RAG com Azure Cosmos DB baseado em vCore para MongoDB
No reino em rápida evolução da IA generativa, os Large Language Models (LLMs) como o GPT-3.5 transformaram o processamento de linguagem natural. No entanto, uma tendência emergente em IA é o uso de lojas vetoriais, que desempenham um papel fundamental no aprimoramento de aplicações de IA.
Este tutorial explora como usar o Azure Cosmos DB para MongoDB (vCore), LangChain e OpenAI para implementar a Geração Aumentada de Recuperação (RAG) para um desempenho superior de IA, além de discutir LLMs e suas limitações. Exploramos o paradigma rapidamente adotado de "geração aumentada de recuperação" (RAG) e discutimos brevemente a estrutura LangChain, modelos OpenAI do Azure. Finalmente, integramos estes conceitos numa aplicação do mundo real. No final, os leitores terão uma sólida compreensão destes conceitos.
Compreender os Grandes Modelos de Linguagem (LLMs) e suas limitações
Os Large Language Models (LLMs) são modelos avançados de redes neurais profundas treinados em extensos conjuntos de dados de texto, permitindo-lhes compreender e gerar texto semelhante ao humano. Embora revolucionários no processamento de linguagem natural, os LLMs têm limitações inerentes:
- Alucinações: LLMs às vezes geram informações factualmente incorretas ou infundadas, conhecidas como "alucinações".
- Dados obsoletos: os LLMs são treinados em conjuntos de dados estáticos que podem não incluir as informações mais recentes, limitando sua relevância atual.
- Sem acesso aos dados locais do usuário: os LLMs não têm acesso direto a dados pessoais ou localizados, restringindo sua capacidade de fornecer respostas personalizadas.
- Limites de token: os LLMs têm um limite máximo de token por interação, restringindo a quantidade de texto que podem processar de uma só vez. Por exemplo, o gpt-3.5-turbo da OpenAI tem um limite de token de 4096.
Aproveite a geração aumentada de recuperação (RAG)
A geração aumentada de recuperação (RAG) é uma arquitetura projetada para superar as limitações do LLM. O RAG usa a pesquisa vetorial para recuperar documentos relevantes com base em uma consulta de entrada, fornecendo esses documentos como contexto para o LLM para gerar respostas mais precisas. Em vez de depender apenas de padrões pré-treinados, a RAG melhora as respostas incorporando informações relevantes e atualizadas. Esta abordagem ajuda a:
- Minimizar alucinações: fundamentar as respostas em informações factuais.
- Garantir informações atuais: recuperar os dados mais recentes para garantir respostas atualizadas.
- Utilize bancos de dados externos: Embora não conceda acesso direto a dados pessoais, o RAG permite a integração com bases de conhecimento externas específicas do usuário.
- Otimize o uso do token: Ao se concentrar nos documentos mais relevantes, o RAG torna o uso do token mais eficiente.
Este tutorial demonstra como o RAG pode ser implementado usando o Azure Cosmos DB para MongoDB (vCore) para criar um aplicativo de resposta a perguntas adaptado aos seus dados.
