Orquestre trabalhos do Azure Databricks com o Apache Airflow
Este artigo descreve o suporte do Apache Airflow para orquestrar pipelines de dados com o Azure Databricks, tem instruções para instalar e configurar o Airflow localmente e fornece um exemplo de implantação e execução de um fluxo de trabalho do Azure Databricks com o Airflow.
Orquestração de tarefas em um pipeline de dados
Desenvolver e implantar um pipeline de processamento de dados geralmente requer o gerenciamento de dependências complexas entre tarefas. Por exemplo, um pipeline pode ler dados de uma fonte, limpar os dados, transformar os dados limpos e gravar os dados transformados em um destino. Você também precisa de suporte para testes, agendamento e solução de problemas de erros ao operacionalizar um pipeline.
Os sistemas de fluxo de trabalho abordam esses desafios, permitindo que você defina dependências entre tarefas, agende quando pipelines são executados e monitore fluxos de trabalho. O Apache Airflow é uma solução de código aberto para gerenciar e agendar pipelines de dados. O fluxo de ar representa pipelines de dados como gráficos acíclicos direcionados (DAGs) de operações. Você define um fluxo de trabalho em um arquivo Python e o Airflow gerencia o agendamento e a execução. A conexão Airflow Azure Databricks permite que você aproveite o mecanismo Spark otimizado oferecido pelo Azure Databricks com os recursos de agendamento do Airflow.
Requisitos
- A integração entre o Airflow e o Azure Databricks requer o Airflow versão 2.5.0 e posterior. Os exemplos neste artigo são testados com o Airflow versão 2.6.1.
- O fluxo de ar requer Python 3.8, 3.9, 3.10 ou 3.11. Os exemplos neste artigo são testados com Python 3.8.
- As instruções neste artigo para instalar e executar o Airflow exigem pipenv para criar um ambiente virtual Python.
Operadores de fluxo de ar para Databricks
Um DAG de fluxo de ar é composto por tarefas, onde cada tarefa executa um operador de fluxo de ar. Os operadores de fluxo de ar que suportam a integração com Databricks são implementados no provedor Databricks.
O provedor Databricks inclui operadores para executar várias tarefas em um espaço de trabalho do Azure Databricks, incluindo a importação de dados para uma tabela, a execução de consultas SQL e o trabalho com pastas Git do Databricks.
O provedor Databricks implementa dois operadores para acionar trabalhos:
- O DatabricksRunNowOperator requer um trabalho existente do Azure Databricks e usa a solicitação de API POST /api/2.1/jobs/run-now para disparar uma execução. O Databricks recomenda o uso do porque reduz a duplicação de definições de trabalho, e as
DatabricksRunNowOperatorexecuções de trabalho acionadas com esse operador podem ser encontradas na interface do usuário de trabalhos. - O DatabricksSubmitRunOperator não requer a existência de um trabalho no Azure Databricks e usa a solicitação de API POST /api/2.1/jobs/runs/submit para enviar a especificação do trabalho e disparar uma execução.
Para criar um novo trabalho do Azure Databricks ou redefinir um trabalho existente, o provedor Databricks implementa o DatabricksCreateJobsOperator. O DatabricksCreateJobsOperator usa as solicitações de API POST /api/2.1/jobs/create e POST /api/2.1/jobs/reset . Você pode usar o DatabricksCreateJobsOperator com o DatabricksRunNowOperator para criar e executar um trabalho.
Nota
Usar os operadores Databricks para disparar um trabalho requer o fornecimento de credenciais na configuração de conexão Databricks. Consulte Criar um token de acesso pessoal do Azure Databricks para o Airflow.
Os operadores Databricks Airflow gravam o URL da página de execução do trabalho nos logs de fluxo de ar a cada polling_period_seconds (o padrão é 30 segundos). Para obter mais informações, consulte a página do pacote apache-airflow-providers-databricks no site Airflow.
Instalar a integração do Airflow Azure Databricks localmente
Para instalar o Airflow e o provedor Databricks localmente para teste e desenvolvimento, use as etapas a seguir. Para outras opções de instalação do Airflow, incluindo a criação de uma instalação de produção, consulte a instalação na documentação do Airflow.
