Criar uma ligação de dados dos Hubs de Eventos para o Azure Data Explorer
O Azure Data Explorer oferece ingestão dos Hubs de Eventos, uma plataforma de transmissão em fluxo de macrodados e um serviço de ingestão de eventos. Os Hubs de Eventos podem processar milhões de eventos por segundo em tempo quase real.
Neste artigo, vai ligar a um hub de eventos e ingerir dados no Azure Data Explorer. Para obter uma descrição geral sobre como ingerir a partir dos Hubs de Eventos, veja Hubs de Eventos do Azure ligação de dados.
Para saber como criar a ligação com os SDKs do Kusto, veja Criar uma ligação de dados dos Hubs de Eventos com SDKs.
Para exemplos de código baseados em versões anteriores do SDK, veja o artigo arquivado.
Criar uma ligação de dados do hub de eventos
Nesta secção, vai estabelecer uma ligação entre o hub de eventos e a tabela Data Explorer do Azure. Desde que esta ligação esteja implementada, os dados são transmitidos do hub de eventos para a tabela de destino. Se o hub de eventos for movido para um recurso ou subscrição diferente, terá de atualizar ou recriar a ligação.
- Obter dados
- Portal - Página de Data Explorer do Azure
- Portal - Hubs de Eventos do Azure página
- Modelo ARM
Pré-requisitos
- Uma conta Microsoft ou uma identidade de utilizador Microsoft Entra. Não é necessária uma subscrição do Azure.
- Um cluster e uma base de dados do Azure Data Explorer. Criar um cluster e uma base de dados.
- A ingestão de transmissão em fluxo tem de ser configurada no cluster do Azure Data Explorer.
Obter dados
No menu esquerdo, selecione Consulta.
Clique com o botão direito do rato na base de dados onde pretende ingerir os dados. Selecione Obter dados.


Origem
Na janela Obter dados , o separador Origem está selecionado.
Selecione a origem de dados na lista disponível. Neste exemplo, está a ingerir dados dos Hubs de Eventos.

Configurar
Selecione uma base de dados de destino e uma tabela. Se quiser ingerir dados numa nova tabela, selecione + Nova tabela e introduza um nome de tabela.
Nota
Os nomes das tabelas podem ter até 1024 carateres, incluindo espaços, alfanuméricos, hífenes e carateres de sublinhado. Os carateres especiais não são suportados.

Preencha os seguintes campos:
Definição Descrição do campo Subscrição O ID da subscrição onde está localizado o recurso do hub de eventos. Espaço de nomes do hub de eventos O nome que identifica o espaço de nomes. Hub de eventos O hub de eventos que pretende Grupo de consumidores O grupo de consumidores definido no seu evento Nome da ligação de dados O nome que identifica a ligação de dados. Filtros avançados Compressão O tipo de compressão do payload de mensagens do hub de eventos. Propriedades do sistema de eventos As propriedades do sistema do hub de eventos. Se existirem vários registos por mensagem de evento, as propriedades do sistema são adicionadas à primeira. Ao adicionar propriedades do sistema, crie ou atualize o esquema e o mapeamento da tabela para incluir as propriedades selecionadas. Data de início da obtenção de eventos A ligação de dados obtém eventos existentes dos Hubs de Eventos criados após a data de início da obtenção de eventos. Apenas os eventos retidos pelo período de retenção dos Hubs de Eventos podem ser obtidos. Se a data de início da obtenção de eventos não for especificada, a hora predefinida é a hora em que a ligação de dados é criada. Selecione Seguinte

Inspecionar
O separador Inspecionar é aberto com uma pré-visualização dos dados.
Para concluir o processo de ingestão, selecione Concluir.

