Copiar dados do SAP HANA usando o Azure Data Factory ou o Synapse Analytics
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a Atividade de Cópia no Azure Data Factory e os pipelines do Synapse Analytics para copiar dados de um banco de dados SAP HANA. Ele se baseia no artigo de visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Gorjeta
Para saber mais sobre o suporte geral para o cenário de integração de dados SAP, consulte o whitepaper de integração de dados SAP com introdução detalhada sobre cada conector, comparação e orientação SAP.
Capacidades suportadas
Este conector SAP HANA é suportado para os seguintes recursos:
| Capacidades suportadas | IR |
|---|---|
| Atividade de cópia (origem/coletor) | (2) |
| Atividade de Pesquisa | (2) |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Para obter uma lista de armazenamentos de dados suportados como fontes/coletores pela atividade de cópia, consulte a tabela Armazenamentos de dados suportados.
Especificamente, este conector SAP HANA suporta:
- Cópia de dados de qualquer versão do banco de dados SAP HANA.
- Copiar dados de modelos de informação HANA (como vistas Analítica e de Cálculo) e tabelas de Linha/Coluna.
- Copiar dados usando autenticação básica ou do Windows .
- Cópia paralela de uma fonte SAP HANA. Consulte a seção Cópia paralela do SAP HANA para obter detalhes.
Gorjeta
Para copiar dados para o armazenamento de dados do SAP HANA, use o conector ODBC genérico. Consulte a seção do coletor do SAP HANA com detalhes. Observe que os serviços vinculados para o conector SAP HANA e o conector ODBC são de tipo diferente, portanto, não podem ser reutilizados.
Pré-requisitos
Para usar esse conector SAP HANA, você precisa:
- Configure um tempo de execução de integração auto-hospedado. Consulte o artigo Self-hosted Integration Runtime para obter detalhes.
- Instale o driver SAP HANA ODBC na máquina Integration Runtime. Você pode baixar o driver SAP HANA ODBC do Centro de Download de Software SAP. Pesquise com a palavra-chave SAP HANA CLIENT para Windows.
Introdução
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao SAP HANA usando a interface do usuário
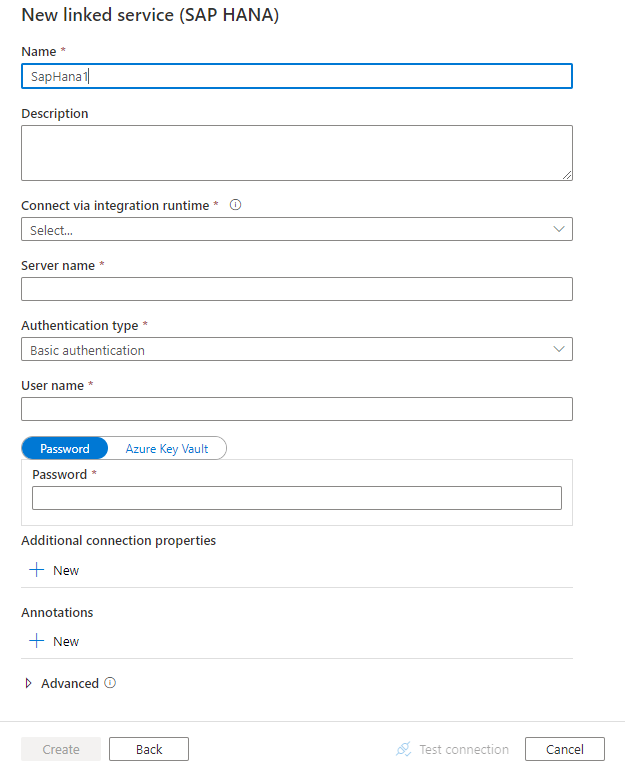
Use as etapas a seguir para criar um serviço vinculado ao SAP HANA na interface do usuário do portal do Azure.
