Tópicos avançados do SAP CDC
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Saiba mais sobre tópicos avançados para o conector SAP CDC, como integração de dados orientada por metadados, depuração e muito mais.
Parametrizando um fluxo de dados de mapeamento SAP CDC
Um dos principais pontos fortes dos pipelines e fluxos de dados de mapeamento no Azure Data Factory e no Azure Synapse Analytics é o suporte para integração de dados orientada por metadados. Com esse recurso, é possível projetar um único (ou pouco) pipeline parametrizado que pode ser usado para lidar com a integração de potencialmente centenas ou até milhares de fontes. O conector SAP CDC foi projetado com este princípio em mente: todas as propriedades relevantes, seja o objeto de origem, modo de execução, colunas de chave, etc., podem ser fornecidas por meio de parâmetros para maximizar a flexibilidade e o potencial de reutilização dos fluxos de dados de mapeamento do SAP CDC.
Para entender os conceitos básicos de parametrização de fluxos de dados de mapeamento, leia Parametrizando fluxos de dados de mapeamento.
Na galeria de modelos do Azure Data Factory e do Azure Synapse Analytics, você encontra um pipeline de modelo e fluxo de dados que mostra como parametrizar a ingestão de dados do SAP CDC.
Parametrizando o modo de origem e execução
O mapeamento de fluxos de dados não requer necessariamente um artefato de conjunto de dados: as transformações de origem e coletor oferecem um tipo de fonte (ou tipo de coletor) embutido. Nesse caso, todas as propriedades de origem definidas de outra forma em um conjunto de dados do ADF podem ser configuradas nas opções de origem da transformação de origem (ou na guia Configurações da transformação do coletor). O uso de um conjunto de dados embutido fornece uma melhor visão geral e simplifica a parametrização de um fluxo de dados de mapeamento, uma vez que a configuração completa de origem (ou coletor) é mantida em um só lugar.
Para SAP CDC, as propriedades mais comumente definidas por meio de parâmetros são encontradas nas guias Opções de origem e Otimizar. Quando Source type é Inline, as propriedades a seguir podem ser parametrizadas nas opções Source.
-
Contexto ODP: os valores de parâmetros válidos são
- ABAP_CDS para exibições do ABAP Core Data Services
- BW para SAP BW ou SAP BW/4HANA InfoProviders
- Visualizações de informações do HANA for SAP HANA
- SAPI para fontes de dados/extratores SAP
- quando o SAP Landscape Transformation Replication Server (SLT) é usado como origem, o nome do contexto ODP é SLT~<Queue Alias>. O valor Alias de fila pode ser encontrado em Dados de administração na configuração SLT no cockpit SLT (transação SAP LTRC).
- ODP_SELF e RANDOM são contextos ODP usados para validação técnica e testes, e normalmente não são relevantes.
- Nome ODP: forneça o nome ODP do qual você deseja extrair dados.
-
Modo de execução: os valores de parâmetros válidos são
- fullAndIncrementalLoad for Full na primeira execução e, em seguida, incremental, que inicia um processo de captura de dados de alteração e extrai um instantâneo de dados completo atual.
- fullLoad for Full em cada execução, que extrai um instantâneo de dados completo atual sem iniciar um processo de captura de dados de alteração.
- incrementalLoad apenas para alterações incrementais, que inicia um processo de captura de dados de alteração sem extrair um instantâneo completo atual.
- Colunas-chave: as colunas-chave são fornecidas como uma matriz de cadeias de caracteres (aspas duplas). Por exemplo, ao trabalhar com a tabela SAP VBAP (itens de ordem de venda), a definição chave teria que ser ["VBELN", "POSNR"] (ou ["MANDT","VBELN","POSNR"] caso o campo cliente também seja levado em consideração).
Parametrizando as condições do filtro para particionamento de origem
Na guia Otimizar, um esquema de particionamento de origem (consulte otimizando o desempenho para cargas completas ou iniciais) pode ser definido por meio de parâmetros. Normalmente, são necessárias duas etapas:
- Defina o esquema de particionamento de origem.
- Ingerir o parâmetro de particionamento no fluxo de dados de mapeamento.
