Usar o Data Lake Tools for Visual Studio para se conectar ao Azure HDInsight e executar consultas do Apache Hive
Saiba como usar o Microsoft Azure Data Lake e as Ferramentas do Stream Analytics para Visual Studio (Ferramentas Data Lake). Use a ferramenta para se conectar a clusters Apache Hadoop no Azure HDInsight e enviar consultas do Hive.
Para obter mais informações sobre como usar o HDInsight, consulte Introdução ao HDInsight.
Pode utilizar o Data Lake Tools para Visual Studio para aceder ao Azure Data Lake Analytics e ao HDInsight. Para obter informações sobre o Data Lake Tools, veja Desenvolver scripts U-SQL com o Data Lake Tools para Visual Studio.
Pré-requisitos
Para concluir este artigo e usar o Data Lake Tools for Visual Studio, você precisa dos seguintes itens:
Um cluster do Azure HDInsight. Para criar um cluster HDInsight, consulte Introdução ao uso do Apache Hadoop no Azure HDInsight. Para executar consultas interativas do Apache Hive, você precisa de um cluster de Consulta Interativa do HDInsight.
Visual Studio. A edição da Comunidade do Visual Studio é gratuita. As instruções mostradas aqui são para o Visual Studio 2019.
Instalar as Ferramentas do Data Lake para Visual Studio
Siga as instruções apropriadas para instalar o Data Lake Tools para sua versão do Visual Studio:
Para Visual Studio 2017 ou Visual Studio 2019:
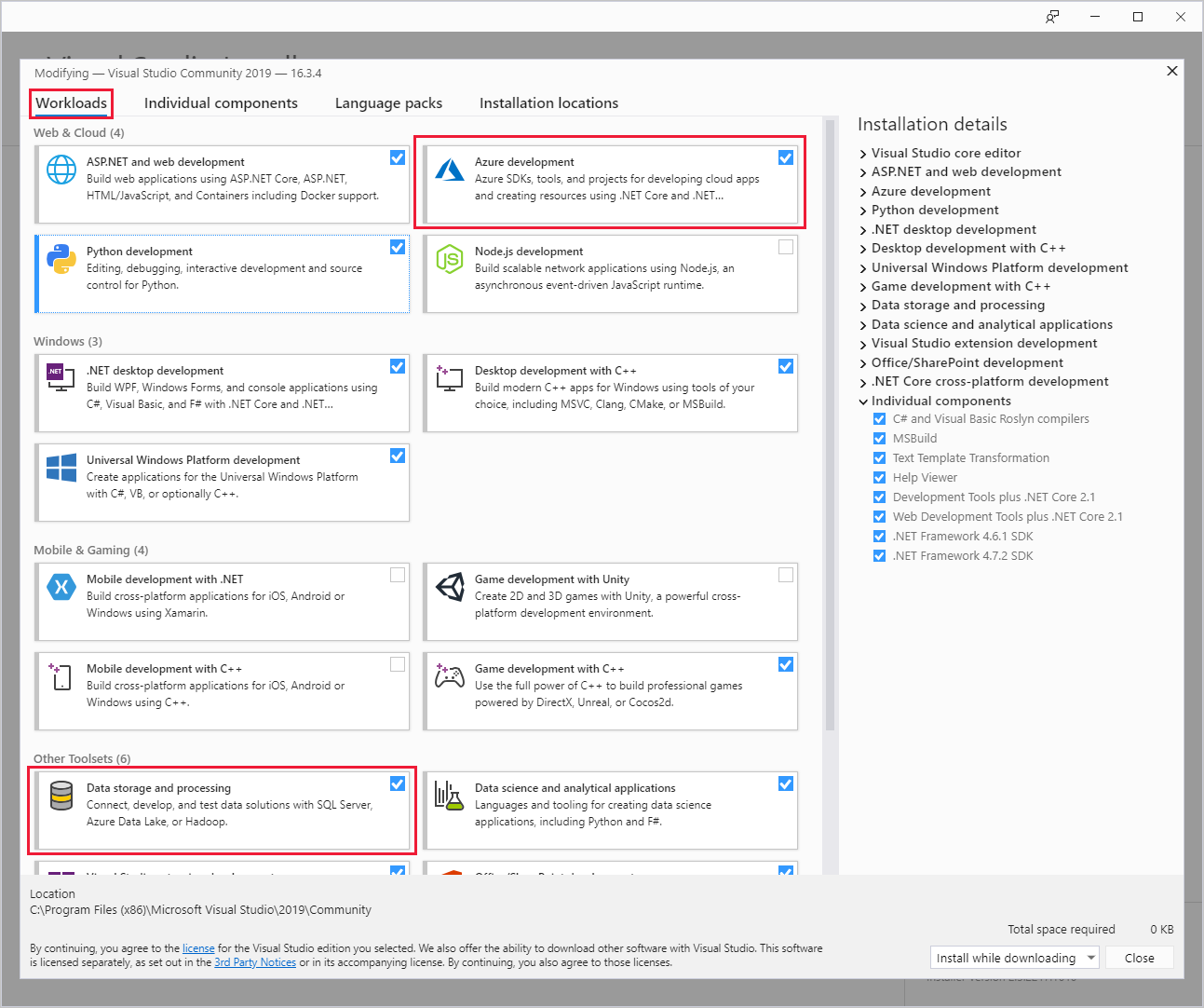
Durante a instalação do Visual Studio, certifique-se de incluir a carga de trabalho de desenvolvimento do Azure ou a carga de trabalho de armazenamento e processamento de dados.
