Definir variáveis
Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
As variáveis proporcionam-lhe uma forma conveniente de obter os principais bits de dados em várias partes do pipeline. A utilização mais comum de variáveis é definir um valor que pode utilizar no pipeline. Todas as variáveis são cadeias mutáveis. O valor de uma variável pode mudar consoante a execução e o trabalho do pipeline.
Quando você define a mesma variável em vários locais com o mesmo nome, a variável com escopo mais local tem precedência. Assim, uma variável definida no nível do trabalho pode substituir uma variável definida no nível do estágio. Uma variável definida no nível do estágio substitui um conjunto de variáveis no nível da raiz do pipeline. Um conjunto de variáveis no nível raiz do pipeline substitui um conjunto de variáveis na interface do usuário de configurações do pipeline. Para saber mais sobre como trabalhar com variáveis definidas no nível de trabalho, estágio e raiz, consulte Escopo da variável.
Você pode usar variáveis com expressões para atribuir condicionalmente valores e personalizar ainda mais os pipelines.
As variáveis são diferentes dos parâmetros de runtime. Os parâmetros de runtime são escritos e estão disponíveis durante a análise de modelos.
Variáveis definidas pelo usuário
Ao definir uma variável, você pode usar sintaxes diferentes (macro, expressão de modelo ou tempo de execução) e qual sintaxe você usa determina onde no pipeline sua variável é renderizada.
Em pipelines YAML, você pode definir variáveis no nível raiz, estágio e trabalho. Você também pode especificar variáveis fora de um pipeline YAML na interface do usuário. Quando você define uma variável na interface do usuário, essa variável pode ser criptografada e definida como secreta.
As variáveis definidas pelo usuário podem ser definidas como somente leitura. Há restrições de nomenclatura para variáveis (exemplo: você não pode usar secret no início de um nome de variável).
Você pode usar um grupo de variáveis para disponibilizar variáveis em vários pipelines.
Use modelos para definir variáveis em um arquivo que são usadas em vários pipelines.
Variáveis de várias linhas definidas pelo usuário
O Azure DevOps dá suporte a variáveis de várias linhas, mas há algumas limitações.
Componentes downstream, como tarefas de pipeline, podem não manipular os valores das variáveis corretamente.
O Azure DevOps não alterará os valores de variáveis definidos pelo usuário. Os valores das variáveis precisam ser formatados corretamente antes de serem passados como variáveis de várias linhas. Ao formatar sua variável, evite caracteres especiais, não use nomes restritos e certifique-se de usar um formato de terminação de linha que funcione para o sistema operacional do seu agente.
As variáveis de várias linhas se comportam de forma diferente dependendo do sistema operacional. Para evitar isso, certifique-se de formatar variáveis de várias linhas corretamente para o sistema operacional de destino.
O Azure DevOps nunca altera valores de variáveis, mesmo que você forneça formatação sem suporte.
Variáveis do sistema
Além das variáveis definidas pelo usuário, o Azure Pipelines tem variáveis de sistema com valores predefinidos. Por exemplo, a variável predefinida Build.BuildId fornece a ID de cada compilação e pode ser usada para identificar diferentes execuções de pipeline. Você pode usar a Build.BuildId variável em scripts ou tarefas quando precisar de um valor exclusivo.
Se você estiver usando YAML ou pipelines de compilação clássicos, consulte variáveis predefinidas para obter uma lista abrangente de variáveis do sistema.
Se você estiver usando pipelines de liberação clássicos, consulte Variáveis de versão.
As variáveis do sistema são definidas com seu valor atual quando você executa o pipeline. Algumas variáveis são definidas automaticamente. Como autor ou usuário final do pipeline, você altera o valor de uma variável de sistema antes que o pipeline seja executado.
As variáveis de sistema são somente leitura.
Variáveis de ambiente
As variáveis de ambiente são específicas do sistema operacional que você está usando. Eles são injetados em um pipeline de maneiras específicas da plataforma. O formato corresponde a como as variáveis de ambiente são formatadas para sua plataforma de script específica.
Em sistemas UNIX (macOS e Linux), as variáveis de ambiente têm o formato $NAME. No Windows, o formato é %NAME% para lote e $env:NAME no PowerShell.