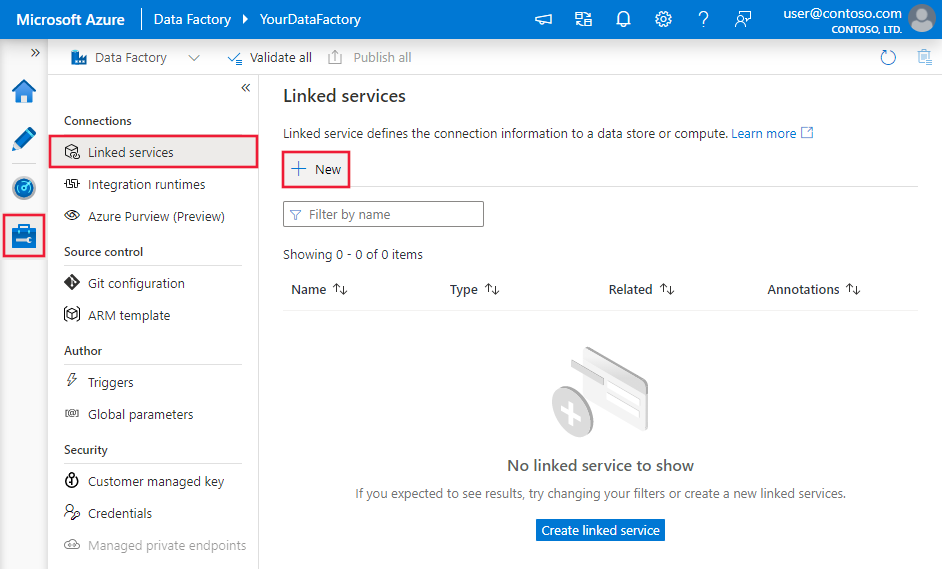
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
Procure SAP e selecione o conector SAP HANA.

Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas para o conector SAP HANA.
Propriedades do serviço vinculado
As seguintes propriedades são suportadas para o serviço vinculado SAP HANA:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como: SapHana | Sim |
| connectionString | Especifique as informações necessárias para se conectar ao SAP HANA usando a autenticação básica ou a autenticação do Windows. Consulte os exemplos a seguir. Na cadeia de conexão, servidor/porta é obrigatório (porta padrão é 30015) e nome de usuário e senha são obrigatórios ao usar a autenticação básica. Para obter configurações avançadas adicionais, consulte Propriedades de conexão SAP HANA ODBC Você também pode colocar senha no Cofre de Chaves do Azure e extrair a configuração de senha da cadeia de conexão. Consulte o artigo Armazenar credenciais no Cofre da Chave do Azure com mais detalhes. |
Sim |
| nome de utilizador | Especifique o nome de usuário ao usar a autenticação do Windows. Exemplo: user@domain.com |
Não |
| password | Especifique a senha para a conta de usuário. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Não |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Um tempo de execução de integração auto-hospedado é necessário, conforme mencionado em Pré-requisitos. | Sim |
Exemplo: usar autenticação básica
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;UID=<userName>;PWD=<Password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: usar a autenticação do Windows
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"connectionString": "SERVERNODE=<server>:<port (optional)>;",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Se você estava usando o serviço vinculado SAP HANA com a seguinte carga útil, ele ainda é suportado no estado em que se encontra, enquanto é sugerido que você use o novo no futuro.
Exemplo:
{
"name": "SapHanaLinkedService",
"properties": {
"type": "SapHana",
"typeProperties": {
"server": "<server>:<port (optional)>",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo sobre conjuntos de dados. Esta seção fornece uma lista de propriedades suportadas pelo conjunto de dados do SAP HANA.
Para copiar dados do SAP HANA, há suporte para as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como: SapHanaTable | Sim |
| esquema | Nome do esquema no banco de dados SAP HANA. | Não (se "consulta" na fonte da atividade for especificado) |
| tabela | Nome da tabela no banco de dados SAP HANA. | Não (se "consulta" na fonte da atividade for especificado) |
Exemplo:
{
"name": "SAPHANADataset",
"properties": {
"type": "SapHanaTable",
"typeProperties": {
"schema": "<schema name>",
"table": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<SAP HANA linked service name>",
"type": "LinkedServiceReference"
}
}
}
Se você estava usando RelationalTable o conjunto de dados digitado, ele ainda é suportado no estado em que se encontra, enquanto é sugerido que você use o novo no futuro.
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades suportadas pela origem do SAP HANA.
SAP HANA como fonte
Gorjeta
Para ingerir dados do SAP HANA de forma eficiente usando o particionamento de dados, saiba mais na seção Cópia paralela do SAP HANA .
