Preparar dados com disputa de dados
APLICA-SE A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
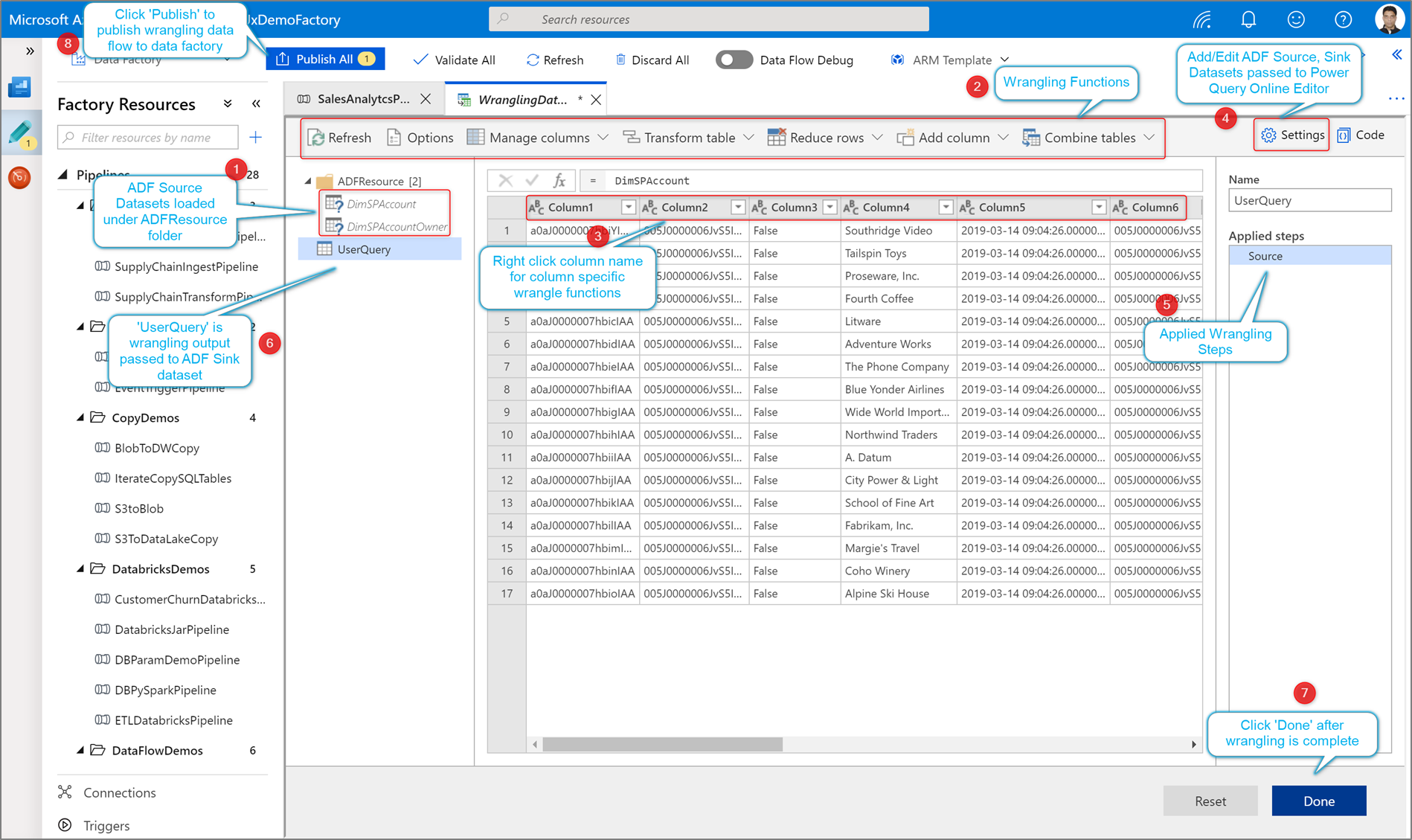
A disputa de dados no data factory permite criar mash-ups interativos do Power Query nativamente no ADF e, em seguida, executá-los em escala dentro de um pipeline do ADF.
Criar uma atividade do Power Query
Há duas maneiras de criar um Power Query no Azure Data Factory. Uma forma é clicar no ícone de adição e selecionar Power Query no painel de recursos de fábrica.