Para instalações existentes do Visual Studio, vá para a barra de menus do IDE e selecione Ferramentas>Obter ferramentas e recursos para abrir o Visual Studio Installer. Na guia Cargas de trabalho, selecione pelo menos a carga de trabalho de desenvolvimento do Azure (em Web & Cloud). Ou selecione a carga de trabalho de armazenamento e processamento de dados (em Outros conjuntos de ferramentas).
Para o Visual Studio 2015:
Faça o download do Data Lake Tools. Escolha a versão do Data Lake Tools que corresponde à sua versão do Visual Studio.
Atualizar ferramentas Data Lake para Visual Studio
Em seguida, atualize as Ferramentas Data Lake para a versão mais recente.
Abra o Visual Studio.
Na janela Iniciar, selecione Continuar sem código.
Na barra de menus IDE do Visual Studio, escolha Extensions>Manage Extensions.
Na caixa de diálogo Gerenciar Extensões , expanda o nó Atualizações .
Se a lista de atualizações disponíveis incluir o Azure Data Lake e as Ferramentas Analíticas de Fluxo, selecione-a. Em seguida, selecione o botão Atualizar . Depois que a caixa de diálogo Baixar e Instalar for exibida e desaparecer, o Visual Studio adicionará a extensão Azure Data Lake e Stream Analytic Tools ao agendamento de atualização.
Feche todas as janelas do Visual Studio. A caixa de diálogo VSIX Installer é exibida.
Selecione Licença para ler os termos de licença e, em seguida, selecione Fechar para retornar à caixa de diálogo Instalador do VSIX.
Selecione Modificar. A instalação da atualização da extensão é iniciada. Depois de um tempo, a caixa de diálogo muda para mostrar que foi feito modificações. Selecione Fechar e reinicie o Visual Studio para concluir a instalação.
Nota
Pode utilizar apenas o Data Lake Tools versão 2.3.0.0 ou posterior para ligar a clusters da Consulta Interativa e executar consultas interativas do Hive.
Ligar a subscrições do Azure
Você pode usar as Ferramentas Data Lake para Visual Studio para se conectar aos clusters HDInsight, fazer algumas operações básicas de gerenciamento e executar consultas do Hive.
Nota
Para obter informações sobre como se conectar a um cluster Hadoop genérico, consulte Como escrever e enviar consultas do Hive usando o Visual Studio.
Ligar a uma subscrição do Azure
Para ligar à sua subscrição do Azure:
Abra o Visual Studio.
Na janela Iniciar, selecione Continuar sem código.
Na barra de menus do IDE, escolha Exibir Gerenciador de>Servidores.
No Gerenciador de Servidores, clique com o botão direito do mouse em Azure, selecione Conectar à Assinatura do Microsoft Azure e conclua o processo de autenticação. No Gerenciador de Servidores, expanda Azure>HDInsight para exibir uma lista de clusters HDInsight existentes.
Se você não tiver clusters, crie um usando o portal do Azure, o Azure PowerShell ou o SDK do HDInsight. Para obter mais informações, consulte Configurar clusters no HDInsight.
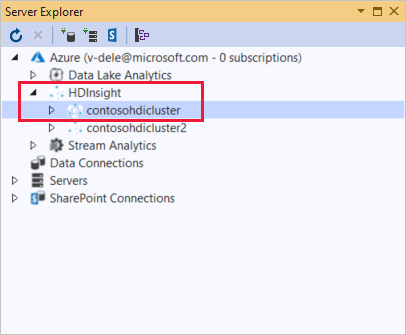
Expanda um cluster do HDInsight. O cluster contém nós para bancos de dados do Hive. Além disso, uma conta de armazenamento padrão, quaisquer contas de armazenamento vinculadas adicionais e o Hadoop Service Log. Pode expandir ainda mais as entidades.
Depois de se ligar à sua subscrição do Azure, pode fazer as tarefas seguintes.
Conectar-se ao Azure a partir do Visual Studio
Ligar-se ao portal do Azure a partir do Visual Studio:
No Gerenciador de Servidores, expanda Azure>HDInsight e selecione seu cluster.
Clique com o botão direito do mouse em um cluster HDInsight e selecione Gerenciar Cluster no portal do Azure.
