Como ingerir dados usando o Azure Data Factory no Azure Cosmos DB para PostgreSQL
APLICA-SE A: ![]() Azure Cosmos DB para PostgreSQL (alimentado pela extensão de banco de dados Citus para PostgreSQL)
Azure Cosmos DB para PostgreSQL (alimentado pela extensão de banco de dados Citus para PostgreSQL)
O Azure Data Factory é um ETL baseado na nuvem e um serviço de integração de dados. Ele permite que você crie fluxos de trabalho orientados por dados para mover e transformar dados em escala.
Usando o Data Factory, você pode criar e agendar fluxos de trabalho controlados por dados (chamados pipelines) que ingerem dados de armazenamentos de dados diferentes. Os pipelines podem ser executados localmente, no Azure ou em outros provedores de nuvem para análises e relatórios.
O Data Factory tem um coletor de dados para o Azure Cosmos DB para PostgreSQL. O coletor de dados permite que você traga seus dados (arquivos relacionais, NoSQL, data lake) para tabelas do Azure Cosmos DB for PostgreSQL para armazenamento, processamento e relatórios.
Importante
No momento, o Data Factory não oferece suporte a pontos de extremidade privados para o Azure Cosmos DB para PostgreSQL.
Data Factory para ingestão em tempo real
Aqui estão os principais motivos para escolher o Azure Data Factory para ingerir dados no Azure Cosmos DB para PostgreSQL:
- Fácil de usar - Oferece um ambiente visual livre de código para orquestrar e automatizar a movimentação de dados.
- Poderoso - Usa a capacidade total de largura de banda de rede subjacente, até 5 GiB / s de taxa de transferência.
- Conectores integrados - Integra todas as suas fontes de dados, com mais de 90 conectores integrados.
- Econômico - Suporta um serviço de nuvem pré-pago e totalmente gerenciado sem servidor que pode ser dimensionado sob demanda.
Etapas para usar o Data Factory
Neste artigo, você cria um pipeline de dados usando a interface do usuário (UI) do Data Factory. O pipeline neste data factory copia dados do armazenamento de Blob do Azure para um banco de dados. Para obter uma lista dos arquivos de dados suportados como origens e sinks, consulte a tabela de arquivos de dados suportados.
No Data Factory, você pode usar a atividade Copiar para copiar dados entre armazenamentos de dados localizados no local e na nuvem para o Azure Cosmos DB para PostgreSQL. Se você é novo no Data Factory, aqui está um guia rápido sobre como começar:
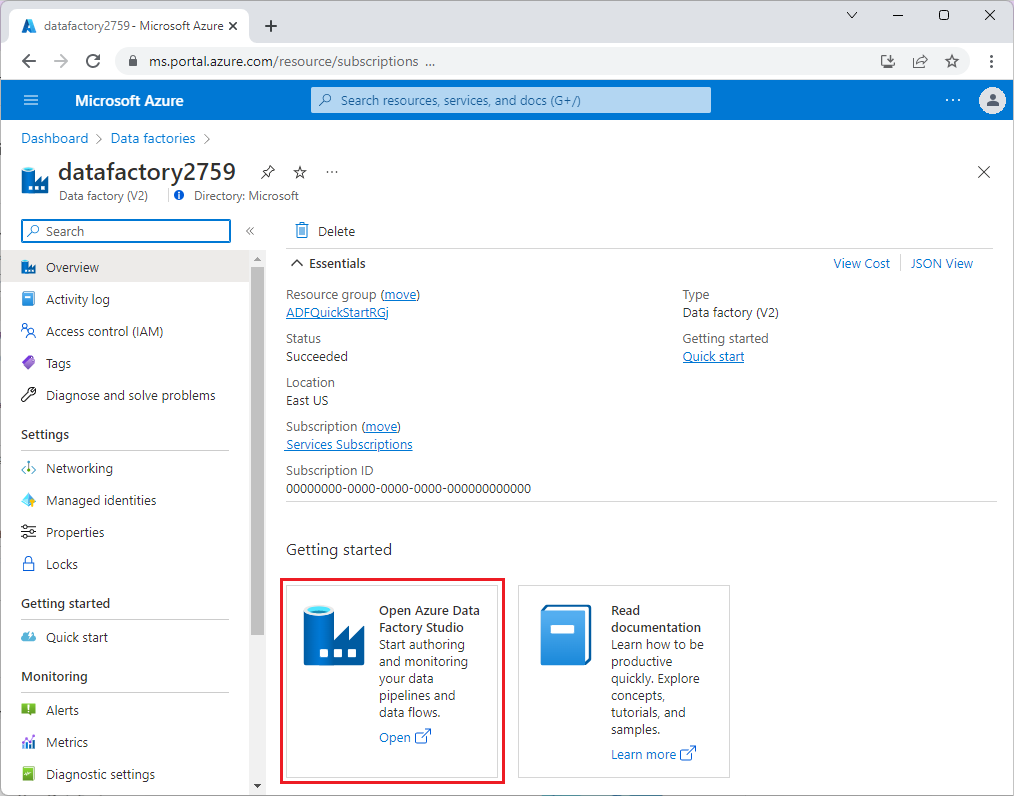
Depois que o Data Factory for provisionado, vá para sua fábrica de dados e inicie o Azure Data Factory Studio. Você vê a página inicial do Data Factory conforme mostrado na imagem a seguir:
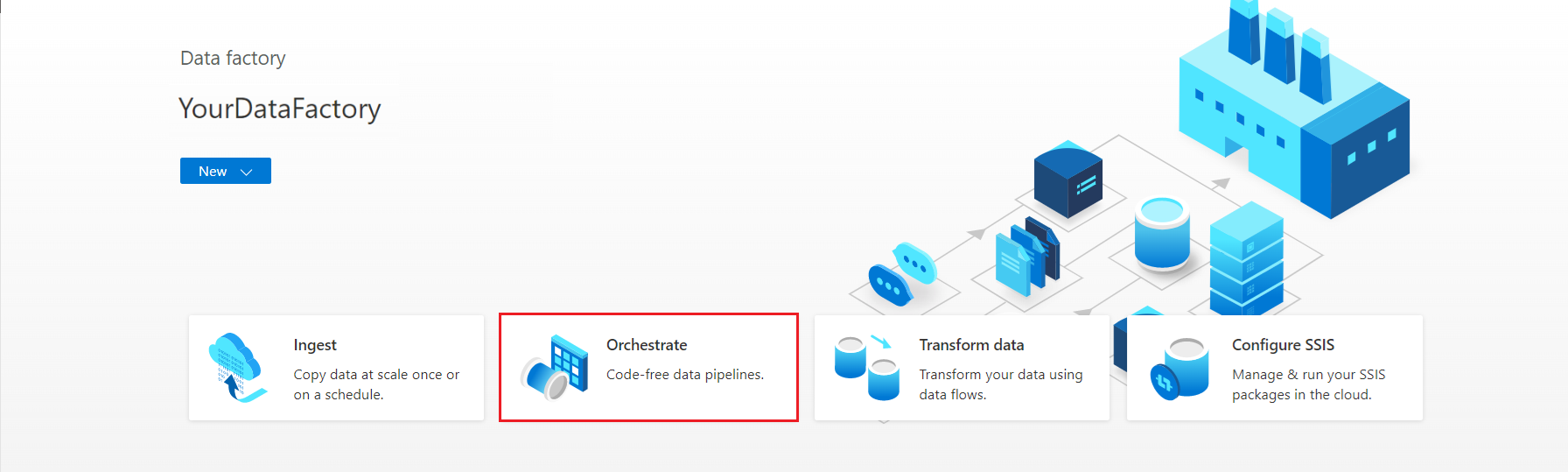
Na home page do Azure Data Factory Studio, selecione Orquestrar.