Visão geral da arquitetura de aplicativos
O diagrama de arquitetura abaixo ilustra os principais componentes da nossa implementação RAG:
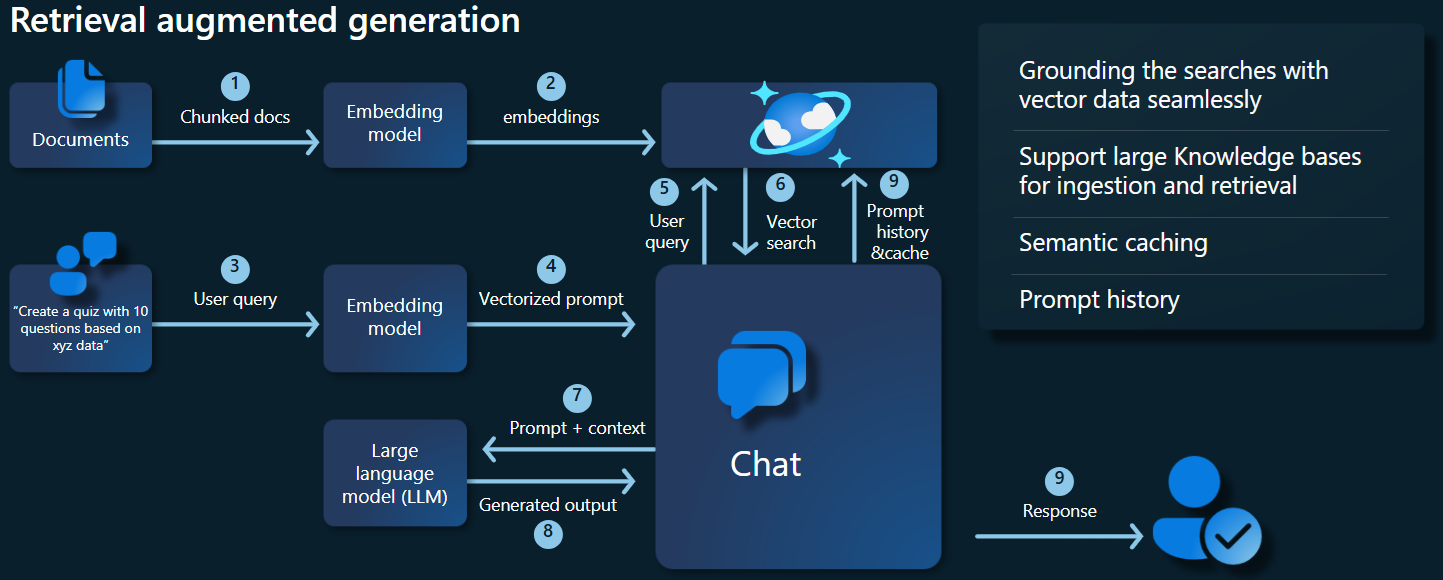
Principais componentes e estruturas
Vamos agora discutir as várias estruturas, modelos e componentes usados neste tutorial, enfatizando suas funções e nuances.
Azure Cosmos DB para MongoDB (vCore)
O Azure Cosmos DB para MongoDB (vCore) suporta pesquisas de semelhança semântica, essenciais para aplicações alimentadas por IA. Ele permite que dados em vários formatos sejam representados como incorporações vetoriais, que podem ser armazenadas ao lado de dados de origem e metadados. Usando um algoritmo de vizinhos mais próximos aproximados, como o mundo pequeno navegável hierárquico (HNSW), essas incorporações podem ser consultadas para pesquisas rápidas de semelhança semântica.
Estrutura LangChain
LangChain simplifica a criação de aplicativos LLM fornecendo uma interface padrão para cadeias, integrações de várias ferramentas e cadeias de ponta a ponta para tarefas comuns. Ele permite que os desenvolvedores de IA criem aplicativos LLM que aproveitam fontes de dados externas.
Principais aspetos do LangChain:
- Cadeias: Sequências de componentes resolvendo tarefas específicas.
- Componentes: Módulos como wrappers LLM, wrappers de armazenamento vetorial, modelos de prompt, carregadores de dados, divisores de texto e retrievers.
- Modularidade: Simplifica o desenvolvimento, a depuração e a manutenção.
- Popularidade: Um projeto de código aberto rapidamente ganhando adoção e evoluindo para atender às necessidades do usuário.
Interface dos Serviços de Aplicativo do Azure
Os serviços de aplicativos fornecem uma plataforma robusta para a criação de interfaces web amigáveis para aplicativos Gen-AI. Este tutorial usa os serviços do Aplicativo do Azure para criar uma interface Web interativa para o aplicativo.