Ofereça perguntas e comentários do Visual Studio
Para fazer perguntas e/ou fornecer comentários do Visual Studio:
No Gerenciador de Servidores, escolha Azure>HDInsight.
Clique com o botão direito do mouse em HDInsight e selecione Fórum do MSDN para fazer perguntas ou Dar Comentários para enviar comentários.
Vincular ou editar um cluster
Nota
Atualmente, o único tipo de cluster HDInsight ao qual você pode vincular é um tipo Hive.
Para vincular um cluster HDInsight:
Clique com o botão direito do mouse em HDInsight e selecione Vincular um Cluster HDInsight para exibir a caixa de diálogo Vincular um Cluster HDInsight.
Insira um URL de conexão no formulário
https://CLUSTERNAME.azurehdinsight.net. O Nome do Cluster é preenchido automaticamente com a parte do nome do cluster do URL quando acede a outro campo. Em seguida, introduza um Nome de utilizador e uma Palavra-passe e selecione Seguinte.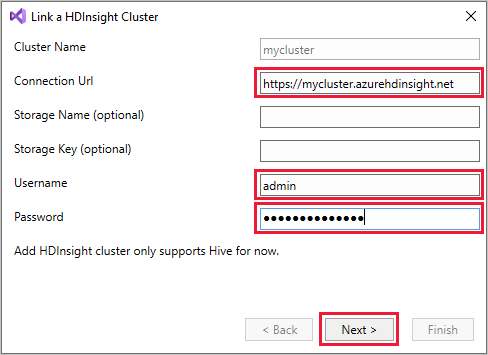
Selecione Concluir. Se a vinculação de cluster for bem-sucedida, o cluster será listado no nó HDInsight .
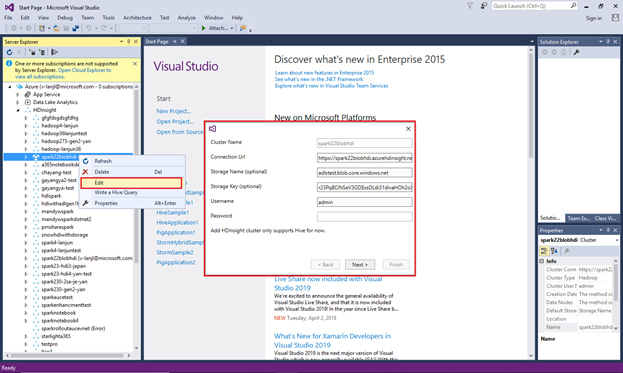
Para atualizar um cluster vinculado, clique com o botão direito do mouse no cluster e selecione Editar. Em seguida, você pode atualizar as informações do cluster.
Explorar recursos ligados
No Explorador de Servidores, pode ver a conta do Storage predefinida e quaisquer contas do Storage ligadas. Se expandir a conta do Storage predefinida, pode ver os contentores incluídos na mesma. A conta do Storage predefinida e o contentor predefinido estão marcados.
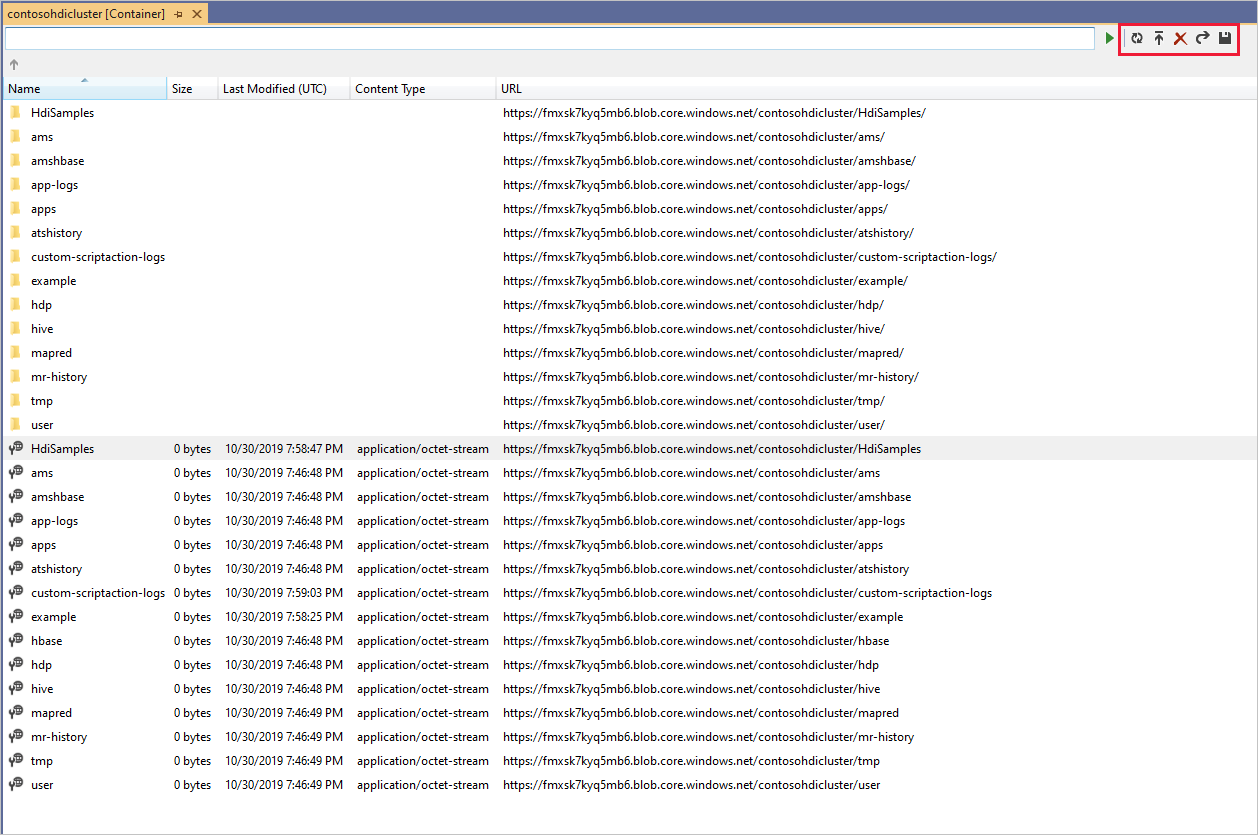
Clique com o botão direito do mouse em um contêiner e selecione Exibir contêiner para exibir o conteúdo do contêiner. Depois de abrir um contêiner, você pode usar os botões da barra de ferramentas para Atualizar a lista de conteúdo, Carregar Blob, Excluir blobs selecionados, Abrir Blob e baixar (Salvar como) blobs selecionados.
Executar consultas interativas do Apache Hive
O Apache Hive é uma infraestrutura de armazém de dados que está incorporada no Hadoop. O Hive é utilizado para resumo de dados, consultas e análises. Pode utilizar o Data Lake Tools para Visual Studio para executar consultas do Hive a partir do Visual Studio. Para obter mais informações sobre o Hive, consulte O que é o Apache Hive e o HiveQL no Azure HDInsight?.
