Exemplos em Máquinas Virtuais de Ciência de Dados do Azure
Uma DSVM (Máquinas Virtuais de Ciência de Dados) do Azure inclui um conjunto abrangente de código de exemplo. Esses exemplos incluem notebooks Jupyter e scripts em linguagens como Python e R.
Nota
Para obter mais informações sobre como executar blocos de anotações Jupyter em suas máquinas virtuais de ciência de dados, visite a seção Access Jupyter .
Pré-requisitos
Para executar esses exemplos, você deve ter uma máquina virtual de ciência de dados do Ubuntu provisionada.
Amostras disponíveis
| Categoria de amostras | Description | Localizações |
|---|---|---|
| Linguagem Python | Exemplos que explicam como se conectar com armazenamentos de dados em nuvem baseados no Azure e como trabalhar com cenários do Azure Machine Learning. Linguagem Python |
~notebooks |
| Língua Julia | Fornece uma descrição detalhada da plotagem e aprendizagem profunda em Julia. Explica como chamar C e Python de Julia. Língua Julia |
Windows: ~notebooks/Julia_notebooksLinux: ~notebooks/julia |
| Azure Machine Learning | Mostra como criar modelos de aprendizagem automática e aprendizagem profunda com o Machine Learning. Implante modelos em qualquer lugar. Use aprendizado de máquina automatizado e ajuste inteligente de hiperparâmetros. Use o gerenciamento de modelos e treinamento distribuído. Machine Learning |
~notebooks/AzureML |
| Cadernos PyTorch | Exemplos de aprendizagem profunda que usam redes neurais baseadas em PyTorch. Os notebooks variam de cenários iniciantes a avançados. Cadernos PyTorch |
~notebooks/Deep_learning_frameworks/pytorch |
| TensorFlow | Várias amostras de redes neurais e técnicas implementadas com a estrutura TensorFlow. TensorFlow |
~notebooks/Deep_learning_frameworks/tensorflow |
| H2O | Exemplos baseados em Python que usam H2O para cenários de problemas do mundo real. H2O |
~notebooks/h2o |
| Linguagem SparkML | Exemplos que usam recursos do kit de ferramentas Apache Spark MLLib, por meio do pySpark e MMLSpark: Microsoft Machine Learning for Apache Spark on Apache Spark 2.x. Linguagem SparkML |
~notebooks/SparkML/pySpark~notebooks/MMLSpark |
| XGBoost | Exemplos de aprendizado de máquina padrão em XGBoost - por exemplo, classificação e regressão. XGBoost |
Windows: \dsvm\samples\xgboost\demo |
Acesso Jupyter
Para acessar o Jupyter, selecione o ícone do Jupyter na área de trabalho ou no menu do aplicativo. Você também pode acessar o Jupyter em uma edição Linux de uma DSVM. Para acesso remoto a partir de um navegador da web, visite https://<Full Domain Name or IP Address of the DSVM>:8000 no Ubuntu.
Para adicionar exceções e disponibilizar o acesso ao Jupyter por meio de um navegador, use estas diretrizes:
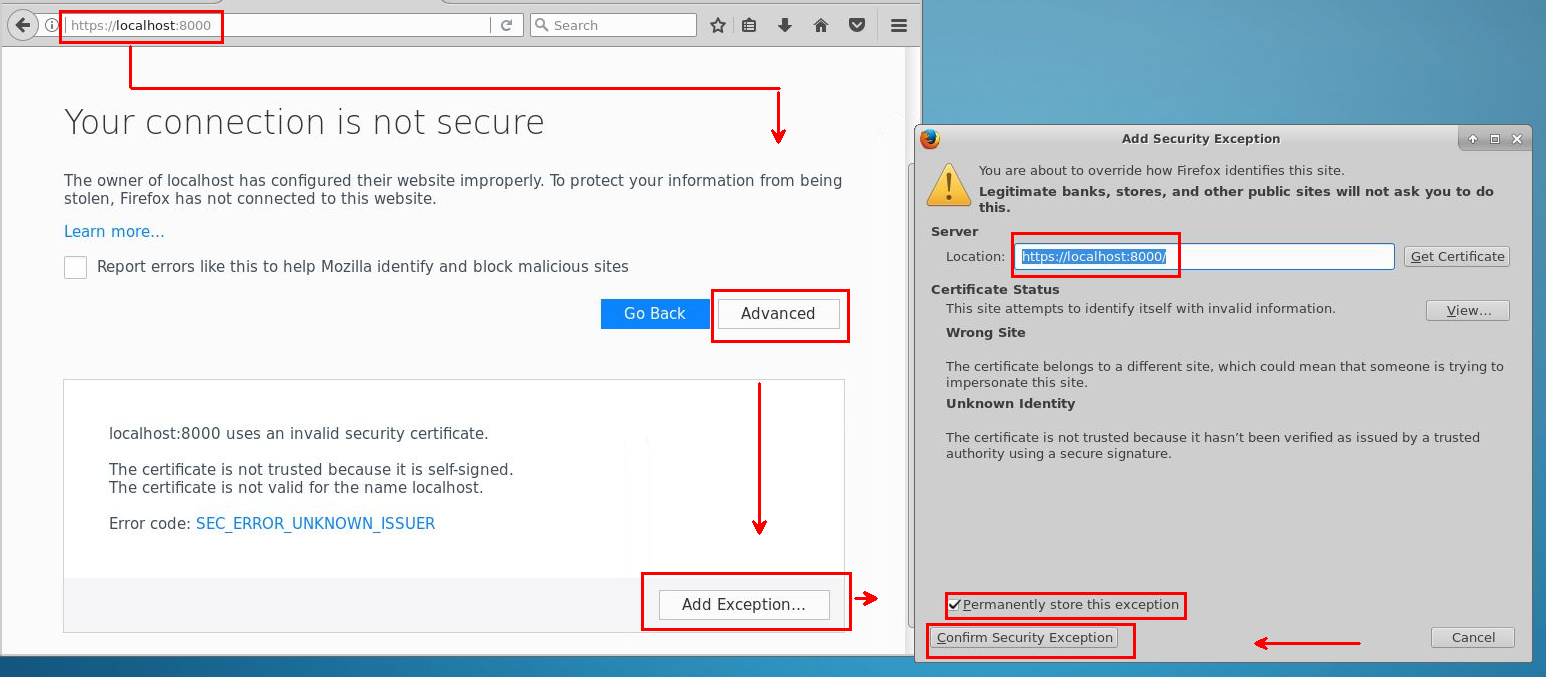
Entre com a mesma senha que você usa para logins de Máquina Virtual de Ciência de Dados.
Jupyter casa

Linguagem R

Linguagem Python

Língua Julia

Azure Machine Learning

PyTorch

TensorFlow

H2O

Faísca

XGBoost
