Explorar e criar tabelas no DBFS
Importante
Esta documentação foi desativada e pode não ser atualizada. Os produtos, serviços ou tecnologias mencionados neste conteúdo não são mais suportados. Consulte Carregar ficheiros para o Azure Databricks, Criar ou modificar uma tabela utilizando o carregamento de ficheirose O que é o Catalog Explorer?.
Aceda à interface do utilizador de carregamento de ficheiros DBFS legados e criação de tabelas através da interface de utilizador de adicionar dados . Clique em ![]() New > Data > DBFS.
New > Data > DBFS.
Você também pode acessar a interface do usuário a partir de blocos de anotações clicando em Adicionar dados>arquivo.
O Databricks recomenda o uso do Catalog Explorer para uma experiência aprimorada para exibir objetos de dados e gerenciar ACLs e o Criar ou modificar tabela a partir da página de upload de arquivos para ingerir facilmente arquivos pequenos no Delta Lake.
Nota
A disponibilidade de alguns elementos descritos neste artigo varia de acordo com as configurações do espaço de trabalho. Entre em contato com o administrador do espaço de trabalho ou com a equipe da conta do Azure Databricks.
Importar dados
Se você tiver pequenos arquivos de dados em sua máquina local que deseja analisar com o Azure Databricks, poderá importá-los para o DBFS usando a interface do usuário.
Nota
Os administradores do espaço de trabalho podem desativar esse recurso. Para obter mais informações, consulte Gerenciar o carregamento de dados.
Criar uma tabela
Você pode iniciar a interface de criação de tabelas do DBFS clicando no ícone ![]() Novo na barra lateral ou no botão DBFS no agregar dados . Você pode preencher uma tabela a partir de arquivos em DBFS ou carregar arquivos.
Novo na barra lateral ou no botão DBFS no agregar dados . Você pode preencher uma tabela a partir de arquivos em DBFS ou carregar arquivos.
Com a interface do usuário, você só pode criar tabelas externas.
Escolha uma fonte de dados e siga as etapas na seção correspondente para configurar a tabela.
Se um administrador de espaço de trabalho do Azure Databricks tiver desabilitado a opção Carregar arquivo, você não terá a opção de carregar arquivos; Você pode criar tabelas usando uma das outras fontes de dados.
Instruções para carregar arquivo
- Arraste os arquivos para a zona suspensa Arquivos ou clique na zona de descarte para procurar e escolher arquivos. Após o upload, um caminho é exibido para cada arquivo. O caminho será algo como
/FileStore/tables/<filename>-<integer>.<file-type>. Você pode usar esse caminho em um bloco de anotações para ler dados. - Clique Criar tabela com a interface do usuário.
- Na lista suspensa Cluster, escolha um cluster.
Instruções para DBFS
- Selecione um arquivo.
- Clique Criar tabela com a interface do usuário.
- Na lista suspensa Cluster, escolha um cluster.
- Arraste os arquivos para a zona suspensa Arquivos ou clique na zona de descarte para procurar e escolher arquivos. Após o upload, um caminho é exibido para cada arquivo. O caminho será algo como
Clique em Pré-visualização da Tabela para ver a tabela.
No campo Nome da Tabela, substitua opcionalmente o nome da tabela padrão. Um nome de tabela pode conter apenas caracteres alfanuméricos minúsculos e sublinhados e deve começar com uma letra minúscula ou sublinhado.
No campo Criar no banco de dados, opcionalmente, substitua o banco de dados selecionado
default.No campo Tipo de arquivo, opcionalmente, substitua o tipo de arquivo inferido.
Se o tipo de ficheiro for CSV:
- No campo Delimitador de Coluna, selecione se deseja substituir o delimitador inferido.
- Indique se a primeira linha deve ser usada como título de coluna.
- Indique se o esquema deve ser inferido.
Se o tipo de ficheiro for JSON, indique se o ficheiro tem várias linhas.
Clique criar tabela.
Exibir bancos de dados e tabelas
Nota
Os espaços de trabalho com Catalog Explorer ativado não têm acesso ao comportamento herdado descrito abaixo.
