Varredura e seleção de modelos para previsão no AutoML
Este artigo se concentra em como o AutoML pesquisa e seleciona modelos de previsão. Consulte o artigo de visão geral de métodos para obter mais informações gerais sobre a metodologia de previsão no AutoML. Instruções e exemplos para treinar modelos de previsão no AutoML podem ser encontrados em nosso artigo de configuração do AutoML para previsão de séries temporais .
Varredura de modelos
A tarefa central do AutoML é treinar e avaliar vários modelos e escolher o melhor em relação à métrica primária dada. A palavra "modelo" aqui refere-se tanto à classe de modelo - como ARIMA ou Random Forest - quanto às configurações específicas de hiperparâmetros que distinguem modelos dentro de uma classe. Por exemplo, ARIMA refere-se a uma classe de modelos que compartilham um modelo matemático e um conjunto de pressupostos estatísticos. O treinamento, ou ajuste, de um modelo ARIMA requer uma lista de inteiros positivos que especificam a forma matemática precisa do modelo; estes são os hiperparâmetros. ARIMA(1, 0, 1) e ARIMA(2, 1, 2) têm a mesma classe, mas hiperparâmetros diferentes e, portanto, podem ser ajustados separadamente com os dados de treinamento e avaliados uns contra os outros. O AutoML pesquisa, ou varre, em diferentes classes de modelo e dentro de classes variando hiperparâmetros.
A tabela a seguir mostra os diferentes métodos de varredura de hiperparâmetros que o AutoML usa para diferentes classes de modelo:
| Grupo de classes modelo | Tipo de modelo | Método de varredura de hiperparâmetros |
|---|---|---|
| Ingênuo, Sazonal Ingênuo, Média, Sazonal Médio | Séries cronológicas | Sem varredura dentro da classe devido à simplicidade do modelo |
| Alisamento Exponencial, ARIMA(X) | Séries cronológicas | Pesquisa de grade para varredura dentro da classe |
| Profeta | Regressão | Sem varredura dentro da sala de aula |
| Linear SGD, LARS LASSO, Rede Elástica, K Vizinhos Mais Próximos, Árvore Decisão, Floresta Aleatória, Árvores Extremamente Aleatórias, Árvores Impulsionadas por Gradiente, LightGBM, XGBoost | Regressão | O serviço de recomendação de modelo do AutoML explora dinamicamente espaços de hiperparâmetros |
| PrevisãoTCN | Regressão | Lista estática de modelos seguida de pesquisa aleatória sobre o tamanho da rede, taxa de abandono e taxa de aprendizagem. |
Para obter uma descrição dos diferentes tipos de modelo, consulte a seção de modelos de previsão do artigo de visão geral de métodos.
A quantidade de varredura que o AutoML faz depende da configuração do trabalho de previsão. Você pode especificar os critérios de parada como um limite de tempo ou um limite para o número de ensaios, ou equivalentemente o número de modelos. A lógica de terminação antecipada pode ser usada em ambos os casos para interromper a varredura se a métrica primária não estiver melhorando.
Seleção de modelos
A pesquisa e seleção do modelo de previsão do AutoML prossegue nas três fases a seguir:
- Varrer os modelos de séries cronológicas e selecionar o melhor modelo de cada classe usando métodos de probabilidade penalizada.
- Varrer os modelos de regressão e classificá-los, juntamente com os melhores modelos de séries temporais da fase 1, de acordo com seus valores métricos primários dos conjuntos de validação.
- Crie um modelo de conjunto a partir dos modelos mais bem classificados, calcule sua métrica de validação e classifique-o com os outros modelos.
O modelo com o valor métrico mais bem classificado no final da fase 3 é designado o melhor modelo.
Importante
A fase final de seleção de modelos do AutoML sempre calcula métricas em dados fora da amostra . Ou seja, dados que não foram usados para se adequar aos modelos. Isto ajuda a proteger contra o excesso de ajuste.
O AutoML tem duas configurações de validação - validação cruzada e dados de validação explícitos. No caso de validação cruzada, o AutoML usa a configuração de entrada para criar divisões de dados em dobras de treinamento e validação. A ordem do tempo deve ser preservada nessas divisões, de modo que o AutoML usa a chamada Validação Cruzada de Origem Rolante , que divide a série em dados de treinamento e validação usando um ponto de tempo de origem. Deslizar a origem no tempo gera as dobras de validação cruzada. Cada dobra de validação contém o horizonte seguinte de observações imediatamente após a posição da origem para a dobra dada. Essa estratégia preserva a integridade dos dados das séries temporais e mitiga o risco de vazamento de informações.
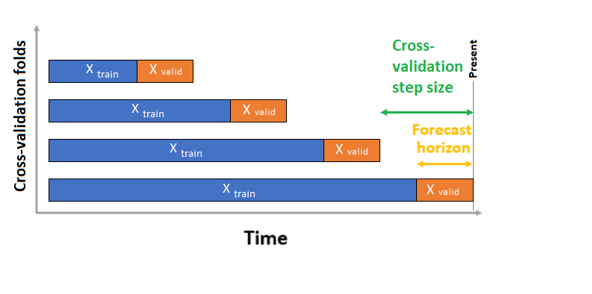
O AutoML segue o procedimento habitual de validação cruzada, treinando um modelo separado em cada dobra e calculando a média das métricas de validação de todas as dobras.
A validação cruzada para trabalhos de previsão é configurada definindo o número de dobras de validação cruzada e, opcionalmente, o número de períodos de tempo entre duas dobras de validação cruzada consecutivas. Consulte o guia de configurações de validação cruzada personalizada para obter mais informações e um exemplo de configuração da validação cruzada para previsão.
Você também pode trazer seus próprios dados de validação. Saiba mais no artigo Configurar divisões de dados e validação cruzada no AutoML (SDK v1).
Próximos passos
- Saiba mais sobre como configurar o AutoML para treinar um modelo de previsão de séries temporais.
- Navegue pelas perguntas frequentes sobre a previsão do AutoML.
- Saiba mais sobre os recursos de calendário para previsão de séries temporais no AutoML.
- Saiba mais sobre como o AutoML usa o aprendizado de máquina para criar modelos de previsão.