A Consulta Interativa no Azure HDInsight usa o Hive no LLAP no Apache Hive 2.1. O Interactive Query traz interatividade para consultas complexas no estilo de data warehouse em grandes conjuntos de dados armazenados. A execução de consultas do Hive no Interactive Query é muito mais rápida do que os trabalhos em lote tradicionais do Hive.
Nota
Pode executar consultas interativas do Hive apenas quando ligar a um cluster do HDInsight Interactive Query.
Você também pode usar as Ferramentas Data Lake para Visual Studio para ver o que há dentro de um trabalho do Hive. O Data Lake Tools para Visual Studio recolhe e analisa os registos do Yarn de determinadas tarefas do Hive.
No Gerenciador de Servidores, escolha Azure>HDInsight e selecione seu cluster. Este nó é o ponto de partida no Gerenciador de Servidores para as seções a seguir.
Veja hivesampletable
Todos os clusters HDInsight têm uma tabela Hive de exemplo padrão chamada hivesampletable.
No cluster, escolha Hive Databases>default>hivesampletable.
Para visualizar o
hivesampletableesquema:Expanda hivesampletable. Os nomes e tipos de dados das
hivesampletablecolunas são mostrados.Para visualizar os
hivesampletabledados:Clique com o botão direito do mouse em hivesampletable e selecione Exibir as 100 principais linhas. A lista de 100 resultados aparece na janela Hive Table: hivesampletable . Essa ação é equivalente a executar a seguinte consulta do Hive usando o driver ODBC do Hive:
SELECT * FROM hivesampletable LIMIT 100Você pode personalizar a contagem de linhas alterando Número de linhas, você pode escolher 50, 100, 200 ou 1000 linhas na lista suspensa.
Criar tabelas do Hive
Para criar uma tabela do Hive, pode utilizar a GUI ou utilizar consultas do Hive. Para obter informações sobre como usar consultas do Hive, consulte Criar e executar consultas do Hive.
No cluster, escolha Bancos de dados>do Hive padrão.
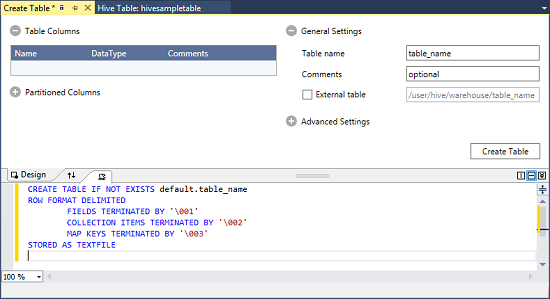
Clique com o botão direito do mouse em padrão e selecione Criar tabela.
Configure a tabela.
