Avalie os sistemas de IA usando o painel de IA Responsável
Implementar IA responsável na prática requer engenharia rigorosa. Mas a engenharia rigorosa pode ser tediosa, manual e demorada sem as ferramentas e a infraestrutura certas.
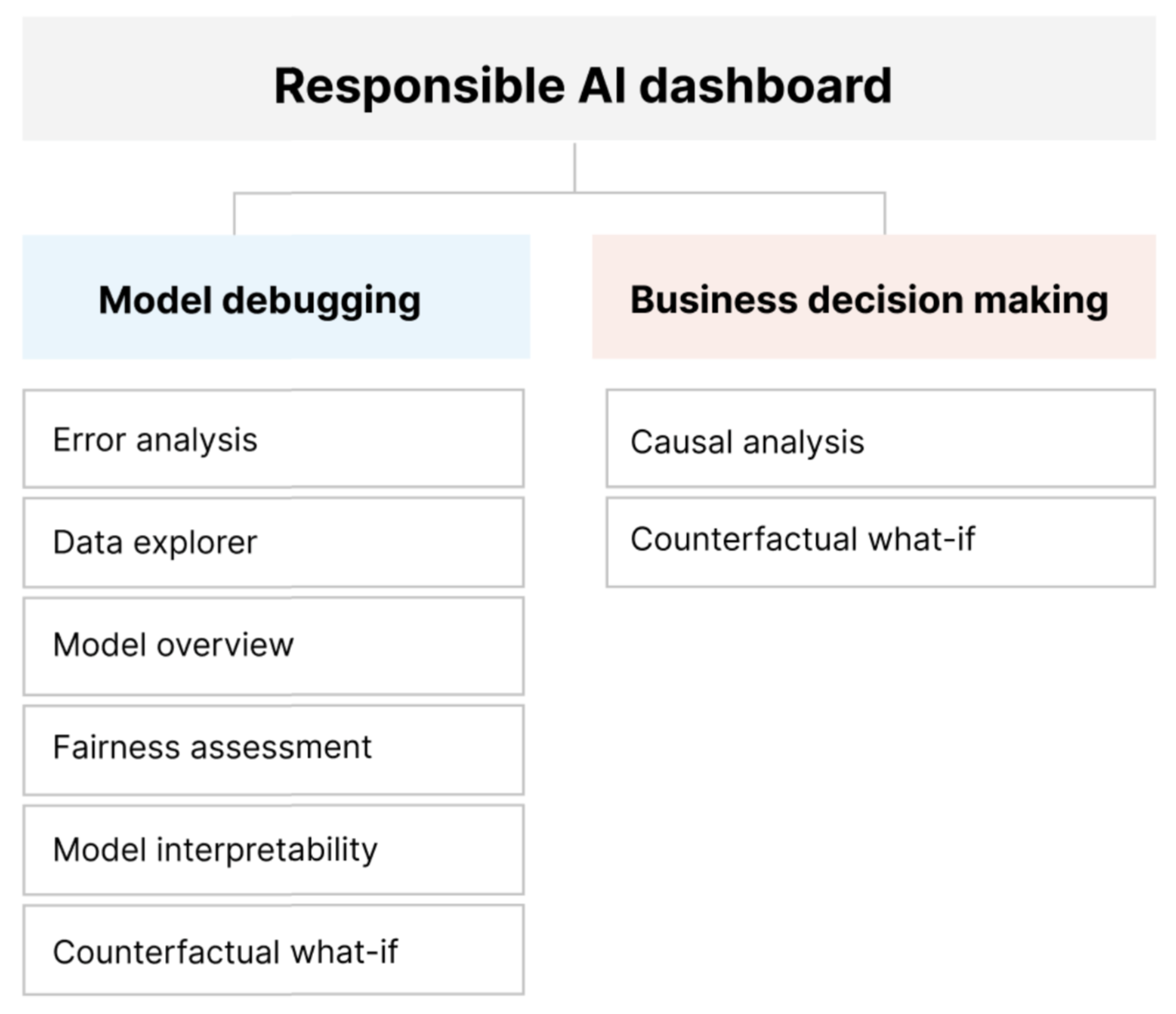
O painel de IA Responsável fornece uma interface única para ajudá-lo a implementar a IA Responsável na prática de forma eficaz e eficiente. Reúne várias ferramentas maduras de IA Responsável nas áreas de:
- Avaliação do desempenho e equidade do modelo
- Exploração de dados
- Interpretabilidade de aprendizado de máquina
- Análise de erros
- Análise contrafactual e perturbações
- Inferência causal
O painel oferece uma avaliação holística e depuração de modelos para que você possa tomar decisões informadas baseadas em dados. Ter acesso a todas essas ferramentas em uma interface permite que você:
Avalie e depure seus modelos de aprendizado de máquina identificando erros de modelo e problemas de equidade, diagnosticando por que esses erros estão acontecendo e informando suas etapas de mitigação.