Para copiar dados do SAP HANA, as seguintes propriedades são suportadas na seção de origem da atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como: SapHanaSource | Sim |
| query | Especifica a consulta SQL para ler dados da instância do SAP HANA. | Sim |
| partitionOptions | Especifica as opções de particionamento de dados usadas para ingerir dados do SAP HANA. Saiba mais na seção Cópia paralela do SAP HANA . Os valores permitidos são: Nenhum (padrão), PhysicalPartitionsOfTable, SapHanaDynamicRange. Saiba mais na seção Cópia paralela do SAP HANA . PhysicalPartitionsOfTable só pode ser usado ao copiar dados de uma tabela, mas não ao consultar. Quando uma opção de partição é ativada (ou seja, não None), o grau de paralelismo para carregar simultaneamente dados do SAP HANA é controlado pela parallelCopies configuração na atividade de cópia. |
Falso |
| partitionSettings | Especifique o grupo de configurações para particionamento de dados. Aplicar quando a opção de partição for SapHanaDynamicRange. |
Falso |
| partitionColumnName | Especifique o nome da coluna de origem que será usada pela partição para cópia paralela. Se não for especificado, o índice ou a chave primária da tabela será detetado automaticamente e usado como a coluna de partição. Aplique quando a opção de partição for SapHanaDynamicRange. Se você usar uma consulta para recuperar os dados de origem, conecte ?AdfHanaDynamicRangePartitionCondition na cláusula WHERE. Veja o exemplo na seção Cópia paralela do SAP HANA . |
Sim ao usar SapHanaDynamicRange partição. |
| packetSize | Especifica o tamanho do pacote de rede (em kilobytes) para dividir dados em vários blocos. Se você tiver uma grande quantidade de dados para copiar, aumentar o tamanho do pacote pode aumentar a velocidade de leitura do SAP HANA na maioria dos casos. O teste de desempenho é recomendado ao ajustar o tamanho do pacote. | N.º O valor padrão é 2048 (2MB). |
Exemplo:
"activities":[
{
"name": "CopyFromSAPHANA",
"type": "Copy",
"inputs": [
{
"referenceName": "<SAP HANA input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SapHanaSource",
"query": "<SQL query for SAP HANA>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Se você estava usando RelationalSource a fonte de cópia digitada, ela ainda é suportada no estado em que se encontra, enquanto você é sugerido para usar a nova no futuro.
Cópia paralela do SAP HANA
O conector SAP HANA fornece particionamento de dados integrado para copiar dados do SAP HANA em paralelo. Você pode encontrar opções de particionamento de dados na tabela Origem da atividade de cópia.
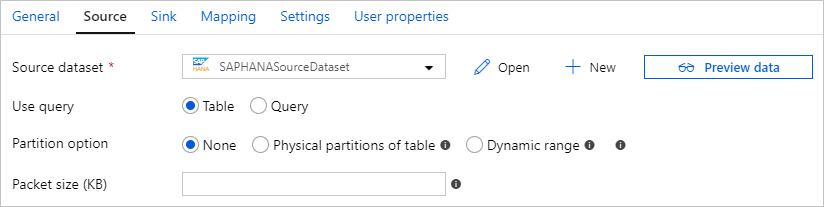
Quando você habilita a cópia particionada, o serviço executa consultas paralelas na origem do SAP HANA para recuperar dados por partições. O grau paralelo é controlado pela parallelCopies configuração na atividade de cópia. Por exemplo, se você definir parallelCopies como quatro, o serviço gerará e executará simultaneamente quatro consultas com base na opção e nas configurações de partição especificadas, e cada consulta recuperará uma parte dos dados do SAP HANA.
