Copie dados do Amazon Redshift usando o Azure Data Factory ou o Synapse Analytics
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a atividade de cópia no Azure Data Factory e os pipelines do Synapse Analytics para copiar dados de um Amazon Redshift. Ele se baseia no artigo de visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Capacidades suportadas
Esse conector do Amazon Redshift é compatível com os seguintes recursos:
| Capacidades suportadas | IR |
|---|---|
| Atividade de cópia (fonte/-) | (1) (2) |
| Atividade de Pesquisa | (1) (2) |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Para obter uma lista de armazenamentos de dados suportados como fontes ou coletores pela atividade de cópia, consulte a tabela Armazenamentos de dados suportados.
Especificamente, esse conector do Amazon Redshift oferece suporte à recuperação de dados do Redshift usando consulta ou suporte integrado a UNLOAD do Redshift.
O conector suporta as versões do Windows neste artigo.
Gorjeta
Para obter o melhor desempenho ao copiar grandes quantidades de dados do Redshift, considere usar o UNLOAD do Redshift integrado por meio do Amazon S3. Consulte a seção Usar UNLOAD para copiar dados do Amazon Redshift para obter detalhes.
Pré-requisitos
- Se você estiver copiando dados para um armazenamento de dados local usando o Self-hosted Integration Runtime, conceda ao Integration Runtime (use o endereço IP da máquina) o acesso ao cluster do Amazon Redshift. Consulte Autorizar acesso ao cluster para obter instruções.
- Se você estiver copiando dados para um repositório de dados do Azure, consulte Intervalos de IP do Data Center do Azure para obter o endereço IP de computação e os intervalos SQL usados pelos data centers do Azure.
Introdução
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao Amazon Redshift usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao Amazon Redshift na interface do usuário do portal do Azure.
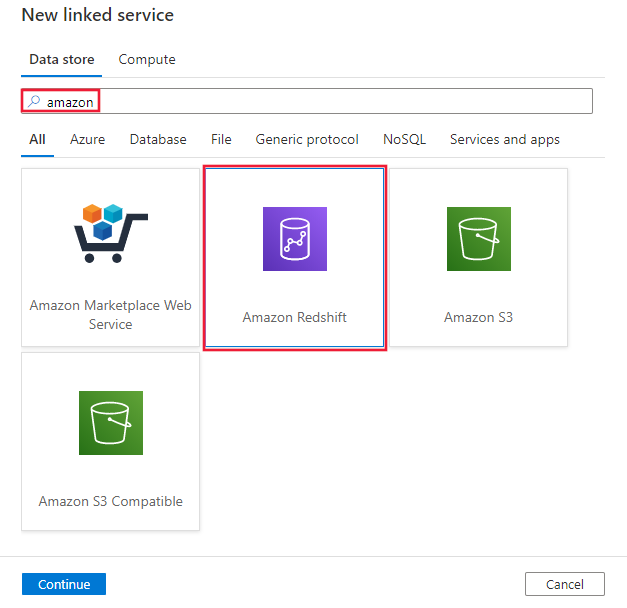
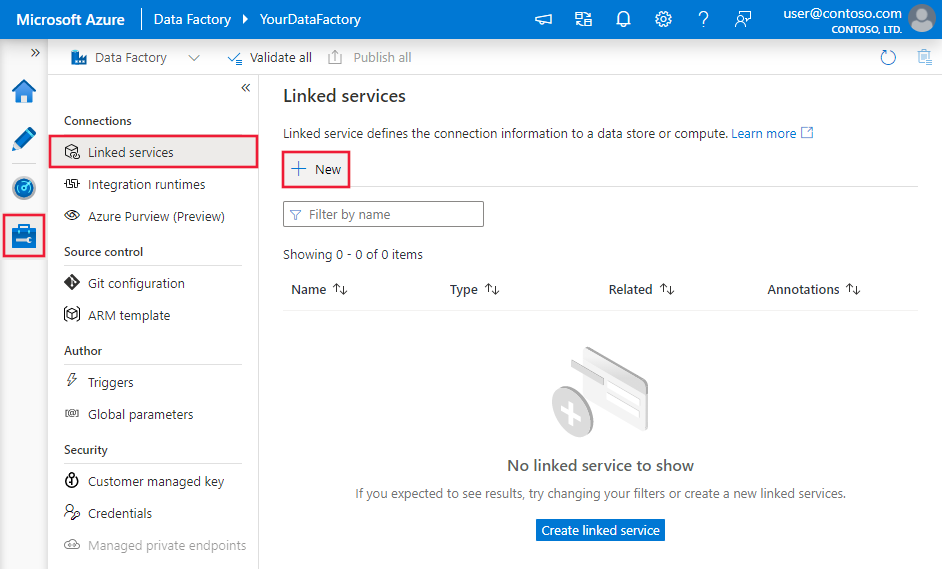
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
Pesquise por Amazon e selecione o conector do Amazon Redshift.
