho ou carga produtiva colocada em um sistema ao longo do tempo. | Transações por unidade de tempo. |
| Taxa de erro | O número total de erros em percentagem. | % Eventos de segurança |
| Latência | Uma medida de tempo ou atraso de entrada para saída, movimento de trabalho através de um processo, ou de aplicativo para usuário. | Média de segundos. |
Outras
| Categoria | Description | Exemplo |
|---|---|---|
| Custo | Meça despesas, faturamento e faturas por serviço, componente ou tempo. | Despesa de Capital ou Despesa Operacional |
| Cobertura | Porcentagem de componentes, sistemas e serviços sob gerenciamento (conformidade) | Conformidade |
| Fiabilidade da alimentação | Falhas de batimento cardíaco, conectores, alterações e muito mais. | Acompanhamento de alterações em dados de missão crítica da empresa. |
| Produtividade | Eficácia para realizar tarefas de forma produtiva | Mão de obra, tempo por funcionário, produtividade do analista. |
Considerações
Garantir o acesso. Certifique-se de que os gerentes e outras pessoas na organização tenham acesso às visualizações disponíveis no Azure Monitor ou de outros serviços do Azure, especialmente SaaS e PaaS do Azure, para evitar a duplicação delas.
Garanta a cobertura de monitoramento ou a visibilidade total dos ativos. Garanta agentes, logs emitidos, tabelas e consultas para todos os ativos que precisam ser gerenciados e protegidos, e identifique "pontos cegos" ou lacunas na cobertura para garantir realismo nos SLOs.
Obtenha os dados corretos na frente dos consumidores certos. Garantir que os consumidores de SLOs e SLIs possam interpretar os dados subjacentes para criar confiança e orientar decisões usando as informações obtidas a partir dos dados.
Faça promessas razoáveis. Ao definir SLOs como metas , especialmente quando o gerenciamento de custos é essencial, certifique-se de que o desempenho real do sistema não esteja com desempenho excessivo ou insuficiente, ou ajuste a meta para gerenciar as expectativas do cliente.
Contabilizar imprevistos externos. Desenvolva planos de continuidade e avaliações de risco para levar em conta eventos que não estão sob seu controle, como condições climáticas, quedas de energia ou desastres.
Conta para Mudança. Garantir que os SLOs levem em conta alterações no serviço ou alterações na confiabilidade técnica, rendimento, qualidade e manutenibilidade - como reduções na equipe de suporte.
Forneça um conjunto equilibrado de SLOs. Garanta uma gama de SLOs que forneçam uma perspetiva equilibrada ou de 360 graus sobre o serviço ou sistema e um foco na confiabilidade.