Implantação de endpoint on-line para inferência em tempo real
APLICA-SE A: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Este artigo descreve os pontos de extremidade online para inferência em tempo real no Azure Machine Learning. A inferência é o processo de aplicação de novos dados de entrada a um modelo de aprendizado de máquina para gerar saídas. O Azure Machine Learning permite que você execute inferências em tempo real em dados usando modelos implantados em pontos de extremidade online. Embora essas saídas sejam normalmente chamadas de previsões, você pode usar a inferência para gerar saídas para outras tarefas de aprendizado de máquina, como classificação e clustering.
Pontos finais online
Os pontos de extremidade online implantam modelos em um servidor Web que pode retornar previsões sob o protocolo HTTP. Os endpoints online podem operacionalizar modelos para inferência em tempo real em solicitações síncronas de baixa latência e são melhor usados quando:
- Você tem requisitos de baixa latência.
- O seu modelo pode responder ao pedido num período de tempo relativamente curto.
- As entradas do seu modelo cabem na carga HTTP da solicitação.
- Você precisa aumentar o número de solicitações.
Para definir um ponto de extremidade, você deve especificar:
- Nome do ponto final. Esse nome deve ser exclusivo na região do Azure. Para outros requisitos de nomenclatura, consulte Pontos de extremidade online e pontos de extremidade em lote do Azure Machine Learning.
- Modo de autenticação. Você pode escolher entre o modo de autenticação baseada em chave, o modo de autenticação baseada em token do Azure Machine Learning ou a autenticação baseada em token do Microsoft Entra para o ponto de extremidade. Para obter mais informações sobre autenticação, consulte Autenticar clientes para pontos de extremidade online.
Pontos finais online geridos
Os pontos de extremidade online gerenciados implantam seus modelos de aprendizado de máquina de maneira conveniente e pronta para uso e são a maneira recomendada de usar os pontos de extremidade online do Azure Machine Learning. Os pontos finais online geridos funcionam com computadores GPU e CPU avançados no Azure de forma dimensionável e totalmente gerida.
Para liberá-lo da sobrecarga de configurar e gerenciar a infraestrutura subjacente, esses pontos de extremidade também cuidam de servir, dimensionar, proteger e monitorar seus modelos. Para saber como definir pontos de extremidade online gerenciados, consulte Definir o ponto de extremidade.
Pontos de extremidade online gerenciados vs Instâncias de Contêiner do Azure ou Serviço Kubernetes do Azure (AKS) v1
Os pontos de extremidade online gerenciados são a maneira recomendada de usar pontos de extremidade online no Azure Machine Learning. A tabela a seguir destaca os principais atributos dos pontos de extremidade online gerenciados em comparação com as Instâncias de Contêiner do Azure e as soluções do Serviço Kubernetes do Azure (AKS) v1.
| Atributos | Pontos de extremidade online gerenciados (v2) | Instâncias de contêiner ou AKS (v1) |
|---|---|---|
| Segurança/isolamento de rede | Controlo fácil de entrada/saída com alternância rápida | Rede virtual não suportada ou requer configuração manual complexa |
| Serviço gerido | • Provisionamento/dimensionamento de computação totalmente gerenciado • Configuração de rede para prevenção de exfiltração de dados • Atualização do sistema operacional host, implementação controlada de atualizações in-loco |
• O dimensionamento é limitado • O usuário deve gerenciar a configuração ou atualização da rede |
| Conceito de endpoint/implantação | A distinção entre ponto de extremidade e implantação permite cenários complexos, como a implantação segura de modelos | Nenhum conceito de ponto final |
| Diagnóstico e monitorização | • Possível depuração de ponto final local com Docker e Visual Studio Code • Análise avançada de métricas e logs com gráfico/consulta para comparar entre implantações • Detalhamento de custos até o nível de implantação |
Sem depuração local fácil |
| Escalabilidade | Dimensionamento elástico e automático (não vinculado pelo tamanho padrão do cluster) | • As instâncias de contêiner não são escaláveis • O AKS v1 suporta apenas escala em cluster e requer configuração de escalabilidade |
| Preparação para empresas | Link privado, chaves gerenciadas pelo cliente, ID do Microsoft Entra, gerenciamento de cotas, integração de cobrança, contrato de nível de serviço (SLA) | Não suportado |
| Recursos avançados de ML | • Modelo de recolha de dados • Monitorização de modelos • Modelo campeão-desafiante, lançamento seguro, espelhamento de tráfego • Extensibilidade responsável da IA |
Não suportado |
Pontos de extremidade online gerenciados vs pontos de extremidade online do Kubernetes
Se você preferir usar o Kubernetes para implantar seus modelos e servir endpoints, e estiver confortável com o gerenciamento de requisitos de infraestrutura, poderá usar os endpoints online do Kubernetes. Esses endpoints permitem que você implante modelos e sirva endpoints online com CPUs ou GPUs em seu cluster Kubernetes totalmente configurado e gerenciado em qualquer lugar.