As variáveis definidas pelo sistema e pelo usuário também são injetadas como variáveis de ambiente para sua plataforma. Quando as variáveis se convertem em variáveis de ambiente, os nomes das variáveis tornam-se maiúsculas e os períodos transformam-se em sublinhados. Por exemplo, o nome any.variable da variável torna-se o nome $ANY_VARIABLEda variável .
Há restrições de nomenclatura de variáveis para variáveis de ambiente (exemplo: você não pode usar secret no início de um nome de variável).
Restrições de nomenclatura das variáveis
As variáveis definidas pelo usuário e de ambiente podem consistir em letras, .números e _ caracteres. Não use prefixos variáveis reservados pelo sistema. São eles: endpoint, input, secret, path, e securefile. Qualquer variável que comece com uma dessas cadeias de caracteres (independentemente da capitalização) não estará disponível para suas tarefas e scripts.
Compreender a sintaxe das variáveis
Os Pipelines do Azure suportam três formas diferentes para referenciar variáveis: macro, expressão de modelo e expressão de runtime. Você pode usar cada sintaxe para uma finalidade diferente e cada uma tem algumas limitações.
Em um pipeline, as variáveis de expressão de modelo (${{ variables.var }}) são processadas em tempo de compilação, antes do início do tempo de execução. As variáveis de sintaxe de macro ($(var)) são processadas durante o tempo de execução antes da execução de uma tarefa. As expressões de tempo de execução ($[variables.var]) também são processadas durante o tempo de execução, mas destinam-se a ser usadas com condições e expressões. Quando utiliza uma expressão de runtime, deve ocupar todo o lado direito de uma definição.
Neste exemplo, você pode ver que a expressão de modelo ainda tem o valor inicial da variável depois que a variável é atualizada. O valor da variável de sintaxe de macro é atualizado. O valor da expressão de modelo não é alterado porque todas as variáveis de expressão de modelo são processadas em tempo de compilação antes da execução das tarefas. Por outro lado, as variáveis de sintaxe de macro são avaliadas antes de cada tarefa ser executada.
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
Variáveis de sintaxe de macro
A maioria dos exemplos de documentação usa sintaxe de macro ($(var)). A sintaxe de macro é projetada para interpolar valores de variáveis em entradas de tarefas e em outras variáveis.
As variáveis com sintaxe de macro são processadas antes que uma tarefa seja executada durante o tempo de execução. O tempo de execução acontece após a expansão do modelo. Quando o sistema encontra uma expressão de macro, ele substitui a expressão pelo conteúdo da variável. Se não houver nenhuma variável com esse nome, a expressão de macro não será alterada. Por exemplo, se $(var) não puder ser substituído, $(var) não será substituído por nada.
As variáveis de sintaxe de macro permanecem inalteradas sem valor porque um valor vazio como $() pode significar algo para a tarefa que você está executando e o agente não deve presumir que deseja que esse valor seja substituído. Por exemplo, se você usar $(foo) para referenciar variável foo em uma tarefa Bash, substituir todas as $() expressões na entrada para a tarefa pode quebrar seus scripts Bash.
As variáveis de macro só são expandidas quando são usadas para um valor, não como uma palavra-chave. Os valores aparecem no lado direito de uma definição de pipeline. O seguinte é válido: key: $(value). O seguinte não é válido: $(key): value. As variáveis de macro não são expandidas quando usadas para exibir um nome de trabalho embutido. Em vez disso, você deve usar a displayName propriedade.
Nota
As variáveis de sintaxe de macro são expandidas apenas para stages, jobse steps.
Não é possível, por exemplo, usar a sintaxe de macro dentro de um resource ou trigger.
Este exemplo usa sintaxe de macro com Bash, PowerShell e uma tarefa de script. A sintaxe para chamar uma variável com sintaxe de macro é a mesma para todos os três.
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
Sintaxe da expressão de modelo
Você pode usar a sintaxe da expressão de modelo para expandir os parâmetros e as variáveis do modelo (${{ variables.var }}). As variáveis de modelo são processadas em tempo de compilação e são substituídas antes do início do tempo de execução. As expressões de modelo são projetadas para reutilizar partes do YAML como modelos.
As variáveis de modelo coalescem silenciosamente em cadeias de caracteres vazias quando um valor de substituição não é encontrado. As expressões de modelo, ao contrário das expressões de macro e tempo de execução, podem aparecer como teclas (lado esquerdo) ou valores (lado direito). O seguinte é válido: ${{ variables.key }} : ${{ variables.value }}.