Modelos OpenAI
A OpenAI é líder em pesquisa de IA, fornecendo vários modelos para geração de linguagem, vetorização de texto, criação de imagens e conversão de áudio em texto. Para este tutorial, usaremos os modelos de incorporação e linguagem da OpenAI, cruciais para entender e gerar aplicativos baseados em linguagem.
Incorporação de modelos vs. modelos de geração de linguagem
| Categoria | Modelo de incorporação de texto | Modelo de linguagem |
|---|---|---|
| Objetivo | Conversão de texto em incorporações vetoriais. | Compreender e gerar linguagem natural. |
| Função | Transforma dados textuais em matrizes de números de alta dimensão, capturando o significado semântico do texto. | Compreende e produz texto semelhante ao humano com base em dados dados. |
| Saída | Matriz de números (incorporações vetoriais). | Texto, respostas, traduções, código, etc. |
| Exemplo de saída | Cada incorporação representa o significado semântico do texto em forma numérica, com uma dimensionalidade determinada pelo modelo. Por exemplo, text-embedding-ada-002 gera vetores com 1536 dimensões. |
Texto contextualmente relevante e coerente gerado com base nos dados fornecidos. Por exemplo, gpt-3.5-turbo pode gerar respostas a perguntas, traduzir texto, escrever código e muito mais. |
| Casos de uso típicos | - Pesquisa semântica | - Chatbots |
| - Sistemas de recomendação | - Criação automatizada de conteúdo | |
| - Agrupamento e classificação de dados de texto | - Tradução linguística | |
| - Recuperação de informação | - Sumarização | |
| Representação de dados | Representação numérica (incorporações) | Texto em linguagem natural |
| Dimensionalidade | O comprimento da matriz corresponde ao número de dimensões no espaço de incorporação, por exemplo, 1536 dimensões. | Normalmente representado como uma sequência de tokens, com o contexto determinando o comprimento. |
Principais componentes da aplicação
- Azure Cosmos DB for MongoDB vCore: Armazenando e consultando incorporações vetoriais.
- LangChain: Construindo o fluxo de trabalho LLM do aplicativo. Utiliza ferramentas como:
- Carregador de Documentos: Para carregar e processar documentos de um diretório.
- Integração de repositório vetorial: para armazenar e consultar incorporações vetoriais no Azure Cosmos DB.
- AzureCosmosDBVectorSearch: Wrapper em torno da pesquisa vetorial do Cosmos DB
- Serviços de Aplicativo do Azure: Criando a interface do usuário para o aplicativo Cosmic Food.
- Azure OpenAI: Para fornecer LLM e modelos de incorporação, incluindo:
- text-embedding-ada-002: Um modelo de incorporação de texto que converte texto em incorporações vetoriais com 1536 dimensões.
- gpt-3.5-turbo: Um modelo de linguagem para compreender e gerar linguagem natural.
Configurar o ambiente
Para começar a otimizar a geração aumentada de recuperação (RAG) usando o Azure Cosmos DB para MongoDB (vCore), siga estas etapas:
- Crie os seguintes recursos no Microsoft Azure:
- Azure Cosmos DB para cluster vCore do MongoDB: consulte o guia de início rápido aqui.
- Recurso do Azure OpenAI com:
- Incorporação de implantação de modelo (por exemplo,
text-embedding-ada-002). - Implantação de modelo de chat (por exemplo,
gpt-35-turbo).
- Incorporação de implantação de modelo (por exemplo,
Exemplos de documentos
Neste tutorial, estaremos carregando um único arquivo de texto usando o Documento. Esses arquivos devem ser salvos em um diretório chamado dados na pasta src . O conteúdo da seringa é o seguinte:
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Carregar documentos
- Defina a cadeia de conexão do Cosmos DB para MongoDB (vCore), Nome do Banco de Dados, Nome da Coleção e Índice:
mongo_client = MongoClient(mongo_connection_string)
database_name = "Contoso"
db = mongo_client[database_name]
collection_name = "ContosoCollection"
index_name = "ContosoIndex"
collection = db[collection_name]
- Inicialize o cliente de incorporação.
from langchain_openai import AzureOpenAIEmbeddings
openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002")
openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding")
azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings(
model=openai_embeddings_model,
azure_deployment=openai_embeddings_deployment,
)
- Crie incorporações a partir dos dados, salve no banco de dados e retorne uma conexão com seu repositório vetorial, Cosmos DB for MongoDB (vCore).