Os endpoints online gerenciados podem ajudar a simplificar seu processo de implantação e fornecer os seguintes benefícios em relação aos endpoints online do Kubernetes:
Gestão automática de infraestruturas
- Provisiona a computação e hospeda o modelo. Basta especificar o tipo de máquina virtual (VM) e as configurações de escala.
- Atualiza e corrige a imagem subjacente do sistema operacional do host.
- Executa a recuperação do nó se houver uma falha do sistema.
Monitorização e registos
- Capacidade de monitorar a disponibilidade, o desempenho e o SLA do modelo usando a integração nativa com o Azure Monitor.
- Facilidade de depuração de implantações usando logs e integração nativa com o Log Analytics.

A visualização de análise de custos permite monitorar os custos no nível do ponto final e da implantação.

Nota
Os pontos de extremidade online gerenciados são baseados na computação do Azure Machine Learning. Quando você usa um endpoint online gerenciado, paga pelas taxas de computação e rede. Não há sobretaxa. Para obter mais informações sobre preços, consulte a calculadora de preços do Azure.
Se você usar uma rede virtual do Azure Machine Learning para proteger o tráfego de saída do ponto de extremidade online gerenciado, será cobrado pelo link privado do Azure e pelas regras de saída FQDN (nome de domínio totalmente qualificado) que a rede virtual gerenciada usa. Para obter mais informações, consulte Preços para rede virtual gerenciada.


A tabela a seguir destaca as principais diferenças entre endpoints online gerenciados e endpoints online do Kubernetes.
| Pontos finais online geridos | Pontos finais online do Kubernetes (AKS v2) | |
|---|---|---|
| Utilizadores recomendados | Utilizadores que desejam uma implementação do modelo gerido e uma experiência melhorada do MLOps | Utilizadores que preferem o Kubernetes e podem autogerir requisitos de infraestrutura |
| Provisionamento de nó | Provisionamento, atualização e remoção de computação gerenciada | Responsabilidade do utilizador |
| Manutenção de nós | Atualizações de imagem do sistema operacional host gerenciado e proteção de segurança | Responsabilidade do utilizador |
| Dimensionamento de cluster (dimensionamento) | Manual gerenciado e dimensionamento automático com suporte ao provisionamento adicional de nós | Dimensionamento manual e automático, suportando o dimensionamento do número de réplicas dentro de limites fixos de cluster |
| Tipo de computação | Gerido pelo serviço | Cluster Kubernetes gerenciado pelo cliente |
| Identidade gerida | Suportado | Suportado |
| Rede virtual | Suportado através de isolamento de rede gerido | Responsabilidade do utilizador |
| Monitoramento e registro prontos para uso | Azure Monitor e Log Analytics alimentado, incluindo métricas-chave e tabelas de log para pontos de extremidade e implantações | Responsabilidade do utilizador |
| Registro em log com o Application Insights (legado) | Suportado | Suportado |
| Visualização de custo | Detalhado para o endpoint/nível de implantação | Nível do cluster |
| Custos aplicados a | Máquinas virtuais (VMs) atribuídas à implantação | VMs atribuídas ao cluster |
| Tráfego espelhado | Suportado | Não suportado |
| Implantação sem código | Suporta modelos MLflow e Triton | Suporta modelos MLflow e Triton |
Implantações on-line
Uma implantação é um conjunto de recursos e cálculos necessários para hospedar o modelo que faz a inferência. Um único ponto de extremidade pode conter várias implantações com configurações diferentes. Essa configuração ajuda a dissociar a interface apresentada pelo ponto de extremidade dos detalhes de implementação presentes na implantação. Um ponto de extremidade online tem um mecanismo de roteamento que pode direcionar solicitações para implantações específicas no ponto de extremidade.