Abra um terminal e execute os seguintes comandos:
mkdir airflow
cd airflow
pipenv --python 3.8
pipenv shell
export AIRFLOW_HOME=$(pwd)
pipenv install apache-airflow
pipenv install apache-airflow-providers-databricks
mkdir dags
airflow db init
airflow users create --username admin --firstname <firstname> --lastname <lastname> --role Admin --email <email>
Substitua <firstname>, <lastname>e <email> pelo seu nome de utilizador e e-mail. Ser-lhe-á pedido que introduza uma palavra-passe para o utilizador administrador. Certifique-se de que guarda esta palavra-passe porque é necessário iniciar sessão na IU do Airflow.
Esse script executa as seguintes etapas:
- Cria um diretório nomeado
airflowe muda para esse diretório. - Usa
pipenvpara criar e gerar um ambiente virtual Python. O Databricks recomenda o uso de um ambiente virtual Python para isolar versões de pacotes e dependências de código para esse ambiente. Esse isolamento ajuda a reduzir incompatibilidades inesperadas de versão de pacote e colisões de dependência de código. - Inicializa uma variável de ambiente chamada
AIRFLOW_HOMEset para o caminho doairflowdiretório. - Instala os pacotes do provedor Airflow e Airflow Databricks.
- Cria um
airflow/dagsdiretório. O fluxo de ar usa o diretório para armazenar definições dedagsDAG. - Inicializa um banco de dados SQLite que o Airflow usa para rastrear metadados. Em uma implantação de fluxo de ar de produção, você configuraria o fluxo de ar com um banco de dados padrão. O banco de dados SQLite e a configuração padrão para sua implantação do
airflowAirflow são inicializados no diretório. - Cria um usuário administrador para o Airflow.
Gorjeta
Para confirmar a instalação do provedor Databricks, execute o seguinte comando no diretório de instalação Airflow:
airflow providers list
Inicie o servidor Web Airflow e o agendador
O servidor Web Airflow é necessário para visualizar a interface do usuário Airflow. Para iniciar o servidor Web, abra um terminal no diretório de instalação do Airflow e execute os seguintes comandos:
Nota
Se o servidor Web Airflow falhar ao iniciar devido a um conflito de portas, você poderá alterar a porta padrão na configuração Airflow.
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow webserver
O agendador é o componente de fluxo de ar que agenda DAGs. Para iniciar o agendador, abra um novo terminal no diretório de instalação do Airflow e execute os seguintes comandos:
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow scheduler
Teste a instalação do fluxo de ar
Para verificar a instalação do fluxo de ar, você pode executar um dos DAGs de exemplo incluídos no fluxo de ar:
- Em uma janela do navegador, abra
http://localhost:8080/homeo . Faça login na interface do usuário do Airflow com o nome de usuário e a senha que você criou ao instalar o Airflow. A página Airflow DAGs é exibida. - Clique no botão Pausar/Despausar DAG para cancelar a pausa de um dos DAGs de exemplo, por exemplo, o
example_python_operator. - Acione o DAG de exemplo clicando no botão Trigger DAG .
- Clique no nome do DAG para exibir detalhes, incluindo o status de execução do DAG.
Criar um token de acesso pessoal do Azure Databricks para o Airflow
O fluxo de ar se conecta ao Databricks usando um token de acesso pessoal (PAT) do Azure Databricks. Para criar um PAT:
- No seu espaço de trabalho do Azure Databricks, clique no seu nome de utilizador do Azure Databricks na barra superior e, em seguida, selecione Definições na lista pendente.
- Clique em Desenvolvedor.
- Ao lado de Tokens de acesso, clique em Gerenciar.
- Clique em Gerar novo token.
- (Opcional) Insira um comentário que o ajude a identificar esse token no futuro e altere o tempo de vida padrão do token de 90 dias. Para criar um token sem tempo de vida (não recomendado), deixe a caixa Tempo de vida (dias) vazia (em branco).
- Clique em Generate (Gerar).
- Copie o token exibido para um local seguro e clique em Concluído.
Nota
Certifique-se de salvar o token copiado em um local seguro. Não partilhe o seu token copiado com outras pessoas. Se você perder o token copiado, não poderá regenerar exatamente o mesmo token. Em vez disso, você deve repetir esse procedimento para criar um novo token. Se você perder o token copiado ou acreditar que o token foi comprometido, o Databricks recomenda que você exclua imediatamente esse token do seu espaço de trabalho clicando no ícone da lixeira (Revogar) ao lado do token na página de tokens do Access.