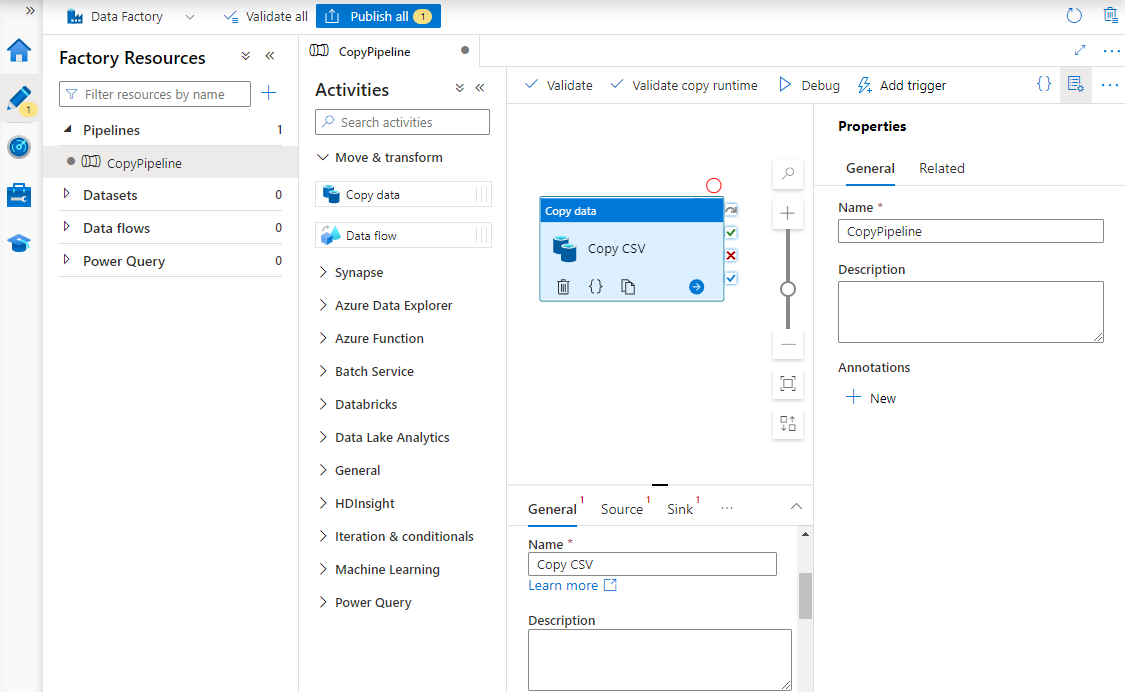
Em Propriedades, insira um nome para o pipeline.
Na caixa de ferramentas Atividades , expanda a categoria Mover & transformar e arraste e solte a atividade Copiar dados na superfície do designer de pipeline. Na parte inferior do painel do designer, na guia Geral , insira um nome para a atividade de cópia.
Configure o código-fonte.
Na página Atividades, selecione a guia Origem. Selecione Novo para criar um conjunto de dados de origem.
Na caixa de diálogo Novo Conjunto de Dados, selecione Armazenamento de Blob do Azure e, em seguida, selecione Continuar.
Escolha o tipo de formato dos seus dados e, em seguida, selecione Continuar.
Na página Definir propriedades, em Serviço vinculado, selecione Novo.
Na página Novo serviço vinculado, insira um nome para o serviço vinculado e selecione sua conta de armazenamento na lista Nome da conta de armazenamento.
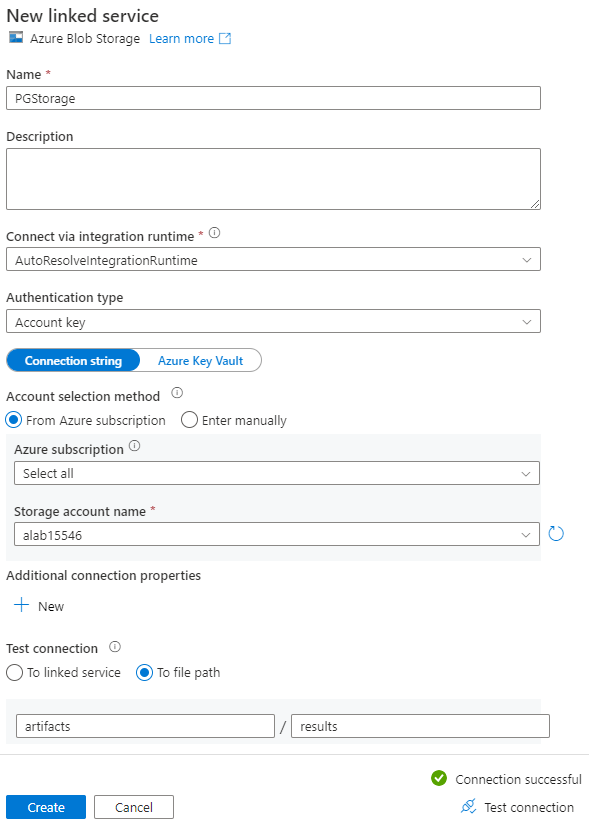
Em Testar conexão, selecione Para caminho do arquivo, insira o contêiner e o diretório aos quais se conectar e selecione Testar conexão.