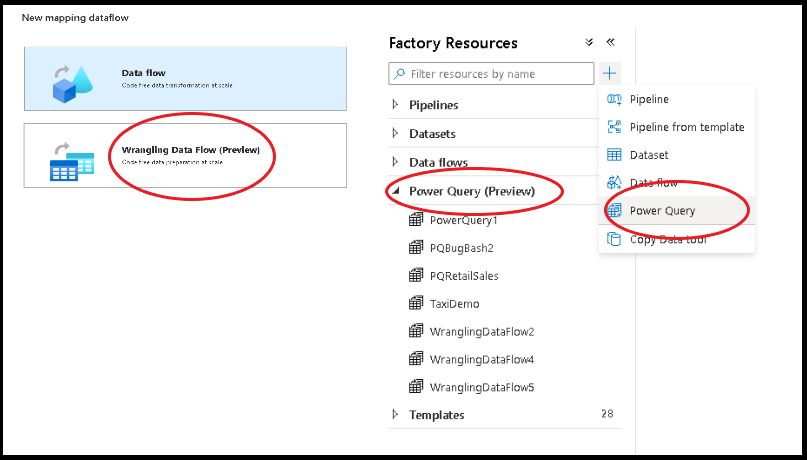
O outro método está no painel de atividades da tela de pipeline. Abra o acordeão do Power Query e arraste a atividade do Power Query para a tela.
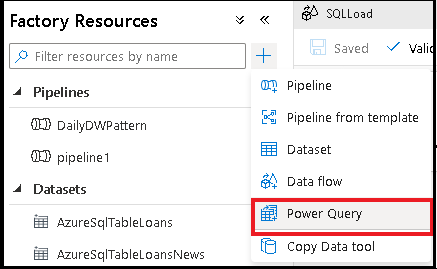
Criar uma atividade de disputa de dados do Power Query
Adicione um conjunto de dados de origem para o mash-up do Power Query. Você pode escolher um conjunto de dados existente ou criar um novo. Depois de salvar o mash-up, você pode criar um pipeline, adicionar a atividade de disputa de dados do Power Query ao pipeline e selecionar um conjunto de dados de coletor para informar ao ADF onde inserir seus dados. Embora você possa escolher um ou mais conjuntos de dados de origem, apenas um coletor é permitido no momento. A escolha de um conjunto de dados de coletor é opcional, mas pelo menos um conjunto de dados de origem é necessário.
Clique em Criar para abrir o editor de mashup do Power Query Online.
Primeiro, você escolherá uma fonte de conjunto de dados para o editor de mashup.
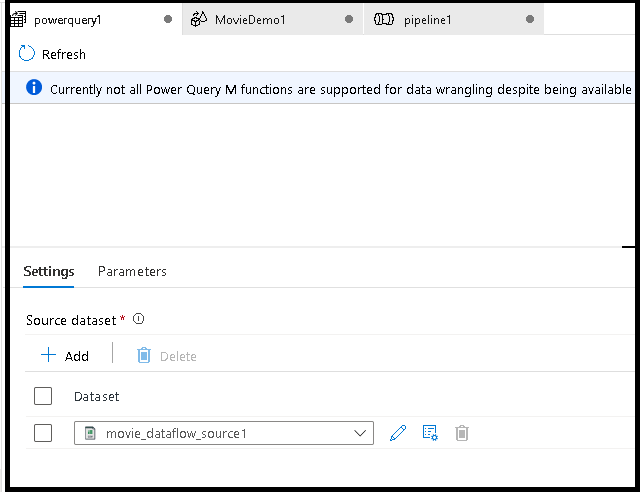
Depois de concluir a criação do Power Query, pode guardá-lo e, em seguida, criar um pipeline. Você precisa adicionar o mashup como uma atividade ao seu pipeline. É quando você vai criar/selecionar o conjunto de dados do coletor para aterrissar seus dados. Você também pode definir as propriedades do conjunto de dados do coletor clicando no segundo botão no lado direito do conjunto de dados afundado. Lembre-se de alterar a "opção de partição" em "Otimizar" para "Partição única" se você quiser apenas obter um único arquivo de saída.

