Integração e entrega contínuas no Azure Data Factory
APLICA-SE A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
A integração contínua é a prática de testar cada alteração feita na sua base de código automaticamente e o mais cedo possível. A entrega contínua segue os testes que ocorrem durante a integração contínua e emite as alterações para um sistema de teste ou de produção.
No Azure Data Factory, a integração contínua e entrega contínua (CI/CD) significa mover pipelines do Data Factory de um ambiente (desenvolvimento, teste, produção) para outro. O Azure Data Factory utiliza modelos do Azure Resource Manager para armazenar a configuração de suas várias entidades do ADF (pipelines, conjuntos de dados, fluxos de dados e assim por diante). Há dois métodos sugeridos para promover uma fábrica de dados para outro ambiente:
- Implantação automatizada usando a integração do Data Factory com o Azure Pipelines
- Carregue manualmente um modelo do Resource Manager usando a integração do Data Factory UX com o Azure Resource Manager.
Nota
Recomendamos que utilize o módulo Azure Az do PowerShell para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo do Az PowerShell, veja Migrar o Azure PowerShell do AzureRM para o Az.
Ciclo de vida do CI/CD
Nota
Para obter mais informações, consulte Melhorias contínuas na implantação.
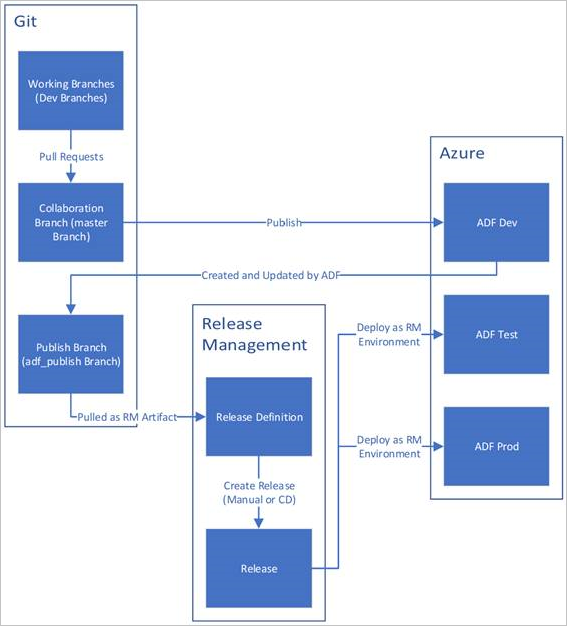
Abaixo está um exemplo de visão geral do ciclo de vida de CI/CD em uma fábrica de dados do Azure configurada com o Azure Repos Git. Para obter mais informações sobre como configurar um repositório Git, consulte Controle de origem no Azure Data Factory.
Uma fábrica de dados de desenvolvimento é criada e configurada com o Azure Repos Git. Todos os desenvolvedores devem ter permissão para criar recursos do Data Factory, como pipelines e conjuntos de dados.
Um desenvolvedor cria uma ramificação de recurso para fazer uma alteração. Eles depuram suas execuções de pipeline com suas alterações mais recentes. Para obter mais informações sobre como depurar uma execução de pipeline, consulte Desenvolvimento iterativo e depuração com o Azure Data Factory.
Depois que um desenvolvedor está satisfeito com suas alterações, ele cria uma solicitação pull de sua ramificação de recurso para a ramificação principal ou de colaboração para que suas alterações sejam revisadas por pares.
Depois que uma solicitação pull é aprovada e as alterações são mescladas na ramificação principal, as alterações são publicadas na fábrica de desenvolvimento.
Quando a equipe estiver pronta para implantar as alterações em uma fábrica de teste ou UAT (Teste de Aceitação do Usuário), a equipe vai para a versão do Azure Pipelines e implanta a versão desejada da fábrica de desenvolvimento no UAT. Essa implantação ocorre como parte de uma tarefa do Azure Pipelines e usa parâmetros de modelo do Gerenciador de Recursos para aplicar a configuração apropriada.
Depois que as alterações tiverem sido verificadas na fábrica de teste, implante na fábrica de produção usando a próxima tarefa da liberação de pipelines.
Nota
Apenas a fábrica de desenvolvimento está associada a um repositório git. As fábricas de teste e produção não devem ter um repositório git associado a elas e só devem ser atualizadas por meio de um pipeline do Azure DevOps ou por meio de um modelo de Gerenciamento de Recursos.
A imagem abaixo destaca as diferentes etapas deste ciclo de vida.
Melhores práticas para CI/CD
Se você estiver usando a integração do Git com sua fábrica de dados e tiver um pipeline de CI/CD que mova suas alterações do desenvolvimento para o teste e, em seguida, para a produção, recomendamos estas práticas recomendadas:
Integração com Git. Configure apenas o seu data factory de desenvolvimento com integração Git. As alterações no teste e na produção são implantadas via CI/CD e não precisam de integração com o Git.
Script pré e pós-implantação. Antes da etapa de implantação do Gerenciador de Recursos em CI/CD, você precisa concluir determinadas tarefas, como parar e reiniciar gatilhos e executar limpeza. Recomendamos que você use scripts do PowerShell antes e depois da tarefa de implantação. Para obter mais informações, consulte Atualizar gatilhos ativos. A equipe da fábrica de dados forneceu um script para usar localizado na parte inferior desta página.
Nota
Use o PrePostDeploymentScript.Ver2.ps1 se quiser desativar/ativar apenas os gatilhos que foram modificados em vez de desativar todos os gatilhos durante o CI/CD.
