Copiar dados do MongoDB usando o Azure Data Factory ou o Synapse Analytics (legado)
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a Atividade de Cópia em um pipeline do Azure Data Factory ou do Synapse Analytics para copiar dados de um banco de dados MongoDB. Ele se baseia no artigo de visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Importante
O serviço lançou um novo conector MongoDB que fornece melhor suporte nativo ao MongoDB em comparação com esta implementação baseada em ODBC, consulte o artigo do conector MongoDB sobre detalhes.
Capacidades suportadas
Você pode copiar dados do banco de dados MongoDB para qualquer armazenamento de dados de coletor suportado. Para obter uma lista de armazenamentos de dados suportados como fontes/coletores pela atividade de cópia, consulte a tabela Armazenamentos de dados suportados.
Especificamente, este conector MongoDB suporta:
- MongoDB versões 2.4, 2.6, 3.0, 3.2, 3.4 e 3.6.
- Cópia de dados usando autenticação básica ou anônima .
Pré-requisitos
Se seu armazenamento de dados estiver localizado dentro de uma rede local, uma rede virtual do Azure ou a Amazon Virtual Private Cloud, você precisará configurar um tempo de execução de integração auto-hospedado para se conectar a ele.
Se o seu armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Tempo de Execução de Integração do Azure. Se o acesso for restrito a IPs aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de tempo de execução de integração de rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um tempo de execução de integração auto-hospedado.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções suportadas pelo Data Factory, consulte Estratégias de acesso a dados.
O Integration Runtime fornece um driver MongoDB integrado, portanto, você não precisa instalar manualmente nenhum driver ao copiar dados do MongoDB.
Introdução
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao MongoDB usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao MongoDB na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
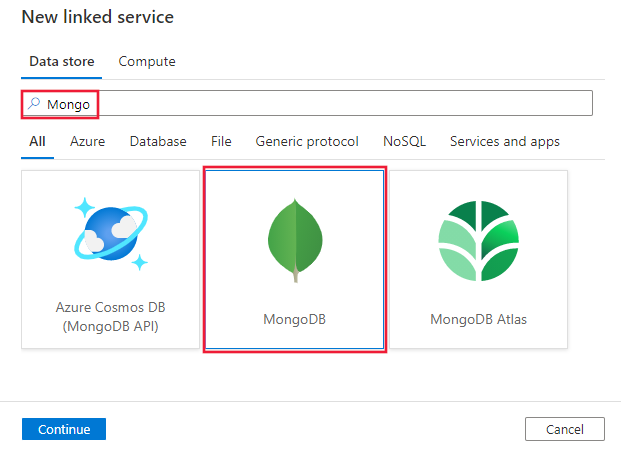
Procure Mongo e selecione o conector MongoDB.
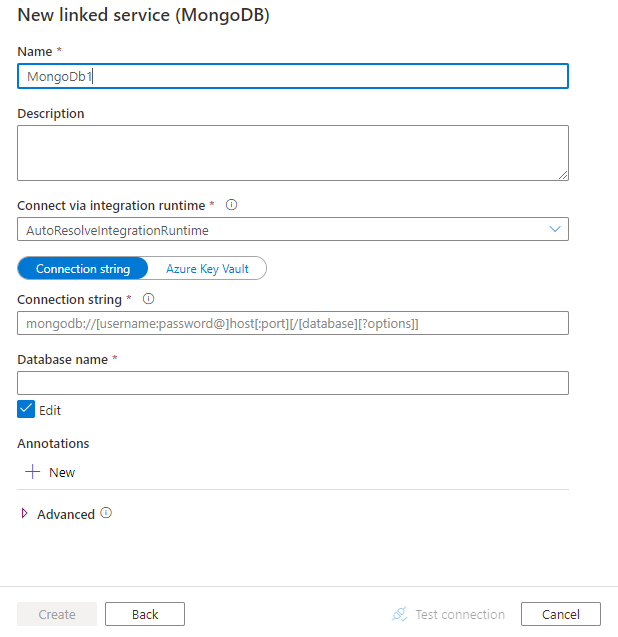
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas para o conector MongoDB.
