Criar scripts de pontuação para implantações em lote
APLICA-SE A: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Os pontos de extremidade em lote permitem implantar modelos que executam inferência de longa duração em escala. Ao implantar modelos, você deve criar e especificar um script de pontuação (também conhecido como script de driver em lote) para indicar como usá-lo sobre os dados de entrada para criar previsões. Neste artigo, você aprenderá a usar scripts de pontuação em implantações de modelo para diferentes cenários. Você também aprenderá sobre as práticas recomendadas para pontos de extremidade em lote.
Gorjeta
Os modelos MLflow não exigem um script de pontuação. Ele é gerado automaticamente para você. Para obter mais informações sobre como os pontos de extremidade em lote funcionam com modelos MLflow, visite o tutorial dedicado Usando modelos MLflow em implantações em lote.
Aviso
Para implantar um modelo de ML automatizado em um ponto de extremidade em lote, observe que o ML automatizado fornece um script de pontuação que só funciona para pontos de extremidade online. Esse script de pontuação não foi projetado para execução em lote. Siga estas diretrizes para obter mais informações sobre como criar um script de pontuação, personalizado para o que seu modelo faz.
Entendendo o roteiro de pontuação
O script de pontuação é um arquivo Python (.py) que especifica como executar o modelo e ler os dados de entrada que o executor de implementação em lote envia. Cada implantação de modelo fornece o script de pontuação (juntamente com todas as outras dependências necessárias) no momento da criação. O script de pontuação geralmente se parece com isto:
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
O script de pontuação deve conter dois métodos:
O init método
Use o método para qualquer preparação cara init() ou comum. Por exemplo, use-o para carregar o modelo na memória. O início de todo o trabalho em lote chama essa função uma vez. Os arquivos do seu modelo estão disponíveis em um caminho determinado pela variável AZUREML_MODEL_DIRde ambiente . Dependendo de como seu modelo foi registrado, seus arquivos podem estar contidos em uma pasta. No próximo exemplo, o modelo tem vários arquivos em uma pasta chamada model. Para obter mais informações, visite como você pode determinar a pasta que seu modelo usa.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
Neste exemplo, colocamos o modelo na variável modelglobal. Para disponibilizar os ativos necessários para executar a inferência em sua função de pontuação, use variáveis globais.
O run método
Use o run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] método para manipular a pontuação de cada minilote gerado pela implantação do lote. Esse método é chamado uma vez para cada mini_batch dado de entrada gerado. As implantações em lote leem dados em lotes de acordo com a configuração da implantação.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
O método recebe uma lista de caminhos de arquivo como um parâmetro (mini_batch). Você pode usar essa lista para iterar e processar individualmente cada arquivo, ou para ler todo o lote e processá-lo de uma só vez. A melhor opção depende da sua memória de computação e da taxa de transferência que você precisa alcançar. Para obter um exemplo que descreve como ler lotes inteiros de dados de uma só vez, visite Implantações de alta taxa de transferência.
Nota
Como é distribuído o trabalho?
As implantações em lote distribuem o trabalho no nível do arquivo, o que significa que uma pasta que contém 100 arquivos, com minilotes de 10 arquivos, gera 10 lotes de 10 arquivos cada. Observe que os tamanhos dos arquivos relevantes não têm relevância. Para arquivos muito grandes para serem processados em minilotes grandes, sugerimos que você divida os arquivos em arquivos menores para obter um nível mais alto de paralelismo ou diminua o número de arquivos por minilote. No momento, a implantação em lote não pode levar em conta as distorções na distribuição de tamanho do arquivo.
O run() método deve retornar um Pandas DataFrame ou uma matriz/lista. Cada elemento de saída retornado indica uma execução bem-sucedida de um elemento de entrada na entrada mini_batch. Para ativos de dados de arquivo ou pasta, cada linha/elemento retornado representa um único arquivo processado. Para um ativo de dados tabulares, cada linha/elemento retornado representa uma linha em um arquivo processado.
Importante
Como escrever previsões?