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents(
json_data,
azure_openai_embeddings,
collection=collection,
index_name=index_name,
)
- Crie o seguinte índice de vetor HNSW na coleção (Observe que o nome do índice é o mesmo que acima).
num_lists = 100
dimensions = 1536
similarity_algorithm = CosmosDBSimilarityType.COS
kind = CosmosDBVectorSearchType.VECTOR_HNSW
m = 16
ef_construction = 64
vector_store.create_index(
num_lists, dimensions, similarity_algorithm, kind, m, ef_construction
)
Executar pesquisa vetorial usando o Cosmos DB para MongoDB (vCore)
- Conecte-se ao seu repositório de vetores.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string(
connection_string=mongo_connection_string,
namespace=f"{database_name}.{collection_name}",
embedding=azure_openai_embeddings,
)
- Defina uma função que execute a pesquisa de semelhança semântica usando a Pesquisa vetorial do Cosmos DB em uma consulta (observe que este trecho de código é apenas uma função de teste).
query = "beef dishes"
docs = vector_store.similarity_search(query)
print(docs[0].page_content)
- Inicialize o cliente de bate-papo para implementar uma função RAG.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI(
model=openai_chat_model,
azure_deployment=openai_chat_deployment,
)
- Crie uma função RAG.
history_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
(
"user",
"""Given the above conversation,
generate a search query to look up to get information relevant to the conversation""",
),
]
)
context_prompt = ChatPromptTemplate.from_messages(
[
("system", "Answer the user's questions based on the below context:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
]
)
- Converte o armazenamento vetorial em um retriever, que pode procurar documentos relevantes com base em parâmetros especificados.
vector_store_retriever = vector_store.as_retriever(
search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold}
)
- Crie uma cadeia de retriever que esteja ciente do histórico de conversas, garantindo a recuperação de documentos contextualmente relevantes usando o modelo azure_openai_chat e vetor_store_retriever.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)
- Crie uma cadeia que combine documentos recuperados em uma resposta coerente usando o modelo de linguagem (azure_openai_chat) e um prompt especificado (context_prompt).
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)
- Crie uma cadeia que lida com todo o processo de recuperação, integrando a cadeia de retriever com reconhecimento de histórico e a cadeia de combinação de documentos. Esta cadeia RAG pode ser executada para recuperar e gerar respostas contextualmente precisas.
rag_chain: Runnable = create_retrieval_chain(
retriever=retriever_chain,
combine_docs_chain=context_chain,
)
Saídas de amostra
A captura de tela abaixo ilustra os resultados para várias perguntas. Uma pesquisa puramente semântica retorna o texto bruto dos documentos de origem, enquanto o aplicativo de resposta a perguntas usando a arquitetura RAG gera respostas precisas e personalizadas combinando o conteúdo do documento recuperado com o modelo de linguagem.