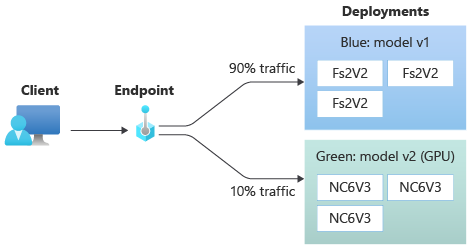
O diagrama a seguir mostra um ponto de extremidade online que tem duas implantações, azul e verde. A implantação azul usa VMs com uma SKU de CPU e executa a versão 1 de um modelo. A implantação verde usa VMs com uma GPU SKU e executa a versão 2 do modelo. O ponto de extremidade é configurado para rotear 90% do tráfego de entrada para a implantação azul, enquanto a implantação verde recebe os 10% restantes.
Para implantar um modelo, você deve ter:
Arquivos de modelo ou o nome e a versão de um modelo já registrado em seu espaço de trabalho.
Código de script de pontuação que executa o modelo em uma determinada solicitação de entrada.
O script de pontuação recebe dados enviados a um serviço Web implantado e os passa para o modelo. Em seguida, o script executa o modelo e retorna sua resposta ao cliente. O script de pontuação é específico para o seu modelo e deve entender os dados que o modelo espera como entrada e retorna como saída.
Um ambiente para executar seu modelo. O ambiente pode ser uma imagem do Docker com dependências do Conda ou um Dockerfile.
Configurações para especificar o tipo de instância e a capacidade de dimensionamento.
Para saber como implantar pontos de extremidade online usando a CLI do Azure, o SDK do Python, o estúdio do Azure Machine Learning ou um modelo ARM, consulte Implantar um modelo de aprendizado de máquina usando um ponto de extremidade online.
Principais atributos de uma implantação
A tabela a seguir descreve os principais atributos de uma implantação:
| Atributo | Description |
|---|---|
| Name | O nome da implantação. |
| Nome do ponto final | O nome do ponto de extremidade sob o qual criar a implantação. |
| Modelo | O modelo a ser usado para a implantação. Esse valor pode ser uma referência a um modelo versionado existente no espaço de trabalho ou uma especificação de modelo embutido. Para obter mais informações sobre como controlar e especificar o caminho para seu modelo, consulte Especificar modelo a ser implantado para uso no ponto de extremidade online. |
| Caminho do código | O caminho para o diretório no ambiente de desenvolvimento local que contém todo o código-fonte Python para pontuar o modelo. Você pode usar diretórios e pacotes aninhados. |
| Roteiro de pontuação | O caminho relativo para o arquivo de pontuação no diretório do código-fonte. Este código Python deve ter uma init() função e uma run() função. A init() função é chamada depois que o modelo é criado ou atualizado, por exemplo, para armazenar o modelo em cache na memória. A run() função é chamada a cada invocação do ponto final para fazer a pontuação e previsão reais. |
| Environment | O ambiente para hospedar o modelo e o código. Esse valor pode ser uma referência a um ambiente versionado existente no espaço de trabalho ou uma especificação de ambiente embutido. |
| Tipo de instância | O tamanho da VM a ser usado para a implantação. Para obter a lista de tamanhos suportados, consulte Lista de SKU de pontos de extremidade online gerenciados. |
| Contagem de instâncias | O número de instâncias a serem usadas para a implantação. Baseie o valor na carga de trabalho esperada. Para alta disponibilidade, defina o valor como pelo menos 3. O sistema reserva um extra de 20% para a realização de upgrades. Para obter mais informações, consulte Alocação de cota de VM para implantações. |
Notas para implantações online
A implantação pode fazer referência ao modelo e à imagem de contêiner definidos no Ambiente a qualquer momento, por exemplo, quando as instâncias de implantação passam por patches de segurança ou outras operações de recuperação. Se você usar um modelo registrado ou uma imagem de contêiner no Registro de Contêiner do Azure para implantação e, posteriormente, remover o modelo ou a imagem de contêiner, as implantações que dependem desses ativos poderão falhar quando ocorrer uma nova geração de imagens. Se você remover o modelo ou a imagem de contêiner, certifique-se de recriar ou atualizar as implantações dependentes com um modelo ou imagem de contêiner alternativo.
