Executar um arquivo em um cluster ou um arquivo ou bloco de anotações como um trabalho no Azure Databricks usando a extensão Databricks para Visual Studio Code
A extensão Databricks para Visual Studio Code permite que você execute seu código Python em um cluster ou seu código ou bloco de anotações Python, R, Scala ou SQL como um trabalho no Azure Databricks.
Essas informações pressupõem que você já tenha instalado e configurado a extensão Databricks para Visual Studio Code. Consulte Instalar a extensão Databricks para Visual Studio Code.
Nota
Para depurar código ou blocos de anotações de dentro do Visual Studio Code, use Databricks Connect. Consulte Depurar código usando Databricks Connect para a extensão Databricks para Visual Studio Code e Executar e depurar células de bloco de anotações com Databricks Connect usando a extensão Databricks para Visual Studio Code.
Executar um arquivo Python em um cluster
Para executar um arquivo Python em um cluster do Azure Databricks usando a extensão Databricks para Visual Studio Code, com a extensão e seu projeto aberto:
- Abra o arquivo Python que você deseja executar no cluster.
- Proceda de uma das seguintes formas:
Na barra de título do editor de ficheiros, clique no ícone Executar no Databricks e, em seguida, clique em Carregar e Executar Ficheiro.
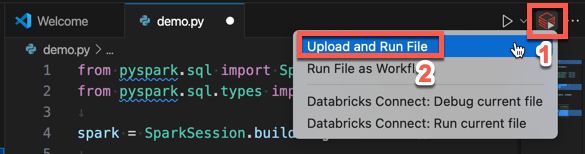
No modo de exibição do
Explorer ( Exibir ), clique com o botão direito do mouse no arquivo e selecioneExplorer Executar no Databricks Carregar e Executar Arquivo no menu de contexto.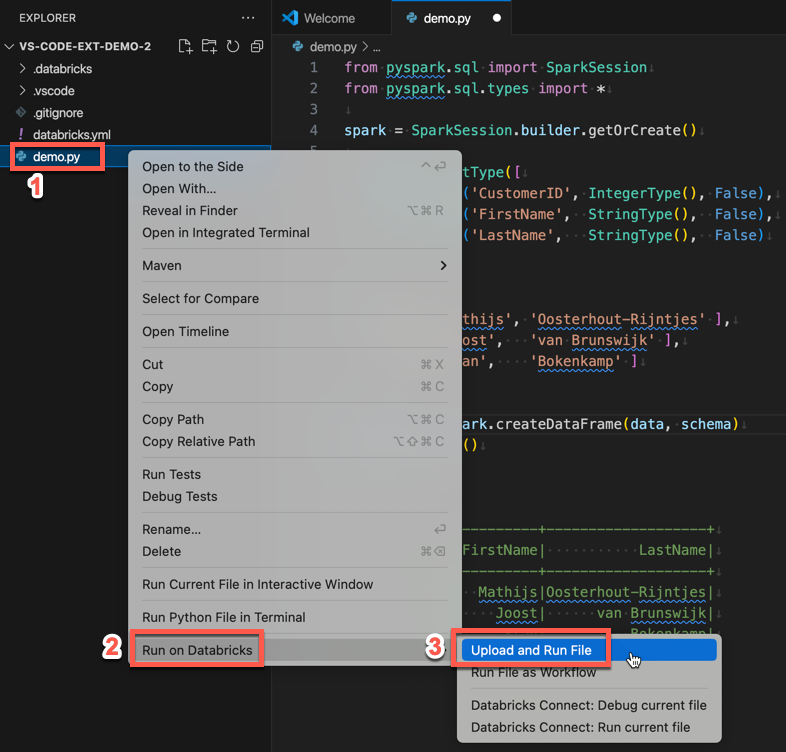
O arquivo é executado no cluster e a saída está disponível no Console de
Executar um arquivo Python como um trabalho
Para executar um arquivo Python como um trabalho do Azure Databricks usando a extensão Databricks para Visual Studio Code, com a extensão e seu projeto abertos:
- Abra o arquivo Python que você deseja executar como um trabalho.
- Proceda de uma das seguintes formas:
Na barra de título do editor de ficheiros, clique no ícone Executar no Databricks e, em seguida, clique em Executar Ficheiro como Fluxo de Trabalho.