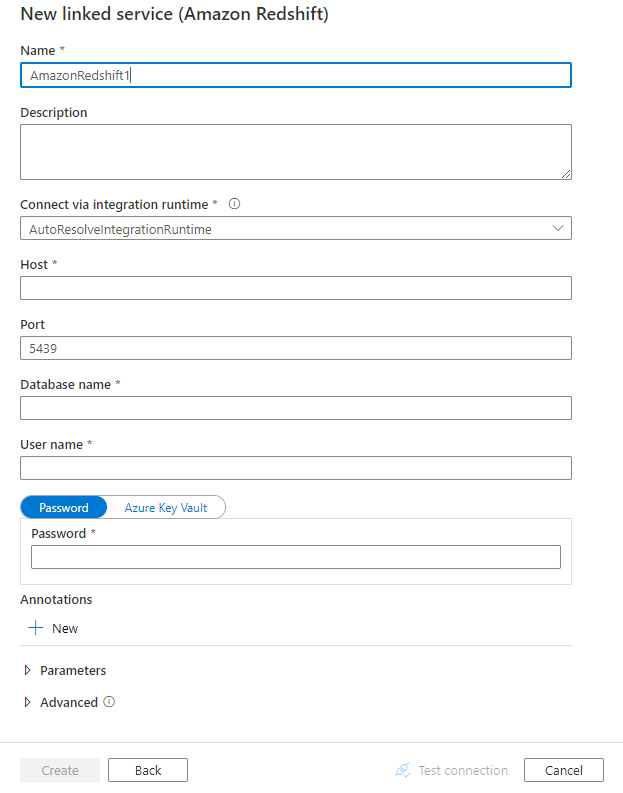
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas para o conector do Amazon Redshift.
Propriedades do serviço vinculado
As seguintes propriedades são compatíveis com o serviço vinculado do Amazon Redshift:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como: AmazonRedshift | Sim |
| servidor | Endereço IP ou nome do host do servidor Amazon Redshift. | Sim |
| porta | O número da porta TCP que o servidor do Amazon Redshift usa para escutar conexões de cliente. | Não, o padrão é 5439 |
| base de dados | Nome do banco de dados do Amazon Redshift. | Sim |
| nome de utilizador | Nome do usuário que tem acesso ao banco de dados. | Sim |
| password | Senha para a conta de usuário. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o Azure Integration Runtime ou o Self-hosted Integration Runtime (se seu armazenamento de dados estiver localizado em rede privada). Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
Exemplo:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo sobre conjuntos de dados. Esta seção fornece uma lista de propriedades compatíveis com o conjunto de dados do Amazon Redshift.
Para copiar dados do Amazon Redshift, as seguintes propriedades são suportadas:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como: AmazonRedshiftTable | Sim |
| esquema | Nome do esquema. | Não (se "consulta" na fonte da atividade for especificado) |
| tabela | Nome da tabela. | Não (se "consulta" na fonte da atividade for especificado) |
| tableName | Nome da tabela com esquema. Esta propriedade é suportada para compatibilidade com versões anteriores. Use schema e table para nova carga de trabalho. |
Não (se "consulta" na fonte da atividade for especificado) |
Exemplo
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
Se você estava usando RelationalTable o conjunto de dados digitado, ele ainda é suportado no estado em que se encontra, enquanto é sugerido que você use o novo no futuro.
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades compatíveis com a origem do Amazon Redshift.
Amazon Redshift como fonte
Para copiar dados do Amazon Redshift, defina o tipo de origem na atividade de cópia como AmazonRedshiftSource. As seguintes propriedades são suportadas na seção de origem da atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como: AmazonRedshiftSource | Sim |
| query | Use a consulta personalizada para ler dados. Por exemplo: selecione * em MyTable. | Não (se "tableName" no conjunto de dados for especificado) |
| redshiftDescarregarConfigurações | Grupo de propriedades ao usar o Amazon Redshift UNLOAD. | Não |
| s3LinkedServiceName | Refere-se a um Amazon S3 a ser usado como um armazenamento provisório especificando um nome de serviço vinculado do tipo "AmazonS3". | Sim se estiver a utilizar UNLOAD |
| bucketName | Indique o bucket do S3 para armazenar os dados provisórios. Se não for prestado, o serviço gera-o automaticamente. | Sim se estiver a utilizar UNLOAD |
Exemplo: origem do Amazon Redshift na atividade de cópia usando UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Saiba mais sobre como usar o UNLOAD para copiar dados do Amazon Redshift de forma eficiente na próxima seção.
Use UNLOAD para copiar dados do Amazon Redshift
O UNLOAD é um mecanismo fornecido pelo Amazon Redshift, que pode descarregar os resultados de uma consulta para um ou mais arquivos no Amazon Simple Storage Service (Amazon S3). É a maneira recomendada pela Amazon para copiar grandes conjuntos de dados do Redshift.
Exemplo: copiar dados do Amazon Redshift para o Azure Synapse Analytics usando UNLOAD, cópia em estágios e PolyBase
Para este exemplo de caso de uso, a atividade de cópia descarrega dados do Amazon Redshift para o Amazon S3 conforme configurado em "redshiftUnloadSettings" e, em seguida, copia dados do Amazon S3 para o Blob do Azure conforme especificado em "stagingSettings", por último, use o PolyBase para carregar dados no Azure Synapse Analytics. Todo o formato provisório é tratado pela atividade de cópia corretamente.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Mapeamento de tipo de dados para Amazon Redshift
Ao copiar dados do Amazon Redshift, os mapeamentos a seguir são usados de tipos de dados do Amazon Redshift para tipos de dados provisórios usados internamente no serviço. Consulte Mapeamentos de esquema e tipo de dados para saber como a atividade de cópia mapeia o esquema de origem e o tipo de dados para o coletor.
| Tipo de dados do Amazon Redshift | Tipo de dados de serviço provisório |
|---|---|
| BIGINT | Int64 |
| BOOLEANO | String |
| CHAR | String |
| DATE | DateTime |
| DECIMAL | Decimal |
| DUPLA PRECISÃO | Duplo |
| INTEIRO | Int32 |
| REAL | Única |
| SMALLINT | Int16 |
| TEXTO | String |
| CARIMBO DE DATA/HORA | DateTime |
| VARCHAR | String |
Propriedades da atividade de pesquisa
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores pela atividade de cópia, consulte Armazenamentos de dados suportados.