Aumente as suas capacidades de tomada de decisão baseadas em dados, abordando questões como:
"Qual é a alteração mínima que os usuários podem aplicar aos seus recursos para obter um resultado diferente do modelo?"
"Qual é o efeito causal de reduzir ou aumentar uma característica (por exemplo, o consumo de carne vermelha) em um resultado do mundo real (por exemplo, progressão do diabetes)?"
Você pode personalizar o painel para incluir apenas o subconjunto de ferramentas que são relevantes para seu caso de uso.
O painel de IA responsável é acompanhado por um scorecard em PDF. O scorecard permite exportar metadados de IA responsável e insights sobre seus dados e modelos. Em seguida, você pode compartilhá-los off-line com as partes interessadas do produto e da conformidade.
Componentes responsáveis do painel de IA
O painel de IA Responsável reúne, numa visão abrangente, várias ferramentas novas e pré-existentes. O painel integra essas ferramentas com a CLI v2 do Azure Machine Learning, o SDK do Python do Azure Machine Learning v2 e o estúdio do Azure Machine Learning. Estas ferramentas incluem:
- Análise de dados, para compreender e explorar as distribuições e estatísticas do conjunto de dados.
- Visão geral do modelo e avaliação de equidade, para avaliar o desempenho do seu modelo e avaliar os problemas de equidade de grupo do seu modelo (como as previsões do seu modelo afetam diversos grupos de pessoas).
- Análise de erros, para visualizar e entender como os erros são distribuídos em seu conjunto de dados.
- Interpretabilidade do modelo (valores de importância para características agregadas e individuais), para entender as previsões do seu modelo e como essas previsões gerais e individuais são feitas.
- Hipóteses contrafactuais, para observar como as perturbações de recursos afetariam suas previsões de modelo enquanto forneciam os pontos de dados mais próximos com previsões de modelo opostas ou diferentes.
- Análise causal, para usar dados históricos para visualizar os efeitos causais das características do tratamento nos resultados do mundo real.
Juntas, essas ferramentas ajudarão você a depurar modelos de aprendizado de máquina, ao mesmo tempo em que informam suas decisões de negócios orientadas por dados e modelos. O diagrama a seguir mostra como você pode incorporá-los ao seu ciclo de vida de IA para melhorar seus modelos e obter insights de dados sólidos.
Depuração de modelo
Avaliar e depurar modelos de aprendizado de máquina é fundamental para a confiabilidade, interpretabilidade, equidade e conformidade do modelo. Isso ajuda a determinar como e por que os sistemas de IA se comportam da maneira que se comportam. Em seguida, você pode usar esse conhecimento para melhorar o desempenho do modelo. Conceitualmente, a depuração do modelo consiste em três estágios:
Identificar, compreender e reconhecer erros de modelo e/ou problemas de equidade, abordando as seguintes questões:
"Que tipos de erros tem o meu modelo?"
"Em que áreas os erros são mais prevalentes?"
Diagnostique, para explorar as razões por trás dos erros identificados, abordando:
"Quais são as causas desses erros?"
"Onde devo concentrar os meus recursos para melhorar o meu modelo?"