Definir um esquema de particionamento de origem
O formato na etapa 1 segue o padrão JSON, consistindo em uma matriz de definições de partição, cada uma das quais é uma matriz de condições de filtro individuais. Essas condições em si são objetos JSON com uma estrutura alinhada com as chamadas opções de seleção no SAP. Na verdade, o formato exigido pela estrutura SAP ODP é basicamente o mesmo que os filtros DTP dinâmicos no SAP BW:
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
Por exemplo
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
corresponde a uma cláusula SQL WHERE ... EM QUE "VBELN" = '0000001000', ou
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
corresponde a uma cláusula SQL WHERE ... ONDE "VBELN" ENTRE '0000000000' E '0000001000'
Uma definição JSON de um esquema de particionamento contendo duas partições, portanto, tem a seguinte aparência:
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
onde a primeira partição contém os anos fiscais (GJAHR) de 2011 a 2015 e a segunda partição contém os anos fiscais de 2016 a 2020.
Nota
O Azure Data Factory não executa nenhuma verificação nessas condições. Por exemplo, é da responsabilidade do utilizador garantir que as condições da partição não se sobrepõem.
As condições de partição podem ser mais complexas, consistindo em várias condições elementares de filtro. Não há conjunções lógicas que definam explicitamente como combinar várias condições elementares dentro de uma partição. A definição implícita no SAP é a seguinte:
- incluindo condições ("sinal": "I") para o mesmo nome de campo são combinadas com OR (mentalmente, coloque parênteses em torno da condição resultante)
- as condições de exclusão ("sinal": "E") para o mesmo nome de campo são combinadas com OR (novamente, mentalmente, coloque parênteses em torno da condição resultante)
