Desenvolver código em notebooks Databricks
Esta página descreve como desenvolver código em blocos de anotações Databricks, incluindo preenchimento automático, formatação automática para Python e SQL, combinação de Python e SQL em um bloco de anotações e acompanhamento do histórico de versões do notebook.
Para obter mais detalhes sobre as funcionalidades avançadas disponíveis com o editor, como preenchimento automático, seleção de variáveis, suporte a vários cursores e comparações lado a lado, consulte Como navegar pelo bloco de notas Databricks e editor de ficheiros.
Quando você usa o bloco de anotações ou o editor de arquivos, o Assistente Databricks está disponível para ajudá-lo a gerar, explicar e depurar código. Consulte Usar o Databricks Assistant para obter mais informações.
Os notebooks Databricks também incluem um depurador interativo integrado para notebooks Python. Consulte Depurar blocos de anotações.
Modularize seu código
Importante
Esta funcionalidade está em Pré-visualização Pública.
Com o Databricks Runtime 11.3 LTS e superior, você pode criar e gerenciar arquivos de código-fonte no espaço de trabalho do Azure Databricks e, em seguida, importar esses arquivos para seus blocos de anotações, conforme necessário.
Para obter mais informações sobre como trabalhar com arquivos de código-fonte, consulte Compartilhar código entre blocos de anotações Databricks e Trabalhar com módulos Python e R.
Formatar células de código
O Azure Databricks fornece ferramentas que permitem formatar código Python e SQL em células de bloco de anotações de forma rápida e fácil. Essas ferramentas reduzem o esforço para manter seu código formatado e ajudam a impor os mesmos padrões de codificação em seus blocos de anotações.
Biblioteca de formatador preto Python
Importante
Esta funcionalidade está em Pré-visualização Pública.
O Azure Databricks dá suporte à formatação de código Python usando preto dentro do bloco de anotações. O notebook deve ser anexado a um cluster com black pacotes tokenize-rt Python instalados.
No Databricks Runtime 11.3 LTS e superior, o black Azure Databricks pré-instala e tokenize-rt. Você pode usar o formatador diretamente sem a necessidade de instalar essas bibliotecas.
No Databricks Runtime 10.4 LTS e inferior, você deve instalar black==22.3.0 e tokenize-rt==4.2.1 partir do PyPI em seu notebook ou cluster para usar o formatador Python. Pode executar o seguinte comando no seu bloco de notas:
%pip install black==22.3.0 tokenize-rt==4.2.1
ou instale a biblioteca no cluster.
Para obter mais detalhes sobre como instalar bibliotecas, consulte Gerenciamento de ambiente Python.
Para arquivos e blocos de anotações em pastas Databricks Git, você pode configurar o formatador Python com base no pyproject.toml arquivo. Para usar esse recurso, crie um pyproject.toml arquivo no diretório raiz da pasta Git e configure-o de acordo com o formato de configuração Black. Edite a seção [tool.black] no arquivo. A configuração é aplicada quando você formata qualquer arquivo e bloco de anotações nessa pasta Git.
Como formatar células Python e SQL
Você deve ter a permissão CAN EDIT no bloco de anotações para formatar o código.
O Azure Databricks usa a biblioteca Gethue/sql-formatter para formatar SQL e o formatador de código preto para Python.
Você pode acionar o formatador das seguintes maneiras:
Formatar uma única célula
- Atalho de teclado: pressione Cmd+Shift+F.
- Menu de contexto de comando:
- Formatar célula SQL: Selecione Formatar SQL no menu de contexto do comando de uma célula SQL. Este item de menu é visível apenas em células do bloco de anotações SQL ou naquelas com uma
%sqlmágica de linguagem. - Formatar célula Python: Selecione Format Python no menu suspenso de contexto de comando de uma célula Python. Este item de menu é visível apenas em células de bloco de anotações Python ou naquelas com uma
%pythonmágica de linguagem.
- Formatar célula SQL: Selecione Formatar SQL no menu de contexto do comando de uma célula SQL. Este item de menu é visível apenas em células do bloco de anotações SQL ou naquelas com uma
- Bloco de Anotações Editar menu: Selecione uma célula Python ou SQL e, em seguida, selecione Editar > Formatar Célula(s).
Formatar várias células
Selecione várias células e, em seguida, selecione Editar > Formatar Célula(s). Se você selecionar células de mais de uma linguagem, somente as células SQL e Python serão formatadas. Isso inclui aqueles que usam
%sqle%python.Formatar todas as células Python e SQL no bloco de notas
Selecione Editar > Formatar Bloco de Anotações. Se o seu bloco de notas contiver mais do que uma linguagem, apenas as células SQL e Python serão formatadas. Isso inclui aqueles que usam
%sqle%python.
Limitações da formatação de código
- O preto aplica os padrões PEP 8 para recuo de 4 espaços. O recuo não é configurável.