Selecione o botão Criar tabela para enviar o trabalho, que cria a nova tabela do Hive.
Criar e executar consultas do Hive
Tem duas opções para criar e executar consultas do Hive:
- Criar consultas ad-hoc
- Criar uma aplicação do Hive
Criar uma consulta ad-hoc
Para criar e executar uma consulta ad-hoc:
Clique com o botão direito do rato no cluster onde pretende executar a consulta e selecione Escrever uma Consulta do Hive.
Insira uma consulta do Hive.
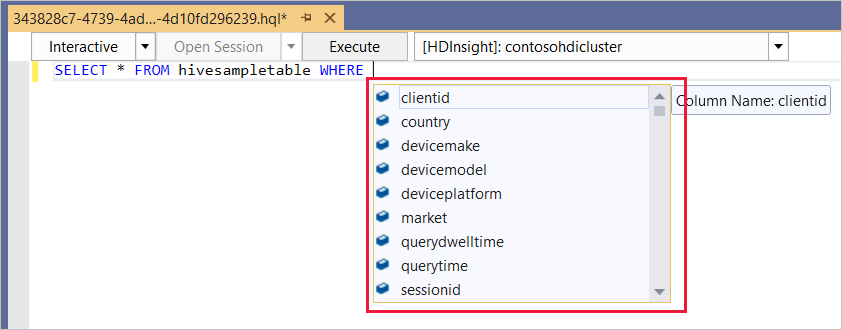
O editor do Hive suporta IntelliSense. O Data Lake Tools para Visual Studio suportam o carregamento de metadados remotos durante a edição do script do Hive. Por exemplo, se você digitar
SELECT * FROM, o IntelliSense listará todos os nomes de tabela sugeridos. Quando é especificado um nome de tabela, o IntelliSense lista os nomes das colunas. As ferramentas suportam quase todas as instruções DML do Hive, subconsultas e os UDFs incorporados.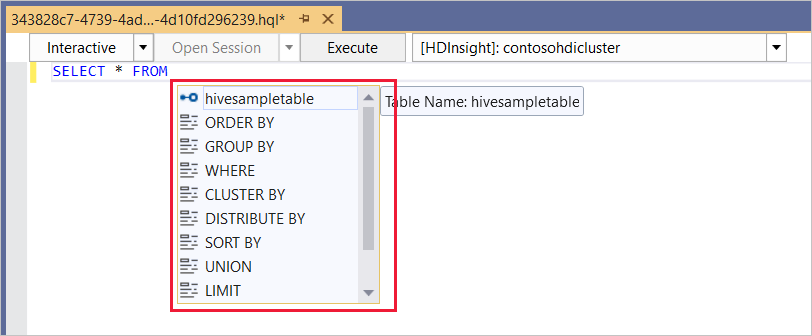
Nota
O IntelliSense sugere apenas os metadados do cluster selecionado na barra de ferramentas do HDInsight.
Aqui está uma consulta de exemplo que você pode usar:
SELECT devicemodel, COUNT(devicemodel) AS deviceCount FROM hivesampletable GROUP BY devicemodel ORDER BY devicemodelEscolha o modo de execução:
Interativo
Na primeira lista suspensa, escolha Interativo e, em seguida, selecione Executar.

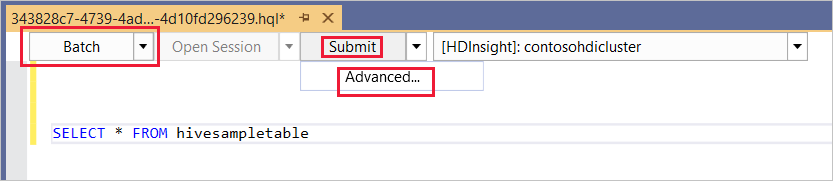
Batch
Na primeira lista suspensa, escolha Lote e, em seguida, selecione Enviar. Ou selecione o ícone suspenso ao lado de Enviar e escolha Avançado.
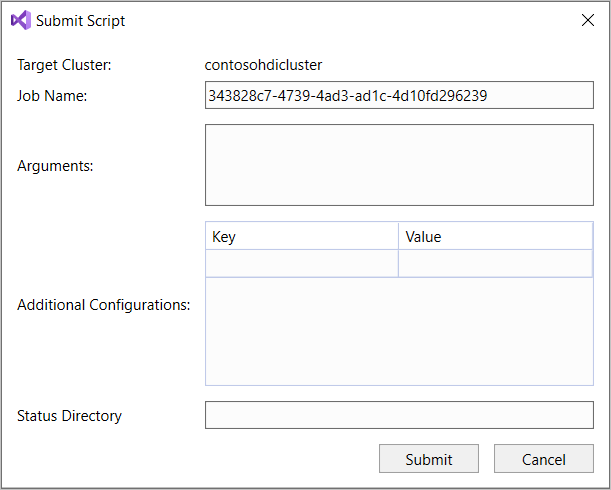
Se você selecionar a opção de envio avançado, a caixa de diálogo Enviar script será exibida. Configure o Nome do Trabalho, Argumentos, Configurações Adicionais e Diretório de Status para o script.