Selecione Criar para salvar a configuração.
Na tela Definir propriedades, selecione OK.
Configurar coletor.
Na página Atividades, selecione a guia Coletor. Selecione Novo para criar um conjunto de dados de coletor.
Na caixa de diálogo Novo Conjunto de Dados, selecione Banco de Dados do Azure para PostgreSQL e selecione Continuar.
Na página Definir propriedades, em Serviço vinculado, selecione Novo.
Na página Novo serviço vinculado, insira um nome para o serviço vinculado e selecione Inserir manualmente no método de seleção de conta.
Insira o nome do coordenador do cluster no campo Nome de domínio totalmente qualificado. Você pode copiar o nome do coordenador na página Visão geral do cluster do Azure Cosmos DB para PostgreSQL.
Deixe a porta padrão 5432 no campo Porta para conexão direta com o coordenador ou substitua-a pela porta 6432 para se conectar à porta PgBouncer gerenciada.
Insira o nome do banco de dados no cluster e forneça credenciais para se conectar a ele.
Selecione SSL na lista suspensa Método de criptografia .
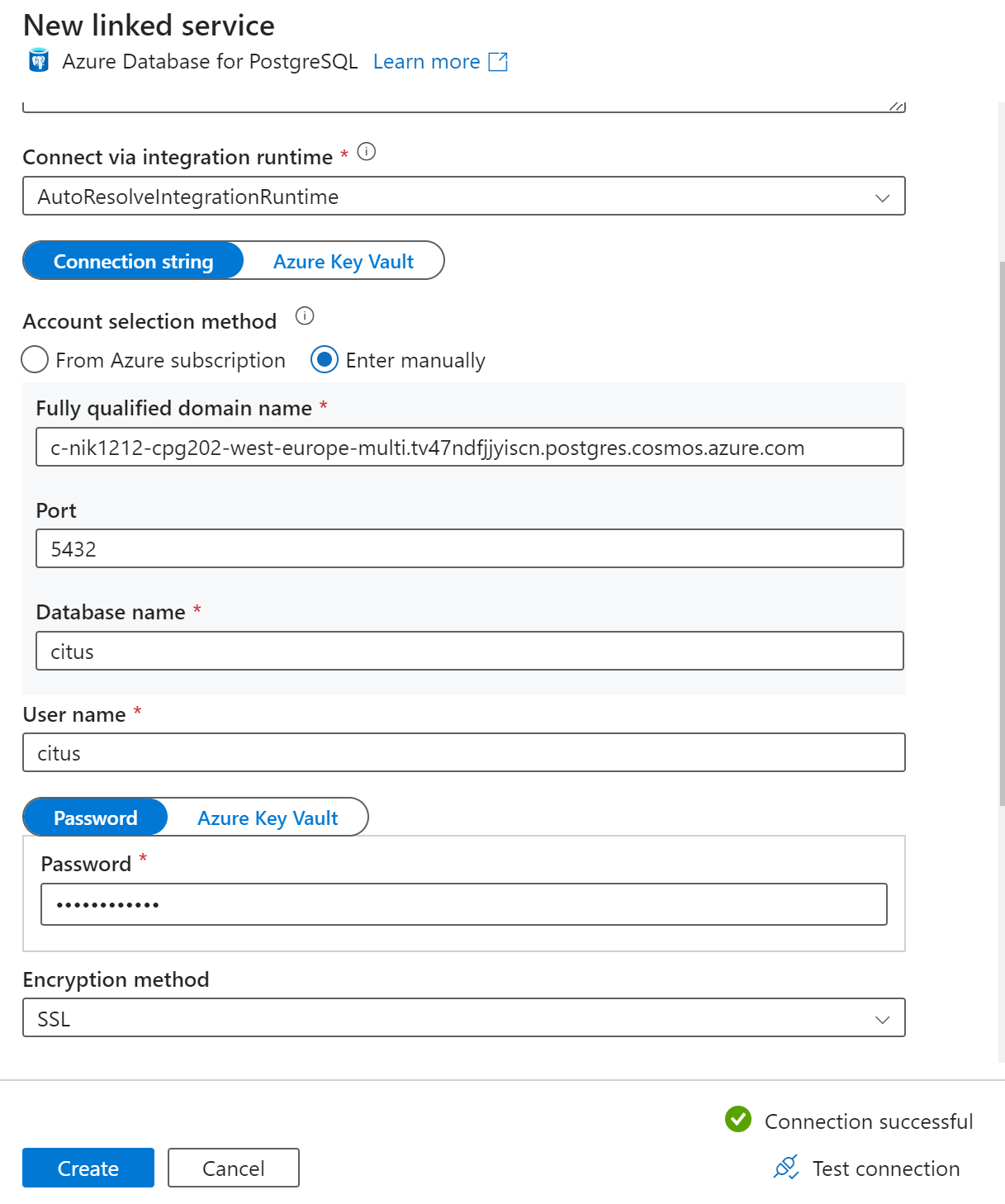
Selecione Testar conexão na parte inferior do painel para validar a configuração do coletor.