- Não há suporte para a formatação de cadeias de caracteres Python incorporadas dentro de um SQL UDF. Da mesma forma, a formatação de cadeias de caracteres SQL dentro de um Python UDF não é suportada.
Linguagens de código em blocos de notas
Definir idioma padrão
O idioma padrão do bloco de anotações aparece ao lado do nome do bloco de anotações.

Para alterar o idioma padrão, clique no botão de idioma e selecione o novo idioma no menu suspenso. Para garantir que os comandos existentes continuem a funcionar, os comandos do idioma padrão anterior são automaticamente prefixados com um comando language magic.
Misturar idiomas
Por padrão, as células usam o idioma padrão do bloco de anotações. Você pode substituir o idioma padrão em uma célula clicando no botão de idioma e selecionando um idioma no menu suspenso.
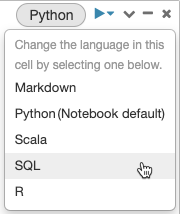
Como alternativa, você pode usar o comando %<language> language magic no início de uma célula. Os comandos mágicos suportados são: %python, %r, %scala, e %sql.
Nota
Quando você invoca um comando language magic, o comando é enviado para o REPL no contexto de execução do bloco de anotações. As variáveis definidas numa língua (e, portanto, no REPL para essa língua) não estão disponíveis no REPL de outra língua. Os REPLs podem compartilhar o estado somente por meio de recursos externos, como arquivos no DBFS ou objetos no armazenamento de objetos.
Os notebooks também suportam alguns comandos mágicos auxiliares:
-
%sh: Permite que você execute o código shell em seu bloco de anotações. Para falhar a célula se o comando shell tiver um status de saída diferente de zero, adicione a-eopção. Este comando é executado apenas no driver Apache Spark, e não nos trabalhadores. Para executar um comando shell em todos os nós, use um script init. -
%fs: Permite que você usedbutilscomandos do sistema de arquivos. Por exemplo, para executar o comandodbutils.fs.lspara listar arquivos, você pode especificar%fs lsem vez disso. Para obter mais informações, consulte Trabalhar com arquivos no Azure Databricks. -
%md: Permite incluir vários tipos de documentação, incluindo texto, imagens e fórmulas e equações matemáticas. Consulte a secção seguinte.
Realce e preenchimento automático da sintaxe SQL em comandos Python
O realce de sintaxe e o preenchimento automático do SQL estão disponíveis quando você usa o SQL dentro de um comando Python, como em um spark.sql comando.
Explore os resultados da célula SQL
Em um bloco de anotações Databricks, os resultados de uma célula de linguagem SQL são disponibilizados automaticamente como um DataFrame implícito atribuído à variável _sqldf. Em seguida, você pode usar essa variável em qualquer célula Python e SQL executada depois, independentemente de sua posição no bloco de anotações.
Nota
Este recurso tem as seguintes limitações:
- A
_sqldfvariável não está disponível em blocos de anotações que usam um SQL warehouse para computação. - O uso
_sqldfem células Python subsequentes é suportado no Databricks Runtime 13.3 e superior. - O uso
_sqldfem células SQL subsequentes só é suportado no Databricks Runtime 14.3 e superior. - Se a consulta usar as palavras-chave
CACHE TABLEouUNCACHE TABLE, a_sqldfvariável não estará disponível.
A captura de tela abaixo mostra como _sqldf pode ser usado em células Python e SQL subsequentes:

Importante
A variável _sqldf é reatribuída cada vez que uma célula SQL é executada. Para evitar perder a referência a um resultado específico do DataFrame, atribua-o a um novo nome de variável antes de executar a próxima célula SQL:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Executar células SQL em paralelo
Enquanto um comando está em execução e seu bloco de anotações está anexado a um cluster interativo, você pode executar uma célula SQL simultaneamente com o comando atual. A célula SQL é executada em uma nova sessão paralela.
Para executar uma célula em paralelo:
Clique em Executar agora. A célula é executada imediatamente.
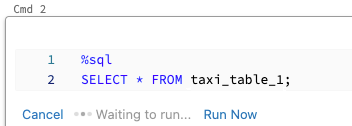
Como a célula é executada em uma nova sessão, exibições temporárias, UDFs e o Python DataFrame implícito (_sqldf) não são suportados para células executadas em paralelo. Além disso, o catálogo padrão e os nomes de banco de dados são usados durante a execução paralela. Se seu código se refere a uma tabela em um catálogo ou banco de dados diferente, você deve especificar o nome da tabela usando namespace de três níveis (catalog.schema.table).
Executar células SQL em um armazém SQL
Você pode executar comandos SQL em um bloco de anotações Databricks em um SQL warehouse, um tipo de computação otimizado para análise SQL. Consulte Usar um bloco de anotações com um depósito SQL.