Tudo o que a run() função retorna será anexado no arquivo de previsões de saída que o trabalho em lote gera. É importante retornar o tipo de dados correto dessa função. Retorne matrizes quando precisar gerar uma única previsão. Retorne pandas DataFrames quando precisar retornar várias informações. Por exemplo, para dados tabulares, convém acrescentar suas previsões ao registro original. Use um Pandas DataFrame para fazer isso. Embora um Pandas DataFrame possa conter nomes de coluna, o arquivo de saída não inclui esses nomes.
Para escrever previsões de uma maneira diferente, você pode personalizar saídas em implantações em lote.
Aviso
Na função, não produza run tipos de dados complexos (ou listas de tipos de dados complexos) em vez de pandas.DataFrame. Essas saídas serão transformadas em strings e se tornarão difíceis de ler.
O DataFrame ou matriz resultante é anexado ao arquivo de saída indicado. Não há exigência sobre a cardinalidade dos resultados. Um arquivo pode gerar 1 ou muitas linhas/elementos na saída. Todos os elementos no DataFrame ou matriz de resultado são gravados no arquivo de saída como está (considerando o output_action não summary_onlyé).
Pacotes Python para pontuação
Você deve indicar qualquer biblioteca que seu script de pontuação exija para ser executado no ambiente em que a implantação em lote é executada. Para pontuar scripts, os ambientes são indicados por implantação. Normalmente, você indica seus requisitos usando um conda.yml arquivo de dependências, que pode ter esta aparência:
mnist/ambiente/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
Visite Criar uma implantação em lote para obter mais informações sobre como indicar o ambiente para seu modelo.
Escrever previsões de uma forma diferente
Por padrão, a implantação em lote grava as previsões do modelo em um único arquivo, conforme indicado na implantação. No entanto, em alguns casos, você deve escrever as previsões em vários arquivos. Por exemplo, para dados de entrada particionados, você provavelmente desejaria gerar saída particionada também. Nesses casos, você pode Personalizar saídas em implantações em lote para indicar:
- O formato de arquivo (CSV, parquet, json, etc) usado para escrever previsões
- A forma como os dados são particionados na saída
Visite Personalizar saídas em implantações em lote para obter mais informações sobre como alcançá-las.
Controle do código-fonte de scripts de pontuação
É altamente aconselhável colocar scripts de pontuação sob controle do código-fonte.
Práticas recomendadas para escrever scripts de pontuação
Ao escrever scripts de pontuação que lidam com grandes quantidades de dados, você deve levar em conta vários fatores, incluindo
- O tamanho de cada ficheiro
- A quantidade de dados em cada arquivo
- A quantidade de memória necessária para ler cada ficheiro
- A quantidade de memória necessária para ler um lote inteiro de arquivos
- A pegada de memória do modelo
- A pegada de memória do modelo, ao executar sobre os dados de entrada
- A memória disponível na sua computação
As implantações em lote distribuem o trabalho no nível do arquivo. Isso significa que uma pasta que contém 100 arquivos, em minilotes de 10 arquivos, gera 10 lotes de 10 arquivos cada (independentemente do tamanho dos arquivos envolvidos). Para arquivos grandes demais para serem processados em minilotes grandes, sugerimos que você divida os arquivos em arquivos menores, para obter um nível mais alto de paralelismo, ou que diminua o número de arquivos por minilote. No momento, a implantação em lote não pode levar em conta as distorções na distribuição de tamanho do arquivo.
Relação entre o grau de paralelismo e o roteiro de pontuação
Sua configuração de implantação controla o tamanho de cada minilote e o número de trabalhadores em cada nó. Isso se torna importante quando você decide se deseja ou não ler todo o minilote para executar a inferência, executar a inferência arquivo por arquivo ou executar a inferência linha por linha (para tabela). Visite Executando inferência no minilote, no arquivo ou no nível da linha para obter mais informações.
Ao executar vários trabalhadores na mesma instância, você deve levar em conta o fato de que a memória é compartilhada entre todos os trabalhadores. Um aumento no número de trabalhadores por nó geralmente deve acompanhar uma diminuição no tamanho do minilote ou uma mudança na estratégia de pontuação se o tamanho dos dados e o SKU de computação permanecerem os mesmos.