Nota
Não é possível enviar lotes para clusters de Consulta Interativa. Você deve usar o modo interativo.
Criar uma aplicação do Hive
Para criar e executar uma solução do Hive:
Na barra de menus, escolha Arquivo>Novo>Projeto.
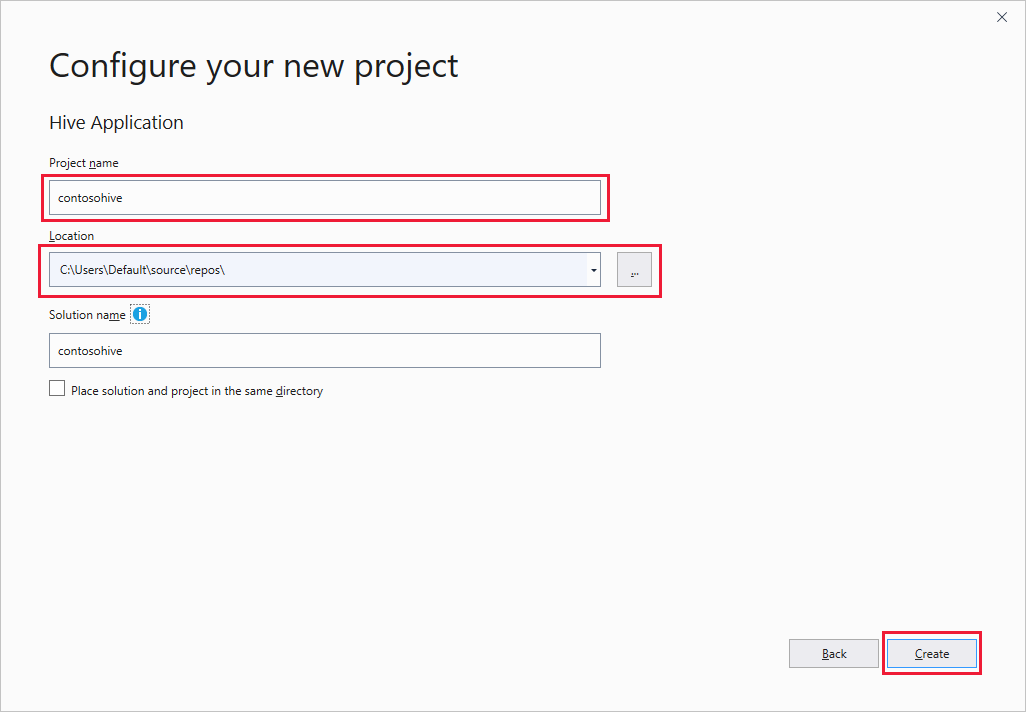
Na janela Criar um novo projeto, selecione a caixa de pesquisa e digite Hive. Em seguida, escolha Hive Application e selecione Next.
Na janela Configurar seu novo projeto, insira um nome de projeto, selecione ou crie o local do projeto e, em seguida, selecione Criar.
No Explorador de Soluções, faça duplo clique em Script.hql para abrir o script.
Ver resumo e saída do trabalho
O resumo do trabalho varia ligeiramente entre o modo Lote e o modo interativo .
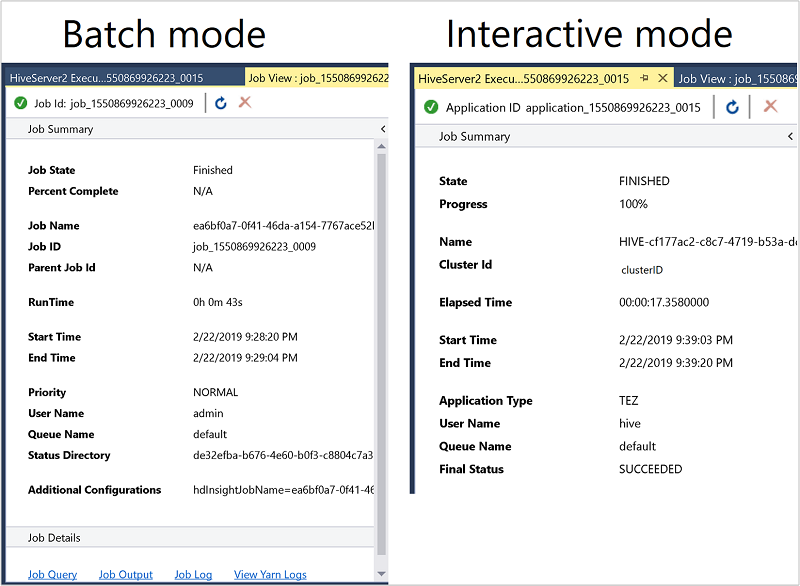
Use o ícone Atualizar para atualizar o status até que o status do trabalho mude para Concluído.