- As condições resultantes dos passos 1 e 2 são
- combinado com E para incluir condições,
- combinado com E NÃO para excluir condições.
Como exemplo, a condição de partição
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1010" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2010", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2021" }
]
corresponde a uma cláusula SQL WHERE ... ONDE ("BUKRS" = '1000' OU "BUKRS" = '1010') E ("GJAHR" ENTRE '2010' E '2025') E NÃO ("GJAHR" = '2021' ou "GJARH" = '2023')
Nota
Certifique-se de usar o formato interno SAP para os valores baixo e alto, inclua zeros à esquerda e expresse datas do calendário como uma cadeia de oito caracteres com o formato "AAAAMMDD".
Ingerir o parâmetro de particionamento no mapeamento do fluxo de dados
Para ingerir o esquema de particionamento em um fluxo de dados de mapeamento, crie um parâmetro de fluxo de dados (por exemplo, "sapPartitions"). Para passar o formato JSON para esse parâmetro, ele deve ser convertido em uma cadeia de caracteres usando a função @string( ):
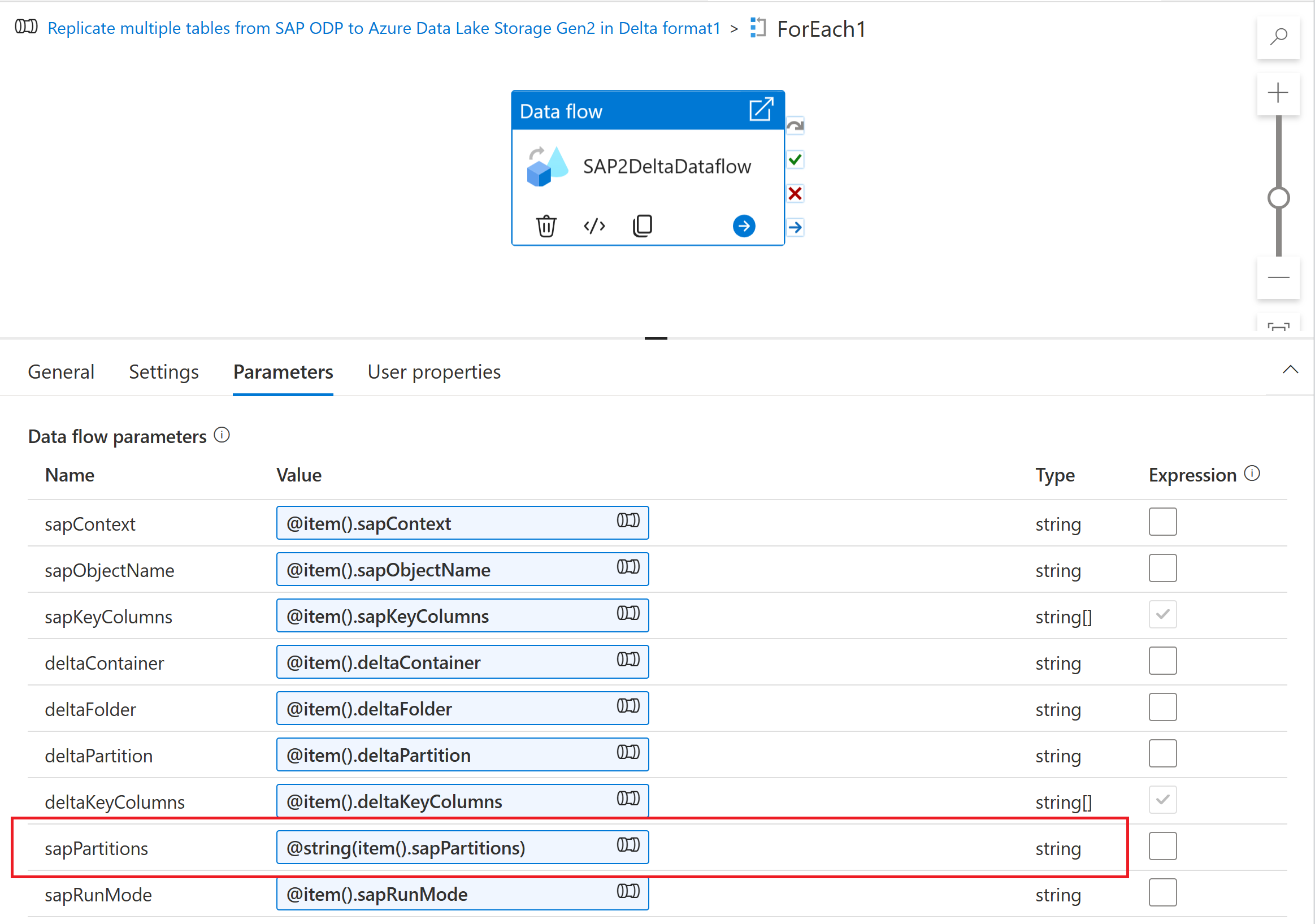
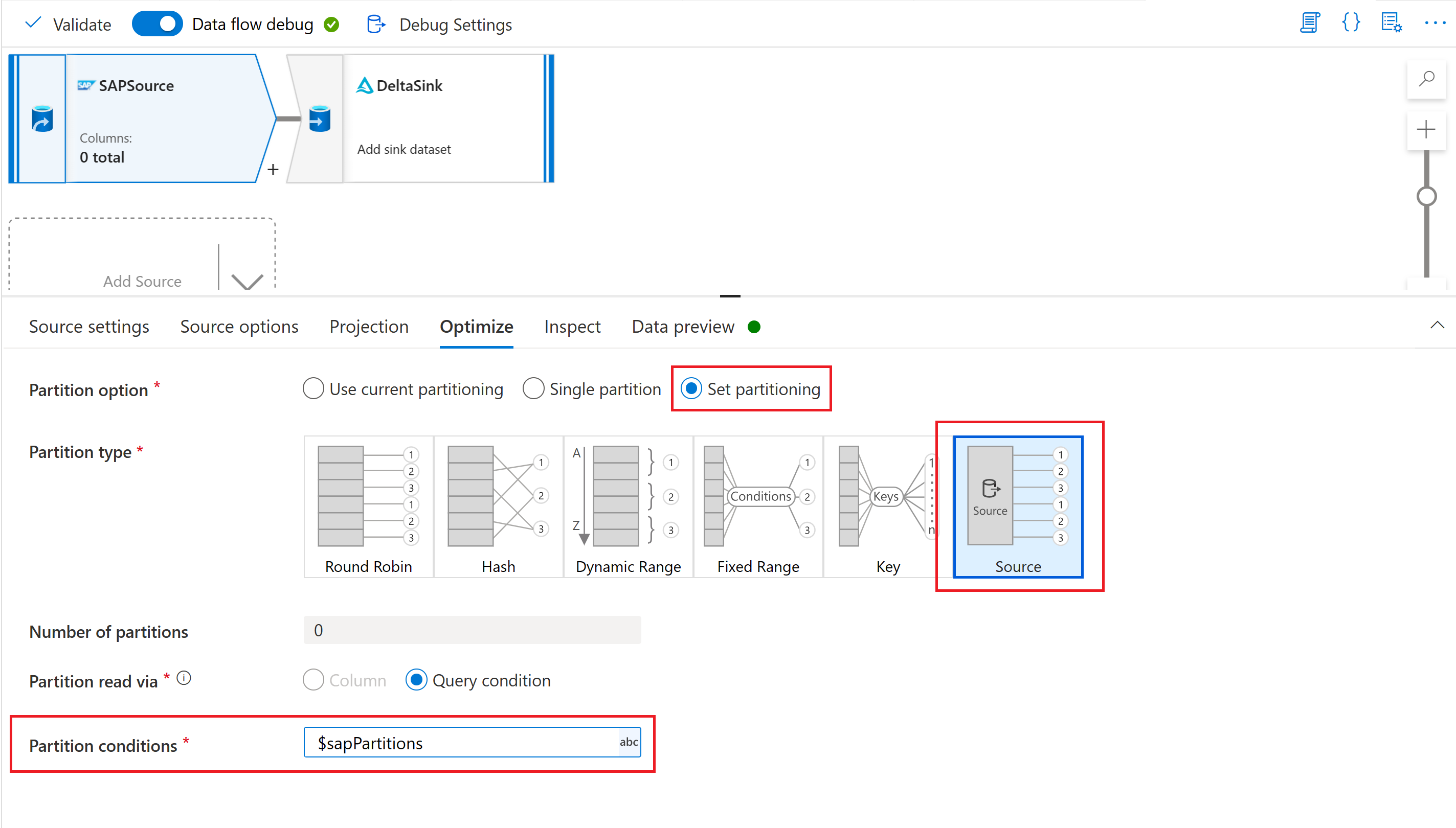
Finalmente, na guia otimizar da transformação de origem em seu fluxo de dados de mapeamento, selecione Tipo de partição "Fonte" e insira o parâmetro de fluxo de dados na propriedade Condições de partição .
Parametrizando a chave de ponto de verificação
Ao usar um fluxo de dados parametrizado para extrair dados de várias fontes SAP CDC, é importante parametrizar a chave de ponto de verificação na atividade de fluxo de dados do seu pipeline. A chave de ponto de verificação é usada pelo Azure Data Factory para gerenciar o status de um processo de captura de dados de alteração. Para evitar que o status de um processo CDC substitua o status de outro, certifique-se de que os valores de chave de ponto de verificação sejam exclusivos para cada conjunto de parâmetros usado em um fluxo de dados.