Executando a inferência no minilote, no arquivo ou no nível da linha
Os pontos de extremidade em lote chamam a run() função em um script de pontuação uma vez por minilote. No entanto, você pode decidir se deseja executar a inferência em todo o lote, em um arquivo de cada vez ou em uma linha de cada vez para dados tabulares.
Nível de minilote
Normalmente, você desejará executar a inferência sobre o lote de uma só vez, para obter alta taxa de transferência em seu processo de pontuação em lote. Isso acontece se você executar a inferência em uma GPU, onde você deseja atingir a saturação do dispositivo de inferência. Você também pode confiar em um carregador de dados que pode lidar com o próprio processamento em lote se os dados não couberem na memória, como TensorFlow ou PyTorch carregadores de dados. Nesses casos, convém executar a inferência em todo o lote.
Aviso
A execução da inferência no nível de lote pode exigir um controle próximo sobre o tamanho dos dados de entrada, para considerar corretamente os requisitos de memória e evitar exceções de falta de memória. Se você pode ou não carregar o minilote inteiro na memória depende do tamanho do minilote, do tamanho das instâncias no cluster, do número de trabalhadores em cada nó e do tamanho do minilote.
Visite Implantações de alta taxa de transferência para saber como conseguir isso. Este exemplo processa um lote inteiro de arquivos de cada vez.
Nível de ficheiro
Uma das maneiras mais fáceis de executar a inferência é a iteração sobre todos os arquivos no minilote e, em seguida, executar o modelo sobre ele. Em alguns casos, por exemplo, processamento de imagem, isso pode ser uma boa ideia. Para dados tabulares, talvez seja necessário fazer uma boa estimativa sobre o número de linhas em cada arquivo. Essa estimativa pode mostrar se seu modelo pode ou não lidar com os requisitos de memória para carregar os dados inteiros na memória e executar inferência sobre eles. Alguns modelos (especialmente aqueles baseados em redes neurais recorrentes) se desdobram e apresentam uma pegada de memória com uma contagem de linhas potencialmente não linear. Para um modelo com alto custo de memória, considere executar a inferência no nível da linha.
Gorjeta
Considere dividir arquivos muito grandes para ler de uma só vez em vários arquivos menores, para levar em conta uma melhor paralelização.
Visite Processamento de imagem com implantações em lote para saber como fazer isso. Esse exemplo processa um arquivo de cada vez.
Nível da linha (tabela)
Para modelos que apresentam desafios com seus tamanhos de entrada, convém executar a inferência no nível da linha. Sua implantação em lote ainda fornece seu script de pontuação com um minilote de arquivos. No entanto, você lerá um arquivo, uma linha de cada vez. Isso pode parecer ineficiente, mas para alguns modelos de aprendizado profundo pode ser a única maneira de executar inferência sem aumentar os recursos de hardware.
Visite Processamento de texto com implantações em lote para saber como fazer isso. Esse exemplo processa uma linha de cada vez.
Usando modelos que são pastas
A AZUREML_MODEL_DIR variável de ambiente contém o caminho para o local do modelo selecionado e a init() função normalmente o usa para carregar o modelo na memória. No entanto, alguns modelos podem conter seus arquivos em uma pasta, e talvez seja necessário levar isso em conta ao carregá-los. Você pode identificar a estrutura de pastas do seu modelo como mostrado aqui:
Vá para o portal do Azure Machine Learning.
Vá para a seção Modelos.
Selecione o modelo que deseja implantar e selecione a guia Artefatos .
Observe a pasta exibida. Esta pasta foi indicada quando o modelo foi registado.
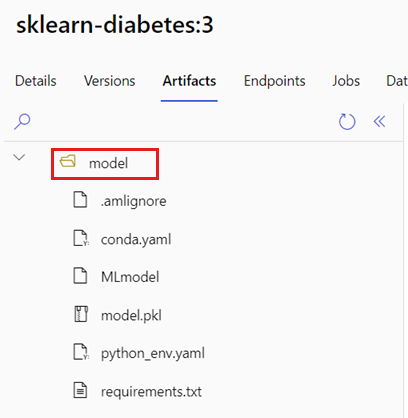

Use este caminho para carregar o modelo:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)