Sintaxe da expressão em tempo de execução
Você pode usar a sintaxe de expressão de tempo de execução para variáveis que são expandidas em tempo de execução ($[variables.var]). As variáveis de expressão de tempo de execução se aglutinam silenciosamente em cadeias de caracteres vazias quando um valor de substituição não é encontrado. Use expressões de tempo de execução em condições de trabalho, para dar suporte à execução condicional de trabalhos ou estágios inteiros.
As variáveis de expressão de tempo de execução só são expandidas quando são usadas para um valor, não como uma palavra-chave. Os valores aparecem no lado direito de uma definição de pipeline. O seguinte é válido: key: $[variables.value]. O seguinte não é válido: $[variables.key]: value. A expressão de tempo de execução deve ocupar todo o lado direito de um par chave-valor. Por exemplo, é válido, key: $[variables.value] mas key: $[variables.value] foo não é.
| Sintaxe | Exemplo | Quando é processado? | Onde ele se expande em uma definição de pipeline? | Como ele renderiza quando não é encontrado? |
|---|---|---|---|---|
| macro | $(var) |
tempo de execução antes da execução de uma tarefa | valor (lado direito) | impressões $(var) |
| expressão de modelo | ${{ variables.var }} |
tempo de compilação | chave ou valor (lado esquerdo ou direito) | cadeia vazia |
| expressão de tempo de execução | $[variables.var] |
tempo de execução | valor (lado direito) | cadeia vazia |
Que sintaxe devo usar?
Use a sintaxe de macro se estiver fornecendo uma cadeia de caracteres segura ou uma entrada de variável predefinida para uma tarefa.
Escolha uma expressão de tempo de execução se estiver trabalhando com condições e expressões. No entanto, não use uma expressão de tempo de execução se não quiser que sua variável vazia seja impressa (exemplo: $[variables.var]). Por exemplo, se você tiver uma lógica condicional que depende de uma variável com um valor específico ou nenhum valor. Nesse caso, você deve usar uma expressão de macro.
Normalmente, uma variável de modelo é o padrão a ser usado. Ao aproveitar as variáveis de modelo, seu pipeline injetará totalmente o valor da variável em seu pipeline na compilação do pipeline. Isso é útil ao tentar depurar pipelines. Você pode baixar os arquivos de log e avaliar o valor totalmente expandido que está sendo substituído. Como a variável é substituída, você não deve aproveitar a sintaxe do modelo para valores confidenciais.
Definir variáveis no pipeline
No caso mais comum, você define as variáveis e usa-as dentro do arquivo YAML. Isso permite que você acompanhe as alterações na variável em seu sistema de controle de versão. Você também pode definir variáveis na interface do usuário de configurações de pipeline (consulte a guia Clássico) e fazer referência a elas em seu YAML.
Aqui está um exemplo que mostra como definir duas variáveis configuration e platform, e usá-las posteriormente em etapas. Para usar uma variável em uma instrução YAML, envolva-a em $(). As variáveis não podem ser usadas para definir um repository em uma instrução YAML.
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
Escopos variáveis
No arquivo YAML, você pode definir uma variável em vários escopos:
- No nível raiz, para torná-lo disponível para todos os trabalhos no pipeline.
- Ao nível do estágio, disponibilizá-lo apenas para um estágio específico.
- No nível do trabalho, para torná-lo disponível apenas para um trabalho específico.
Quando você define uma variável na parte superior de um YAML, a variável está disponível para todos os trabalhos e estágios no pipeline e é uma variável global. As variáveis globais definidas em um YAML não são visíveis na interface do usuário de configurações do pipeline.
As variáveis no nível do trabalho substituem as variáveis no nível raiz e no nível do estágio. As variáveis no nível do estágio substituem as variáveis no nível raiz.
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
A saída de ambos os trabalhos tem esta aparência:
# job1
value
value1
value1
# job2
value
value2
value
Especificar variáveis
Nos exemplos anteriores, a variables palavra-chave é seguida por uma lista de pares chave-valor.
As chaves são os nomes das variáveis e os valores são os valores das variáveis.
Há outra sintaxe, útil quando você deseja usar modelos para variáveis ou grupos de variáveis.
Com modelos, as variáveis podem ser definidas em um YAML e incluídas em outro arquivo YAML.