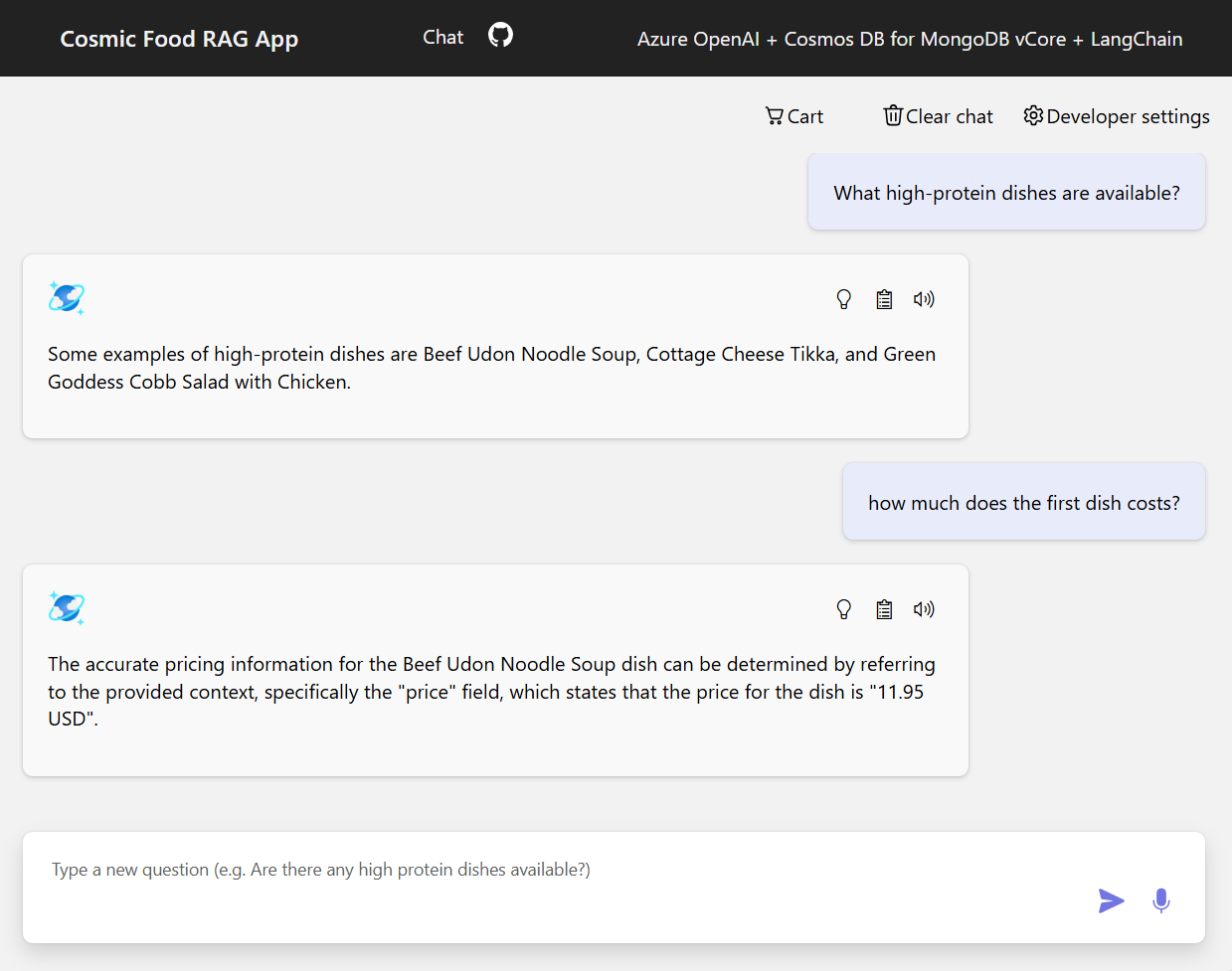
Conclusão
Neste tutorial, exploramos como criar um aplicativo de resposta a perguntas que interage com seus dados privados usando o Cosmos DB como um repositório vetorial. Ao aproveitar a arquitetura de geração aumentada de recuperação (RAG) com LangChain e Azure OpenAI, demonstramos como os repositórios vetoriais são essenciais para aplicativos LLM.
O RAG é um avanço significativo em IA, particularmente no processamento de linguagem natural, e a combinação dessas tecnologias permite a criação de poderosas aplicações orientadas por IA para vários casos de uso.
Próximos passos
Para obter uma experiência prática detalhada e ver como o RAG pode ser implementado usando o Azure Cosmos DB para modelos MongoDB (vCore), LangChain e OpenAI, visite nosso repositório GitHub.