O registro de contêiner ao qual o ambiente se refere pode ser privado somente se a identidade do ponto de extremidade tiver permissão para acessá-lo por meio da autenticação do Microsoft Entra e do RBAC (controle de acesso baseado em função) do Azure. Pelo mesmo motivo, não há suporte para registros privados do Docker que não sejam o Registro de Contêiner.
A Microsoft corrige regularmente as imagens base para vulnerabilidades de segurança conhecidas. Você precisa reimplantar seu ponto de extremidade para usar a imagem corrigida. Se fornecer a sua própria imagem, é responsável por atualizá-la. Para obter mais informações, consulte Correção de imagem.
Alocação de cota de VM para implantação
Para pontos de extremidade online gerenciados, o Aprendizado de Máquina do Azure reserva 20% de seus recursos de computação para executar atualizações em algumas SKUs de VM. Se você solicitar um determinado número de instâncias para essas SKUs de VM em uma implantação, deverá ter uma cota disponível para ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU evitar obter um erro. Por exemplo, se você solicitar 10 instâncias de uma VM Standard_DS3_v2 (que vem com quatro núcleos) em uma implantação, deverá ter uma cota para 48 núcleos (12 instances * 4 cores) disponível. Essa cota extra é reservada para operações iniciadas pelo sistema, como atualizações do sistema operacional e recuperação de VM, e não incorrerá em custo, a menos que essas operações sejam executadas.
Existem certas VM SKUs que estão isentas de reserva de cota extra. Para exibir a lista completa, consulte Lista de SKU de pontos de extremidade online gerenciados. Para ver o seu uso e solicitar aumentos de cota, consulte Exibir seu uso e cotas no portal do Azure. Para ver o custo de execução de um endpoint online gerenciado, consulte Exibir custos de um endpoint online gerenciado.
Pool de cotas compartilhadas
O Azure Machine Learning fornece um pool de cotas compartilhadas a partir do qual os usuários em várias regiões podem acessar a cota para executar testes por um tempo limitado, dependendo da disponibilidade. Quando você usa o estúdio para implantar modelos Llama-2, Phi, Nemotron, Mistral, Dolly e Deci-DeciLM do catálogo de modelos para um ponto de extremidade online gerenciado, o Aprendizado de Máquina do Azure permite que você acesse seu pool de cotas compartilhadas por um curto período de tempo para que você possa executar testes. Para obter mais informações sobre o pool de cotas compartilhadas, consulte Cota compartilhada do Azure Machine Learning.
Para implantar modelos Llama-2, Phi, Nemotron, Mistral, Dolly e Deci-DeciLM do catálogo de modelos usando a cota compartilhada, você deve ter uma assinatura do Enterprise Agreement. Para obter mais informações sobre como usar a cota compartilhada para implantação de ponto de extremidade online, consulte Como implantar modelos básicos usando o estúdio.
Para obter mais informações sobre cotas e limites para recursos no Azure Machine Learning, consulte Gerenciar e aumentar cotas e limites para recursos com o Azure Machine Learning.
Implantação para codificadores e não codificadores
O Azure Machine Learning dá suporte à implantação de modelo em pontos de extremidade online para codificadores e não codificadores, fornecendo opções para implantação sem código, implantação de baixo código e implantação de BYOC (Bring Your Own Container).
- A implantação sem código fornece inferência pronta para uso para estruturas comuns como scikit-learn, TensorFlow, PyTorch e Open Neural Network Exchange (ONNX) via MLflow e Triton.
- A implantação low-code permite que você forneça código mínimo junto com seu modelo de aprendizado de máquina para implantação.
- A implantação do BYOC permite que você traga praticamente todos os contêineres para executar seu ponto de extremidade online. Você pode usar todos os recursos da plataforma Azure Machine Learning, como dimensionamento automático, GitOps, depuração e distribuição segura para gerenciar seus pipelines de MLOps.