Opcionalmente:
Se os dados que vê na janela de pré-visualização não estiverem concluídos, poderá precisar de mais dados para criar uma tabela com todos os campos de dados necessários. Utilize os seguintes comandos para obter novos dados do seu hub de eventos:
Eliminar e obter novos dados: elimina os dados apresentados e procura novos eventos.
Obter mais dados: procura mais eventos para além dos eventos já encontrados.
Nota
Para ver uma pré-visualização dos seus dados, o hub de eventos tem de estar a enviar eventos.
Selecione Visualizador de comandos para ver e copiar os comandos automáticos gerados a partir das suas entradas.
Utilize a lista pendente Ficheiro de definição de esquema para alterar o ficheiro a partir do qual o esquema é inferido.
Altere o formato de dados inferidos automaticamente ao selecionar o formato pretendido na lista pendente. Veja Formatos de dados suportados pelo Azure Data Explorer para ingestão.
Editar colunas
Nota
- Para formatos tabulares (CSV, TSV, PSV), não pode mapear uma coluna duas vezes. Para mapear para uma coluna existente, elimine primeiro a nova coluna.
- Não pode alterar um tipo de coluna existente. Se tentar mapear para uma coluna com um formato diferente, poderá acabar com colunas vazias.
As alterações que pode fazer numa tabela dependem dos seguintes parâmetros:
- O tipo de tabela é novo ou existente
- O tipo de mapeamento é novo ou existente
| Tipo de tabela | Tipo de mapeamento | Ajustes disponíveis |
|---|---|---|
| Nova tabela | Novo mapeamento | Mudar o nome da coluna, alterar o tipo de dados, alterar a origem de dados, mapear a transformação, adicionar coluna, eliminar coluna |
| Tabela existente | Novo mapeamento | Adicionar coluna (na qual pode alterar o tipo de dados, mudar o nome e atualizar) |
| Tabela existente | Mapeamento existente | nenhum |

Transformações de mapeamento
Alguns mapeamentos de formato de dados (Parquet, JSON e Avro) suportam transformações simples de tempo de ingestão. Para aplicar transformações de mapeamento, crie ou atualize uma coluna na janela Editar colunas .
As transformações de mapeamento podem ser executadas numa coluna do tipo cadeia ou datetime, com a origem a ter um tipo de dados int ou longo. As transformações de mapeamento suportadas são:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opções avançadas com base no tipo de dados
Tabular (CSV, TSV, PSV):
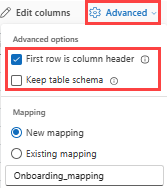
Se estiver a ingerir formatos tabulares numa tabela existente, pode selecionar AdvancedKeep current table schema (Manter o esquema de tabela atual).> Os dados tabulares não incluem necessariamente os nomes de coluna que são utilizados para mapear dados de origem para as colunas existentes. Quando esta opção é selecionada, o mapeamento é feito por encomenda e o esquema da tabela permanece o mesmo. Se esta opção estiver desmarcada, serão criadas novas colunas para dados recebidos, independentemente da estrutura de dados.
Para utilizar a primeira linha como nomes de colunas, selecione Advanced>First row é cabeçalho de coluna.
JSON:
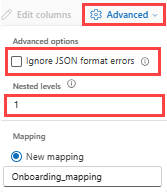
Para determinar a divisão de colunas de dados JSON, selecioneNíveis AninhadosAvançados>, de 1 a 100.
Se selecionarErros de formato de dados Ignorar Avançadas>, os dados são ingeridos no formato JSON. Se deixar esta caixa de verificação desmarcada, os dados são ingeridos no formato multijson.
Resumo
Na janela Preparação de dados , os três passos são marcados com marcas de verificação verdes quando a ingestão de dados é concluída com êxito. Pode ver os comandos que foram utilizados para cada passo ou selecionar um cartão para consultar, visualizar ou remover os dados ingeridos.



Remover uma ligação de dados do hub de eventos
Remova a ligação de dados através do portal do Azure conforme explicado no separador do portal.
Conteúdo relacionado
- Verificar a ligação com a aplicação de mensagens de exemplo do Hub de Eventos
- Consultar dados na IU da Web