Mitigar, para usar os insights de identificação e diagnóstico de estágios anteriores para tomar medidas de mitigação direcionadas e abordar questões como:
"Como posso melhorar o meu modelo?"
"Que soluções sociais ou técnicas existem para estas questões?"

A tabela a seguir descreve quando usar os componentes do painel de IA responsável para dar suporte à depuração de modelo:
| Fase | Componente | Description |
|---|---|---|
| Identificar | Análise de erros | O componente de análise de erros ajuda você a obter uma compreensão mais profunda da distribuição de falhas do modelo e identificar rapidamente coortes (subgrupos) errôneas de dados. Os recursos desse componente no painel vêm do pacote Análise de Erros. |
| Identificar | Análise de equidade | O componente equidade define grupos em termos de atributos sensíveis, como sexo, raça e idade. Em seguida, ele avalia como as previsões do modelo afetam esses grupos e como você pode reduzir as disparidades. Ele avalia o desempenho do seu modelo explorando a distribuição dos seus valores de previsão e os valores das métricas de desempenho do seu modelo entre os grupos. Os recursos desse componente no painel vêm do pacote Fairlearn . |
| Identificar | Descrição geral do modelo | O componente de visão geral do modelo agrega métricas de avaliação do modelo em uma visão de alto nível da distribuição de previsão do modelo para uma melhor investigação de seu desempenho. Este componente também permite a avaliação da equidade do grupo, destacando a divisão do desempenho do modelo em grupos sensíveis. |
| Diagnosticar | Análise de dados | A análise de dados visualiza conjuntos de dados com base em resultados previstos e reais, grupos de erros e recursos específicos. Em seguida, você pode identificar problemas de sobre-representação e sub-representação, além de ver como os dados são agrupados no conjunto de dados. |
| Diagnosticar | Capacidade de interpretação do modelo | O componente de interpretabilidade gera explicações compreensíveis por humanos das previsões de um modelo de aprendizado de máquina. Ele fornece várias visualizações sobre o comportamento de um modelo: - Explicações globais (por exemplo, quais características afetam o comportamento geral de um modelo de alocação de empréstimos) - Explicações locais (por exemplo, por que o pedido de empréstimo de um candidato foi aprovado ou rejeitado) Os recursos desse componente no painel vêm do pacote InterpretML . |
| Diagnosticar | Análise contrafactual e hipóteses | Este componente consiste em duas funcionalidades para um melhor diagnóstico de erros: - Gerar um conjunto de exemplos em que mudanças mínimas em um determinado ponto alteram a previsão do modelo. Ou seja, os exemplos mostram os pontos de dados mais próximos com previsões de modelo opostas. - Permitir perturbações hipotéticas interativas e personalizadas para pontos de dados individuais para entender como o modelo reage a alterações de recursos. Os recursos desse componente no painel vêm do pacote DiCE . |
As etapas de mitigação estão disponíveis por meio de ferramentas autônomas, como o Fairlearn. Para obter mais informações, consulte os algoritmos de mitigação de injustiça.
Tomada de decisão responsável
A tomada de decisão é uma das maiores promessas do machine learning. O painel de IA responsável pode ajudá-lo a tomar decisões de negócios informadas através de:
Insights orientados por dados, para entender melhor os efeitos do tratamento causal em um resultado usando apenas dados históricos. Por exemplo:
"Como um medicamento afetaria a pressão arterial de um paciente?"
"Como o fornecimento de valores promocionais a determinados clientes afetaria a receita?"
Esses insights são fornecidos por meio do componente de inferência causal do painel.
Insights orientados por modelos, para responder às perguntas dos usuários (como "O que posso fazer para obter um resultado diferente da sua IA da próxima vez?") para que eles possam agir. Esses insights são fornecidos aos cientistas de dados por meio do componente hipotético contrafactual.

A análise exploratória de dados, a inferência causal e os recursos de análise contrafactual podem ajudá-lo a tomar decisões informadas baseadas em modelos e dados de forma responsável.