Aviso
Certifique-se de usar o PowerShell Core na tarefa ADO para executar o script.
Aviso
Se você não usar as versões mais recentes do PowerShell e do módulo Data Factory, poderá encontrar erros de desserialização ao executar os comandos.
Tempo de execução e compartilhamento de integração. Os tempos de execução de integração não mudam com frequência e são semelhantes em todos os estágios do seu CI/CD. Portanto, o Data Factory espera que você tenha o mesmo nome, tipo e subtipo de tempo de execução de integração em todos os estágios de CI/CD. Se você quiser compartilhar tempos de execução de integração em todos os estágios, considere usar uma fábrica ternária apenas para conter os tempos de execução de integração compartilhados. Você pode usar essa fábrica compartilhada em todos os seus ambientes como um tipo de tempo de execução de integração vinculado.
Nota
O compartilhamento de tempo de execução de integração só está disponível para tempos de execução de integração auto-hospedados. Os tempos de execução de integração do Azure-SSIS não oferecem suporte ao compartilhamento.
Implantação de ponto final privado gerenciado. Se já existir um ponto de extremidade privado em uma fábrica e você tentar implantar um modelo ARM que contenha um ponto de extremidade privado com o mesmo nome, mas com propriedades modificadas, a implantação falhará. Por outras palavras, pode implementar com êxito um ponto final privado, desde que tenha as mesmas propriedades do que o que já existe na fábrica. Se alguma propriedade for diferente entre ambientes, poderá substituí-la ao parametrizar essa propriedade e ao indicar o respetivo valor durante a implementação.
Cofre da chave. Quando você usa serviços vinculados cujas informações de conexão são armazenadas no Cofre de Chaves do Azure, é recomendável manter cofres de chaves separados para ambientes diferentes. Você também pode configurar níveis de permissão separados para cada cofre de chaves. Por exemplo, talvez você não queira que os membros da sua equipe tenham permissões para segredos de produção. Se você seguir essa abordagem, recomendamos que mantenha os mesmos nomes secretos em todos os estágios. Se você mantiver os mesmos nomes secretos, não precisará parametrizar cada cadeia de conexão em ambientes de CI/CD porque a única coisa que muda é o nome do cofre de chaves, que é um parâmetro separado.
Nomenclatura de recursos. Devido a restrições de modelo ARM, problemas na implantação podem surgir se seus recursos contiverem espaços no nome. A equipe do Azure Data Factory recomenda o uso de caracteres '_' ou '-' em vez de espaços para recursos. Por exemplo, «Pipeline_1» seria um nome preferível a «Pipeline 1».
Alteração do repositório. O ADF gerencia o conteúdo do repositório GIT automaticamente. Alterar ou adicionar manualmente arquivos ou pastas não relacionados em qualquer lugar na pasta de dados do repositório Git do ADF pode causar erros de carregamento de recursos. Por exemplo, a presença de arquivos .bak pode causar erro ADF CI/CD, portanto, eles devem ser removidos para que o ADF seja carregado.
Controle de exposição e sinalizadores de recursos. Ao trabalhar em equipe, há instâncias em que você pode mesclar alterações, mas não quer que elas sejam executadas em ambientes elevados, como PROD e QA. Para lidar com esse cenário, a equipe do ADF recomenda o conceito de DevOps de usar sinalizadores de recursos. No ADF, você pode combinar parâmetros globais e a atividade de condição if para ocultar conjuntos de lógica com base nesses sinalizadores de ambiente.
Para saber como configurar um sinalizador de recurso, consulte o tutorial em vídeo abaixo:
Funcionalidades não suportadas
Por design, o Data Factory não permite a seleção seletiva de confirmações ou a publicação seletiva de recursos. As publicações incluirão todas as alterações feitas no data factory.
- As entidades do data factory dependem umas das outras. Por exemplo, os gatilhos dependem de pipelines e os pipelines dependem de conjuntos de dados e outros pipelines. A publicação seletiva de um subconjunto de recursos pode levar a comportamentos e erros inesperados.
- Em raras ocasiões em que você precisa de publicação seletiva, considere usar um hotfix. Para obter mais informações, consulte Ambiente de produção de hotfix.
A equipe do Azure Data Factory não recomenda atribuir controles RBAC do Azure a entidades individuais (pipelines, conjuntos de dados, etc.) em uma fábrica de dados. Por exemplo, se um programador tiver acesso a um pipeline ou um conjunto de dados, deverá conseguir aceder a todos os pipelines ou conjuntos de dados na fábrica de dados. Se você achar que precisa implementar muitas funções do Azure em um data factory, examine a implantação de um segundo data factory.
Não pode publicar a partir de ramos privados.
Atualmente, não é possível hospedar projetos no Bitbucket.
Atualmente, não é possível exportar e importar alertas e matrizes como parâmetros.
Os modelos ARM parciais em sua ramificação de publicação não são mais suportados a partir de 1º de novembro de 2021. Se o seu projeto utilizou esse recurso, alterne para um mecanismo suportado para implantações, usando:
ARMTemplateForFactory.jsonoulinkedTemplatesarquivos.
Conteúdos relacionados
- Melhorias contínuas na implantação
- Automatizar a integração contínua mediante a utilização das versões dos Pipelines do Azure
- Promover manualmente um modelo do Resource Manager para cada ambiente
- Usar parâmetros personalizados com um modelo do Gerenciador de Recursos
- Modelos do Gerenciador de Recursos Vinculados
- Usando um ambiente de produção de hotfix
- Exemplo de script pré e pós-implantação