Propriedades do serviço vinculado
As seguintes propriedades são suportadas para o serviço vinculado MongoDB:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como: MongoDb | Sim |
| servidor | Endereço IP ou nome de host do servidor MongoDB. | Sim |
| porta | Porta TCP que o servidor MongoDB usa para escutar conexões de cliente. | Não (o padrão é 27017) |
| databaseName | Nome do banco de dados MongoDB que você deseja acessar. | Sim |
| authenticationType | Tipo de autenticação usado para se conectar ao banco de dados MongoDB. Os valores permitidos são: Básico e Anônimo. |
Sim |
| nome de utilizador | Conta de usuário para acessar o MongoDB. | Sim (se for utilizada autenticação básica). |
| password | A palavra-passe do utilizador. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Sim (se for utilizada autenticação básica). |
| authSource | Nome do banco de dados MongoDB que você deseja usar para verificar suas credenciais de autenticação. | N.º Para autenticação básica, o padrão é usar a conta de administrador e o banco de dados especificado usando a propriedade databaseName. |
| habilitarSsl | Especifica se as conexões com o servidor são criptografadas usando TLS. O valor predefinido é false. | Não |
| allowSelfSignedServerCert | Especifica se os certificados autoassinados do servidor devem ser permitidos. O valor predefinido é false. | Não |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos . Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
Exemplo:
{
"name": "MongoDBLinkedService",
"properties": {
"type": "MongoDb",
"typeProperties": {
"server": "<server name>",
"databaseName": "<database name>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte Conjuntos de dados e serviços vinculados. As seguintes propriedades são suportadas para o conjunto de dados MongoDB:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como: MongoDbCollection | Sim |
| collectionName | Nome da coleção no banco de dados MongoDB. | Sim |
Exemplo:
{
"name": "MongoDbDataset",
"properties": {
"type": "MongoDbCollection",
"linkedServiceName": {
"referenceName": "<MongoDB linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"collectionName": "<Collection name>"
}
}
}
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades suportadas pela fonte do MongoDB.
MongoDB como fonte
As seguintes propriedades são suportadas na seção de origem da atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como: MongoDbSource | Sim |
| query | Use a consulta SQL-92 personalizada para ler dados. Por exemplo: selecione * em MyTable. | Não (se "collectionName" no conjunto de dados for especificado) |
Exemplo:
"activities":[
{
"name": "CopyFromMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<MongoDB input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "MongoDbSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Gorjeta
Ao especificar a consulta SQL, preste atenção ao formato DateTime. Por exemplo: SELECT * FROM Account WHERE LastModifiedDate >= '2018-06-01' AND LastModifiedDate < '2018-06-02' ou para usar parâmetro SELECT * FROM Account WHERE LastModifiedDate >= '@{formatDateTime(pipeline().parameters.StartTime,'yyyy-MM-dd HH:mm:ss')}' AND LastModifiedDate < '@{formatDateTime(pipeline().parameters.EndTime,'yyyy-MM-dd HH:mm:ss')}'
Esquema por Data Factory
O serviço Azure Data Factory infere o esquema de uma coleção MongoDB usando os 100 documentos mais recentes da coleção. Se esses 100 documentos não contiverem o esquema completo, algumas colunas podem ser ignoradas durante a operação de cópia.
Mapeamento de tipo de dados para MongoDB
Ao copiar dados do MongoDB, os mapeamentos a seguir são usados de tipos de dados do MongoDB para tipos de dados provisórios usados internamente no serviço. Consulte Mapeamentos de esquema e tipo de dados para saber como a atividade de cópia mapeia o esquema de origem e o tipo de dados para o coletor.
| Tipo de dados MongoDB | Tipo de dados de serviço provisório |
|---|---|
| Binário | Byte[] |
| Boolean | Boolean |
| Date | DateTime |
| NúmeroDuplo | Duplo |
| NúmeroInt | Int32 |
| NúmeroLong | Int64 |
| ObjectID | String |
| String | String |
| UUID | GUID |
| Object | Renormalizado em colunas planas com "_" como separador aninhado |
Nota
Para saber mais sobre o suporte para matrizes usando tabelas virtuais, consulte a seção Suporte para tipos complexos usando tabelas virtuais.