Clique no ícone do Catálogo ![]() na barra lateral. O Azure Databricks seleciona um cluster em execução ao qual você tem acesso. A pasta Bancos de dados exibe a lista de bancos de dados com o banco de dados
na barra lateral. O Azure Databricks seleciona um cluster em execução ao qual você tem acesso. A pasta Bancos de dados exibe a lista de bancos de dados com o banco de dados default selecionado. A pasta Tabelas exibe a lista de tabelas no banco de dados default.
Você pode alterar o cluster no menu Bancos de dados, na interface do usuário de criação de tabela , ou na interface do usuário de visualização de tabela . Por exemplo, no menu Bancos de dados:
Clique na seta
 para baixo na parte superior da pasta Bancos de dados.
para baixo na parte superior da pasta Bancos de dados.Selecione um cluster.
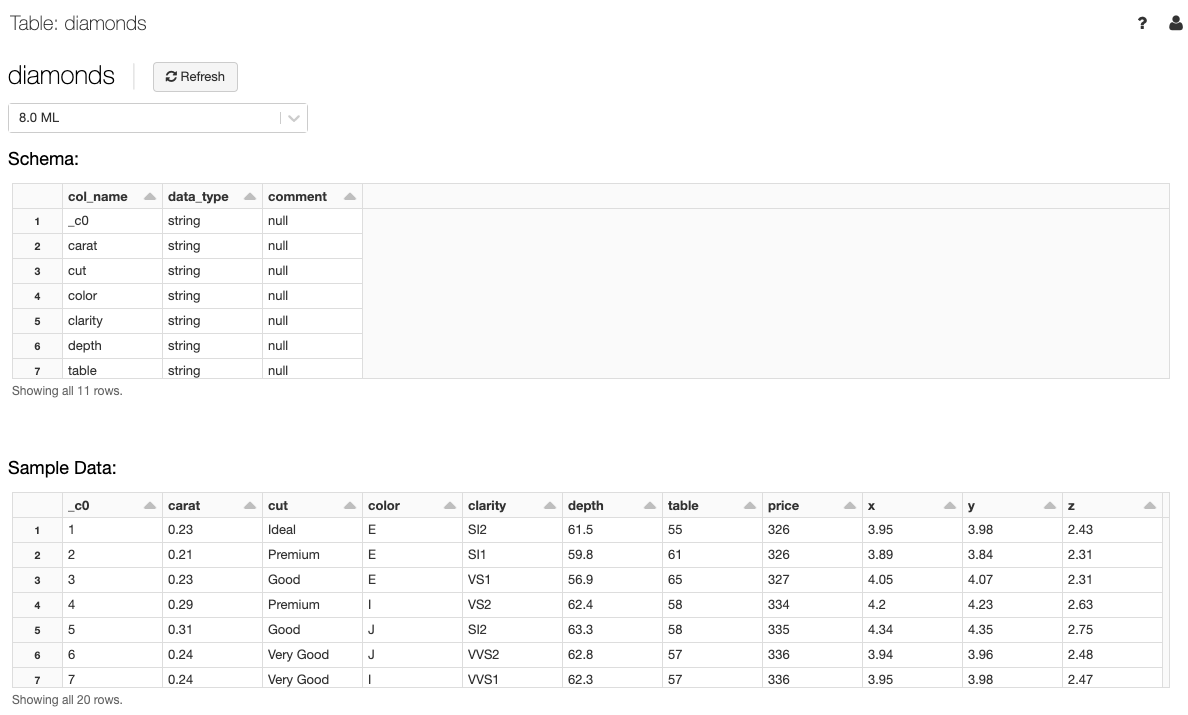
Ver detalhes da tabela
A exibição de detalhes da tabela mostra o esquema da tabela e os dados de exemplo.
Clique no ícone Catálogo
 na barra lateral.
na barra lateral.Na pasta Bancos de dados, clique em um banco de dados.
Na pasta Tabelas, clique no nome da tabela.
Na lista suspensa Cluster, selecione opcionalmente outro cluster para renderizar a visualização da tabela.
Nota
Para exibir a visualização da tabela, uma consulta Spark SQL é executada no cluster selecionado na lista suspensa Cluster. Se o cluster já tiver uma carga de trabalho em execução, a visualização da tabela pode levar mais tempo para carregar.
Excluir uma tabela usando a interface do usuário
- Clique no ícone do Catálogo na barra lateral.
- Clique no Menu Dropdown
 ao lado do nome da tabela e selecione Eliminar.
ao lado do nome da tabela e selecione Eliminar.