Os grupos de variáveis são um conjunto de variáveis que você pode usar em vários pipelines. Eles permitem que você gerencie e organize variáveis que são comuns a vários estágios em um só lugar.
Use esta sintaxe para modelos de variáveis e grupos de variáveis no nível raiz de um pipeline.
Nessa sintaxe alternativa, a variables palavra-chave usa uma lista de especificadores de variáveis.
Os especificadores de variáveis são name para uma variável regular, group para um grupo de variáveis e template para incluir um modelo de variável.
O exemplo a seguir demonstra todos os três.
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
Saiba mais sobre a reutilização de variáveis com modelos.
Acessar variáveis através do ambiente
Observe que as variáveis também são disponibilizadas para scripts por meio de variáveis de ambiente. A sintaxe para usar essas variáveis de ambiente depende da linguagem de script.
O nome é maiúsculo e o . é substituído pelo _. Isso é inserido automaticamente no ambiente do processo. Seguem-se alguns exemplos:
- Script em lote:
%VARIABLE_NAME% - Script do PowerShell:
$env:VARIABLE_NAME - Script Bash:
$VARIABLE_NAME
Importante
As variáveis predefinidas que contêm caminhos de arquivo são convertidas para o estilo apropriado (estilo do Windows C:\foo\ versus estilo Unix /foo/) com base no tipo de host do agente e no tipo de shell. Se você estiver executando tarefas de script bash no Windows, deverá usar o método de variável de ambiente para acessar essas variáveis em vez do método de variável de pipeline para garantir que você tenha o estilo de caminho de arquivo correto.
Definir variáveis de segredos
Gorjeta
As variáveis secretas não são exportadas automaticamente como variáveis de ambiente. Para usar variáveis secretas em seus scripts, mapeie-as explicitamente para variáveis de ambiente. Para obter mais informações, consulte Definir variáveis secretas.
Não defina variáveis secretas em seu arquivo YAML. Os sistemas operacionais geralmente registram comandos para os processos que eles executam, e você não gostaria que o log incluísse um segredo que você passou como entrada. Use o ambiente do script ou mapeie a variável dentro do variables bloco para passar segredos para seu pipeline.
Nota
O Azure Pipelines faz um esforço para mascarar segredos ao emitir dados para logs de pipeline, para que você possa ver variáveis adicionais e dados mascarados na saída e logs que não estão definidos como segredos.
Você precisa definir variáveis secretas na interface do usuário de configurações de pipeline para seu pipeline. Essas variáveis têm como escopo o pipeline onde estão definidas. Você também pode definir variáveis secretas em grupos de variáveis.
Para definir segredos na interface Web, siga estes passos:
- Vá para a página Pipelines , selecione o pipeline apropriado e, em seguida, selecione Editar.
- Localize as variáveis para este pipeline.
- Adicione ou atualize a variável.
- Selecione a opção Manter esse valor secreto para armazenar a variável de forma criptografada.
- Salve o pipeline.
As variáveis secretas são encriptadas em repouso com uma chave RSA de 2048 bits. Os segredos estão disponíveis no agente para tarefas e scripts a serem usados. Tenha cuidado com quem tem acesso para alterar seu pipeline.
Importante
Fazemos um esforço para impedir que segredos apareçam na saída do Azure Pipelines, mas você ainda precisa tomar precauções. Nunca ecoe segredos como saída. Alguns sistemas operacionais registram argumentos de linha de comando. Nunca passe segredos na linha de comando. Em vez disso, sugerimos que você mapeie seus segredos em variáveis de ambiente.
Nunca mascaramos subcadeias de segredos. Se, por exemplo, "abc123" for definido como um segredo, "abc" não será mascarado dos logs. Isso é para evitar mascarar segredos em um nível muito granular, tornando os logs ilegíveis. Por esta razão, os segredos não devem conter dados estruturados. Se, por exemplo, "{ "foo": "bar" }" for definido como um segredo, "bar" não será mascarado dos logs.
Ao contrário de uma variável normal, eles não são automaticamente descriptografados em variáveis de ambiente para scripts. Você precisa mapear explicitamente variáveis secretas.