Se você não conseguir criar ou usar tokens em seu espaço de trabalho, isso pode ser porque o administrador do espaço de trabalho desabilitou tokens ou não lhe deu permissão para criar ou usar tokens. Consulte o administrador do espaço de trabalho ou os seguintes tópicos:
Nota
Como prática recomendada de segurança, quando você se autentica com ferramentas, sistemas, scripts e aplicativos automatizados, o Databricks recomenda que você use tokens de acesso pessoal pertencentes a entidades de serviço em vez de usuários do espaço de trabalho. Para criar tokens para entidades de serviço, consulte Gerenciar tokens para uma entidade de serviço.
Você também pode se autenticar no Azure Databricks usando um token de ID do Microsoft Entra. Consulte Conexão Databricks na documentação do fluxo de ar.
Configurar uma conexão do Azure Databricks
Sua instalação do Airflow contém uma conexão padrão para o Azure Databricks. Para atualizar a conexão para se conectar ao seu espaço de trabalho usando o token de acesso pessoal criado acima:
- Em uma janela do navegador, abra
http://localhost:8080/connection/list/o . Se lhe for pedido para iniciar sessão, introduza o seu nome de utilizador e palavra-passe de administrador. - Em Conn ID, localize databricks_default e clique no botão Editar registro .
- Substitua o valor no campo Host pelo nome da instância do espaço de trabalho da sua implantação do Azure Databricks, por exemplo,
https://adb-123456789.cloud.databricks.com. - No campo Senha, insira seu token de acesso pessoal do Azure Databricks.
- Clique em Guardar.
Se você estiver usando um token de ID do Microsoft Entra, consulte Conexão Databricks na documentação do Airflow para obter informações sobre como configurar a autenticação.
Exemplo: Criar um DAG de fluxo de ar para executar um trabalho do Azure Databricks
O exemplo a seguir demonstra como criar uma implantação simples do Airflow que é executada em sua máquina local e implanta um exemplo de DAG para disparar execuções no Azure Databricks. Neste exemplo, você irá:
- Crie um novo bloco de anotações e adicione código para imprimir uma saudação com base em um parâmetro configurado.
- Crie um trabalho do Azure Databricks com uma única tarefa que executa o bloco de anotações.
- Configure uma conexão de fluxo de ar para seu espaço de trabalho do Azure Databricks.
- Crie um DAG de fluxo de ar para acionar o trabalho do bloco de anotações. Você define o DAG em um script Python usando
DatabricksRunNowOperatoro . - Use a interface do usuário Airflow para acionar o DAG e exibir o status da execução.
Criar um bloco de notas
Este exemplo usa um bloco de anotações contendo duas células:
- A primeira célula contém um widget de texto Databricks Utilities que define uma variável chamada
greetingset para o valorworldpadrão. - A segunda célula imprime o valor da variável prefixada
greetingporhello.
Para criar o bloco de notas:
Vá para seu espaço de trabalho do Azure Databricks, clique em
 Novo na barra lateral e selecione Bloco de Anotações.
Novo na barra lateral e selecione Bloco de Anotações.Dê um nome ao seu bloco de anotações, como Hello Airflow, e verifique se o idioma padrão está definido como Python.
Copie o seguinte código Python e cole-o na primeira célula do bloco de anotações.
dbutils.widgets.text("greeting", "world", "Greeting") greeting = dbutils.widgets.get("greeting")Adicione uma nova célula abaixo da primeira célula e copie e cole o seguinte código Python na nova célula:
print("hello {}".format(greeting))
Criar um trabalho
Clique em
 Fluxos de trabalho na barra lateral.
Fluxos de trabalho na barra lateral.Clique em
 .
.A guia Tarefas é exibida com a caixa de diálogo Criar tarefa.