Para obter os detalhes do trabalho no modo Lote, selecione os links na parte inferior para ver a Consulta de Trabalho, a Saída do Trabalho ou o Log de Trabalho, ou para Exibir Logs do Yarn.
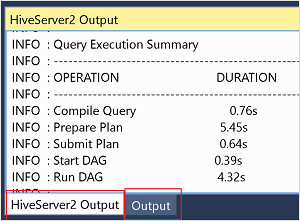
Para obter os detalhes do trabalho no modo interativo , consulte os painéis Saída e Saída do HiveServer2.
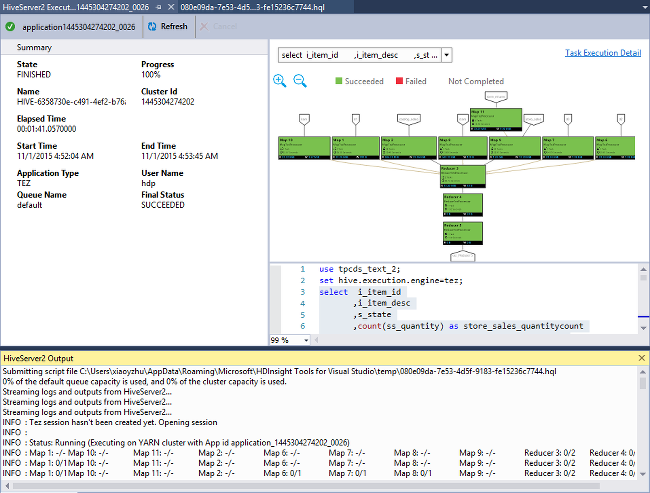
Ver gráfico de trabalho
Atualmente, os gráficos de trabalho são mostrados apenas para trabalhos do Hive que usam Tez como mecanismo de execução. Para obter informações sobre como habilitar o Tez, consulte O que é o Apache Hive e o HiveQL no Azure HDInsight?. Consulte também, Usar Apache Tez em vez de Reduzir Mapas.
Para visualizar todos os operadores dentro do vértice, clique duas vezes nos vértices do gráfico de trabalho. Também pode apontar para um operador específico para ver mais detalhes sobre o operador.
Mesmo que Tez seja especificado como o mecanismo de execução, o gráfico de trabalho pode não aparecer se nenhum aplicativo Tez for iniciado. Essa situação pode ocorrer porque o trabalho não contém instruções DML. Ou porque as declarações DML podem retornar sem iniciar um aplicativo Tez. Por exemplo, SELECT * FROM table1 não iniciará o aplicativo Tez.
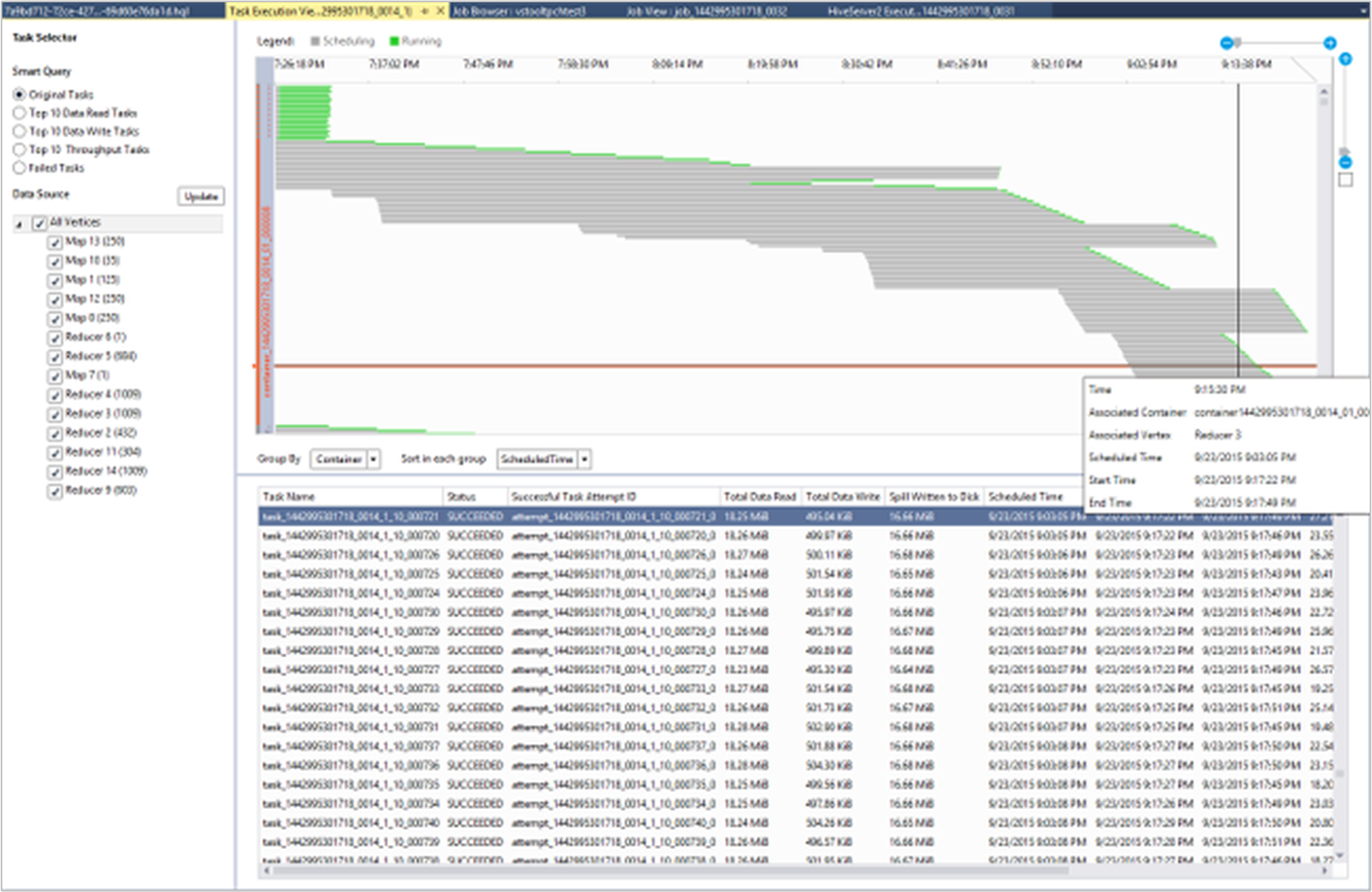
Ver detalhes da execução da tarefa
No gráfico de tarefas, você pode selecionar Detalhes de execução de tarefas para obter informações estruturadas e visualizadas para trabalhos do Hive. Você também pode obter mais detalhes do trabalho. Se ocorrerem problemas de desempenho, pode utilizar a vista para obter mais detalhes sobre o problema. Por exemplo, você pode recuperar informações sobre como cada tarefa opera e informações detalhadas sobre cada tarefa (dados de leitura/gravação, agendamento/hora de início/término e muito mais). Utilize as informações para otimizar as configurações da tarefa ou a arquitetura do sistema, com base nas informações visualizadas.