O exemplo a seguir mostra como mapear e usar uma variável secreta chamada mySecret em scripts PowerShell e Bash. Duas variáveis globais são definidas. GLOBAL_MYSECRET é atribuído o valor de uma variável mySecretsecreta e GLOBAL_MY_MAPPED_ENV_VAR é atribuído o valor de uma variável nonSecretVariablenão secreta . Ao contrário de uma variável de pipeline normal, não há nenhuma variável de ambiente chamada MYSECRET.
A tarefa do PowerShell executa um script para imprimir as variáveis.
$(mySecret): Esta é uma referência direta à variável secreta e funciona.$env:MYSECRET: Isso tenta acessar a variável secreta como uma variável de ambiente, o que não funciona porque as variáveis secretas não são mapeadas automaticamente para variáveis de ambiente.$env:GLOBAL_MYSECRET: Isso tenta acessar a variável secreta através de uma variável global, que também não funciona porque as variáveis secretas não podem ser mapeadas dessa maneira.$env:GLOBAL_MY_MAPPED_ENV_VAR: Este acessa a variável não secreta através de uma variável global, que funciona.$env:MY_MAPPED_ENV_VAR: Isso acessa a variável secreta por meio de uma variável de ambiente específica da tarefa, que é a maneira recomendada de mapear variáveis secretas para variáveis de ambiente.
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
A saída de ambas as tarefas no script anterior teria esta aparência:
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
Você também pode usar variáveis secretas fora de scripts. Por exemplo, você pode mapear variáveis secretas para tarefas usando a variables definição. Este exemplo mostra como usar variáveis $(vmsUser) secretas e $(vmsAdminPass) em uma tarefa de cópia de arquivo do Azure.
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@4
inputs:
SourcePath: 'my/path'
azureSubscription: 'my-subscription'
Destination: 'AzureVMs'
storage: 'my-storage'
resourceGroup: 'my-rg'
vmsAdminUserName: $(VMS_USER)
vmsAdminPassword: $(VMS_PASS)
Variáveis secretas de referência em grupos de variáveis
Este exemplo mostra como fazer referência a um grupo de variáveis em seu arquivo YAML e também como adicionar variáveis dentro do YAML. São utilizadas duas variáveis do grupo de variáveis: user e token. A token variável é secreta e é mapeada para a variável $env:MY_MAPPED_TOKEN de ambiente para que possa ser referenciada no YAML.
Este YAML faz uma chamada REST para recuperar uma lista de versões e produz o resultado.
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
Importante
Por padrão, com os repositórios do GitHub, as variáveis secretas associadas ao seu pipeline não são disponibilizadas para obter compilações de solicitação de forks. Para obter mais informações, consulte Contribuições de forks.
Compartilhar variáveis entre pipelines
Para compartilhar variáveis em vários pipelines em seu projeto, use a interface da Web. Em Biblioteca, use grupos de variáveis.
Usar variáveis de saída de tarefas
Algumas tarefas definem variáveis de saída, que podem ser consumidas em etapas, trabalhos e estágios downstream. No YAML, você pode acessar variáveis entre trabalhos e estágios usando dependências.
Ao fazer referência a trabalhos de matriz em tarefas downstream, você precisará usar uma sintaxe diferente. Consulte Definir uma variável de saída multitrabalho. Você também precisa usar uma sintaxe diferente para variáveis em trabalhos de implantação. Consulte Suporte para variáveis de saída em trabalhos de implantação.
Algumas tarefas definem variáveis de saída, que você pode consumir em etapas e trabalhos downstream dentro do mesmo estágio. No YAML, você pode acessar variáveis entre trabalhos usando dependências.
- Para fazer referência a uma variável de uma tarefa diferente dentro do mesmo trabalho, use
TASK.VARIABLE. - Para fazer referência a uma variável de uma tarefa de um trabalho diferente, use
dependencies.JOB.outputs['TASK.VARIABLE'].
Nota
Por padrão, cada estágio em um pipeline depende daquele imediatamente anterior no arquivo YAML. Se você precisar se referir a um estágio que não seja imediatamente anterior ao atual, poderá substituir esse padrão automático adicionando uma dependsOn seção ao estágio.
Nota
Os exemplos a seguir usam sintaxe de pipeline padrão. Se você estiver usando pipelines de implantação, a sintaxe variável e condicional será diferente. Para obter informações sobre a sintaxe específica a ser usada, consulte Trabalhos de implantação.
Para esses exemplos, suponha que temos uma tarefa chamada MyTask, que define uma variável de saída chamada MyVar.