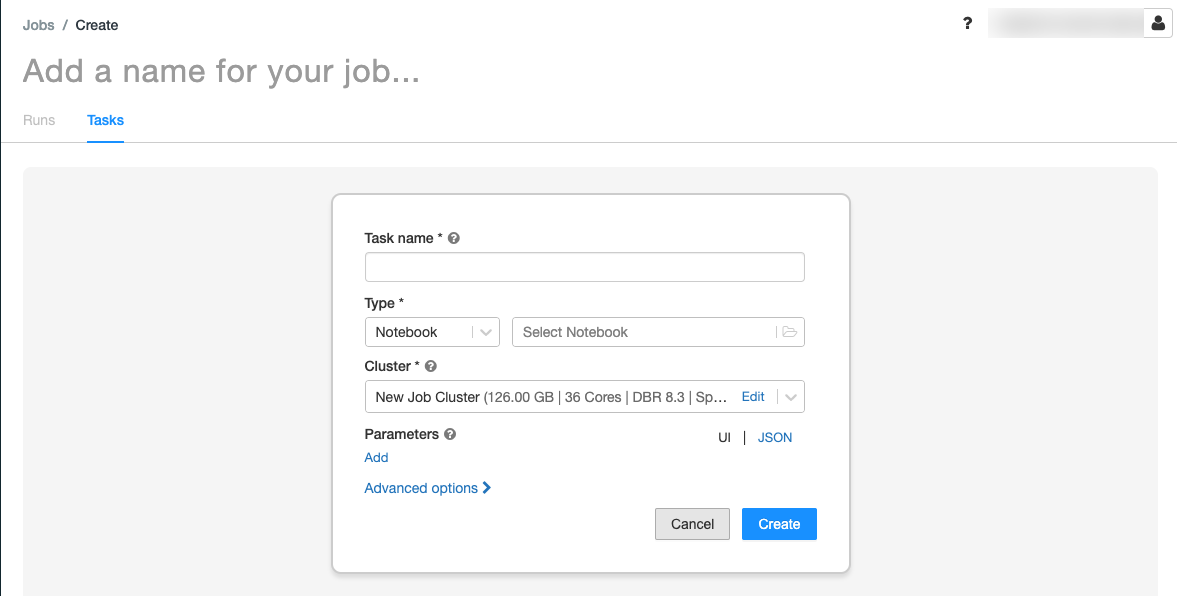
Substitua Adicione um nome para o seu trabalho... pelo nome do seu trabalho.
No campo Nome da tarefa , insira um nome para a tarefa, por exemplo, tarefa de saudação.
No menu suspenso Tipo, selecione Bloco de Anotações.
No menu suspenso Origem, selecione Espaço de trabalho.
Clique na caixa de texto Caminho e use o navegador de arquivos para localizar o bloco de anotações criado, clique no nome do bloco de anotações e clique em Confirmar.
Clique em Adicionar em Parâmetros. No campo Chave, digite
greeting. No campo Valor, insiraAirflow user.Clique em Criar tarefa.
No painel Detalhes do trabalho, copie o valor ID do trabalho. Esse valor é necessário para acionar o trabalho a partir do fluxo de ar.
Executar a tarefa
Para testar seu novo trabalho na interface do usuário de Trabalhos do Azure Databricks, clique em  no canto superior direito. Quando a execução for concluída, você poderá verificar a saída exibindo os detalhes da execução do trabalho.
no canto superior direito. Quando a execução for concluída, você poderá verificar a saída exibindo os detalhes da execução do trabalho.
Criar um novo DAG de fluxo de ar
Você define um DAG Airflow em um arquivo Python. Para criar um DAG para acionar o trabalho de bloco de anotações de exemplo:
Em um editor de texto ou IDE, crie um novo arquivo nomeado
databricks_dag.pycom o seguinte conteúdo:from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator from airflow.utils.dates import days_ago default_args = { 'owner': 'airflow' } with DAG('databricks_dag', start_date = days_ago(2), schedule_interval = None, default_args = default_args ) as dag: opr_run_now = DatabricksRunNowOperator( task_id = 'run_now', databricks_conn_id = 'databricks_default', job_id = JOB_ID )Substitua
JOB_IDpelo valor do ID do trabalho salvo anteriormente.Salve o
airflow/dagsarquivo no diretório. O Airflow lê e instala automaticamente os arquivos DAG armazenados noairflow/dags/.
Instalar e verificar o DAG no fluxo de ar
Para acionar e verificar o DAG na interface do usuário do fluxo de ar:
- Em uma janela do navegador, abra
http://localhost:8080/homeo . A tela Airflow DAGs é exibida. - Localize
databricks_dage clique no botão Pausar/Despausar DAG para cancelar a pausa do DAG. - Acione o DAG clicando no botão Trigger DAG .
- Clique em uma execução na coluna Execuções para exibir o status e os detalhes da execução.