Sugere-se que você habilite a cópia paralela com particionamento de dados, especialmente quando ingere uma grande quantidade de dados do seu SAP HANA. A seguir estão sugeridas configurações para diferentes cenários. Ao copiar dados para o armazenamento de dados baseado em arquivo, é recomendável gravar em uma pasta como vários arquivos (especifique apenas o nome da pasta), caso em que o desempenho é melhor do que gravar em um único arquivo.
| Cenário | Configurações sugeridas |
|---|---|
| Carga completa a partir de uma mesa grande. | Opção de partição: Partições físicas da tabela. Durante a execução, o serviço deteta automaticamente o tipo de partição física da tabela SAP HANA especificada e escolhe a estratégia de partição correspondente: - Particionamento de intervalo: obtenha a coluna de partição e os intervalos de partição definidos para a tabela e, em seguida, copie os dados por intervalo. - Particionamento de hash: Use a chave de partição hash como coluna de partição e, em seguida, particione e copie os dados com base em intervalos calculados pelo serviço. - Particionamento Round-Robin ou Sem Partição: Use a chave primária como coluna de partição e, em seguida, particione e copie os dados com base nos intervalos calculados pelo serviço. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada. | Opção de partição: Partição de intervalo dinâmico. Consulta: SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>.Coluna de partição: especifique a coluna usada para aplicar a partição de intervalo dinâmico. Durante a execução, o serviço primeiro calcula os intervalos de valores da coluna de partição especificada, distribuindo uniformemente as linhas em um número de buckets de acordo com o número de valores distintos de coluna de partição da configuração de cópia paralela, em seguida, substitui ?AdfHanaDynamicRangePartitionCondition pela filtragem do intervalo de valores da coluna de partição para cada partição e envia para o SAP HANA.Se quiser usar várias colunas como coluna de partição, você pode concatenar os valores de cada coluna como uma coluna na consulta e especificá-la como a coluna de partição, como SELECT * FROM (SELECT *, CONCAT(<KeyColumn1>, <KeyColumn2>) AS PARTITIONCOLUMN FROM <TABLENAME>) WHERE ?AdfHanaDynamicRangePartitionCondition. |
Exemplo: consulta com partições físicas de uma tabela
"source": {
"type": "SapHanaSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exemplo: consulta com partição de intervalo dinâmico
"source": {
"type": "SapHanaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHanaDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "SapHanaDynamicRange",
"partitionSettings": {
"partitionColumnName": "<Partition_column_name>"
}
}
Mapeamento de tipo de dados para SAP HANA
Ao copiar dados do SAP HANA, os mapeamentos a seguir são usados de tipos de dados do SAP HANA para tipos de dados provisórios usados internamente no serviço. Consulte Mapeamentos de esquema e tipo de dados para saber como a atividade de cópia mapeia o esquema de origem e o tipo de dados para o coletor.
| Tipo de dados SAP HANA | Tipo de dados de serviço provisório |
|---|---|
| ALFANUM | String |
| BIGINT | Int64 |
| BINÁRIO | Byte[] |
| BINTEXT | String |
| BLOB | Byte[] |
| BOOL | Byte |
| CLOB | String |
| DATE | DateTime |
| DECIMAL | Decimal |
| DUPLO | Duplo |
| FLUTUAR | Duplo |
| INTEIRO | Int32 |
| NCLOB | String |
| NVARCHAR | String |
| REAL | Única |
| SEGUNDA DATA | DateTime |
| TEXTO CURTO | String |
| PEQUENODECIMAL | Decimal |
| SMALLINT | Int16 |
| STGEOMETRYTYPE | Byte[] |
| STPOINTTYPE | Byte[] |
| TEXTO | String |
| TIME | TimeSpan |
| TINYINT | Byte |
| VARCHAR | String |
| CARIMBO DE DATA/HORA | DateTime |
| VARBINARY | Byte[] |
Dissipador SAP HANA
Atualmente, o conector SAP HANA não é suportado como coletor, enquanto você pode usar o conector ODBC genérico com o driver SAP HANA para gravar dados no SAP HANA.
Siga os pré-requisitos para configurar o Self-hosted Integration Runtime e instale primeiro o driver SAP HANA ODBC. Crie um serviço vinculado ODBC para se conectar ao armazenamento de dados do SAP HANA, conforme mostrado no exemplo a seguir, crie um conjunto de dados e copie o coletor de atividades com o tipo ODBC de acordo. Saiba mais no artigo do conector ODBC.
{
"name": "SAPHANAViaODBCLinkedService",
"properties": {
"type": "Odbc",
"typeProperties": {
"connectionString": "Driver={HDBODBC};servernode=<HANA server>.clouddatahub-int.net:30015",
"authenticationType": "Basic",
"userName": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades da atividade de pesquisa
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores pela atividade de cópia, consulte Armazenamentos de dados suportados.