A tabela a seguir destaca os principais aspetos das opções de implantação online:
| Sem código | Low-code | BYOC | |
|---|---|---|---|
| Resumo | Usa inferência pronta para uso para estruturas populares como scikit-learn, TensorFlow, PyTorch e ONNX, via MLflow e Triton. Para obter mais informações, consulte Implantar modelos MLflow em pontos de extremidade online. | Usa imagens seguras e publicadas publicamente para estruturas populares, com atualizações a cada duas semanas para resolver vulnerabilidades. Você fornece script de pontuação e/ou dependências do Python. Para obter mais informações, consulte Ambientes curados do Azure Machine Learning. | Você fornece sua pilha completa por meio do suporte do Azure Machine Learning para imagens personalizadas. Para obter mais informações, consulte Usar um contêiner personalizado para implantar um modelo em um ponto de extremidade online. |
| Imagem de base personalizada | Nenhum. Os ambientes com curadoria fornecem a imagem base para fácil implantação. | Você pode usar uma imagem selecionada ou sua imagem personalizada. | Traga um local de imagem de contêiner acessível, como docker.io, Registro de Contêiner ou Registro de Artefato da Microsoft, ou um Dockerfile que você pode criar/enviar por push com o Registro de Contêiner para seu contêiner. |
| Dependências personalizadas | Nenhum. Os ambientes com curadoria fornecem dependências para fácil implantação. | Traga o ambiente do Azure Machine Learning no qual o modelo é executado, seja uma imagem do Docker com dependências Conda ou um dockerfile. | As dependências personalizadas são incluídas na imagem do contêiner. |
| Código personalizado | Nenhum. O script de pontuação é gerado automaticamente para facilitar a implantação. | Traga o seu guião de pontuação. | O script de pontuação é incluído na imagem do contêiner. |
Nota
As execuções do AutoML criam um script de pontuação e dependências automaticamente para os usuários. Para implantação sem código, você pode implantar qualquer modelo AutoML sem criar outro código. Para implantação low-code, você pode modificar scripts gerados automaticamente de acordo com suas necessidades de negócios. Para saber como implantar com modelos AutoML, consulte Como implantar um modelo AutoML em um ponto de extremidade online.
Depuração de ponto de extremidade on-line
Se possível, teste seu ponto de extremidade localmente para validar e depurar seu código e configuração antes de implantar no Azure. A CLI do Azure e o SDK do Python dão suporte a pontos de extremidade e implantações locais, enquanto o estúdio do Azure Machine Learning e os modelos ARM não oferecem suporte a pontos de extremidade ou implantações locais.
O Azure Machine Learning fornece as seguintes maneiras de depurar pontos de extremidade online localmente e usando logs de contêiner:
- Depuração local com o servidor HTTP de inferência do Azure Machine Learning
- Depuração local com ponto de extremidade local
- Depuração local com ponto de extremidade local e Visual Studio Code
- Depuração com logs de contêiner
Depuração local com o servidor HTTP de inferência do Azure Machine Learning
Você pode depurar seu script de pontuação localmente usando o servidor HTTP de inferência do Aprendizado de Máquina do Azure. O servidor HTTP é um pacote Python que expõe sua função de pontuação como um ponto de extremidade HTTP e encapsula o código e as dependências do servidor Flask em um único pacote.
O Azure Machine Learning inclui um servidor HTTP nas imagens pré-criadas do Docker para inferência usada para implantar um modelo. Usando apenas o pacote, você pode implantar o modelo localmente para produção e também pode validar facilmente seu script de pontuação de entrada em um ambiente de desenvolvimento local. Se houver um problema com o script de pontuação, o servidor retornará um erro e o local onde o erro ocorreu. Você também pode usar o Visual Studio Code para depurar com o servidor HTTP de inferência do Azure Machine Learning.
Gorjeta
Você pode usar o pacote Python do servidor HTTP de inferência do Azure Machine Learning para depurar seu script de pontuação localmente sem o Docker Engine. A depuração com o servidor de inferência ajuda você a depurar o script de pontuação antes de implantar em pontos de extremidade locais, para que você possa depurar sem ser afetado pelas configurações do contêiner de implantação.
Para obter mais informações sobre depuração com o servidor HTTP, consulte Script de pontuação de depuração com o servidor HTTP de inferência do Azure Machine Learning.
Depuração local com ponto de extremidade local
Para depuração local, você precisa de um modelo implantado em um ambiente Docker local. Você pode usar essa implantação local para testar e depurar antes da implantação na nuvem.