Selecione Criar para salvar a configuração.
Na tela Definir propriedades, selecione OK.
Na guia Coletor na página Atividades, selecione Abrir ao lado da lista suspensa Conjunto de dados do coletor e selecione o nome da tabela no cluster de destino onde você deseja ingerir os dados.
Em Método de gravação, selecione Comando Copiar.
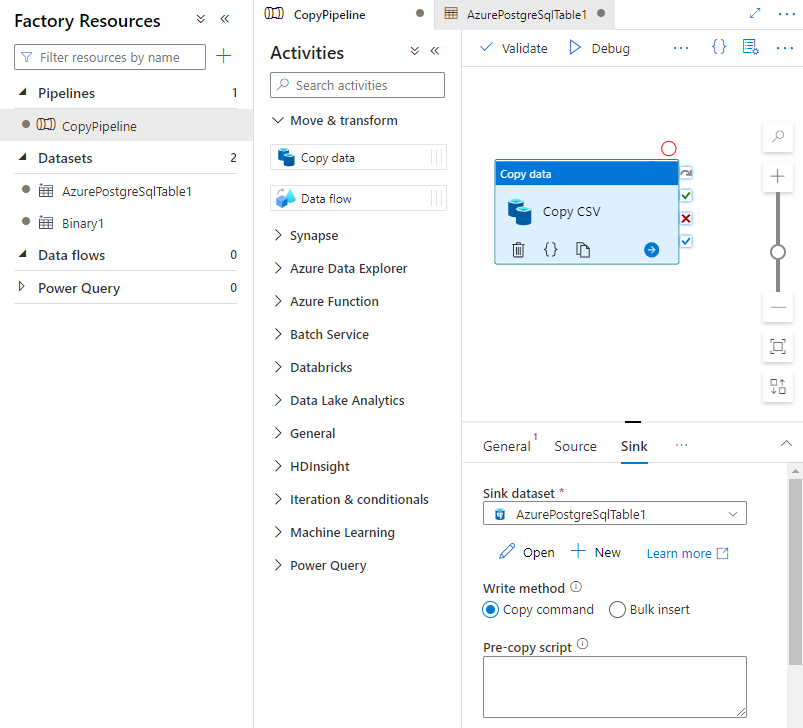
Na barra de ferramentas acima da tela, selecione Validar para validar as configurações do pipeline. Corrija quaisquer erros, revalide e certifique-se de que o pipeline seja validado com êxito.
Selecione Depurar na barra de ferramentas para executar o pipeline.