Nota
Uma prática recomendada para garantir a exclusividade da chave de ponto de verificação é adicionar o valor da chave de ponto de verificação ao conjunto de parâmetros para seu fluxo de dados.
Para obter mais informações sobre a chave de ponto de verificação, consulte Transformar dados com o conector SAP CDC.
Depuração
Os pipelines do Azure Data Factory podem ser executados por meio de execuções acionadas ou de depuração. Uma diferença fundamental entre essas duas opções é que as execuções de depuração executam o fluxo de dados e o pipeline com base na versão atual modelada na interface do usuário, enquanto as execuções acionadas executam a última versão publicada de um fluxo de dados e pipeline.
Para o SAP CDC, há mais um aspeto que precisa ser compreendido: para evitar um impacto das execuções de depuração em um processo de captura de dados de alteração existente, as execuções de depuração usam um valor de "processo de assinante" diferente (consulte Monitorar fluxos de dados do SAP CDC) do que as execuções acionadas. Assim, eles criam assinaturas separadas (ou seja, alteram processos de captura de dados) dentro do sistema SAP. Além disso, o valor "processo de assinante" para execuções de depuração tem um tempo de vida limitado à sessão da interface do usuário do navegador.
Nota
Para testar a estabilidade de um processo de captura de dados de alteração com o SAP CDC por um longo período de tempo (por exemplo, vários dias), o fluxo de dados e o pipeline precisam ser publicados e as execuções acionadas precisam ser executadas.