Estes componentes do painel de IA Responsável apoiam a tomada de decisões responsáveis:
Análise de dados: Você pode reutilizar o componente de análise de dados aqui para entender as distribuições de dados e identificar a sobre-representação e a sub-representação. A exploração de dados é uma parte crítica da tomada de decisões, porque não é viável tomar decisões informadas sobre uma coorte que está sub-representada nos dados.
Inferência causal: O componente de inferência causal estima como um resultado do mundo real muda na presença de uma intervenção. Também ajuda a construir intervenções promissoras, simulando respostas de características a várias intervenções e criando regras para determinar quais coortes populacionais se beneficiariam de uma intervenção específica. Coletivamente, essas funcionalidades permitem que você aplique novas políticas e efetue mudanças no mundo real.
As capacidades deste componente vêm do pacote EconML, que estima efeitos de tratamento heterogêneos de dados observacionais via aprendizado de máquina.
Análise contrafactual: Você pode reutilizar o componente de análise contrafactual aqui para gerar alterações mínimas aplicadas aos recursos de um ponto de dados que levam a previsões de modelo opostas. Por exemplo: Taylor teria obtido a aprovação do empréstimo da IA se ganhasse US$ 10.000 a mais em renda anual e tivesse dois cartões de crédito a menos abertos.
Fornecer essas informações aos usuários informa sua perspetiva. Educa-os sobre como podem agir para obter o resultado desejado da IA no futuro.
As capacidades deste componente vêm do pacote DiCE .
Razões para usar o painel de IA responsável
Embora tenham sido feitos progressos em ferramentas individuais para áreas específicas da IA responsável, os cientistas de dados muitas vezes precisam usar várias ferramentas para avaliar holisticamente seus modelos e dados. Por exemplo: poderão ter de utilizar em conjunto a interpretabilidade do modelo e a avaliação da equidade.
Se os cientistas de dados descobrirem um problema de equidade com uma ferramenta, eles precisarão pular para uma ferramenta diferente para entender quais dados ou fatores de modelo estão na raiz do problema antes de tomar quaisquer medidas de mitigação. Os seguintes fatores complicam ainda mais esse processo desafiador:
- Não há um local central para descobrir e aprender sobre as ferramentas, estendendo o tempo necessário para pesquisar e aprender novas técnicas.
- As diferentes ferramentas não comunicam entre si. Os cientistas de dados devem analisar os conjuntos de dados, modelos e outros metadados à medida que os passam entre as ferramentas.
- As métricas e visualizações não são facilmente comparáveis e os resultados são difíceis de compartilhar.
O painel de IA responsável desafia esse status quo. É uma ferramenta abrangente, mas personalizável, que reúne experiências fragmentadas em um só lugar. Ele permite que você integre perfeitamente a uma única estrutura personalizável para depuração de modelos e tomada de decisão orientada por dados.
Usando o painel IA responsável, você pode criar coortes de conjunto de dados, passar essas coortes para todos os componentes suportados e observar a integridade do modelo para as coortes identificadas. Você pode comparar ainda mais informações de todos os componentes suportados em uma variedade de coortes pré-criadas para executar análises desagregadas e encontrar os pontos cegos do seu modelo.
Quando estiver pronto para compartilhar esses insights com outras partes interessadas, você poderá extraí-los facilmente usando o scorecard PDF da IA Responsável. Anexe o relatório PDF aos seus relatórios de conformidade ou partilhe-o com colegas para criar confiança e obter a aprovação deles.
Maneiras de personalizar o painel de IA responsável
A força do painel de IA responsável reside na sua personalização. Ele permite que os usuários projetem fluxos de trabalho personalizados e completos de depuração de modelos e tomada de decisões que atendam às suas necessidades específicas.