Saiba mais sobre a sintaxe em Expressões - Dependências.
Usar saídas no mesmo trabalho
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
Usar saídas em um trabalho diferente
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Usar saídas em um estágio diferente
Para usar a saída de um estágio diferente, o formato para referenciar variáveis é stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE']. No nível do estágio, mas não no nível do trabalho, você pode usar essas variáveis em condições.
As variáveis de saída só estão disponíveis na próxima etapa a jusante. Se vários estágios consumirem a mesma variável de saída, use a dependsOn condição.
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Você também pode passar variáveis entre estágios com uma entrada de arquivo. Para fazer isso, você precisará definir variáveis no segundo estágio no nível do trabalho e, em seguida, passar as variáveis como env: entradas.
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
A saída dos estágios no pipeline anterior tem esta aparência:
Hello inline version
true
crushed tomatoes
Listar variáveis
Você pode listar todas as variáveis em seu pipeline com o comando az pipelines variable list . Para começar, consulte Introdução à CLI do Azure DevOps.
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
Parâmetros
- org: URL da organização do Azure DevOps. Você pode configurar a organização padrão usando
az devops configure -d organization=ORG_URLo . Obrigatório se não estiver configurado como padrão ou coletado usandogit configo . Exemplo:--org https://dev.azure.com/MyOrganizationName/. - pipeline-id: Obrigatório se o nome do pipeline não for fornecido. ID do pipeline.
- pipeline-name: Necessário se pipeline-id não for fornecido, mas ignorado se pipeline-id for fornecido. Nome do pipeline.
- projeto: Nome ou ID do projeto. Você pode configurar o projeto padrão usando
az devops configure -d project=NAME_OR_ID. Obrigatório se não estiver configurado como padrão ou coletado usandogit config.
Exemplo
O comando a seguir lista todas as variáveis no pipeline com ID 12 e mostra o resultado em formato de tabela.
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
Definir variáveis em scripts
Os scripts podem definir variáveis que são posteriormente consumidas em etapas subsequentes no pipeline. Todas as variáveis definidas por este método são tratadas como strings. Para definir uma variável a partir de um script, use uma sintaxe de comando e imprima como stdout.
Definir uma variável de escopo de trabalho a partir de um script
Para definir uma variável a partir de um script, use o task.setvariable comando log. Isso atualiza as variáveis de ambiente para trabalhos subsequentes. Os trabalhos subsequentes têm acesso à nova variável com sintaxe de macro e em tarefas como variáveis de ambiente.
Quando issecret for true, o valor da variável será salvo como secreto e mascarado do log. Para obter mais informações sobre variáveis secretas, consulte comandos de log.
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
As etapas subsequentes também terão a variável pipeline adicionada ao seu ambiente. Não é possível usar a variável na etapa em que ela está definida.
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
A saída do pipeline anterior.
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
Definir uma variável de saída de trabalho múltiplo
Se quiser disponibilizar uma variável para trabalhos futuros, marque-a como uma variável de saída usando isOutput=true. Em seguida, você pode mapeá-lo em trabalhos futuros usando a $[] sintaxe e incluindo o nome da etapa que definiu a variável. As variáveis de saída de vários trabalhos só funcionam para trabalhos no mesmo estágio.
Para passar variáveis para trabalhos em diferentes estágios, use a sintaxe de dependências de estágio.
Nota
Por padrão, cada estágio em um pipeline depende daquele imediatamente anterior no arquivo YAML. Portanto, cada estágio pode usar variáveis de saída do estágio anterior. Para acessar outros estágios, você precisará alterar o gráfico de dependência, por exemplo, se o estágio 3 exigir uma variável do estágio 1, você precisará declarar uma dependência explícita no estágio 1.
Ao criar uma variável de saída de trabalho múltiplo, você deve atribuir a expressão a uma variável. Neste YAML, $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] é atribuído à variável $(myVarFromJobA).
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
A saída do pipeline anterior.
this is the value
this is the value
Se você estiver definindo uma variável de um estágio para outro, use stageDependencies.
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
Se você estiver definindo uma variável a partir de uma matriz ou fatia, para fazer referência à variável quando acessá-la a partir de um trabalho downstream, você deve incluir:
- O nome da tarefa.
- O passo.