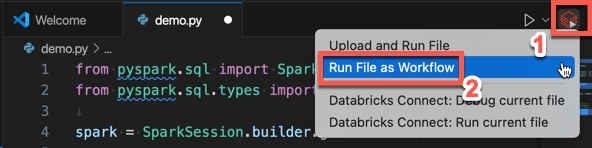
No modo de exibição do
Explorer ( Exibir ), clique com o botão direito do mouse no arquivo e selecioneExplorer Executar no Databricks Executar Arquivo como Fluxo de Trabalho no menu de contexto.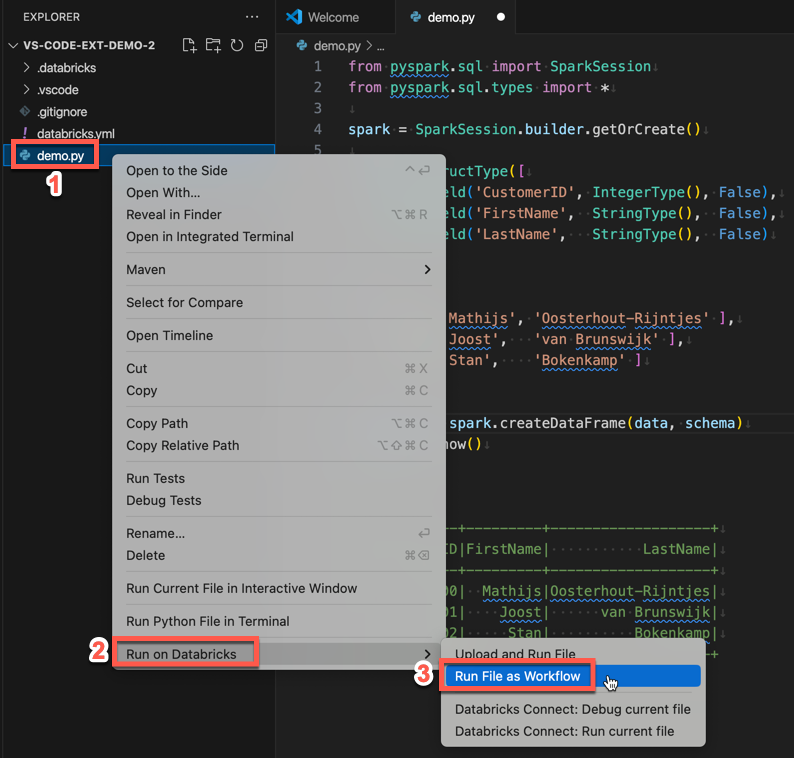
Uma nova guia do editor é exibida, intitulada Databricks Job Run. O arquivo é executado como um trabalho no espaço de trabalho e qualquer saída é impressa na área Saída da nova guia do editor.
Para exibir informações sobre a execução do trabalho, clique no link ID de execução da tarefa na nova guia Editor de execução de trabalho do Databricks. Seu espaço de trabalho é aberto e os detalhes da execução do trabalho são exibidos no espaço de trabalho.
Executar um bloco de anotações Python, R, Scala ou SQL como um trabalho
Para executar um bloco de anotações como um trabalho do Azure Databricks usando a extensão Databricks para Visual Studio Code, com a extensão e seu projeto aberto:
Abra o bloco de notas que pretende executar como trabalho.
Gorjeta
Para transformar um arquivo Python, R, Scala ou SQL em um bloco de anotações do Azure Databricks, adicione o comentário
# Databricks notebook sourceao início do arquivo e adicione o comentário# COMMAND ----------antes de cada célula. Para obter mais informações, consulte Importar um arquivo e convertê-lo em um bloco de anotações.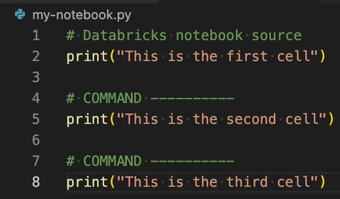
Execute um dos seguintes procedimentos:
- Na barra de título do editor de ficheiros do bloco de notas, clique no ícone Executar no Databricks e, em seguida, clique em Executar Ficheiro como Fluxo de Trabalho.
Nota
Se Executar no Databricks, pois o fluxo de trabalho não estiver disponível, consulte Criar uma configuração de execução personalizada.
- Na vista do
Explorer ( Vista ), clique com o botão direito do rato no arquivo de bloco de notas e selecioneExplorer Executar no Databricks Executar Arquivo como Fluxo de Trabalho no menu de contexto.
Uma nova guia do editor é exibida, intitulada Databricks Job Run. O bloco de anotações é executado como um trabalho no espaço de trabalho. O notebook e sua saída são exibidos na área Saída da nova guia do editor.
Para exibir informações sobre a execução do trabalho, clique no link ID de execução da tarefa na guia Editor de execução de trabalho do Databricks. Seu espaço de trabalho é aberto e os detalhes da execução do trabalho são exibidos no espaço de trabalho.
Criar uma configuração de execução personalizada
Uma configuração de execução personalizada para a extensão Databricks para Visual Studio Code permite que você passe argumentos personalizados para um trabalho ou um bloco de anotações, ou crie configurações de execução diferentes para arquivos diferentes.
Para criar uma configuração de execução personalizada, clique em Executar > Adicionar Configuração no menu principal do Visual Studio Code. Em seguida, selecione Databricks para uma configuração de execução baseada em cluster ou Databricks: Workflow para uma configuração de execução baseada em trabalho.
Por exemplo, a seguinte configuração de execução personalizada modifica o comando Run File as Workflow launch para passar o --prod argumento para o trabalho:
{
"version": "0.2.0",
"configurations": [
{
"type": "databricks-workflow",
"request": "launch",
"name": "Run on Databricks as Workflow",
"program": "${file}",
"parameters": {},
"args": ["--prod"]
}
]
}
Gorjeta
Adicione "databricks": true à sua "type": "python" configuração se quiser usar a configuração do Python, mas aproveite a autenticação do Databricks Connect que faz parte da configuração da extensão.
Usando configurações de execução personalizadas, você também pode passar argumentos de linha de comando e executar seu código apenas pressionando F5. Para obter mais informações, consulte Iniciar configurações na documentação do Visual Studio Code.