Atualmente, os seguintes tipos de dados MongoDB não são suportados: DBPointer, JavaScript, tecla Max/Min, Expressão Regular, Símbolo, Carimbo de data/hora, Indefinido.
Suporte para tipos complexos usando tabelas virtuais
O serviço usa um driver ODBC integrado para se conectar e copiar dados do seu banco de dados MongoDB. Para tipos complexos, como matrizes ou objetos com tipos diferentes nos documentos, o driver renormaliza os dados em tabelas virtuais correspondentes. Especificamente, se uma tabela contiver essas colunas, o driver gerará as seguintes tabelas virtuais:
- Uma tabela base, que contém os mesmos dados que a tabela real, exceto para as colunas de tipo complexo. A tabela base usa o mesmo nome que a tabela real que ela representa.
- Uma tabela virtual para cada coluna de tipo complexo, que expande os dados aninhados. As tabelas virtuais são nomeadas usando o nome da tabela real, um separador "_" e o nome da matriz ou objeto.
As tabelas virtuais referem-se aos dados na tabela real, permitindo que o driver acesse os dados desnormalizados. Você pode acessar o conteúdo das matrizes MongoDB consultando e unindo as tabelas virtuais.
Exemplo
Por exemplo, ExampleTable aqui é uma tabela MongoDB que tem uma coluna com uma matriz de Objetos em cada célula - Faturas e uma coluna com uma matriz de tipos escalares - Classificações.
| _id | Nome do Cliente | Faturas | Nível de Serviço | Classificações |
|---|---|---|---|---|
| 1111 | ABC | [{invoice_id:"123", item:"torradeira", preço:"456", desconto:"0.2"}, {invoice_id:"124", item:"forno", preço: "1235", desconto: "0.2"}] | Silver | [5,6] |
| 2222 | XYZ | [{invoice_id:"135", item:"frigorífico", preço: "12543", desconto: "0.0"}] | Gold | [1,2] |
O driver geraria várias tabelas virtuais para representar essa única tabela. A primeira tabela virtual é a tabela base chamada "ExampleTable", mostrada no exemplo. A tabela base contém todos os dados da tabela original, mas os dados das matrizes foram omitidos e são expandidos nas tabelas virtuais.
| _id | Nome do Cliente | Nível de Serviço |
|---|---|---|
| 1111 | ABC | Silver |
| 2222 | XYZ | Gold |
As tabelas a seguir mostram as tabelas virtuais que representam as matrizes originais no exemplo. Estas tabelas contêm o seguinte:
- Uma referência à coluna de chave primária original correspondente à linha da matriz original (através da coluna _id)
- Uma indicação da posição dos dados dentro da matriz original
- Os dados expandidos para cada elemento dentro da matriz
Tabela "ExampleTable_Invoices":
| _id | ExampleTable_Invoices_dim1_idx | invoice_id | item | preço | Discount |
|---|---|---|---|---|---|
| 1111 | 0 | 123 | torradeira | 456 | 0.2 |
| 1111 | 1 | 124 | forno | 1235 | 0.2 |
| 2222 | 0 | 135 | frigorífico | 12543 | 0.0 |
Quadro "ExampleTable_Ratings":
| _id | ExampleTable_Ratings_dim1_idx | ExampleTable_Ratings |
|---|---|---|
| 1111 | 0 | 5 |
| 1111 | 1 | 6 |
| 2222 | 0 | 1 |
| 2222 | 1 | 2 |
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores pela atividade de cópia, consulte Armazenamentos de dados suportados.