Ver tarefas do Hive
Pode ver as consultas da tarefa, a saída da tarefa, os registos da tarefa e os registos Yarn para as tarefas do Hive.
Na versão mais recente das ferramentas, você pode ver o que está dentro de seus trabalhos do Hive coletando e exibindo logs do Yarn. Um registo Yarn pode ajudar a investigar problemas de desempenho. Para obter mais informações sobre como o HDInsight coleta logs do Yarn, consulte Access Apache Hadoop YARN application logs.
Para ver tarefas do Hive:
Clique com o botão direito do mouse em um cluster HDInsight e selecione Exibir trabalhos.
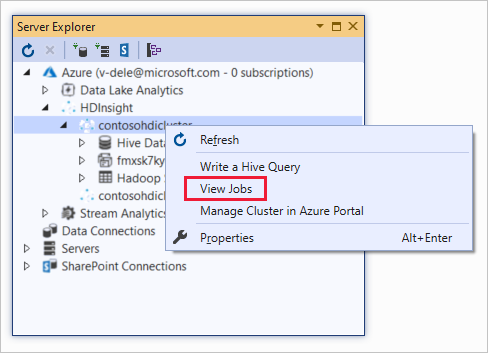
É apresentada uma lista dos trabalhos do Hive executados no cluster.
Selecione uma tarefa. Na janela Resumo do trabalho do Hive, selecione um dos seguintes links:
- Consulta da Tarefa
- Resultado da Tarefa
- Registo da Tarefa
- Log de fios
Executar scripts Apache Pig
Na barra de menus, escolha Arquivo>Novo>Projeto.
Na janela Iniciar, selecione a caixa de pesquisa e digite Pig. Em seguida, selecione Pig Application e selecione Next.
Na janela Configurar seu novo projeto, insira um nome de projeto e selecione ou crie um local para o projeto. Depois, selecione Criar.
No painel Gerenciador de Soluções IDE, clique duas vezes em Script.pig para abrir o script.
Comentários e problemas conhecidos
Foi corrigido um problema no qual os resultados que são iniciados com valores nulos não são apresentados. Se estiver bloqueado neste problema, contacte a equipa de suporte.
O script HQL que o Visual Studio cria é codificado, dependendo da configuração de região local do usuário. O script não é executado corretamente se carregar o script para um cluster como um ficheiro binário.
Próximos passos
Neste artigo, aprendeu a utilizar o pacote do Data Lake Tools para Visual Studio para ligar a clusters do HDInsight a partir do Visual Studio. Também aprendeu a executar uma consulta do Hive.