Precisa de inspiração? Aqui estão alguns exemplos de como os componentes do painel podem ser reunidos para analisar cenários de diversas maneiras:
| Fluxo responsável do painel de IA | Caso de utilização |
|---|---|
| Visão geral do modelo, > análise de > erros, análise de dados | Para identificar erros de modelo e diagnosticá-los compreendendo a distribuição de dados subjacente |
| Visão geral do > modelo, avaliação > da equidade, análise de dados | Para identificar problemas de equidade do modelo e diagnosticá-los compreendendo a distribuição de dados subjacente |
| Visão geral do > modelo, análise > de erros, análise contrafactual e hipóteses | Para diagnosticar erros em instâncias individuais com análise contrafactual (alteração mínima para levar a uma previsão de modelo diferente) |
| Análise de dados de visão geral > do modelo | Compreender a causa raiz dos erros e problemas de equidade introduzidos por meio de desequilíbrios de dados ou falta de representação de uma coorte de dados específica |
| Interpretabilidade da visão geral > do modelo | Diagnosticar erros de modelo através da compreensão de como o modelo fez suas previsões |
| Inferência causal da análise > dos dados | Distinguir entre correlações e causalidades nos dados ou decidir os melhores tratamentos a aplicar para obter um resultado positivo |
| Interpretabilidade > inferência causal | Para saber se os fatores que o modelo usou para fazer previsões têm algum efeito causal no resultado do mundo real |
| Análise > de dados, análise contrafactual e hipóteses | Para responder às perguntas dos clientes sobre o que eles podem fazer da próxima vez para obter um resultado diferente de um sistema de IA |
Pessoas que devem usar o painel de IA responsável
As seguintes pessoas podem usar o painel de IA Responsável e seu scorecard de IA Responsável correspondente para construir confiança com os sistemas de IA:
- Profissionais de aprendizado de máquina e cientistas de dados interessados em depurar e melhorar seus modelos de aprendizado de máquina antes da implantação
- Profissionais de aprendizado de máquina e cientistas de dados interessados em compartilhar seus registros de integridade do modelo com gerentes de produto e partes interessadas de negócios para criar confiança e receber permissões de implantação
- Gerentes de produto e partes interessadas de negócios que estão revisando modelos de aprendizado de máquina antes da implantação
- Responsáveis pelo risco que estão a rever modelos de aprendizagem automática para compreender os problemas de equidade e fiabilidade
- Fornecedores de soluções de IA que querem explicar as decisões do modelo aos utilizadores ou ajudá-los a melhorar o resultado
- Profissionais em espaços altamente regulamentados que precisam rever modelos de aprendizado de máquina com reguladores e auditores
Cenários e limitações suportados
- O painel de IA responsável atualmente suporta modelos de regressão e classificação (binários e multiclasse) treinados em dados estruturados tabulares.
- Atualmente, o painel de IA Responsável dá suporte a modelos MLflow registrados no Aprendizado de Máquina do Azure apenas com um sabor sklearn (scikit-learn). Os modelos scikit-learn devem implementar
predict()/predict_proba()métodos, ou o modelo deve ser envolvido dentro de uma classe que implementapredict()/predict_proba()métodos. Os modelos devem ser carregáveis no ambiente do componente e devem ser decapáveis. - Atualmente, o painel de IA responsável visualiza até 5K de seus pontos de dados na interface do usuário do painel. Você deve reduzir a amostra do conjunto de dados para 5K ou menos antes de passá-lo para o painel.
- As entradas do conjunto de dados para o painel de IA responsável devem ser pandas DataFrames no formato Parquet. Atualmente, não há suporte para dados esparsos NumPy e SciPy.
- O painel de IA responsável atualmente suporta recursos numéricos ou categóricos. Para recursos categóricos, o usuário deve especificar explicitamente os nomes dos recursos.
- Atualmente, o painel de IA responsável não suporta conjuntos de dados com mais de 10 mil colunas.
- O painel de IA responsável atualmente não suporta o modelo AutoML MLFlow.
- Atualmente, o painel de IA responsável não suporta modelos AutoML registrados da interface do usuário.
Próximos passos
- Saiba como gerar o painel de IA Responsável por meio de CLI e SDK ou da interface do usuário do estúdio Azure Machine Learning.
- Saiba como gerar um scorecard de IA Responsável com base nos insights observados no painel de IA Responsável.