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA1)"
name: echovar
Certifique-se de prefixar o nome do trabalho para as variáveis de saída de um trabalho de implantação . Neste caso, o nome do trabalho é A:
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar
 Definir as
Definir as  Definir as
Definir as  Definir as
Definir as Definir variáveis usando expressões
Você pode definir uma variável usando uma expressão. Já encontramos um caso disso para definir uma variável para a saída de outra de um trabalho anterior.
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
Você pode usar qualquer uma das expressões suportadas para definir uma variável. Aqui está um exemplo de configuração de uma variável para atuar como um contador que começa em 100, é incrementado em 1 para cada execução e é redefinido para 100 todos os dias.
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
Para obter mais informações sobre contadores, dependências e outras expressões, consulte expressões.
Configurar variáveis configuráveis para etapas
Você pode definir settableVariables dentro de uma etapa ou especificar que nenhuma variável pode ser definida.
Neste exemplo, o script não pode definir uma variável.
steps:
- script: echo This is a step
target:
settableVariables: none
Neste exemplo, o script permite a variável sauce , mas não a variável secretSauce. Você verá um aviso na página de execução do pipeline.

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
Permitir no momento da fila
Se uma variável aparecer no bloco de um arquivo YAML, seu valor será fixo variables e não poderá ser substituído no momento da fila. A prática recomendada é definir suas variáveis em um arquivo YAML, mas há momentos em que isso não faz sentido. Por exemplo, você pode querer definir uma variável secreta e não ter a variável exposta em seu YAML. Ou, talvez seja necessário definir manualmente um valor variável durante a execução do pipeline.
Você tem duas opções para definir valores de tempo de fila. Você pode definir uma variável na interface do usuário e selecionar a opção Permitir que os usuários substituam esse valor ao executar esse pipeline ou pode usar parâmetros de tempo de execução. Se sua variável não for um segredo, a prática recomendada é usar parâmetros de tempo de execução.
Para definir uma variável no momento da fila, adicione uma nova variável dentro do pipeline e selecione a opção de substituição.
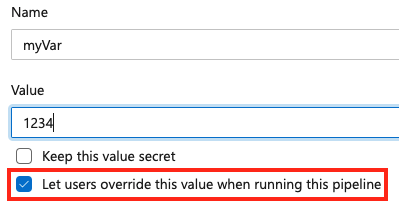
Para permitir que uma variável seja definida no momento da fila, certifique-se de que a variável também não apareça no variables bloco de um pipeline ou trabalho. Se você definir uma variável no bloco de variáveis de um YAML e na interface do usuário, o valor no YAML terá prioridade.

Expansão de variáveis
Quando define uma variável com o mesmo nome em vários âmbitos, aplica-se a seguinte precedência (precedência mais alta primeiro).
- Variável ao nível do trabalho definida no ficheiro YAML
- Variável ao nível da fase definida no ficheiro YAML
- Variável ao nível do pipeline definida no ficheiro YAML
- Variável definida no momento da fila
- Variável de pipeline definida na IU de Definições do pipeline
No exemplo a seguir, a mesma variável a é definida no nível de pipeline e no nível de trabalho no arquivo YAML. Ele também é definido em um grupo Gde variáveis e como uma variável na interface do usuário de configurações de pipeline.
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
Quando você define uma variável com o mesmo nome no mesmo escopo, o último valor definido tem precedência.
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
Nota
Quando você definir uma variável no arquivo YAML, não a defina no editor da Web como configurável no momento da fila. No momento, não é possível alterar variáveis definidas no arquivo YAML no momento da fila. Se você precisar que uma variável seja configurável no momento da fila, não a defina no arquivo YAML.
As variáveis são expandidas uma vez quando a execução é iniciada e novamente no início de cada etapa. Por exemplo:
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
Há duas etapas no exemplo anterior. A expansão de $(a) acontece uma vez no início do trabalho, e uma vez no início de cada uma das duas etapas.
Como as variáveis são expandidas no início de um trabalho, você não pode usá-las em uma estratégia. No exemplo a seguir, você não pode usar a variável a para expandir a matriz de trabalho, porque a variável só está disponível no início de cada trabalho expandido.
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
Se a variável a for uma variável de saída de um trabalho anterior, você poderá usá-la em um trabalho futuro.
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
Expansão recursiva
No agente, as variáveis referenciadas usando $( ) sintaxe são expandidas recursivamente.
Por exemplo:
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"