Para implantar localmente, você precisa do Docker Engine instalado e em execução. Em seguida, o Azure Machine Learning cria uma imagem local do Docker para imitar a imagem online. O Azure Machine Learning cria e executa implantações para você localmente e armazena em cache a imagem para iterações rápidas.
Gorjeta
Se o Docker Engine não iniciar quando o computador for iniciado, você poderá solucionar problemas do Docker Engine. Você pode usar ferramentas do lado do cliente, como o Docker Desktop , para depurar o que acontece no contêiner.
A depuração local normalmente envolve as seguintes etapas:
- Primeiro, verifique se a implantação local foi bem-sucedida.
- Em seguida, invoque o ponto de extremidade local para inferência.
- Finalmente, revise os logs de saída para a
invokeoperação.
Os pontos de extremidade locais têm as seguintes limitações:
Não há suporte para regras de trânsito, autenticação ou configurações de teste.
Suporte para apenas uma implantação por ponto de extremidade.
Suporte para arquivos de modelo local e ambiente apenas com arquivo conda local.
Para testar modelos registrados, primeiro baixe-os usando CLI ou SDK e, em seguida, use
pathna definição de implantação para fazer referência à pasta pai.Para testar ambientes registrados, verifique o contexto do ambiente no estúdio do Azure Machine Learning e prepare um arquivo conda local para usar.
Para obter mais informações sobre depuração local, consulte Implantar e depurar localmente usando um ponto de extremidade local.
Depuração local com ponto de extremidade local e Visual Studio Code (visualização)
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Assim como na depuração local, você precisa ter o mecanismo do Docker instalado e em execução e, em seguida, implantar um modelo no ambiente local do Docker. Depois de ter uma implantação local, os pontos de extremidade locais do Aprendizado de Máquina do Azure usam contêineres de desenvolvimento do Docker e do Visual Studio Code (contêineres de desenvolvimento) para criar e configurar um ambiente de depuração local.
Com contêineres de desenvolvimento, você pode usar recursos do Visual Studio Code, como depuração interativa de dentro de um contêiner do Docker. Para obter mais informações sobre como depurar pontos de extremidade online interativamente no Visual Studio Code, consulte Depurar pontos de extremidade online localmente no Visual Studio Code.
Depuração com logs de contêiner
Você não pode obter acesso direto a uma VM onde um modelo é implantado, mas pode obter logs dos seguintes contêineres que estão sendo executados na VM:
- O log do console do servidor de inferência contém a saída das funções de impressão/registro do seu script de pontuação score.py código.
- Os logs do inicializador de armazenamento contêm informações sobre se os dados de código e modelo baixados com êxito para o contêiner. O contêiner é executado antes que o contêiner do servidor de inferência comece a ser executado.
Para obter mais informações sobre depuração com logs de contêiner, consulte Obter logs de contêiner.
Roteamento e espelhamento de tráfego para implantações online
Um único ponto de extremidade online pode ter várias implantações. À medida que o ponto de extremidade recebe solicitações de tráfego de entrada, ele pode rotear porcentagens de tráfego para cada implantação, como na estratégia de implantação nativa azul/verde. O ponto de extremidade também pode espelhar ou copiar o tráfego de uma implantação para outra, chamado espelhamento de tráfego ou sombreamento.
Roteamento de tráfego para implantação azul/verde
A implantação azul/verde é uma estratégia de implantação que permite implantar uma nova implantação verde para um pequeno subconjunto de usuários ou solicitações antes de implementá-la completamente. O ponto de extremidade pode implementar o balanceamento de carga para alocar determinadas porcentagens do tráfego para cada implantação, com a alocação total em todas as implantações somando até 100%.
Gorjeta
Uma solicitação pode ignorar o balanceamento de carga de tráfego configurado incluindo um cabeçalho HTTP de azureml-model-deployment. Defina o valor do cabeçalho como o nome da implantação para a qual você deseja que a solicitação seja roteada.
A imagem a seguir mostra as configurações no estúdio do Azure Machine Learning para alocar tráfego entre uma implantação azul e verde.
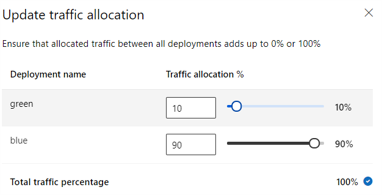
A alocação de tráfego anterior roteia 10% do tráfego para a implantação verde e 90% do tráfego para a implantação azul, conforme mostrado na imagem a seguir.