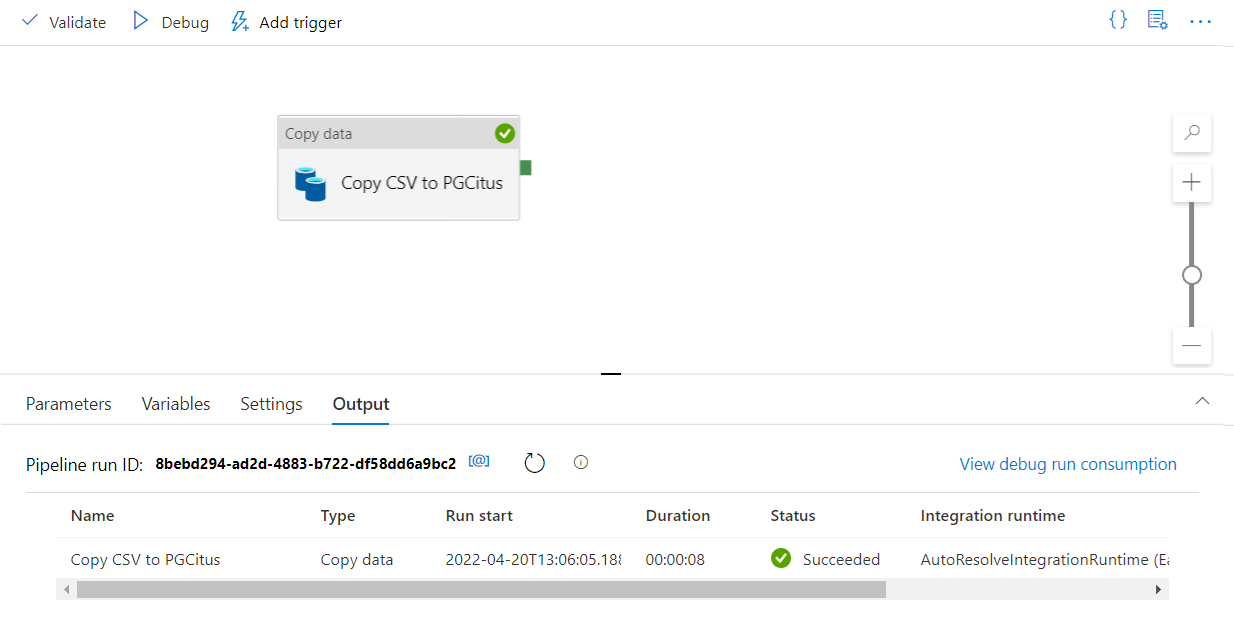
Quando o pipeline puder ser executado com êxito, na barra de ferramentas superior, selecione Publicar tudo. Esta ação publica entidades (conjuntos de dados e pipelines) que você criou no Data Factory.
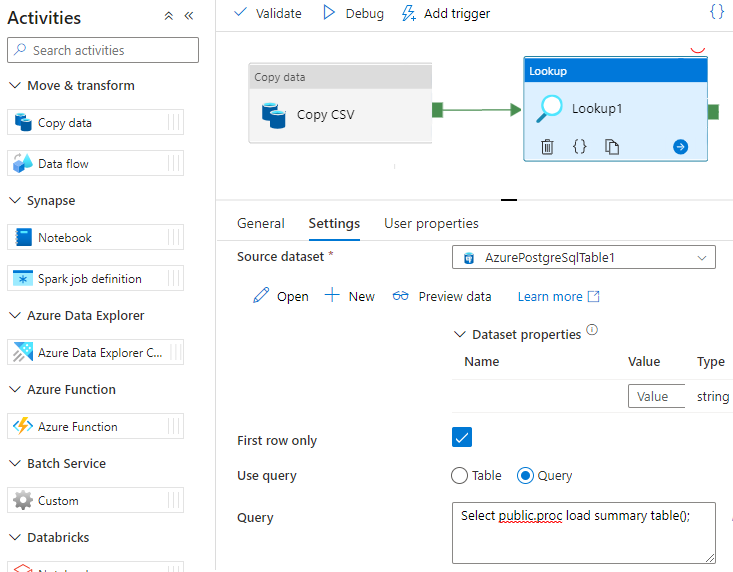
Chamar um procedimento armazenado no Data Factory
Em alguns cenários específicos, talvez você queira chamar um procedimento/função armazenado para enviar dados agregados da tabela de preparo para a tabela de resumo. O Data Factory não oferece uma atividade de procedimento armazenado para o Azure Cosmos DB para PostgreSQL, mas, como solução alternativa, você pode usar a atividade Pesquisa com uma consulta para chamar um procedimento armazenado, conforme mostrado abaixo:
Próximos passos
- Saiba como criar um painel em tempo real com o Azure Cosmos DB para PostgreSQL.
- Saiba como mover sua carga de trabalho para o Azure Cosmos DB para PostgreSQL