Crie a sua disputa Power Query utilizando a preparação de dados sem código. Para obter a lista de funções disponíveis, consulte funções de transformação. O ADF traduz o script M em um script de fluxo de dados para que você possa executar seu Power Query em escala usando o ambiente Spark de fluxo de dados do Azure Data Factory.
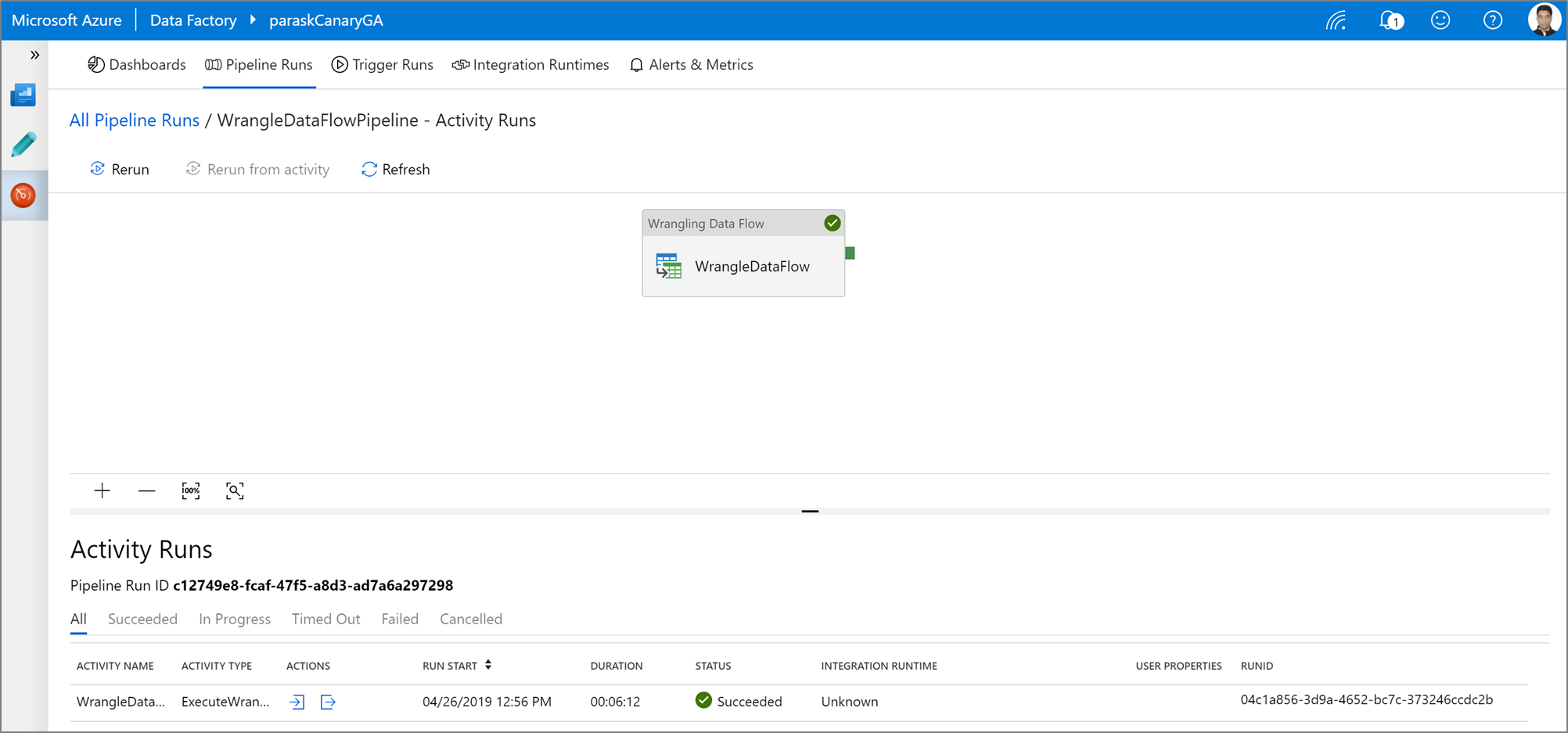
Executar e monitorizar uma atividade de disputa de dados do Power Query
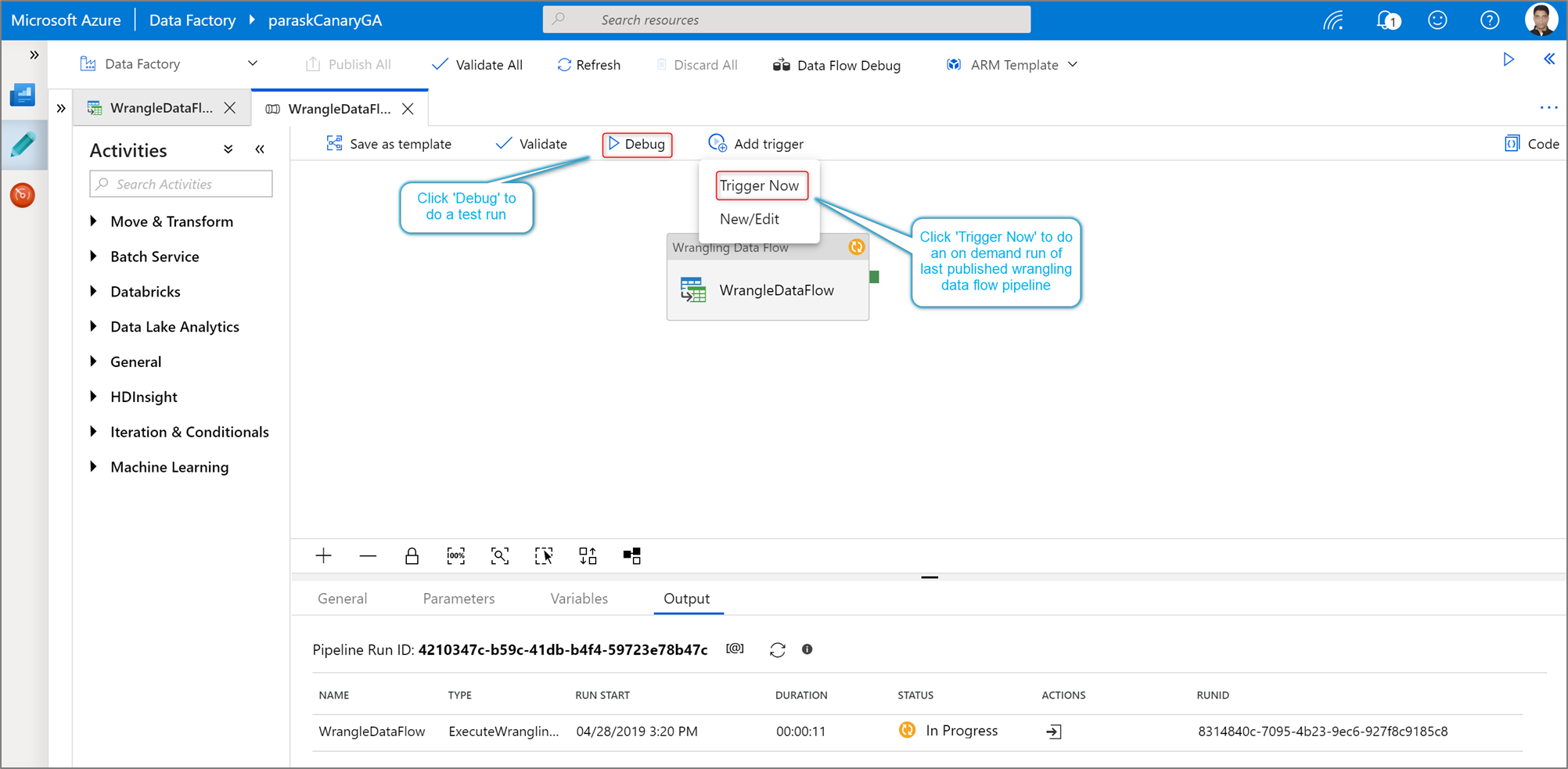
Para executar uma execução de depuração de pipeline de uma atividade do Power Query, clique em Depurar na tela do pipeline. Depois de publicar seu pipeline, o Trigger agora executa uma execução sob demanda do último pipeline publicado. Os pipelines do Power Query podem ser agendados com todos os gatilhos existentes do Azure Data Factory.
Aceda ao separador Monitor para visualizar a saída de uma execução de atividade do Power Query acionada.
Conteúdos relacionados
Saiba como criar um fluxo de dados de mapeamento.