Espelhamento de tráfego para implantações online
O ponto de extremidade também pode espelhar ou copiar o tráfego de uma implantação para outra. Você pode usar o espelhamento de tráfego, também chamado de teste de sombra, quando quiser testar uma nova implantação com tráfego de produção sem afetar os resultados que os clientes recebem das implantações existentes.
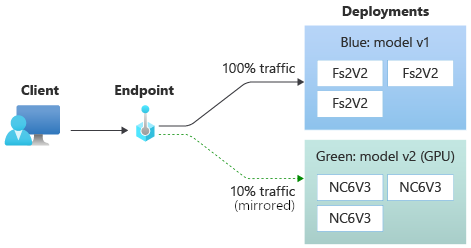
Por exemplo, você pode implementar uma implantação azul/verde em que 100% do tráfego é roteado para azul e 10% é espelhado para a implantação verde. Os resultados do tráfego espelhado para a implantação verde não são retornados aos clientes, mas as métricas e os logs são registrados.
Para obter mais informações sobre como usar o espelhamento de tráfego, consulte Executar a distribuição segura de novas implantações para inferência em tempo real.
Mais recursos de endpoint online
As seções a seguir descrevem outros recursos dos pontos de extremidade online do Azure Machine Learning.
Autenticação e encriptação
- Autenticação: Chave e tokens do Azure Machine Learning
- Identidade gerenciada: atribuído pelo usuário e atribuído pelo sistema
- Secure socket layer (SSL) por padrão para invocação de ponto de extremidade
Dimensionamento automático
O dimensionamento automático executa a quantidade certa de recursos para processar a carga da aplicação. Os pontos de extremidade gerenciados dão suporte ao dimensionamento automático por meio da integração com o recurso de dimensionamento automático do Azure Monitor. Você pode configurar o dimensionamento baseado em métricas, como a utilização >da CPU 70%, o dimensionamento baseado em programação, como regras de horário comercial de pico, ou ambos.

Para obter mais informações, consulte Autoscale online endpoints in Azure Machine Learning.
Isolamento de rede gerenciado
Ao implantar um modelo de aprendizado de máquina em um ponto de extremidade online gerenciado, você pode proteger a comunicação com o ponto de extremidade online usando pontos de extremidade privados. Você pode configurar a segurança para solicitações de pontuação de entrada e comunicações de saída separadamente.
As comunicações de entrada usam o ponto de extremidade privado do espaço de trabalho do Azure Machine Learning, enquanto as comunicações de saída usam pontos de extremidade privados criados para a rede virtual gerenciada do espaço de trabalho. Para obter mais informações, consulte Isolamento de rede com pontos de extremidade online gerenciados.
Monitoramento de endpoints e implantações on-line
Os pontos de extremidade do Azure Machine Learning integram-se ao Azure Monitor. A integração do Azure Monitor permite exibir métricas em gráficos, configurar alertas, consultar tabelas de log e usar o Application Insights para analisar eventos de contêineres de usuário. Para obter mais informações, consulte Monitorar pontos de extremidade online.
Injeção secreta em implantações online (visualização)
A injeção secreta para uma implantação online envolve recuperar segredos, como chaves de API, de armazenamentos secretos e injetá-los no contêiner do usuário que é executado dentro da implantação. Para fornecer consumo secreto seguro para o servidor de inferência que executa o script de pontuação ou a pilha de inferência em sua implantação BYOC, você pode usar variáveis de ambiente para acessar segredos.
Você mesmo pode injetar segredos usando identidades gerenciadas ou pode usar o recurso de injeção secreta. Para obter mais informações, consulte Injeção secreta em pontos de extremidade online (visualização).
Conteúdos relacionados
- Implantar e pontuar um modelo de aprendizado de máquina usando um ponto de extremidade online
- Pontos finais de lote
- Proteja seus endpoints online gerenciados com isolamento de rede
- Implantar modelos com REST
- Monitorizar pontos finais online
- Exibir custos de um ponto de extremidade online gerenciado do Azure Machine Learning
- Gerenciar e aumentar cotas e limites de recursos com o Azure Machine Learning